Category: MySQL / MariaDB
sql_mode
The following statement usually is valid and the function returns 1. But sometimes it is invalid and sometimes the function returns 0.
CREATE FUNCTION f() RETURNS INT DETERMINISTIC BEGIN DECLARE a CHAR DEFAULT 'a'; IF a = 0 || a > 0 THEN RETURN 1; END IF; RETURN 0; END;
Why?
First, consider that “||” is usually the same as “OR” because that’s the default. But if sql_mode is ‘ansi’ and the DBMS is MySQL 8.0, then “||” is the operator for concatenating strings. So the meaning of the IF condition changes, and it becomes false.
Second, consider that the function is written with SQL/PSM syntax. But if sql_mode is ‘oracle’ and the DBMS is MariaDB 10.3, then the function has to be written with PL/SQL syntax. And the requirements differ as soon as the word “RETURNS” comes along, so the result is a syntax error.
Our lesson is: you can’t know a statement’s meaning if you don’t know whether somebody said “SET sql_mode=…” earlier.
Usually SET sql_mode is a DIRECTIVE with the same sense as “pragma” in C, it is telling the compiler or interpreter how to treat the syntax of following statements. And in fact Oracle and SQLite actually use the word “pragma” in that sense. I use C pragmas despite a nagging feeling that somewhere there is a jeremiad blog post about how they’re as bad as goto and #ifndef, and I’ll recommended certain sql_mode values enthusiastically. The only strong warning is: be consistent, so you don’t end up with idiocy like my example above.
(By the way, speaking of C, one of the possible settings is “treat warnings as errors”, and if there were such a mode in MySQL/MariaDB then my example function wouldn’t have worked. But there isn’t an exact equivalent.)
The modes
The manuals’ lists are more complete, but this list has more advice.
ANSI: Avoid. It won’t deliver “American National Standards Institute” SQL. And try this:
SET @@sql_mode=''; CREATE TABLE x (s1 INT); SHOW CREATE TABLE x; SET @@sql_mode='ANSI'; SHOW CREATE TABLE x;
Compare the SHOW CREATE TABLE results. Before:
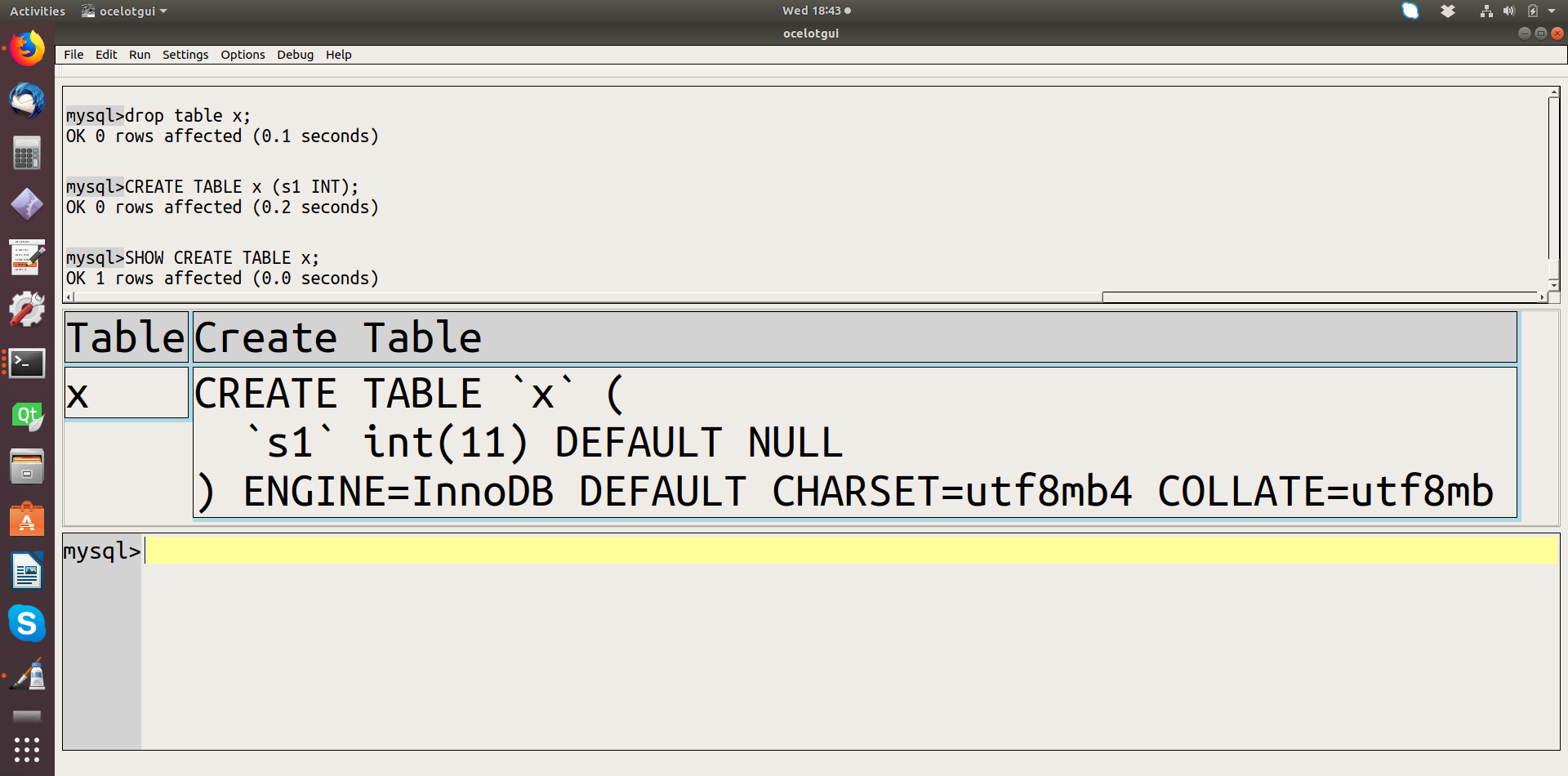
and after:
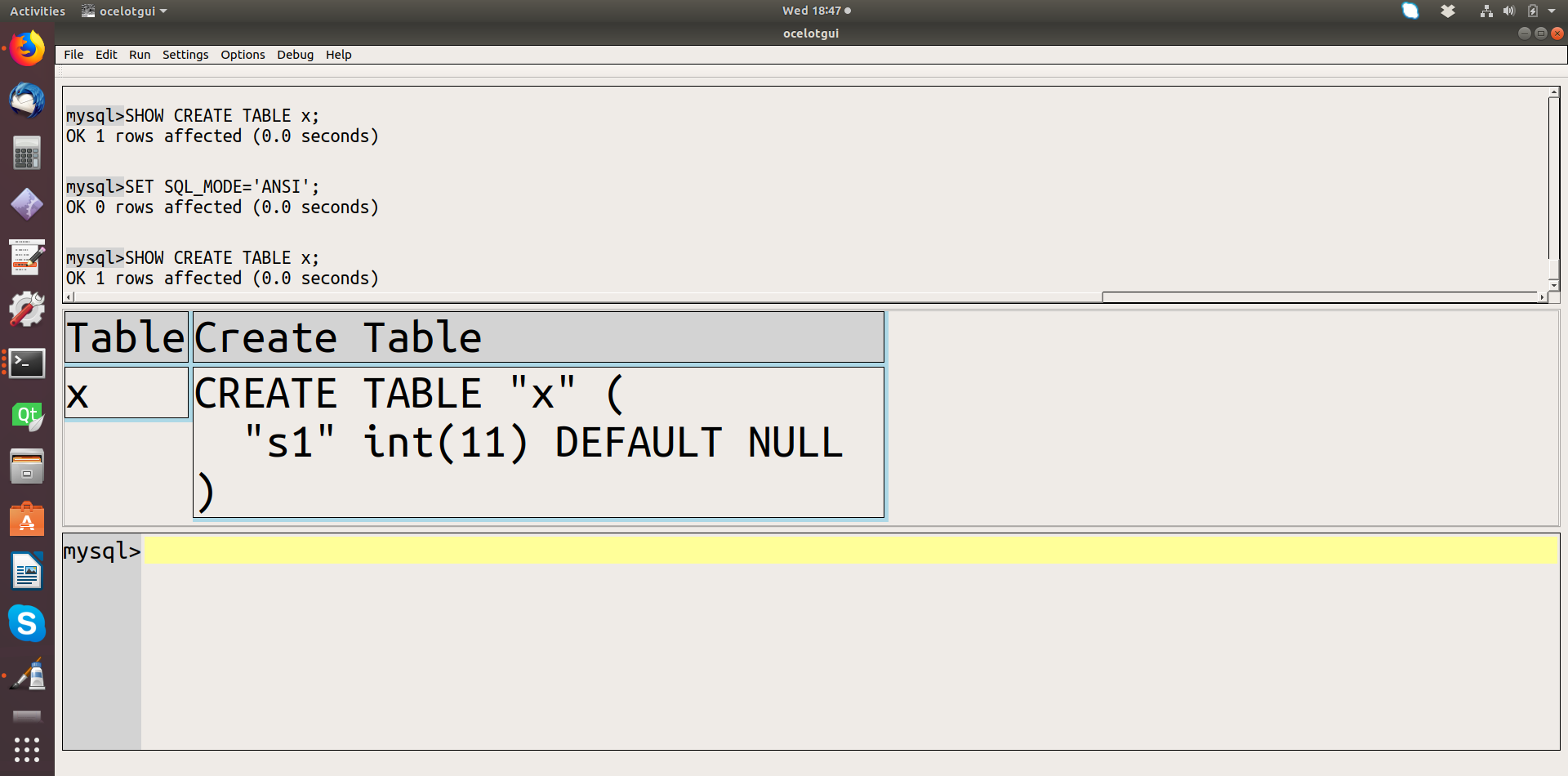
Notice that critical information is missing in the ‘ANSI’ result — information that would be necessary to reproduce the table correctly. So, although using standard SQL is good, the way to do it is by setting other SQL-mode settings that don’t have such ugly side effects.
TRADITIONAL: Don’t avoid. This has very limited effect, it only “treats warnings as errors” if you’re changing a database value, and it’s only safe if you’re using a storage engine that can do statement rollbacks, such as InnoDB. But most of the time it’s good to disallow bad data, which is why it’s “traditional” (which stands for “what everybody else has done for decades”).
ALLOW_INVALID_DATES, Avoid. This made sense when the objective was to avoid “invalid data” errors because transactions were hard to roll back. That’s less of a concern nowadays.
ANSI_QUOTES. Probably don’t avoid. If you frequently have single quotes inside string literals, such as “O’Hara”, it’s understandable that you’d want ANSI_QUOTES to be off. With ANSI_QUOTES on, you have to say ‘O”Hara” and it’s possible to lose the duplicated ‘. But ANSI_QUOTES are standard SQL.
HIGH_NOT_PRECEDENCE, NO_BACKSLASH_ESCAPES, NO_ZERO_DATE, NO_ZERO_IN_DATE, ONLY_FULL_GROUP_BY, PIPES_AS_CONCAT, REAL_AS_FLOAT. Don’t avoid. These are standard SQL.
PAD_CHAR_TO_FULL_LENGTH, ERROR_FOR_DIVISION_BY_ZERO. Avoid in MySQL. They’re deprecated.
IGNORE_SPACE. Avoid. The effect on naming is too great, because so many new reserved words appear.
NO_AUTO_VALUE_ON_ZERO. Avoid. This is a case where a non-standard feature can be treated in more than one way, so it’s hard to care.
SIMULTANEOUS_ASSIGNMENT. See my earlier blog post, The simultaneous_assignment mode in MariaDB 10.3.5.
STRICT_ALL_TABLES + STRICT_TRANS_TABLES. Don’t avoid. Perhaps you have some way of cleaning up messes after they’re added, but setting is simpler.
TIME_TRUNCATE_FRACTIONAL. Avoid but not forever. I hear from reliable sources that there is some strange behaviour that will be corrected real soon.
DB2,MAXDB,MSSQL,MYSQL323,MYSQL40,ORACLE,POSTGRESQL, etc. Mostly avoid. These have disappeared in MySQL 8.0. They never delivered a serious amount of compatibility with other DBMSs. The only one that is worth any consideration is ORACLE in MariaDB 10.3, because it affects quite a few Oracle-related matters including PL/SQL support.
The statement
There are many variants.
SET sql_mode=value; SET @sql_mode=value; SET @@sql_mode=value; SET SESSION | GLOBAL | PERSIST | PERSIST_ONLY sql_mode=value; SET @@session.|@@global.|@@persist.|@@persist_only.sql_mode=value;
where value can be a string literal containing a mode name
or a series of mode names as in ‘ansi,ansi’, or a variable, or even
a keyword. When it’s a keyword, it can be DEFAULT or
it can be a mode name — this seems to be undocumented but
I’ve seen that one of the MariaDB developers likes to use
SET sql_mode=ORACLE;
The good news is that the setting is transient and local. By “transient” I mean its effect ends when the routine ends or the session ends. By “local” I mean changes won’t affect other users whose sessions already started. And both these non-effects are good. Wouldn’t it be awful if your SQL statements stopped working because you invoked a function that changed sql_mode, or because some other user on the system found a way to change it for everybody while they were online?
ocelotgui 1.0.7
Version 1.0.7 of our open-source ocelotgui MySQL/MariaDB client is out, and one of the features is that it recognizes all the current syntax of MySQL 8.0 and MariaDB 10.3, including the sql_mode bizarreness (though we can’t get it right if the source value is a variable). That means that it won’t get confused when parsing batches of SQL statements that include statements that change the dialect.
The major feature is that the debugger can now debug routines written in MySQL 8.0, and routines written in MariaDB 10.3 with sql_mode=oracle — that is, with PL/SQL syntax.
As usual, download for various Linux distros and for Windows is via github.
Reserved Words
In the 1990s C.J.Date said: “The rule by which it is determined within the standard that one key word needs to be reserved while another need not be is not clear to this writer.”
Nothing has changed since then, except there are more reserved words. No DBMS uses the standard list. So I think that it is probably best to know what words are reserved in product X that are not reserved in product Y. If you know, you can avoid syntax errors when you update or migrate.
I’ll present several comparisons, ending with a grand chart of all the reserved words in the standard and six current DBMSs.
First here’s a screenshot of ocelotgui where I’m hovering over the word BEGIN.
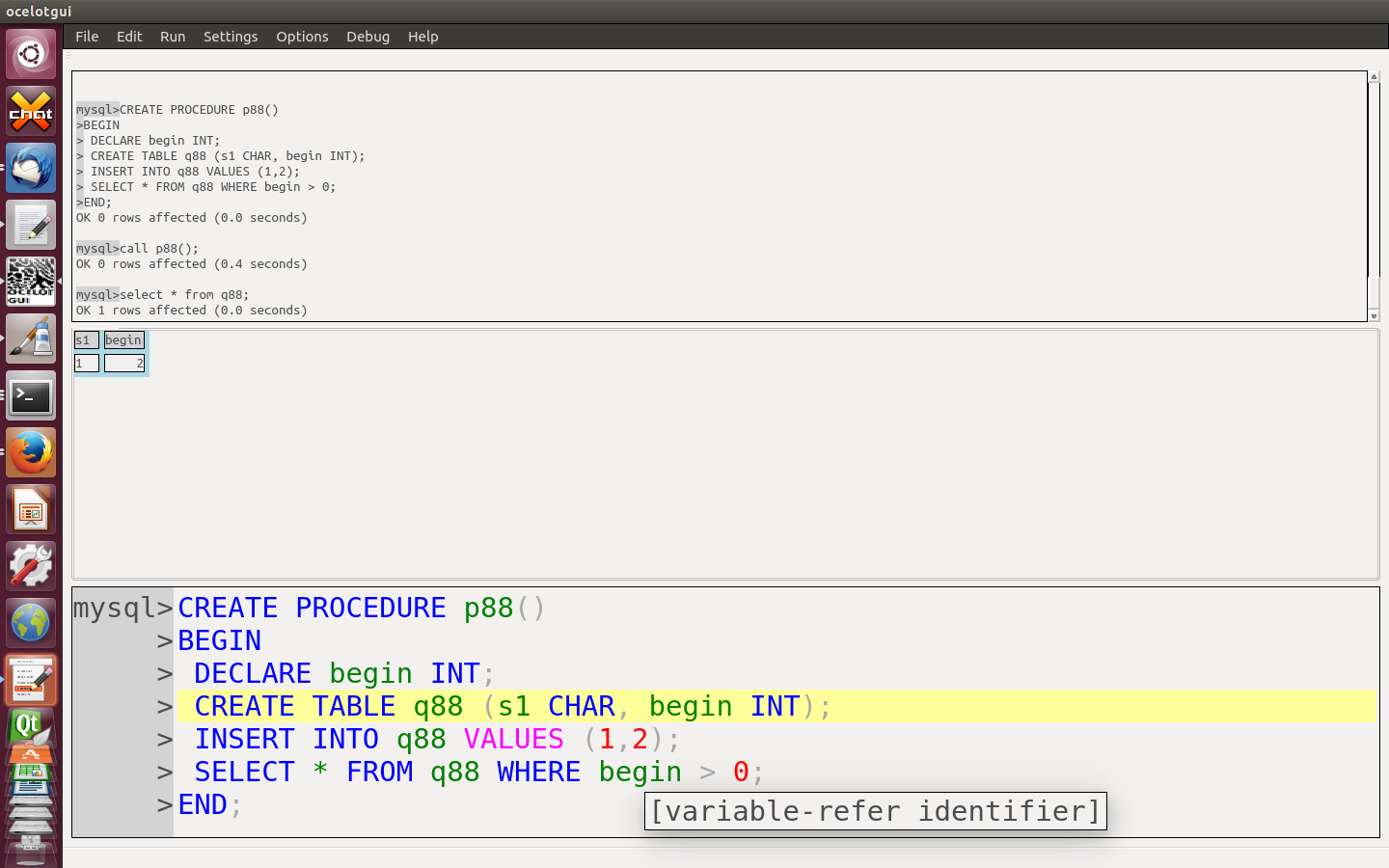
What I’m illustrating is that you can’t depend on intuition and assume BEGIN is reserved, but a GUI client can tell you from context: it’s a declared variable.
20 words are reserved in MariaDB but not in MySQL:
+-------------------------+ | word | +-------------------------+ | CURRENT_ROLE | | DO_DOMAIN_IDS | | GENERAL | | IGNORE_DOMAIN_IDS | | IGNORE_SERVER_IDS | | INTERSECT | | LEFT | | MASTER_HEARTBEAT_PERIOD | | MAX | | MODIFIES | | PAGE_CHECKSUM | | PARSE_VCOL_EXPR | | REF_SYSTEM_ID | | REPLACE | | RETURNING | | SCHEMA | | SLOW | | STATS_AUTO_RECALC | | STATS_PERSISTENT | | STATS_SAMPLE_PAGES | +-------------------------+
36 words are reserved in MySQL but not in MariaDB:
+-------------------+ | word | +-------------------+ | ADMIN | | ANALYSE | | CUBE | | CUME_DIST | | DENSE_RANK | | EMPTY | | FIRST_VALUE | | FUNCTION | | GENERATED | | GET | | GROUPING | | GROUPS | | IO_AFTER_GTIDS | | IO_BEFORE_GTIDS | | JSON_TABLE | | LAG | | LAST_VALUE | | LEAD | | LEAVESLEFT | | MASTER_BIND | | MODEMODIFIES | | NTH_VALUE | | NTILE | | OF | | OPTIMIZER_COSTS | | PERCENT_RANK | | PERSIST | | PERSIST_ONLY | | RANK | | REPEATABLEREPLACE | | ROW | | ROW_NUMBER | | SCHEDULESCHEMA | | STORED | | SYSTEM | | VIRTUAL | +-------------------+
15 words are reserved in MariaDB 10.3 but not in MariaDB 10.2:
+--------------------+ | word | +--------------------+ | CURRENT_ROLE | | DO_DOMAIN_IDS | | EXCEPT | | IGNORE_DOMAIN_IDS | | INTERSECT | | MAX | | OVER | | PAGE_CHECKSUM | | PARSE_VCOL_EXPR | | REF_SYSTEM_ID | | RETURNING | | STATS_AUTO_RECALC | | STATS_PERSISTENT | | STATS_SAMPLE_PAGES | | WINDOW | +--------------------+
(My MariaDB-10.3 list comes from the code source, my MariaDB-10.2 list comes from the manual, which may not be up to date.)
6 words are reserved in all of (DB2 and Oracle and Microsoft) but not in (MySQL or MariaDB):
+---------+ | word | +---------+ | ANY | | CURRENT | | FILE | | PUBLIC | | USER | | VIEW | +---------+
We said in SQL-99 Complete, Really: “[The standard] suggests that you include either a digit or an underline character in your regular identifiers and avoid names that begin with CURRENT_, SESSION_, SYSTEM_, or TIMEZONE_ and those that end with _LENGTH to avoid conflicts with reserved keywords added in future revisions.” It’s also good to avoid words that begin with SYS, or words that begin with the product name such as “IBM…” or “sql…”. And of course it might also be good to use “delimiters”, if you can avoid case-sensitivity confusions.
My original reason for making lists was to answer some questions about Tarantool. I do some paid work for this group, including tutorials about SQL like this one. In a forthcoming post I will show why I believe that this product is far ahead of the others that I discussed in an earlier post, What’s in the SQL of NoSQL and even has some useful characteristics that MySQL/MariaDB lack.
Ocelot news: We have just uploaded a Windows version of the ocelotgui client, with an executable ocelotgui.exe static-linked to MariaDB Connector C and Qt. So it should be easy to download the release from github and run. See the windows.txt file on github for more explanation. Alpha.
To end this post, here is the grand finale list — all reserved words in all dialects. Sta = Standard, Mar = MariaDB, MyS = MySQL, Db2 = DB2, Ora = Oracle, Mic = Microsoft, Odb = Odbc, Tar = Tarantool. (The Mic and Odb columns represent what Microsoft recommends but doesn’t always enforce.) (The Tar column is still subject to change.)
+----------------------------------+-----+-----+-----+-----+-----+-----+-----+-----+ | word | Sta | Mar | MyS | Db2 | Ora | Mic | Odb | Tar | +----------------------------------+-----+-----+-----+-----+-----+-----+-----+-----+ | ABS | x | | | | | | | | | ABSOLUTE | | | | | | | x | | | ACCESS | | | | | x | | | | | ACCESSIBLE | | x | x | | | | | | | ACTION | | | | | | | x | | | ACTIVATE | | | | x | | | | | | ADA | | | | | | | x | | | ADD | | x | x | x | x | x | x | | | ADMIN | | | x | | | | | | | AFTER | | | | x | | | | | | ALIAS | | | | x | | | | | | ALL | x | x | x | x | x | x | x | x | | ALLOCATE | x | | | x | | | x | | | ALLOW | | | | x | | | | | | ALTER | x | x | x | x | x | x | x | x | | ANALYSE | | | x | | | | | | | ANALYZE | | x | x | | | | | x | | AND | x | x | x | x | x | x | x | x | | ANY | x | | | x | x | x | x | x | | ARE | x | | | | | | x | | | ARRAY | x | | | | | | | | | ARRAY_AGG | x | | | | | | | | | ARRAY_MAX_CARDINALITY | x | | | | | | | | | AS | x | x | x | x | x | x | x | x | | ASC | | x | x | | x | x | x | x | | ASENSITIVE | x | x | x | x | | | | x | | ASSERTION | | | | | | | x | | | ASSOCIATE | | | | x | | | | | | ASUTIME | | | | x | | | | | | ASYMMETRIC | x | | | | | | | | | AT | x | | | x | | | x | | | ATOMIC | x | | | | | | | | | ATTRIBUTES | | | | x | | | | | | AUDIT | | | | x | x | | | | | AUTHORIZATION | x | | | x | | x | x | | | AUTOINCREMENT | | | | | | | | x | | AUX | | | | x | | | | | | AUXILIARY | | | | x | | | | | | AVG | x | | | | | | x | | | BACKUP | | | | | | x | | | | BEFORE | | x | x | x | | | | | | BEGIN | x | | | x | | x | x | x | | BEGIN_FRAME | x | | | | | | | | | BEGIN_PARTITION | x | | | | | | | | | BETWEEN | x | x | x | x | x | x | x | x | | BIGINT | x | x | x | | | | | | | BINARY | x | x | x | x | | | | x | | BIT | | | | | | | x | | | BIT_LENGTH | | | | | | | x | | | BLOB | x | x | x | | | | | | | BOOLEAN | x | | | | | | | | | BOTH | x | x | x | | | | x | | | BREAK | | | | | | x | | | | BROWSE | | | | | | x | | | | BUFFERPOOL | | | | x | | | | | | BULK | | | | | | x | | | | BY | x | x | x | x | x | x | x | x | | CACHE | | | | x | | | | | | CALL | x | x | x | x | | | | x | | CALLED | x | | | x | | | | | | CAPTURE | | | | x | | | | | | CARDINALITY | x | | | x | | | | | | CASCADE | | x | x | | | x | x | | | CASCADED | x | | | x | | | x | | | CASE | x | x | x | x | | x | x | x | | CAST | x | | | x | | | x | x | | CATALOG | | | | | | | x | | | CCSID | | | | x | | | | | | CEIL | x | | | | | | | | | CEILING | x | | | | | | | | | CHANGE | | x | x | | | | | | | CHAR | x | x | x | x | x | | x | x | | CHARACTER | x | x | x | x | | | x | x | | CHARACTER_LENGTH | x | | | | | | x | | | CHAR_LENGTH | x | | | | | | x | | | CHECK | x | x | x | x | x | x | x | x | | CHECKPOINT | | | | | | x | | | | CLASSIFIER | x | | | | | | | | | CLOB | x | | | | | | | | | CLONE | | | | x | | | | | | CLOSE | x | | | x | | x | x | | | CLUSTER | | | | x | x | | | | | CLUSTERED | | | | | | x | | | | COALESCE | x | | | | | x | x | | | COLLATE | x | x | x | | | x | x | x | | COLLATION | | | | | | | x | | | COLLECT | x | | | | | | | | | COLLECTION | | | | x | | | | | | COLLID | | | | x | | | | | | COLUMN | x | x | x | x | x | x | x | x | | COLUMN_VALUE | | | | | x | | | | | COMMENT | | | | x | x | | | | | COMMIT | x | | | x | | x | x | x | | COMPRESS | | | | | x | | | | | COMPUTE | | | | | | x | | | | CONCAT | | | | x | | | | | | CONDITION | x | x | x | x | | | | x | | CONNECT | x | | | x | x | | x | x | | CONNECTION | | | | x | | | x | | | CONSTRAINT | x | x | x | x | | x | x | x | | CONSTRAINTS | | | | | | | x | | | CONTAINS | x | | | x | | x | | | | CONTAINSTABLE | | | | | | x | | | | CONTINUE | | x | x | x | | x | x | | | CONVERT | x | x | x | | | x | x | | | CORR | x | | | | | | | | | CORRESPONDING | x | | | | | | x | | | COUNT | x | | | x | | | x | | | COUNT_BIG | | | | x | | | | | | COVAR_POP | x | | | | | | | | | COVAR_SAMP | x | | | | | | | | | CREATE | x | x | x | x | x | x | x | x | | CROSS | x | x | x | x | | x | x | x | | CUBE | x | | x | | | | | | | CUME_DIST | x | | x | | | | | | | CURRENT | x | | | x | x | x | x | x | | CURRENT_CATALOG | x | | | | | | | | | CURRENT_DATE | x | x | x | x | | x | x | x | | CURRENT_DEFAULT_TRANSFORM_GROUP | x | | | | | | | | | CURRENT_LC_CTYPE | | | | x | | | | | | CURRENT_PATH | x | | | x | | | | | | CURRENT_ROLE | x | x | | | | | | | | CURRENT_ROW | x | | | | | | | | | CURRENT_SCHEMA | x | | | x | | | | | | CURRENT_SERVER | | | | x | | | | | | CURRENT_TIME | x | x | x | x | | x | x | x | | CURRENT_TIMESTAMP | x | x | x | x | | x | x | x | | CURRENT_TIMEZONE | | | | x | | | | | | CURRENT_TRANSFORM_GROUP_FOR_TYPE | x | | | | | | | | | CURRENT_USER | x | x | x | x | | x | x | x | | CURSOR | x | x | x | x | | x | x | x | | CYCLE | x | | | x | | | | | | DATA | | | | x | | | | | | DATABASE | | x | x | x | | x | | | | DATABASES | | x | x | | | | | | | DATAPARTITIONNAME | | | | x | | | | | | DATAPARTITIONNUM | | | | x | | | | | | DATE | x | | | x | x | | x | x | | DAY | x | | | x | | | x | | | DAYS | | | | x | | | | | | DAY_HOUR | | x | x | | | | | | | DAY_MICROSECOND | | x | x | | | | | | | DAY_MINUTE | | x | x | | | | | | | DAY_SECOND | | x | x | | | | | | | DB2GENERAL | | | | x | | | | | | DB2GENRL | | | | x | | | | | | DB2SQL | | | | x | | | | | | DBCC | | | | | | x | | | | DBINFO | | | | x | | | | | | DBPARTITIONNAME | | | | x | | | | | | DBPARTITIONNUM | | | | x | | | | | | DEALLOCATE | x | | | x | | x | x | | | DEC | x | x | x | | | | x | | | DECFLOAT | x | | | | | | | | | DECIMAL | x | x | x | | x | | x | x | | DECLARE | x | x | x | x | | x | x | x | | DEFAULT | x | x | x | x | x | x | x | x | | DEFAULTS | | | | x | | | | | | DEFERRABLE | | | | | | | x | x | | DEFERRED | | | | | | | x | | | DEFINE | x | | | | | | | | | DEFINITION | | | | x | | | | | | DELAYED | | x | x | | | | | | | DELETE | x | x | x | x | x | x | x | x | | DENSERANK | | | | x | | | | | | DENSE_RANK | x | | x | x | | | | x | | DENY | | | | | | x | | | | DEREF | x | | | | | | | | | DESC | | x | x | | x | x | x | x | | DESCRIBE | x | x | x | x | | | x | x | | DESCRIPTOR | | | | x | | | x | | | DETERMINISTIC | x | x | x | x | | | | x | | DIAGNOSTICS | | | | x | | | x | | | DISABLE | | | | x | | | | | | DISALLOW | | | | x | | | | | | DISCONNECT | x | | | x | | | x | | | DISK | | | | | | x | | | | DISTINCT | x | x | x | x | x | x | x | x | | DISTINCTROW | | x | x | | | | | | | DISTRIBUTED | | | | | | x | | | | DIV | | x | x | | | | | | | DO | x | | | x | | | | | | DOCUMENT | | | | x | | | | | | DOMAIN | | | | | | | x | | | DOUBLE | x | x | x | x | | x | x | x | | DO_DOMAIN_IDS | | x | | | | | | | | DROP | x | x | x | x | x | x | x | x | | DSSIZE | | | | x | | | | | | DUAL | | x | x | | | | | | | DUMP | | | | | | x | | | | DYNAMIC | x | | | x | | | | | | EACH | x | x | x | x | | | | x | | EDITPROC | | | | x | | | | | | ELEMENT | x | | | | | | | | | ELSE | x | x | x | x | x | x | x | x | | ELSEIF | x | x | x | x | | | | x | | EMPTY | x | | x | | | | | | | ENABLE | | | | x | | | | | | ENCLOSED | | x | x | | | | | | | ENCODING | | | | x | | | | | | ENCRYPTION | | | | x | | | | | | END | x | | | x | | x | x | x | | END-EXEC | x | | | x | | | x | | | ENDING | | | | x | | | | | | END_FRAME | x | | | | | | | | | END_PARTITION | x | | | | | | | | | EQUALS | x | | | | | | | | | ERASE | | | | x | | | | | | ERRLVL | | | | | | x | | | | ESCAPE | x | | | x | | x | x | x | | ESCAPED | | x | x | | | | | | | EVERY | x | | | x | | | | | | EXCEPT | x | x | x | x | | x | x | x | | EXCEPTION | | | | x | | | | | | EXCEPTION | | | | | | | x | | | EXCLUDING | | | | x | | | | | | EXCLUSIVE | | | | x | x | | | | | EXEC | x | | | | | x | x | | | EXECUTE | x | | | x | | x | x | | | EXISTS | x | x | x | x | x | x | x | x | | EXIT | | x | x | x | | x | | | | EXP | x | | | | | | | | | EXPLAIN | | x | x | x | | | | x | | EXTERNAL | x | | | x | | x | x | | | EXTRACT | x | | | x | | | x | | | FALSE | x | x | x | | | | x | | | FENCED | | | | x | | | | | | FETCH | x | x | x | x | | x | x | x | | FIELDPROC | | | | x | | | | | | FILE | | | | x | x | x | | | | FILLFACTOR | | | | | | x | | | | FILTER | x | | | | | | | | | FINAL | | | | x | | | | | | FIRST | | | | | | | x | | | FIRST_VALUE | x | | x | | | | | | | FLOAT | x | x | x | | x | | x | x | | FLOAT4 | | x | x | | | | | | | FLOAT8 | | x | x | | | | | | | FLOOR | x | | | | | | | | | FOR | x | x | x | x | x | x | x | x | | FORCE | | x | x | | | | | | | FOREIGN | x | x | x | x | | x | x | x | | FORTRAN | | | | | | | x | | | FOUND | | | | | | | x | | | FRAME_ROW | x | | | | | | | | | FREE | x | | | x | | | | | | FREETEXT | | | | | | x | | | | FREETEXTTABLE | | | | | | x | | | | FROM | x | x | x | x | x | x | x | x | | FULL | x | | | x | | x | x | | | FULLTEXT | | x | x | | | | | | | FUNCTION | x | | x | x | | x | | x | | FUSION | x | | | | | | | | | GENERAL | | x | | x | | | | | | GENERATED | | | x | x | | | | | | GET | x | | x | x | | | x | x | | GLOB | | | | | | | | x | | GLOBAL | x | | | x | | | x | | | GO | | | | x | | | x | | | GOTO | | | | x | | x | x | | | GRANT | x | x | x | x | x | x | x | x | | GRAPHIC | | | | x | | | | | | GROUP | x | x | x | x | x | x | x | x | | GROUPING | x | | x | | | | | | | GROUPS | x | | x | | | | | | | HANDLER | x | | | x | | | | | | HASH | | | | x | | | | | | HASHED_VALUE | | | | x | | | | | | HAVING | x | x | x | x | x | x | x | x | | HIGH_PRIORITY | | x | x | | | | | | | HINT | | | | x | | | | | | HOLD | x | | | x | | | | | | HOLDLOCK | | | | | | x | | | | HOUR | x | | | x | | | x | | | HOURS | | | | x | | | | | | HOUR_MICROSECOND | | x | x | | | | | | | HOUR_MINUTE | | x | x | | | | | | | HOUR_SECOND | | x | x | | | | | | | IDENTIFIED | | | | | x | | | | | IDENTITY | x | | | x | | x | x | | | IDENTITYCOL | | | | | | x | | | | IDENTITY_INSERT | | | | | | x | | | | IF | x | x | x | x | | x | | x | | IGNORE | | x | x | | | | | | | IGNORE_DOMAIN_IDS | | x | | | | | | | | IGNORE_SERVER_IDS | | x | | | | | | | | IMMEDIATE | | | | x | x | | x | x | | IN | x | x | x | x | x | x | x | x | | INCLUDE | | | | | | | x | | | INCLUDING | | | | x | | | | | | INCLUSIVE | | | | x | | | | | | INCREMENT | | | | x | x | | | | | INDEX | | x | x | x | x | x | x | x | | INDICATOR | x | | | x | | | x | | | INF | | | | x | | | | | | INFILE | | x | x | | | | | | | INFINITY | | | | x | | | | | | INHERIT | | | | x | | | | | | INITIAL | x | | | | x | | | | | INITIALLY | | | | | | | x | | | INNER | x | x | x | x | | x | x | x | | INOUT | x | x | x | x | | | | x | | INPUT | | | | | | | x | | | INSENSITIVE | x | x | x | x | | | x | x | | INSERT | x | x | x | x | x | x | x | x | | INT | x | x | x | | | | x | | | INT1 | | x | x | | | | | | | INT2 | | x | x | | | | | | | INT3 | | x | x | | | | | | | INT4 | | x | x | | | | | | | INT8 | | x | x | | | | | | | INTEGER | x | x | x | | x | | x | x | | INTEGRITY | | | | x | | | | | | INTERSECT | x | x | | x | x | x | x | x | | INTERSECTION | x | | | | | | | | | INTERVAL | x | x | x | | | | x | | | INTO | x | x | x | x | x | x | x | x | | IO_AFTER_GTIDS | | | x | | | | | | | IO_BEFORE_GTIDS | | | x | | | | | | | IS | x | x | x | x | x | x | x | x | | ISOBID | | | | x | | | | | | ISOLATION | | | | x | | | x | | | ITERATE | x | x | x | x | | | | x | | JAR | | | | x | | | | | | JAVA | | | | x | | | | | | JOIN | x | x | x | x | | x | x | x | | JSON_ARRAY | x | | | | | | | | | JSON_ARRAYAGG | x | | | | | | | | | JSON_EXISTS | x | | | | | | | | | JSON_OBJECT | x | | | | | | | | | JSON_OBJECTAGG | x | | | | | | | | | JSON_QUERY | x | | | | | | | | | JSON_TABLE | x | | x | | | | | | | JSON_TABLE_PRIMITIVE | x | | | | | | | | | JSON_VALUE | x | | | | | | | | | KEEP | | | | x | | | | | | KEY | | x | x | x | | x | x | | | KEYS | | x | x | | | | | | | KILL | | x | x | | | x | | | | LABEL | | | | x | | | | | | LAG | x | | x | | | | | | | LANGUAGE | x | | | x | | | x | | | LARGE | x | | | | | | | | | LAST | | | | | | | x | | | LAST_VALUE | x | | x | | | | | | | LATERAL | x | | | x | | | | | | LC_CTYPE | | | | x | | | | | | LEAD | x | | x | | | | | | | LEADING | x | x | x | | | | x | | | LEAVE | x | x | x | x | | | | x | | LEAVESLEFT | | | x | | | | | | | LEFT | x | x | | x | | x | x | x | | LEVEL | | | | | x | | x | | | LIKE | x | x | x | x | x | x | x | x | | LIKE_REGEX | x | | | | | | | | | LIMIT | | x | x | | | | | x | | LINEAR | | x | x | | | | | | | LINENO | | | | | | x | | | | LINES | | x | x | | | | | | | LINKTYPE | | | | x | | | | | | LN | x | | | | | | | | | LOAD | | x | x | | | x | | | | LOCAL | x | | | x | | | x | | | LOCALDATE | | | | x | | | | | | LOCALE | | | | x | | | | | | LOCALTIME | x | x | x | x | | | | x | | LOCALTIMESTAMP | x | x | x | x | | | | x | | LOCATOR | | | | x | | | | | | LOCATORS | | | | x | | | | | | LOCK | | x | x | x | x | | | | | LOCKMAX | | | | x | | | | | | LOCKSIZE | | | | x | | | | | | LONG | | x | x | x | x | | | | | LONGBLOB | | x | x | | | | | | | LONGTEXT | | x | x | | | | | | | LOOP | x | x | x | x | | | | x | | LOWER | x | | | | | | x | | | LOW_PRIORITY | | x | x | | | | | | | MAINTAINED | | | | x | | | | | | MASTER_BIND | | | x | | | | | | | MASTER_HEARTBEAT_PERIOD | | x | | | | | | | | MASTER_SSL_VERIFY_SERVER_CERT | | x | x | | | | | | | MATCH | x | x | x | | | | x | x | | MATCHES | x | | | | | | | | | MATCH_NUMBER | x | | | | | | | | | MATCH_RECOGNIZE | x | | | | | | | | | MATERIALIZED | | | | x | | | | | | MAX | x | x | | | | | x | | | MAXEXTENTS | | | | | x | | | | | MAXVALUE | | x | x | x | | | | | | MEDIUMBLOB | | x | x | | | | | | | MEDIUMINT | | x | x | | | | | | | MEDIUMTEXT | | x | x | | | | | | | MEMBER | x | | | | | | | | | MERGE | x | | | | | x | | | | METHOD | x | | | | | | | | | MICROSECOND | | | | x | | | | | | MICROSECONDS | | | | x | | | | | | MIDDLEINT | | x | x | | | | | | | MIN | x | | | | | | x | | | MINUS | | | | | x | | | | | MINUTE | x | | | x | | | x | | | MINUTES | | | | x | | | | | | MINUTE_MICROSECOND | | x | x | | | | | | | MINUTE_SECOND | | x | x | | | | | | | MINVALUE | | | | x | | | | | | MLSLABEL | | | | | x | | | | | MOD | x | x | x | | | | | | | MODE | | | | x | x | | | | | MODEMODIFIES | | | x | | | | | | | MODIFIES | x | x | | x | | | | | | MODIFY | | | | | x | | | | | MODULE | x | | | | | | x | | | MONTH | x | | | x | | | x | | | MONTHS | | | | x | | | | | | MULTISET | x | | | | | | | | | NAMES | | | | | | | x | | | NAN | | | | x | | | | | | NATIONAL | x | | | | | x | x | | | NATURAL | x | x | x | | | | x | x | | NCHAR | x | | | | | | x | | | NCLOB | x | | | | | | | | | NESTED_TABLE_ID | | | | | x | | | | | NEW | x | | | x | | | | | | NEW_TABLE | | | | x | | | | | | NEXT | | | | | | | x | | | NEXTVAL | | | | x | | | | | | NO | x | | | x | | | x | | | NOAUDIT | | | | | x | | | | | NOCACHE | | | | x | | | | | | NOCHECK | | | | | | x | | | | NOCOMPRESS | | | | | x | | | | | NOCYCLE | | | | x | | | | | | NODENAME | | | | x | | | | | | NODENUMBER | | | | x | | | | | | NOMAXVALUE | | | | x | | | | | | NOMINVALUE | | | | x | | | | | | NONCLUSTERED | | | | | | x | | | | NONE | x | | | x | | | x | | | NOORDER | | | | x | | | | | | NORMALIZE | x | | | | | | | | | NORMALIZED | | | | x | | | | | | NOT | x | x | x | x | x | x | x | x | | NOTNULL | | | | | | | | x | | NOWAIT | | | | | x | | | | | NO_WRITE_TO_BINLOG | | x | x | | | | | | | NTH_VALUE | x | | x | | | | | | | NTILE | x | | x | | | | | | | NULL | x | x | x | x | x | x | x | x | | NULLIF | x | | | | | x | x | | | NULLS | | | | x | | | | | | NUMBER | | | | | x | | | | | NUMERIC | x | x | x | | | | x | | | NUMPARTS | | | | x | | | | | | OBID | | | | x | | | | | | OCCURRENCES_REGEX | x | | | | | | | | | OCTET_LENGTH | x | | | | | | x | | | OF | x | | x | x | x | x | x | x | | OFF | | | | | | x | | | | OFFLINE | | | | | x | | | | | OFFSET | x | | | | | | | | | OFFSETS | | | | | | x | | | | OLD | x | | | x | | | | | | OLD_TABLE | | | | x | | | | | | OMIT | x | | | | | | | | | ON | x | x | x | x | x | x | x | x | | ONE | x | | | | | | | | | ONLINE | | | | | x | | | | | ONLY | x | | | | | | x | | | OPEN | x | | | x | | x | x | | | OPENDATASOURCE | | | | | | x | | | | OPENQUERY | | | | | | x | | | | OPENROWSET | | | | | | x | | | | OPENXML | | | | | | x | | | | OPTIMIZATION | | | | x | | | | | | OPTIMIZE | | x | x | x | | | | | | OPTIMIZER_COSTS | | | x | | | | | | | OPTION | | x | x | x | x | x | x | | | OPTIONALLY | | x | x | | | | | | | OR | x | x | x | x | x | x | x | x | | ORDER | x | x | x | x | x | x | x | x | | OUT | x | x | x | x | | | | x | | OUTER | x | x | x | x | | x | x | x | | OUTFILE | | x | x | | | | | | | OUTPUT | | | | | | | x | | | OVER | x | x | x | x | | x | | x | | OVERLAPS | x | | | | | | x | | | OVERLAY | x | | | | | | | | | OVERRIDING | | | | x | | | | | | PACKAGE | | | | x | | | | | | PAD | | | | | | | x | | | PADDED | | | | x | | | | | | PAGESIZE | | | | x | | | | | | PAGE_CHECKSUM | | x | | | | | | | | PARAMETER | x | | | x | | | | | | PARSE_VCOL_EXPR | | x | | | | | | | | PART | | | | x | | | | | | PARTIAL | | | | | | | x | | | PARTITION | x | x | x | x | | | | x | | PARTITIONED | | | | x | | | | | | PARTITIONING | | | | x | | | | | | PARTITIONS | | | | x | | | | | | PASCAL | | | | | | | x | | | PASSWORD | | | | x | | | | | | PATH | | | | x | | | | | | PATTERN | x | | | | | | | | | PCTFREE | | | | | x | | | | | PER | x | | | | | | | | | PERCENT | x | | | | | x | | | | PERCENTILE_CONT | x | | | | | | | | | PERCENTILE_DISC | x | | | | | | | | | PERCENT_RANK | x | | x | | | | | | | PERIOD | x | | | | | | | | | PERSIST | | | x | | | | | | | PERSIST_ONLY | | | x | | | | | | | PIECESIZE | | | | x | | | | | | PIVOT | | | | | | x | | | | PLAN | | | | x | | x | | | | PORTION | x | | | | | | | | | POSITION | x | | | x | | | x | | | POSITION_REGEX | x | | | | | | | | | POWER | x | | | | | | | | | PRAGMA | | | | | | | | x | | PRECEDES | x | | | | | | | | | PRECISION | x | x | x | x | | x | x | x | | PREPARE | x | | | x | | | x | | | PRESERVE | | | | | | | x | | | PREVVAL | | | | x | | | | | | PRIMARY | x | x | x | x | | x | x | x | | PRINT | | | | | | x | | | | PRIOR | | | | | x | | x | | | PRIQTY | | | | x | | | | | | PRIVILEGES | | | | x | | | x | | | PROC | | | | | | x | | | | PROCEDURE | x | x | x | x | | x | x | x | | PROGRAM | | | | x | | | | | | PSID | | | | x | | | | | | PUBLIC | | | | x | x | x | x | | | PURGE | | x | x | | | | | | | QUERY | | | | x | | | | | | QUERYNO | | | | x | | | | | | RAISERROR | | | | | | x | | | | RANGE | x | x | x | x | | | | x | | RANK | x | | x | x | | | | x | | RAW | | | | | x | | | | | READ | | x | x | x | | x | x | | | READS | x | x | x | x | | | | x | | READTEXT | | | | | | x | | | | READ_WRITE | | x | x | | | | | | | REAL | x | x | x | | | | x | | | RECONFIGURE | | | | | | x | | | | RECOVERY | | | | x | | | | | | RECURSIVE | x | x | x | | | | | x | | REF | x | | | | | | | | | REFERENCES | x | x | x | x | | x | x | x | | REFERENCING | x | | | x | | | | | | REFRESH | | | | x | | | | | | REF_SYSTEM_ID | | x | | | | | | | | REGEXP | | x | x | | | | | x | | REGR_AVGX | x | | | | | | | | | REGR_AVGY | x | | | | | | | | | REGR_COUNT | x | | | | | | | | | REGR_INTERCEPT | x | | | | | | | | | REGR_R2 | x | | | | | | | | | REGR_SLOPE | x | | | | | | | | | REGR_SXX | x | | | | | | | | | REGR_SXY | x | | | | | | | | | REGR_SYY | x | | | | | | | | | REINDEX | | | | | | | | x | | RELATIVE | | | | | | | x | | | RELEASE | x | x | x | x | | | | x | | RENAME | | x | x | x | x | | | x | | REPEAT | x | x | x | x | | | | x | | REPEATABLEREPLACE | | | x | | | | | | | REPLACE | | x | | | | | | x | | REPLICATION | | | | | | x | | | | REQUIRE | | x | x | | | | | | | RESET | | | | x | | | | | | RESIGNAL | x | x | x | x | | | | x | | RESOURCE | | | | | x | | | | | RESTART | | | | x | | | | | | RESTORE | | | | | | x | | | | RESTRICT | | x | x | x | | x | x | | | RESULT | x | | | x | | | | | | RESULT_SET_LOCATOR | | | | x | | | | | | RETURN | x | x | x | x | | x | | x | | RETURNING | | x | | | | | | | | RETURNS | x | | | x | | | | | | REVERT | | | | | | x | | | | REVOKE | x | x | x | x | x | x | x | x | | RIGHT | x | x | x | x | | x | x | x | | RLIKE | | x | x | | | | | | | ROLE | | | | x | | | | | | ROLLBACK | x | | | x | | x | x | x | | ROLLUP | x | | | | | | | | | ROUND_CEILING | | | | x | | | | | | ROUND_DOWN | | | | x | | | | | | ROUND_FLOOR | | | | x | | | | | | ROUND_HALF_DOWN | | | | x | | | | | | ROUND_HALF_EVEN | | | | x | | | | | | ROUND_HALF_UP | | | | x | | | | | | ROUND_UP | | | | x | | | | | | ROUTINE | | | | x | | | | | | ROW | x | | x | x | x | | | x | | ROWCOUNT | | | | | | x | | | | ROWGUIDCOL | | | | | | x | | | | ROWID | | | | | x | | | | | ROWNUM | | | | | x | | | | | ROWNUMBER | | | | x | | | | | | ROWS | x | x | x | x | x | | x | x | | ROWSET | | | | x | | | | | | ROW_NUMBER | x | | x | x | | | | x | | RRN | | | | x | | | | | | RULE | | | | | | x | | | | RUN | | | | x | | | | | | RUNNING | x | | | | | | | | | SAVE | | | | | | x | | | | SAVEPOINT | x | | | x | | | | x | | SCHEDULESCHEMA | | | x | | | | | | | SCHEMA | | x | | x | | x | x | | | SCHEMAS | | x | x | | | | | | | SCOPE | x | | | | | | | | | SCRATCHPAD | | | | x | | | | | | SCROLL | x | | | x | | | x | | | SEARCH | x | | | x | | | | | | SECOND | x | | | x | | | x | | | SECONDS | | | | x | | | | | | SECOND_MICROSECOND | | x | x | | | | | | | SECQTY | | | | x | | | | | | SECTION | | | | | | | x | | | SECURITY | | | | x | | | | | | SECURITYAUDIT | | | | | | x | | | | SEEK | x | | | | | | | | | SELECT | x | x | x | x | x | x | x | x | | SEMANTICKEYPHRASETABLE | | | | | | x | | | | SEMANTICSIMILARITYDETAILSTABLE | | | | | | x | | | | SEMANTICSIMILARITYTABLE | | | | | | x | | | | SENSITIVE | x | x | x | x | | | | x | | SEPARATOR | | x | x | | | | | | | SEQUENCE | | | | x | | | | | | SESSION | | | | x | x | | x | | | SESSION_USER | x | | | x | | x | x | | | SET | x | x | x | x | x | x | x | x | | SETUSER | | | | | | x | | | | SHARE | | | | | x | | | | | SHOW | x | x | x | | | | | | | SHUTDOWN | | | | | | x | | | | SIGNAL | x | x | x | x | | | | x | | SIMILAR | x | | | | | | | | | SIMPLE | | | | x | | | | | | SIZE | | | | | x | | x | | | SKIP | x | | | | | | | | | SLOW | | x | | | | | | | | SMALLINT | x | x | x | | x | | x | x | | SNAN | | | | x | | | | | | SOME | x | | | x | | x | x | | | SOURCE | | | | x | | | | | | SPACE | | | | | | | x | | | SPATIAL | | x | x | | | | | | | SPECIFIC | x | x | x | x | | | | x | | SPECIFICTYPE | x | | | | | | | | | SQL | x | x | x | x | | | x | x | | SQLCA | | | | | | | x | | | SQLCODE | | | | | | | x | | | SQLERROR | | | | | | | x | | | SQLEXCEPTION | x | x | x | | | | | | | SQLID | | | | x | | | | | | SQLSTATE | x | x | x | | | | x | | | SQLWARNING | x | x | x | | | | x | | | SQL_BIG_RESULT | | x | x | | | | | | | SQL_CALC_FOUND_ROWS | | x | x | | | | | | | SQL_SMALL_RESULT | | x | x | | | | | | | SQRT | x | | | | | | | | | SSL | | x | x | | | | | | | STACKED | | | | x | | | | | | STANDARD | | | | x | | | | | | START | x | | | x | x | | | x | | STARTING | | x | x | x | | | | | | STATEMENT | | | | x | | | | | | STATIC | x | | | x | | | | | | STATISTICS | | | | | | x | | | | STATMENT | | | | x | | | | | | STATS_AUTO_RECALC | | x | | | | | | | | STATS_PERSISTENT | | x | | | | | | | | STATS_SAMPLE_PAGES | | x | | | | | | | | STAY | | | | x | | | | | | STDDEV_POP | x | | | | | | | | | STDDEV_SAMP | x | | | | | | | | | STOGROUP | | | | x | | | | | | STORED | | | x | | | | | | | STORES | | | | x | | | | | | STRAIGHT_JOIN | | x | x | | | | | | | STYLE | | | | x | | | | | | SUBMULTISET | x | | | | | | | | | SUBSET | x | | | | | | | | | SUBSTRING | x | | | x | | | x | | | SUBSTRING_REGEX | x | | | | | | | | | SUCCEEDS | x | | | | | | | | | SUCCESSFUL | | | | | x | | | | | SUM | x | | | | | | x | | | SUMMARY | | | | x | | | | | | SYMMETRIC | x | | | | | | | | | SYNONYM | | | | x | x | | | | | SYSDATE | | | | | x | | | | | SYSFUN | | | | x | | | | | | SYSIBM | | | | x | | | | | | SYSPROC | | | | x | | | | | | SYSTEM | x | | x | x | | | | x | | SYSTEM_TIME | x | | | | | | | | | SYSTEM_USER | x | | | x | | x | x | | | SYS_* | | | | | x | | | | | TABLE | x | x | x | x | x | x | x | x | | TABLESAMPLE | x | | | | | x | | | | TABLESPACE | | | | x | | | | | | TEMPORARY | | | | | | | x | | | TERMINATED | | x | x | | | | | | | TEXTSIZE | | | | | | x | | | | THEN | x | x | x | x | x | x | x | x | | TIME | x | | | x | | | x | | | TIMESTAMP | x | | | x | | | x | | | TIMEZONE_HOUR | x | | | | | | x | | | TIMEZONE_MINUTE | x | | | | | | x | | | TINYBLOB | | x | x | | | | | | | TINYINT | | x | x | | | | | | | TINYTEXT | | x | x | | | | | | | TO | x | x | x | x | x | x | x | x | | TOP | | | | | | x | | | | TRAILING | x | x | x | | | | x | | | TRAN | | | | | | x | | | | TRANSACTION | | | | x | | x | x | x | | TRANSLATE | x | | | | | | x | | | TRANSLATE_REGEX | x | | | | | | | | | TRANSLATION | x | | | | | | x | | | TREAT | x | | | | | | | | | TRIGGER | x | x | x | x | x | x | | x | | TRIM | x | | | x | | | x | | | TRIM_ARRAY | x | | | | | | | | | TRUE | x | x | x | | | | x | | | TRUNCATE | x | | | x | | x | | | | TRY_CONVERT | | | | | | x | | | | TSEQUAL | | | | | | x | | | | TYPE | | | | x | | | | | | UESCAPE | x | | | | | | | | | UID | | | | | x | | | | | UNDO | | x | x | x | | | | | | UNION | x | x | x | x | x | x | x | x | | UNIQUE | x | x | x | x | x | x | x | x | | UNKNOWN | x | | | | | | x | | | UNLOCK | | x | x | | | | | | | UNNEST | x | | | | | | | | | UNPIVOT | | | | | | x | | | | UNSIGNED | | x | x | | | | | | | UNTIL | x | | | x | | | | | | UPDATE | x | x | x | x | x | x | x | x | | UPDATETEXT | | | | | | x | | | | UPPER | x | | | | | | x | | | USAGE | | x | x | x | | | x | | | USE | | x | x | | | x | | | | USER | x | | | x | x | x | x | x | | USING | x | x | x | x | | | x | x | | UTC_DATE | | x | x | | | | | | | UTC_TIME | | x | x | | | | | | | UTC_TIMESTAMP | | x | x | | | | | | | VALIDATE | | | | | x | | | | | VALIDPROC | | | | x | | | | | | VALUE | x | | | x | | | x | | | VALUES | x | x | x | x | x | x | x | x | | VALUE_OF | x | | | | | | | | | VARBINARY | x | x | x | | | | | | | VARCHAR | x | x | x | | x | | x | x | | VARCHAR2 | | | | | x | | | | | VARCHARACTER | | x | x | | | | | | | VARIABLE | | | | x | | | | | | VARIANT | | | | x | | | | | | VARYING | x | x | x | | | x | x | | | VAR_POP | x | | | | | | | | | VAR_SAMP | x | | | | | | | | | VCAT | | | | x | | | | | | VERSION | | | | x | | | | | | VERSIONING | x | | | | | | | | | VIEW | | | | x | x | x | x | x | | VIRTUAL | | | x | | | | | | | VOLATILE | | | | x | | | | | | VOLUMES | | | | x | | | | | | WAITFOR | | | | | | x | | | | WHEN | x | x | x | x | | x | x | x | | WHENEVER | x | | | x | x | | x | x | | WHERE | x | x | x | x | x | x | x | x | | WHILE | x | x | x | x | | x | | x | | WIDTH_BUCKET | x | | | | | | | | | WINDOW | x | x | x | | | | | | | WITH | x | x | x | x | x | x | x | x | | WITHIN | x | | | | | | | | | WITHIN GROUP | | | | | | x | | | | WITHOUT | x | | | x | | | | x | | WLM | | | | x | | | | | | WORK | | | | | | | x | | | WRITE | | x | x | x | | | x | | | WRITETEXT | | | | | | x | | | | XMLELEMENT | | | | x | | | | | | XMLEXISTS | | | | x | | | | | | XMLNAMESPACES | | | | x | | | | | | XOR | | x | x | | | | | | | YEAR | x | | | x | | | x | | | YEARS | | | | x | | | | | | YEAR_MONTH | | x | x | | | | | | | ZEROFILL | | x | x | | | | | | | ZONE | | | | | | | x | | +----------------------------------+-----+-----+-----+-----+-----+-----+-----+-----+
MySQL, MariaDB, International Components for Unicode
In an earlier blog post I wrote “MySQL has far better support for character sets and collations than any other open-source DBMS, except sometimes MariaDB.”
That’s no longer always true, because ICU.
ICU — International Components for Unicode — was a Sun + IBM initiative that started over 20 years ago, and has become a major component of major products. The key advantage is that it provides a lax-licensed library that does all the work that’s needed for the Unicode Collation ALgorithm and the CLDRs. No competitive products do that.
When I was with MySQL we considered using ICU. We decided “no”. We had good reasons then: it didn’t do anything new for the major languages that we already handled well, it seemed to change frequently, we preferred to listen to our user base, there wasn’t a big list of appropriate rules in a “Common Locale Data Repository” (CLDR) in those days, we expected it to be slow, we worried about the license, and it was quite large. But since then the world has moved on.
The support for ICU among DBMSs
ICU is an essential or an optional part of many products (they’re listed on the ICU page in section “who uses”). So there’s no problem finding it in Lucene, PHP 6, or a major Linux distro. But our main concern is DBMSs.
DB2 total support, IBM is an ICU evangelist
Firebird total support
SQLite optional support (you have to download and recompile yourself)
CouchDB you're supposed to download ICU but
you seem to have choices
Sybase IQ for sortkeys and for Thai
PostgreSQL catches up?
MySQL/MariaDB have their own code for collations while PostgreSQL depends on the operating system’s libraries (libc etc.) to do all its collating with strcoll(), strxfrm(), and equivalents. PostgreSQL is inferior for these reasons:
(1) when the operating system is upgraded your indexes might become corrupt because now the keys aren’t where they’re supposed to be according to the OS’s new rules, and you won’t be warned. For a typical horror story see here.
(2) libc had problems and it still does, for example see the bug report “strxfrm results do not match strcoll”.
(3) libc is less sophisticated than ICU, for example towupper() looks at only one character at a time (sometimes capitalization should be affected by prior or following characters)
(4) ORDER BY worked differently on Windows than on Linux.
(5) Mac OS X in particular, and sometimes BSD, caused surprise when people found they lacked what libc had in Linux. Sample remarks: “you will have to realize that collations will not work on any BSD-ish OS (incl. OSX) for an UTF8 encoding.”, and “It works fine if you use the English language, or if you don’t use utf-8.”
I’ve observed before that sometimes MySQL is more standards-compliant than PostgreSQL and this PostgreSQL behaviour is consistent with that observation. Although some people added or suggested ICU patches — EnterpriseDB and Postgresapp come to mind — those were improvements that didn’t become part of the main line.
In August 2016 a well-known PostgreSQL developer proposed a patch in a thread titled ICU integration. Many others jumped in with support or with rather intelligent criticisms. In March 2017 the well-known developer posted the dread word “Committed”. Hurrahs followed. Sample remark: “Congratulations on getting this done. It’s great work, and it’ll make a whole class of potential bugs and platform portability warts go away if widely adopted.”
This doesn’t destroy all of MySQL/MariaDB’s advantages in the collation area — a built-in bespoke routine will probably be faster than a generic one that’s bloated with checks for things that will never happen, and PostgreSQL perhaps can’t do case insensitive ordering without using upper(), and the ICU approach forces some hard trade-off decisions, as we’ll see. But the boast “Only MySQL has consistent per-column collation support for multiple languages and multiple platforms” will lose sting.
The problems
If MySQL and/or MariaDB decided to add ICU to their existing collation support, what problems would they face?
LICENSE.
The licence has changed recently, now it is a “Unicode license”. You have to acknowledge the copyright and permission everywhere. It is compatible with GPL with some restrictions that shouldn’t matter. So whatever license problems existed (I forget what they were) are gone.
SIZE.
The Fedora .tgz file is 15MB, the Windows zip file is 36 MB. The executables are a bit smaller, but you get the idea — it takes longer to download and takes more storage space. For SQLite this was frightening because its applications embed the library, but to others this doesn’t look like a big deal in the era of multi-gigabyte disk drives. The other consideration is that the library might already be there — it’s optional for many Linux packages (I’d also seen a report that it would be the norm in FreeBSD 11 but I didn’t find it in the release notes).
SPEED.
According to ICU’s own tests ICU can be faster than glibc. According to EnterpriseDB a sort or an index-build can be twice as fast with ICU as without it I’d be surprised if it ever beats MySQL/MariaDB’s built-in code, but that’s not a factor — the built-in collations would stay. These tests just establish that the new improved ones would be at least passable.
CLIENTS.
One of the PostgreSQL folks worried about ICU because the results coming from the DBMS might not match what the results would be if they used strcoll() in their C programs and lc in their directory searches. But I’ve never heard of anyone having a problem with this in MySQL, which has never used the same algorithms as strcoll().
DISTROS.
If an open-source application comes via a distro, it might have to accept the ICU version that comes with the distro. That’s caused problems for Firebird and it’s caused fear that you can’t bundle your own ICU (“RH [Red Hat] and Debian would instantly rip it out and replace it with their packaged ICU anyway” was one comment on the PostgreSQL thread). EnterpriseDB did bundle, but they had to, because RHEL 6 had a uselessly old (4.2) ICU version on it. Ordinarily this means that the DBMS vendor does not have total control over what ICU version it will use.
RULE CHANGES.
If you can’t bundle a specific version of ICU and freeze it, you have to worry: what if the collation rules change? I mentioned before how this frightened us MySQL oldies. For example, in early versions of the Unicode Collation Algorithm (what ICU implements), the Polish L-with-slash moved (ah, sweet memories of bygone bogus bug reports). and Upper(German Sharp S) changed (previously ß had no upper case). Such changes would have caused disasters if we’d used ICU in those days: indexes would have keys in the wrong order, CHECK clauses (if we’d had them) would have variable meaning, and some rows could be in different partitions.
But it’s been years since a movement of a modern letter happened in a major European language. Look at the “Migration issues” that are described in the Unicode Collation Algorithm document:
UCA 6.1.0 2012-02-01 -- added the ignoreSP option
added an option for parametric tailoring
UCA 6.3.0 2013-08-13 -- removed the ignoreSP option
changed weight of U+FFFD
removed fourth-level weights
UCA 7.0.0 2014-05-23 -- clarifications of the text description
UCA 8.0.0 2015-06-01 -- removed contractions for Cyrillic accent letters except Й
UCA 9.0.0 2016-05-18 -- added support for Tangut weights
… If none of these match your idea of an issue, you probably don’t have an issue. Plus you have a guarantee: “The contents of the DUCET [Default Unicode Collation Element Table which has the root collation for every character] will remain unchanged in any particular version of the UCA.” That’s wonderful because the DUCET is good for most languages; only the tailorings — the special-purpose specifications in the CLDR — seem to see changes with every release. But if you have them, I guess you would have to say:
* If there’s an upgrade and the ICU version number is new, check indexes are in order
* If there’s a network, the ICU version should be the same on all nodes, i.e. upgrade everything together
* Don’t store weights (the equivalent of what strxfrm produces) as index keys.
Other news: there is no new release of Ocelot’s GUI client for MySQL + MariaDB (ocelotgui) this month, but a few program changes have been made for those who download the source from github.
Binary Serializers
DBMS client applications need to store SQL query results in local memory or local files. The format is flat and the fields are ordered — that’s “serialization”. The most important serializer format uses human-readable markup, like
[start of field] [value] [end of field]
and the important ones in the MySQL/MariaDB world are CSV (what you get with SELECT … INTO OUTFILE or LOAD INFILE), XML (what you get with –xml or LOAD XML), and JSON (for which there are various solutions if you don’t use MySQL 5.7).
The less important serializer format uses length, like
[length of value] [value]
and this, although it has the silly name “binary serialization”, is what I want to talk about.
The length alone isn’t enough, we also need to know the type, so we can decode it correctly. With CSV there are hints such as “is the value enclosed in quotes”, but with binary serializers the value contains no hints. There has to be an indicator that says what the type is. There might be a single list of types for all of the records, in which case the format is said to “have a schema”. Or there might be a type attached to each record, like
[type] [length of value] [value]
in which case the format is often called “TLV” (type-length-value).
Binary serializers are better than markup serializers if you need “traversability” — the ability to skip to field number 2 without having to read every byte in field number 1. Binary TLV serializers are better than binary with-schema serializers if you ned “flexibility” — when not every record has the same number of fields and not every field has the same type. But of course TLV serializers might require slightly more space.
A “good” binary serializer will have two Characteristics:
#1 It is well known, preferably a standard with a clear specification, but otherwise a commonly-used format with a big sponsor. Otherwise you have to write your own library and you will find out all the gotchas by re-inventing a wheel. Also, if you want to ship your file for import by another application, it would be nice if the other application knew how to import it.
#2 It can store anything that comes out of MySQL or MariaDB.
Unfortunately, as we’ll see, Characteristic #1 and Characteristic #2 are contradictory. The well-known serializers usually were made with the objective of storing anything that comes out of XML or JSON, or that handled quirky situations when shipping over a wire. So they’re ready for things that MySQL and MariaDB don’t generate (such as structured arrays) but not ready for things that MySQL and MariaDB might generate (such as … well, we’ll see as I look at each serializer).
To decide “what is well known” I used the Wikipedia article Comparison of data serialization formats. It’s missing some formats (for example sereal) but it’s the biggest list I know of, from a source that’s sometimes neutral. I selected the binary serializers that fit Characteristic #1. I evaluated them according to Characteristic #2.
I’ll look at each serializer. Then I’ll show a chart. Then you’ll draw a conclusion.
Avro
Has schemas. Not standard but sponsored by Apache.
I have a gripe. Look at these two logos. The first one is for the defunct British/Canadian airplane maker A.V.Roe (from Wikipedia). The second one is for the binary serializer format Apache Avro (from their site).


Although I guess that the Apache folks somehow have avoided breaking laws, I think that taking A.V.Roe’s trademark is like wearing medals that somebody else won. But putting my gripe aside, let’s look at a technical matter.
The set of primitive type names is:
null: no value
Well, of course, in SQL a NULL is not a type and it is a value. This is not a showstopper, because I can declare a union of a null type and a string type if I want to allow nulls and strings in the same field. Um, okay. But then comes the encoding rule:
null is written as zero bytes.
I can’t read that except as “we’re like Oracle 12c, we think empty strings are NULLs”.
ASN.1
TLV. Standard.
ASN means “abstract syntax notation” but there are rules for encoding too, and ASN.1 has a huge advantage: it’s been around for over twenty years. So whenever any “why re-invent the wheel?” argument starts up on any forum, somebody is bound to ask why all these whippersnapper TLVs are proposed considering ASN.1 was good enough for grand-pappy, eh?
Kidding aside, it’s a spec that’s been updated as recently as 2015. As usual with official standards, it’s hard to find a free-and-legitimate copy, but here it is: the link to a download of “X.690 (08/2015) ITU-T X.690 | ISO/IEC 8825-1 ISO/IEC 8825-1:2015 Information technology — ASN.1 encoding rules: Specification of Basic Encoding Rules (BER), Canonical Encoding Rules (CER) and Distinguished Encoding Rules (DER)” from the International Telecommunication Union site: http://www.itu.int/rec/T-REC-X.690-201508-I/en.
It actually specifies how to handle exotic situations, such as
** If it is a “raw” string of bits, are there unused bits in the final byte?
** If the string length is greater than 2**32, is there a way to store it?
** Can I have a choice between BMP (like MySQL UCS2) and UTF-8 and other character sets?
** Can an integer value be greater than 2**63?
… You don’t always see all these things specified except in ASN.1.
Unfortunately, if you try to think of everything, your spec will be large and your overhead will be large, so competitors will appear saying they have something “simpler” and “more compact”. Have a look at trends.google.com to see how ASN.1 once did bestride the narrow world like a colossus, but nowadays is not more popular than all the others.
BSON
TLV. Sponsored by MongoDB.
Although BSON is “used mainly as a data storage and network transfer format in the MongoDB [DBMS]”, anybody can use it. There’s a non-Mongo site which refers to independent libraries and discussion groups.
BSON is supposed to make you think “binary JSON” but in fact all the binary serializers that I’m discussing (and I few that I’m not discussing such as UBJSON) can do a fair job of representing JSON-marked-up-text in binary format. Some people even claim that MessagePack does a better job of that than BSON does.
There is a “date” but it is milliseconds since the epoch, so it might be an okay analogue for MySQL/MariaDB TIMESTAMP but not for DATETIME.
CBOR
TLV. Proposed standard.
CBOR is not well known but there’s an IETF Internet Standards Document for it (RFC 7049 Concise Binary Object Representation), so I reckoned it’s worth looking at. I don’t give that document much weight, though — it has been in the proposal phase since 2013.
The project site page mentions JSON data model, schemalessness, raw binary strings, and concise encoding — but I wanted to see distinguishing features. There are a few.
I was kind of surprised that there are two “integer” types: one type is positive integers, the other type is negative integers.
In other words -5 is
[type = negative number] [length] [value = 5]
rather than the Two’s Complement style
[type = signed number] [length] [value = -5]
but that’s just an oddness rather than a problem.
There was an acknowledgment in the IETF document that “CBOR is inspired by MessagePack”. But one of MessagePack’s defects (the lack of a raw string type) has been fixed now. That takes away one of the reasons that I’d have for regarding CBOR as a successor to MessagePack.
Fast Infoset
TLV. Uses a standard.
After seeing so much JSON, it’s nice to run into an international standard that specifies a binary encoding format for the XML Information Set (XML Infoset) as an alternative to the XML document format”. Okay, they get points for variety.
However, it’s using ASN.1’s underlying encoding methods, so I won’t count it as a separate product.
MessagePack
TLV. Not standard but widely used.
MessagePack, also called MsgPack, is popular and is actually used as a data storage format for Pinterest and Tarantool.
It’s got a following among people who care a lot about saving bytes; for example see this Uber survey where MessagePack beat out some of the other formats that I’m looking at here.
One of the flaws of MessagePack, from my point of view, is its poor handling for character sets other than UTF-8. But I’ll admit: when MessagePack’s original author is named Sadayuki Furuhashi, I’m wary about arguing that back in Japan UTF-8 is not enough. For some of the arguing that happened about supporting other character sets with MessagePack, see this thread. Still, I think my “The UTF-8 world is not enough” post is valid for the purposes I’m discussing.
And the maximum length of a string is 2**32-1 bytes, so you can forget about dumping a LONGBLOB. I’d have the same trouble with BSON but BSON allows null-terminated strings.
OPC-UA
TLV. Sort of a standard for a particular industry group.
Open Platform Communications – Unified Architecture has a Binary Encoding format.
Most of the expected types are there: boolean, integer, float, double, string, raw string, and datetime. The datetime description is a bit weird though: number of 100 nanosecond intervals since January 1, 1601 (UTC). I’ve seen strange cutover dates in my time, but this is a new one for me.
For strings, there’s a way to indicate NULLs (hurrah).
I have the impression that OPC is an organization for special purposes (field devices, control systems, etc.) and I’m interested in general-purpose formats, so didn’t look hard at this.
Protocol Buffers
Has schemas. Not standard but sponsored by Google.
Like Avro, Google’s Protocol Buffers have a schema for the type and so they are schema + LV rather than TLV. But MariaDB uses them for its Dynamic Columns feature, so everybody should know about them.
Numbers and strings can be long, but there’s very little differentiation — essentially you have integers, double-precision floating point numbers, and strings. So, since I was objecting earlier when I saw that other serialization formats didn’t distinguish (say) character sets, I have to be fair and say: this is worse. When the same “type” tag can be used for multiple different types, it’s not specific enough.
Supposedly the makers of Protocol Buffers were asked why they didn’t use ASN.1 and they answered “We never heard of it before”. That’s from a totally unreliable biased source but I did stop and ask myself: is that really so unbelievable? In this benighted age?
Thrift
Can be TLV but depends on protocol. Not standard but sponsored by Apache, used a lot by Facebook.
I looked in vain for what one might call a “specification” of Thrift’s binary serialization, and finally found an old stackoverflow discussion that said: er, there isn’t any. There’s a “Thrift Missing Guide” that tells me the base types, and a Java class describer for one of the protocols to help me guess the size limits.
Thrift’s big advantage is that it’s language neutral, which is why it’s popular and there are many libraries and high-level tutorials. That makes it great as a communication format, which is what it’s supposed to be. However, the number of options is small and the specification is so vague that I can’t call it “good” according to the criteria I stated earlier.
The Chart
I depend on each serializer’s specification, I didn’t try anything out, I could easily have made some mistakes.
For the “NULL is a value” row, I say No (and could have added “Alackaday!”) for all the formats that say NULL is a data type. Really the only way to handle NULL is with a flag so this would be best:
[type] [length] [flag] [value]
and in fact, if I was worried about dynamic schemas, I’d be partial to Codd’s “two kinds of NULLs” arguments, in case some application wanted to make a distinction between not-applicable-value and missing-value.
For most of the data-type rows, I say Yes for all the formats that have explicit defined support. This does not mean that it’s impossible to store the value — for example it’s easy to store a BOOLEAN with an integer or with a user-defined extension — but then you’re not using the format specification so some of its advantages are lost.
For dates (including DATETIME TIMESTAMP DATE etc.), I did not worry if the precision and range were less than what MySQL or MariaDB can handle. But for DECIMAL, i say No if the maximum number of digits is 18 or if there are no post-decimal digits.
For LONGBLOB, I say No if the maximum number of bytes is 2**32.
For VARCHAR, I say Yes if there’s any way to store any encoded characters (rather than just bytes, which is what BINARY and BLOB are). In the “VARCHAR+” row I say Yes if there is more than one character set, although this doesn’t mean much — the extra character sets don’t match with MySQL/MariaDB’s variety.
I’ll say again that specifications allow for “extensions”, for example with ASN.1 you can define your own tags, but I’m only looking at what’s specific in the specification.
| Avro | ASN.1 | BSON | CBOR | Message Pack | OPC UA | Protocol Buffers | Thrift | |
|---|---|---|---|---|---|---|---|---|
| NULL is a value | no | no | no | no | no | YES | no | no |
| BOOLEAN | YES | YES | YES | YES | YES | YES | no | YES |
| INTEGER | YES | YES | YES | YES | YES | YES | YES | YES |
| BIGINT | YES | YES | YES | YES | YES | YES | YES | YES |
| FLOAT | YES | YES | YES | YES | YES | YES | no | no |
| DOUBLE | YES | YES | YES | YES | YES | YES | YES | YES |
| BINARY / BLOB | YES | YES | YES | YES | YES | YES | YES | YES |
| VARCHAR | YES | YES | YES | YES | YES | YES | no | YES |
| Dates | no | YES | YES | YES | no | YES | no | no |
| LONGBLOB | YES | YES | no | YES | no | no | YES | no |
| DECIMAL | no | YES | no | YES | no | no | no | no |
| VARCHAR+ | no | YES | no | no | no | YES | no | no |
| BIT | no | YES | no | no | no | no | no | no |
Your Conclusion
You have multiple choice:
(1) Peter Gulutzan is obsessed with standards and exactness,
(2) Well, might as well use one of these despite its defects
(3) We really need yet another binary serializer format.
ocelotgui news
Recently there were some changes to the ocelot.ca site to give more prominence to the ocelotgui manual, and a minor release — ocelotgui version 1.02 — happened on August 15.
Releasing ocelotgui 1.0.0
Today ocelotgui, the Ocelot Graphical User Interface for MySQL and MariaDB, version 1.0.0, is generally available for Linux. Read the manual, see the screenshots, and download binary (.deb or .rpm) packages and GPL-licensed C++ source here.
Client-Side Predictive Parsing of MySQL/MariaDB Grammar
The Ocelot GUI client for MySQL/MariaDB is now beta. The final feature is client-side predictive parsing of every SQL clause and statement. Readers who only care how we did it can skip to the section Recursive Descent Parsers”. I’ll start by illustrating why this is a good feature.
Error Checks
Compare this snapshot from mysql client:

with this from ocelotgui:
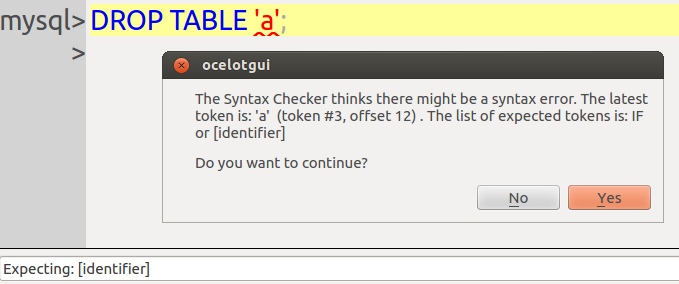
The GUI advantage is that the error message is more clear and the error location is more definite. This is not always true. However, anybody who dislikes the famous message “You have an error …” should like that there is another way to hear the bad news. It’s like getting an extra opinion.
In theory the further advantage is: this saves time on the server, because the client catches the syntax errors. In practice that should not be important, because: (a) ocelotgui is lax and can be erroneous; (b) there are better ways to catch some syntax errors before sending them to the server, for example setting up a test machine.
Finding the end
All respectable clients can scan an SQL statement to find its tokens. For example the mysql client knows that anything enclosed in quote marks, except a pair of quote marks, is a single token. This is pretty well essential, because it has to know whether a semicolon is just part of a string, or is the end of a statement.
Unfortunately a semicolon might not be the end of a compound statement, and that’s where simple “tokenizers” like mysql’s can’t cope. So in my MySQL days we had to come up with the concept of delimiters (I say “we” because I think the hassle of delimiters might have been my idea, but others are welcome to take the credit). It should be clear that a statement like
CREATE PROCEDURE p() BEGIN WHILE 0 = 0 DO ... END WHILE;
is not complete and should not go to the server, so it’s nice that we can say we don’t need delimiters.
But they still can have their uses. The scenario I dread is that a user has a spelling error, causing the client to think that input is complete, and shipping it off to the server prematurely. If there was some symbol that always meant “ship it!” and no other symbol ever meant “ship it!”, that would become unlikely. That’s what delimiters are. But we should have decided on a fixed unchangeable symbol instead of a user-defined one.
Highlighting
All respectable GUIs have highlighting, that is, they can display different colours for literals, operators, or keywords. But most GUIs cannot figure out what is a keyword, unless they ask the MySQL-server’s parser. The SQL problem is that there are two kinds of keywords: reserved words (which are guaranteed to have syntactic meaning if they’re not errors), and ordinary keywords (which might have syntactic meaning but might be identifiers, depending where they appear). An example statement is
CREATE PROCEDURE begin () end: BEGIN END;
where “end” and “begin” are identifiers, but BEGIN and END are not.
(A much easier problem is that you’d need two keyword lists, because in MySQL 5.7 GENERATED and GET and IO_AFTER_GTIDS and IO_BEFORE_GTIDS and MASTER_BIND and STORED and VIRTUAL are reserved words, but in MariaDB they’re not. But, since we don’t think the MariaDB manual’s reserved-word list is correct, we think those are the only reserved-word differences.)
So we have to beware of anything that depends on a list of keywords. For example my favoured editor is a variant of Kate, which recognizes a hodgepodge of symbols in its “SQL Keyword” list, and displays utterly useless highlighting when my file’s extension is .sql. Apparently Vim would be similar. Most clients that claim to work with MySQL or MariaDB are better than editors — they at least use a DBMS-specific keyword list rather than a generic one — and they’re generally good because in a sense they train users not to use keywords as identifiers. For example, if users see that “begin” has a non-identifier colour while they’re typing, they’ll avoid creating objects named “begin” even though it’s not a reserved word.
I’m not sure whether, in the wider SQL world, well known GUI clients have advanced past the keyword-list stage. I see hints here and there that SQL Server Management Studio has not and Toad has not, and Oracle SQL Developer has, but nothing explicit, and I repeat I’m not sure.
(UPDATE 2016-03-28: Mike Lischke’s description of Oracle’s new approach is here.)
In the end, then, a GUI with keyword-list highlighting will be right 90% of the time (I’m just guessing here, but I think it will sound right to experienced readers). On the other hand, a GUI that recognizes grammar should be right 97% of the time, and — just guessing again — I expect that’s preferable.
Predicting
The next step upwards in intelligence is knowing what the next token might be before the user starts typing it, or knowing how the current token ends before the user finishes typing it. And here, if you contemplate the Error Message example that we started with, you might realize: the MySQL/MariaDB server parser can’t do this. Which is why I emphasized right in the title: this is “predictive” parsing.
Example 1: suppose you’ve typed SELECT * FROM T ORDER. The GUI will show what the next word must be …
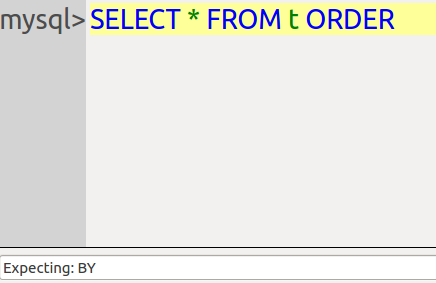
Example 2: suppose you’ve typed CREATE T. The GUI will show what possible words start with T …
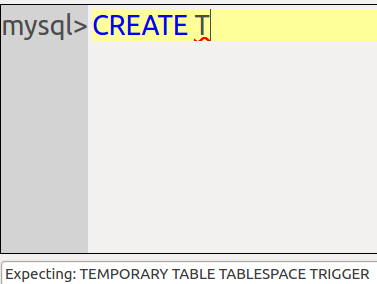
And in either case, hitting the Tab key will save a bit of typing time. I should note that “hitting the Tab key to complete” is something many can do, even the mysql client — but for identifiers not keywords. Technically we can do both, though we prefer to avoid discussing identifiers.
Initial Summary
For error checking, finding the end, highlighting, and predicting: whoopie for predictive parsing of the whole MySQL / MariaDB grammar.
As an additional point, I suppose it’s obvious that we wouldn’t have been able to incorporate a stored-procedure debugger in ocelotgui without parsing. Admittedly it is not using the new parsing code, but it is necessary for it to do a lot more than looking at keywords. So I class debugger capability as the fifth advantage of having client-side parsing.
Recursive Descent Parsers
The algorithms for recursive descent parsers are in most textbooks for compilers, and even in Wikipedia. The “recursive” means that the process can call itself; the rest of the algorithm looks like this:
If (next thing is X) accept it and get the next thing
if (next thing is Y) accept it and get the next thing
if (next thing is Z) accept it and get the next thing
…
else give up and say there’s an error.
Simple, eh?
Now for some quotes from those textbooks for compilers:
“The advantages of recursive descent parsers are that it’s easy to write, and once written, it’s easy to read and understand. The main disadvantage is that it tends to be large and slow.” — Ronald Mak, Writing Compilers And Interpreters, page 810
“The parser text shows an astonishingly direct relationship to the grammar for which it was written. This similarity is one of the great attractions of recursive descent parsing. … In spite of their initial good looks, recursive descent parsers have a number of drawbacks … repeated backtracking … often fails to produce a correct parser [text] … error handling leaves much to be desired.” — Dick Grune, Henri Bal, Ceriel Jacobs, Koen Langendoen, pages 117-119
And they’re right. Have a look at the parsing code of ocelotgui, which can be done by opening a source file here and searching for the first line that begins with “void MainWindow::hparse_f_” (line 9565 in today’s beta). Then scroll downwards till there are no more routines that begin with hparse_f_ — 5000 lines later. Readable, sure, because it’s the simplest of C code. But also tedious, repetitive, and yes, “large and slow”. And this is without knowing anything about object names, since it’s a purely syntactic syntax checker and won’t look at metadata.
On a server the disadvantages could be crippling, but on a client they don’t matter — the meanest laptop has megabytes to spare and the response time is still way faster than a user can blink. And SQL doesn’t require repeated backtracking because it’s rarely necessary to look ahead to the next tokens in order to figure out what the current token means. Here is the worst example that we ran into (I’m quoting the MariaDB 10.1 manual
GRANT role [, role2 ... ] TO grantee [, grantee2 ... ]
which can be instantiated as
GRANT EXECUTE, ROLE55 TO JOE;
See the problem? It’s perfectly okay for EXECUTE to be a role name — it’s not reserved — but typically it’s in statements like GRANT EXECUTE … ON PROCEDURE. So we have to look ahead to find whether ON follows, or whether TO follows. Which we did … and then found out that MariaDB couldn’t. I’d mentioned that this looked tough when I wrote about MariaDB roles two years ago. But for some reason it was attempted anyway and the inevitable bug report has been labelled “stalled” for a long time.
Oh, and one more detail that you’ll find in those compiler textbooks: correctly speaking, ocelotgui has a “recognizer” not a “parser” because it doesn’t generate a tree. That’s why I’ve carefully said it “does parsing” but not said it contains a parser.
Beta Status
The above represents the last feature that we intend to add. It’s at last “ocelotgui beta” rather than “ocelotgui alpha”. The C source and Linux executables, as usual, are at
https://github.com/ocelot-inc/ocelotgui.
Comments in SQL Statements
First I will say what the comment syntax is for various vendors’ dialects. Then I will get specific about some matters that specifically affect MySQL or MariaDB.
Syntax Table
| DBMS | –… | /*…*/ | #… | Nesting | Hints |
|---|---|---|---|---|---|
| Standard | YES | YES | NO | YES | NO |
| Oracle 12c | YES | YES | NO | NO | YES |
| DB2 | YES | YES | NO | YES | NO |
| SQL Server | YES | YES | NO | YES | NO |
| PostgreSQL | YES | YES | NO | YES | NO |
| MySQL/MariaDB | YES(99%) | YES | YES | NO | YES |
The first column is for the type of DBMS. “Standard” is the ISO/IEC SQL standard document. For the others, just click on the DBMS name to see the relevant documentation. The standard, incidentally, clarifies that strings of comments are to be treated as a newline, so if you hear somebody say “comments are ignored”, that’s slightly wrong.
The first column is for comments that begin with “–” (two hyphen-minus signs), what the standard document calls “simple comments”, the ones that look like this:
SELECT * FROM t; -- SIMPLE COMMENT
Everyone supports simple comments, the only problem with MySQL/MariaDB is their insistence that the — must be followed by a space. I’ve had it explained to me that otherwise the parser had problems.
The second column is for comments enclosed by /* and */, what the standard document calls “bracketed comments”, the ones that look like this:
SELECT * FROM t; /* BRACKETED COMMENT */
According to the standard document, bracketed comments are not mandatory, they are optional feature T351. However, it would be surprising to find a modern SQL implementation that doesn’t support them.
The third column is for comments that begin with “#” (what Unicode calls Number Sign but an American dictionary allows for the word Octothorpe ), the ones that look like this:
SELECT * FROM t; # OCTOTHORPE COMMENT
Notice how, in every row but the MySQL/MariaDB row, the key word is NO? In fact I’ve only encountered one other SQL DBMS that is octothorpophiliac: mSQL. Old-timers may recall that mSQL from Hughes Technologies was, for a while, an inspiration for one of MySQL’s founders. Anyway, it’s unnecessary because simple comments do the job just as well.
The fourth column is for nesting, that is, putting bracketed comments within bracketed comments, that look like this:
SELECT * FROM t; /* OUTER /* INNER */ COMMENT */
I’ve often been irritated that I can’t nest in C, so I approve of the DBMSs that support this standard requirement. But I never saw it as important in my MySQL-architect days. There were a few what I guess could be categorized
as “feature requests” (here and here and here) and I approved of my colleagues’ clear responses, it’s low priority.
The final column is for hints. A hint is a bit of syntax that the server might ignore, signalled by an extra character or two in a bracketed comment, like this:
SELECT /*+ HINT COMMENT */ * FROM t;
Typically a hint is a suggestion for an optimizer, like “use index X instead of the default”. It’s found in Oracle; it’s not found in PostgreSQL and some PostgreSQL folks don’t like it; but it’s found in EnterpriseDB’s “advanced PostgreSQL”; and of course it’s found in MySQL and MariaDB. A newish point is that MariaDB has an extra signal “/*M!###### MariaDB-specific code */” that MySQL won’t recognize, which is a good thing since the optimizers have diverged somewhat.
Passing comments to the server
In the MySQL 5.7 manual we see the client has an interesting option:
–comments, -c
Whether to preserve comments in statements sent to the server. The default is –skip-comments (discard comments), enable with –comments (preserve comments).
and a good question is: huh? Surely we should preserve comments, especially in stored procedures, no? Well, the obvious answer is that the parser has to spend time skipping over them, but I doubt that the effect is significant nowadays. The better answer is merely that behaviour changes are serious so let’s leave this up to the users. Our GUI client supports –comments too, which is no surprise since we support all mysql-client options that make sense in a GUI.
But what happens if it’s hard to tell where comments belong? Buried in the source download is a file named mysql-test/t/mysql_comments.sql which is checking these questions:
* Ignore comments outside statements, on separate lines?
* Ignore comments at the end of statements, on the same line but after the semicolon?
* Ignore comments inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT, but not in the body?
The test should be updated now that compound statements in MariaDB don’t have to be inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT.
Therefore
Steve McConnell’s “Code Complete” book advises: “A common guideline for Java and C++ that arises from a similar motivation is to use // synax for single-line comments and /* … */ syntax for larger comments.”
I guess that the equivalent for SQL purposes would be to say: use — for single-line comments and /* … */ for longer ones. But don’t use #, and be wary with standalone or endline comments, and turn –comments on.
Update
In an earlier blog post I predicted that ocelotgui, our GUI client for MySQL and MariaDB, would be beta in February. Now it’s February 29, so I have to modify that to: “any day now (watch this blog for updates or click Watch on the github project page)”. The latest feature additions are in the downloadable source code, by the way, but not in the binary release.
Privileges in MySQL and MariaDB: The Weed Of Crime Bears Bitter Fruit
Let’s look at how well MySQL and MariaDB support privileges (part of “access control” in standard terms), compared to other DBMSs, and consequences thereof.
Count the Privileges
I go to the DBMS manuals (here and starting here and here) and I count the privileges. This is like judging a town by the number of traffic lights it claims to have, but I’m trying to get an indicator for how granular the DBMS’s “authorization” is.
Number of privileges listed in the manuals MySQL/MariaDB Oracle 12c DB2 9.7 SQL Server 2014 31 240 52 124
Pretty small number in the first column, eh? There are historical reasons that MySQL was reluctant to add new privileges, illustrated by Bug#43730.
What is the effect of having a limited number of privileges? Sometimes the same privilege has to be used for two different things. For example, the SUPER privilege is good for “CHANGE MASTER TO, KILL, PURGE BINARY LOGS, SET GLOBAL, and mysqladmin debug command”, while the PROCESS privilege is what you need for SHOW PROCESSLIST — but also for selecting from information_schema.innodb_sys_tables.
Why is this a flaw? If administrators want to allow access to a goose, they are forced to allow access to a gander as well — even when the gander is none of the grantee’s business. As an example that affected us: to make Ocelot’s stored-procedure debugger work, we have to be able to set values in a single global variable, which is impossible without the SUPER privilege, therefore to allow people to use the debugger you have to allow them to purge binary logs too.
Standard Requirements
The SQL standard mentions 9 privileges: INSERT UPDATE DELETE SELECT REFERENCES USAGE UNDER TRIGGER EXECUTE. MySQL and MariaDB do a fair job of handling them:
INSERT: perfect support, including column-level grants.
UPDATE: perfect support, including column-level grants.
DELETE: perfect support.
SELECT: perfect support, including column-level grants.
REFERENCES: perfect support, not including column-level grants. I think this is not well known yet. Deep in the caverns of the manual are the words: “The REFERENCES privilege is unused before MySQL 5.7.6. As of 5.7.6, creation of a foreign key constraint requires the REFERENCES privilege for the parent table.” Kudos to MySQL. The MariaDB manual, on the other hand, still says the REFERENCES privilege is “unused”. For some background about this new feature, click the high-level architecture tab in the old worklog task Foreign keys: reference privilege.
USAGE: no support. In standard SQL, USAGE is for access to domains or UDTs or sequence generators or transliterations or character sets or collations. In MySQL/MariaDB, USAGE is the minimum privilege — you can log in, that’s all. So USAGE is unsupported, but unimportant.
UNDER: no relevance. This is for optional UDT features.
TRIGGER: perfect support.
EXECUTE: perfect support.
Looking at the down side, MySQL and MariaDB don’t allow for the standard GRANT OPTION. Yes, they have a GRANT OPTION privilege, but that’s not standard — what’s needed (and what’s supported by the other serious DBMSs) is an option to grant a particular privilege, not a privilege to grant any privileges.
Packaging
The objection about having hundreds of possible privileges is: it’s hard to keep track of them, or even remember what they are. This should be a solved problem: allow a package of privileges, in other words support CREATE ROLE. This time the kudos go to MariaDB which has allowed roles for over two years. But what if you have MySQL and it’s tedious to grant multiple times?
It’s still simple. You either make a script which contains a bunch of GRANT statements, or you create a stored procedure. Certainly I’d recommend a stored procedure, because it will be “inside the database”, and therefore subject to tracking. Scripts are a tad more dicey security-wise, since changing or deleting files is a process outside the DBMS’s control.
After all, doing grants via an insecure mechanism would kinda mess up the idea of using grants for extra security.
information_schema
There is a standard and reasonable way to get at metadata: you can see the information_schema table, but you won’t see rows for database objects that you don’t have access to.
MySQL and MariaDB follow this plan, but there is a major exception: InnoDB. Consider INNODB_SYS_TABLES, which has information about other tables. Of course this table should not exist at all (the sensible place is information_schema.TABLES), but the more troubling fact is that the relevant privilege is not “whether you have access to the other tables”, but — wow — the PROCESS privilege. And to top it off, in MySQL (though not MariaDB) instead of an empty table you get an error message.
Statement: select * from information_schema.innodb_sys_tables;
Response from MySQL 5.7: ERROR 1227 (42000): Access denied; you need (at least one of) the PROCESS privilege(s) for this operation
We Live In A Just World
Therefore, here is how I can crash my MySQL 5.7 server. Provided, ironically, that I do not have any privileges on any database objects. In other words, I’ve logged in as a user who has been granted the minimum:
GRANT USAGE ON *.* to ‘peter’@’localhost’;
The important prerequisites are: MySQL 5.7.9 compiled from source, a new installation, and an unprivileged user. It doesn’t seem to happen under any other circumstances. So this is not a vulnerability alert. I like to show it, though, as an illustration of the punishment that awaits violators of the precepts of privileges.
As I indicated, I’ve logged in, and the database is empty. Now I say:
SELECT A.NAME, B.NAME FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES A LEFT JOIN INFORMATION_SCHEMA.INNODB_SYS_TABLES B ON A.SPACE = B.SPACE;
On the client I see
ERROR 2013 (HY000): Lost connection to MySQL server during query
On the server I see
mysqld: /home/pgulutzan/Downloads/mysql-5.7.9/sql/sql_error.cc:444: void Diagnostics_area::set_error_status(uint, const char*, const char*): Assertion `! is_set() || m_can_overwrite_status’ failed.
18:37:12 UTC – mysqld got signal 6 ;
…
As this is a crash and something is definitely wrong, the information collection process might fail.
etc.
Those who live in glass houses
I don’t think it would be fair to end this without confessing: us too.
For example, the ocelotgui GUI client for MySQL and MariaDB can crash if I ask it not to send /* comments */ to the server, and there is a very long comment at the end of a statement after the semicolon. We are all sinners.
However, that bug, and a few minor ones, have been found during alpha tests. I’m still hopeful that we’ll go beta within a few weeks, and invite anyone to try and find an embarrassing problem before that happens. The readme and the download are on github at https://github.com/ocelot-inc/ocelotgui.
Generated columns in MariaDB and MySQL
It has been seven years since the last time I blogged about generated columns, and a lot has happened — now both MariaDB and MySQL support them. So it’s time to look again, see how well they’re doing, and compare to the SQL standard’s Optional feature T175 Generated columns.
This is not an introductory description or an explanation why you’d want to use generated columns rather than (say) triggers and views. For that, I’d recommend the relevant manuals or the blog posts by Alexander Rubin and Anders Karlsson.
The Generation Clause
Standard MariaDB 10.1 MySQL 5.7
--------- ------------ ---------
[data type] data_type data type
GENERATED ALWAYS [GENERATED ALWAYS] [GENERATED ALWAYS]
AS AS AS
(expression) (expression) (expression)
[VIRTUAL | PERSISTENT] [VIRTUAL | STORED]
[constraints] [constraints] [constraints]
[COMMENT 'string'] [COMMENT 'string']
The above side-by-side BNFs show the standard syntax and the syntax that MariaDB and MySQL actually allow at the time I’m writing this. The MariaDB manual says incorrectly that either VIRTUAL or PERSISTENT is mandatory. The MySQL manual suggests incorrectly that the clause order is fixed, and has a typo: there should be two “]]”s after “STORED”.
The first important deviation from standard SQL is that “data type” is not an optional clause in either MariaDB or MySQL. The data type can be figured out from the type of the expression, after all.
The second important deviation is that [GENERATED ALWAYS] is optional and there’s a way to say whether the column is virtual (column value is generated when it’s accessed) or persistent/stored (column value is generated when it’s set, and kept in the database). I call this a single deviation because it’s got a single backgrounder: compatibility with Microsoft SQL Server. In fact the original title of the worklog task (WL#411) was “Computed virtual columns as MS [i.e. Microsoft] SQL server has”. We changed it to “Generated columns”, but the perfume of Microsoftness lingers, and you’ll see traces in the vocabulary too. For example, MariaDB has an error message: “”HY000 A computed column cannot be based on a computed column”.
So the tip sheet is: for the sake of compatibility with the standard rather than with Microsoft, always say GENERATED ALWAYS, and call it a “generated” column not a “computed” column. It’s okay to say VIRTUAL, though, because Oracle does.
Restrictions
In standard SQL these restrictions apply:
“Every column reference contained in [the generation expression) shall reference a base column of [the same table].”
In other words, a generated column cannot be based on another generated column. MariaDB adheres to this, but MySQL, as a harmless extension, allows
CREATE TABLE t (a INT, b INT GENERATED ALWAYS AS (a), c INT GENERATED ALWAYS AS (b));
“[The generation expression] shall be deterministic.”
This is pretty reasonable, and both MariaDB and MySQL comply.
“[The generation expression] shall not contain a routine invocation whose subject routine possibly reads SQL-data.”
This is reasonable too, but MariaDB and MySQL go much further — they forbid every user-defined function, even if it’s declared that it’s deterministic and reads no SQL data.
“[The generation expression] shall not contain a query expression”.
In other words, GENERATED ALWAYS AS (SELECT …)” is a no-no. Again, reasonable, and I doubt it will occur to anyone to try.
Differences between MariaDB and MySQL
We’re actually looking at two different implementations — MariaDB’s generated columns come ultimately from a user contribution by Andrey Zhakov, while MySQL’s generated columns are younger and are more of an in-house development. (Update added later: Mr Zhakov deserves credit for the MySQL development too, see the comments.) Things worth noticing are:
* the PERSISTENT versus STORED syntax detail, mentioned earlier,
* GENERATED is a reserved word in MySQL but not in MariaDB,
* MariaDB has some restrictions about foreign keys that MySQL doesn’t have.
MySQL lacks some restrictions about foreign keys, eh? That could lead to interesting results. I tried this sequence of statements:
CREATE TABLE t1 (s1 INT PRIMARY KEY);
CREATE TABLE t2 (s1 INT,
s2 INT AS (s1) STORED,
FOREIGN KEY (s1) REFERENCES t1 (s1)
ON UPDATE CASCADE);
INSERT INTO t1 VALUES (1);
INSERT INTO t2 VALUES (1, DEFAULT);
UPDATE t1 SET s1 = 2;
SELECT * FROM t1;
SELECT * FROM t2;
And the results from the two SELECTs looked like this:
mysql> SELECT * FROM t1; +----+ | s1 | +----+ | 2 | +----+ 1 row in set (0.00 sec) mysql> SELECT * FROM t2; +------+------+ | s1 | s2 | +------+------+ | 2 | 1 | +------+------+ 1 row in set (0.00 sec)
If you’re thinking “whoa, that shouldn’t be right”, then I’m sure you’ll understand why MariaDB doesn’t allow this trick.
Metadata
In the standard there are two relevant INFORMAIION_SCHEMA columns: IS_GENERATED and GENERATION_EXPRESSION. In MySQL all we get is a value in the EXTRA column: “VIRTUAL GENERATED”. In MariaDB also we get a value in the EXTRA column: “VIRTUAL”.
I’d say that both implementations are deficient here — you can’t even see what the “(expression)” was.
Hurray For Everybody
Both MariaDB and MySQL have slight flaws in their implementations of generated columns, but my complaints here shouldn’t cause worry. Both are robust, as I found out by wasting time looking for bugs. This feature can be used.
What about us?
In my last blog post I may have been over-confident when I predicted ocelotgui (our GUI for MariaDB and MySQL) would allow multiple connections and go beta this month. We will have something that, I hope, will be far more exciting.
Send messages between sessions on MySQL or MariaDB
Suppose you want to send a message from one SQL session to one or more other sessions, like “Hey, session#13, here is the latest figure for your calculation, please acknowledge”. I’ll say what Oracle and EnterpriseDB and DB2 do, then rate the various ways to implement something similar in MySQL and MariaDB, and finish with a demo of the procedure that we use, which is available as part of an open-source package.
The syntax was established by Oracle, with EnterpriseDB and IBM following suit. The details are in the Oracle 12c manual and the DB2 9.7 manual. The oversimplification is this:
DBMS_PIPE.PACK_MESSAGE('message');
SET status = DBMS_PIPE.SEND_MESSAGE('channel#1');
SET status = DBMS_PIPE.RECEIVE_MESSAGE('channel#1');
DBMS_PIPE.UNPACK_MESSAGE(target_variable);
The idea is that PACK_MESSAGE prepares the message, SEND_MESSAGE ships the message on a channel, RECEIVE_MESSAGE receives something on a channel, and UNPACK_MESSAGE puts a received message in a variable. The whole package is called DBMS_PIPE because “pipe” is a common word when the topic is Inter-process communication.
MySQL and MariaDB don’t have DBMS_PIPE, but it’s possible to write it as an SQL stored procedure. I did, while working for Hewlett-Packard. Before saying “here it is”, I want to share the agony that we endured when deciding what, at the lowest level, would be the best mechanism.
The criteria are:
size -- how many bits can a message contain? isolation -- how many conversations can take place simultaneously? privilege -- how specific is the authorization, if any? is eavesdropping easy? danger -- what are the chances of fouling up some other process? reliability -- can messages be delayed or destroyed? utility -- can it be used at any time regardless of what's gone before?
There is no “overhead” criterion because messaging should be rare.
These are the 5 candidate mechanisms.
1. Tables.
Session#1 INSERTs to a table, Session#2 SELECTs from the table.
Rating: size=good, isolation=good, privilege=good, danger=low, reliability=good.
But utility=terrible. First: with some storage engines you have to COMMIT in order to send and this might not be a time that you want to COMMIT. Second and more important: there’s a bit of fine print in the MySQL Reference Manual:
A stored function acquires table locks before executing, to avoid inconsistency in the binary log due to mismatch of the order in which statements execute and when they appear in the log.
Think about it. It means that you can’t read a message that’s sent by a function while the function is running. And you can’t work around that by writing the messaging code in a stored procedure — there’s no guarantee that the stored procedure won’t be called from a function.
2. Files.
Session#1 uses SELECT … INTO OUTFILE. Session#2 says LOAD_FILE.
(We don’t consider LOAD DATA because it won’t work in stored procedures.)
Rating: size=good, isolation=good, privilege=good, utility=good.
But danger=high, reliability=bad. The problem is that you can’t overwrite a file, so the messages would pile up indefinitely.
3. information_schema.processlist.
Session#1 says SELECT SLEEP(0.5),’message’. Session#2 says SELECT from information_schema.processlist.
Rating: size=bad, isolation=bad, privilege=good, danger=low, utility=bad.
This is okay for short messages if you’re not worried about eavesdropping. But notice that the message can only be a literal, like ‘message’. It cannot always be a variable, because then it’s dynamic SQL, and dynamic SQL is illegal in functions, and now you’ve got the same problem as with mechanism number 1.
4. GET_LOCK.
Session#1 says GET_LOCK(). Session#2 says IS_USED_LOCK().
Rating: size=bad, isolation=good, privilege=good, danger=low, utility=good.
Technically reliability=low because the message disappears when the server goes down, but in many situations that would actually be a good thing. The rating “size=bad” is easy to understand: effectively there’s only one bit of information (yes/no) that Session#2 is getting by checking IS_USED_LOCK(). However, one-bit signals are great for lots of applications so this would still fit in a toolkit if it weren’t for The Great GET_LOCK Showstopper. Namely, you can only have one GET_LOCK at a time.
Now for the good news. Multiple GET_LOCK invocations are on their way. The person to thank (and I say “thank” because this was a contribution done to the whole community) is Konstantin Osipov, who wrote a patch and a blog post — “MySQL: multiple user level locks per connection”. As I understand matters, this was a basis for the code that is coming in a future MySQL version and is now in the MySQL 5.7.5 manual. Konstantin Osipov, by the way, nowadays writes for the Tarantool NoSQL DBMS and Lua application server, to which I am pleased to contribute in small ways.
5. System variables.
Session#1 says SET @@variable_name = ‘message’. Session#2 says target = @@variable_name.
Rating: size=bad, isolation=good, privilege=good, danger=high, utility=good.
The system variable must be a string, must be dynamically writable, and must not change the server’s behaviour if you write a bad value. Only one item does all that: @@init_connect. It’s actually easy to ensure that changes to @@init_connect won’t affect its official purpose — just put the message /* inside a comment */. However, I still rate it as danger=high because anybody could overwrite the message inadvertently.
And the winner, as far as we’re concerned, is … #5 System variables. Remember, Ocelot is supplying a debugger for MySQL/MariaDB routines. It would be a pretty poor debugger that used a message mechanism that wouldn’t work with functions, so mechanism#1 and mechanism#3 are out. The GET_LOCK of mechanism#4 is in fact used by a different debugger, but in my opinion that means it’s hard to have two debugger sessions on the same server, or to run without pausing after every statement. So our implementation involves setting @@init_connect.
If you want to see our implementation, here is how (on Linux).
Download, install, and start ocelotgui. The instructions are in the
README.md file at https://github.com/ocelot-inc/ocelotgui (just scroll past the list of files). Connect to a MySQL/MariaDB server as a user with privileges to create databases and tables, and execute routines. Then type in, on the statement widget
$INSTALL
After this, you actually won’t need ocelotgui any more. So, although I think the real “demo” would be to use the debugger now that you’ve installed it, I’ll show how to use pipes with the mysql client instead.
Start a shell. Start mysql. You need the SUPER privilege, and the EXECUTE privilege for routines in the xxxmdbug database. Send a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_send('channel#1','message');
Query OK, 0 rows affected (0.00 sec)
Start a second shell. Receive a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_receive
-> ('channel#1',1,@message_part_1,@message_part_2);
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> select @message_part_1;
+-----------------+
| @message_part_1 |
+-----------------+
| message |
+-----------------+
1 row in set (0.00 sec)
You can see how it’s implemented by saying
SELECT * FROM information_schema.routines WHERE routine_schema = 'xxxmdbug' AND routine_name like 'dbms_pipe_%';
The dbms_pipe_send and dbms_pipe_receive routines are GPL and copyrighted by Hewlett-Packard.
I might not moderate comments on this blog while on vacation. Tomorrow I leave for Reykjavik, Amsterdam and London.