Category: MariaDB
General Purpose Storage Engines in MariaDB
MariaDB tries to encourage use of many storage engines, which Oracle doesn’t bother with. The ones that could be considered — occasionally! — as InnoDB replacements are: Mroonga, TokuDB, and Aria.
Mroonga
I predicted that Mroonga would be in MariaDB 10.0.8, and behold, here it is in MariaDB 10.0.15. Truly I am the Nostradamus of the database world.
It’s a general-purpose storage engine, in that it doesn’t have serious limitations regarding what can be stored or indexed. I think its “column-store” feature has limited appeal, but as I saw in January, it’s dandy for full-text searching. This time I look at the list of “Full-Text Restrictions” in the MySQL manual, and quote from it:
“Full-text searches are supported for InnoDB and MyISAM tables only.” — Not true for Mroonga, of course.
“Full-text searches are not supported for partitioned tables.” — True for Mroonga, which can’t handle partitioned tables at all.
“… the utf8 character set can be used, but not the ucs2 [or utf16 or utf32] character set.” — True for Mroonga.
“Therefore, the FULLTEXT parser cannot determine where words begin and end in [Chinese/Japanese/Korean i.e. CJK].” — Not true for Mroonga, which is just great with CJK.
“… all columns in a FULLTEXT index must use the same character set and collation.” — True for Mroonga.
“The argument to AGAINST() must be a string value that is constant during query evaluation.” — True for Mroonga.
“For InnoDB, all DML operations (INSERT, UPDATE, DELETE) involving columns with full-text indexes are processed at transaction commit time.” — Technically not true for Mroonga, but Mroonga indexes will get out of synch if rollbacks occur.
TokuDB
In a previous escapade I found that TokuDB was good stuff but lacked two features: foreign keys and full-text search.
So, inspired by the fact that I can use Mroonga full-text searching with InnoDB, I wondered: wouldn’t it be great if I could use that trick on TokuDB too?
Well, I gave it a try, and have to say the result was a bit disappointing …
MariaDB [test]> CREATE TABLE t (
-> id INT NOT NULL DEFAULT '0',
-> `text_column` VARCHAR(100) CHARACTER SET utf8 DEFAULT NULL,
-> PRIMARY KEY (id),
-> FULLTEXT KEY `text_column` (text_column)
-> ) ENGINE=mroonga DEFAULT CHARSET=latin1 COMMENT='engine "tokudb"'
-> ;
ERROR 2013 (HY000): Lost connection to MySQL server during query
… Do not do this on a production system, as it will disable all your databases.
I also have a MariaDB 10.0.15 server that I built from source, and on that server TokuDB crashes even for simple everyday statements. I suppose this is like saying “Doctor my head hurts when I beat it against the wall”. But there’s no warning during the build and no warning in the documentation. Therefore it must be somebody else’s fault.
Aria
In 2013 Stewart Smith said about Aria: “It’s still not there and I don’t think it ever will be.” I didn’t see anything in 2014 that contradicts what he predicts, and the MariaDB people themselves say improvements are “on hold”, but it does have some advantages over MyISAM.
This is another storage engine with full-text support, but I rate that feature as “poor” because (like InnoDB) it won’t do CJK well, and (unlike InnoDB) it has some irritating default settings about minimum key length and maximum frequency.
It looks nice that I can create a SPATIAL index with Aria; however, I see that this is supposedly possible with InnoDB too, according to the recent announcement of MySQL 5.7.5.
Data can be represented in tables
| Capability | Mroonga | TokuDB | Aria | InnoDB |
|---|---|---|---|---|
| Full-text Indexes | Excellent | No | Poor | Poor |
| Foreign Keys | No | No | No | Yes |
| Rollbacks | No | Yes | No | Yes |
| Spatial Indexes | Yes | No | Yes | Real Soon |
| Maximum Key Length | 3072 | 3072 | 1000 | 767 |
| Smallest Lock | Column | Row | Table | Row |
| Allows Partition Clauses | No | Yes | Yes | Yes |
| Recovers after ‘kill -9’ | No | Yes | Yes | Yes |
| Works on Windows | Yes | No | Yes | Yes |
Or, if you want to go beyond general-purpose open-source storage engines like these, there are lots more to look at. The biggest list of MySQL-compatible storage engines that I know of is in the Spanish Wikipedia.
UPDATE NOTICE: The chart above has been corrected due to comments from a Mroonga developer and a TokuDB developer.
Dynamic compound statements in MariaDB
A long-ago-discussed and much-requested feature, “dynamic compound statements”, is working at last.
It’s been eleven years since the original discussion of dynamic compound statements for MySQL, as you can see by looking at the worklog task on the wayback machine. (As usual, you have to click the “high level architecture” box to see the meat of the specification.) The essential idea is that one can directly enter compound statements like BEGIN … END and conditional statements like “IF … END IF” and looping statements like “WHILE … END WHILE” without needing a CREATE PROCEDURE or CREATE FUNCTION statement.
The advantages are that one can run conditional or complex sequences of statements without needing an EXECUTE privilege, or affecting the database metadata. This has been a popular feature request, as one can see from bug#15037, bug#48777, bug#54000, and bug#61895. and bug#62679.
In 2013 Antony Curtis submitted a patch named “Compound / Anonymous statement blocks for MySQL”. (Anonymous blocks is the Oracle terminology.) Apparently he offered it to Oracle but they couldn’t agree about the licence terms. The MariaDB people were gladder to get the offer, so it’s now in the MariaDB 10.1.1 alpha.
I downloaded it from source. There’s a problem with “make install” but it’s easy to work around and has nothing to do with Mr Curtis’s patch. I had no trouble checking that the feature works as advertised. So, next, I compared the spec with Mr Curtis’s implementation.
Spec: Allow BEGIN … END “compound statements”, CASE, IF, LOOP, WHILE, and REPEAT. Implementation: all done. The only significant defect is that BEGIN has to be stated as BEGIN NOT ATOMIC, to avoid confusion with an old non-standard meaning of BEGIN. So “BEGIN DELETE FROM t; END” is illegal. And “label_x: BEGIN DELETE FROM t; END” is illegal. Only “BEGIN NOT ATOMIC DELETE FROM t; END” is legal. It’s a slight disappointment that no way was found to handle these little difficulties in the parser.
Spec: internally there will be a temporary anonymous procedure created for every compound statement. Implementation: This didn’t happen, at least not in a user-visible way. That’s a low-level detail so it doesn’t matter.
Spec: there should be no new privilege requirement. Implementation: there is no new privilege requirement.
Spec: the implied routine will have characteristics like MODIFIES SQL DATA and NOT DETERMINISTIC. Implementation: characteristics are irrelevant.
Spec: even if there is an anonymous procedure, it should not be visible to the user in information_schema.routines. Implementation: nothing is visible in information_schema.routines.
Spec: perhaps the statement should be in performance_schema.statements. Implementation: no.
Spec: some statements that are client-specific and are not allowed in stored procedures should not be in dynamic compound statements. Implementation: right. For example “USE database_name” is not allowed.
Spec: it’s uncertain whether a dynamic compound statement (which after all is a “statement”) should appear as a single statement in the slow log. Implementation: I didn’t test this because I don’t believe in the slow log; I assumed it doesn’t work.
Spec: if @@sql_mode is set within a dynamic compound statement, then it gets restored to its original value when the statement ends. Implementation: yes, it’s restored.
Spec: A dynamic compound statement may not contain statements that create or drop or alter routines. Implementation: right, statements like DROP PROCEDURE are illegal.
Spec: a dynamic compound statement cannot be used for a PREPARE statement, and therefore there is no fix for BUG#14115 “Prepare() with compound statements breaks”. Supposedly there could be parser-related pitfalls with such syntax. Implementation: PREPARE is allowed. Statements like PREPARE stmt1 FROM ‘BEGIN NOT ATOMIC DECLARE v INT; END’// are just fine. This is worrisome, but probably the supposed pitfalls were cleared up long ago.
Spec: SHOW STATUS could have new counters: Com_compound_statement, Com_if, Com_loop, Com_repeat, Com_while. Implementation: No, that’s not implemented.
Spec: SHOW PROCESSLIST will show the whole compound statement. Implementation: No, that’s not implemented. When I first started the performance_schema design I realized that SHOW PROCESSLIST would eventually become obsolete, so nowadays I think this part of the spec is obsolete.
The future
Given that dynamic compound statements are in DB2 and Oracle 12c and PostgreSQL and now in MariaDB alpha, Oracle/MySQL will look a bit slow if it waits another eleven years to implement them.
But MariaDB 10.1.1 is an early alpha, and nothing is guaranteed in an alpha, so it’s too early to say that MariaDB is ahead in this respect.
A glance at a MariaDB release candidate
Today I looked at the MariaDB Release Candidate wondering how my earlier predictions came out.
I predicted, for “roles”:
For all of the bugs, and for some of the flaws, there’s no worry — they’ll probably disappear.
In fact all the bugs are gone, and I belatedly realized (after some gentle nudges from a MariaDB employee) that some of the flaws weren’t flaws.
The inability to grant to PUBLIC still troubles me, but it looks like roles are ready to roll.
I predicted for “mroonga”:
At the time I’m writing this, MariaDB 10.0.8 doesn’t have mroonga yet.
In other words, I thought it would be in 10.0.8. It was not to be, as another MariaDB employee told me:
Unfortunately, mroonga appeared to have some portability problems. Most likely it won’t be in 10.0.8. There is a good chance it will be 10.0.9 though.
While I was looking, I tried out a new clause for the DELETE statement:
DELETE FROM t RETURNING select-list;
which returns the rows that just got deleted. It’s a new non-standard clause which increases MariaDB’s divergence from MySQL, so decent people should demand an explanation.
Oracle 12c looks similar but does something different:
DELETE FROM t RETURN|RETURNING expr [,expr...] INTO data-item [,data-item...];
SQL Server 2012 has a clause which looks different but does something similar:
DELETE FROM t OUTPUT select-list;
PostgreSQL has a clause which looks similar and does something similar:
DELETE FROM t RETURNING select-list;
So we’re seeing, yet again, the belief that PostgreSQL is a better model for MariaDB than the big boys are. By the way, the big boys are a bit more orthogonal — I’ve seen extensions similar to this one in UPDATE or MERGE statements. But the bigger orthogonality woe is that here we have a statement that returns a result set, but can’t be used in all the places where a result-set-returning sub-statement could work, like DECLARE CURSOR FOR DELETE, or INSERT … DELETE. Of course, I’m glad they don’t work. My point is only that now-it-works-now-it-doesn’t additions make the product look haphazard.
Update: How it’s done in standard SQL
This section was added on 2014-03-01, one week after the original post.
SQL:2011 has a non-core (optional) feature T495 “Combined data change and retrieval”. Ignoring a lot, the syntax is SELECT … FROM NEW|OLD|FINAL TABLE (INSERT|UPDATE|DELETE …) …. For example
SELECT column1+5 FROM OLD TABLE (DELETE FROM t) AS t WHERE f = 77;
In this example table t is a “delta table”.
There’s an example with DECLARE CURSOR and FETCH in the DB2 10 for z/OS manual.
Mroonga and me and MariaDB
Chinese and Japanese and Korean (CJK) text usually has no spaces between words. Conventional full-text search does its tokenizing by looking for spaces. Therefore conventional full-text search will fail for CJK.
One workaround is bigrams. Suppose the text is
册免从冘
There should be three index keys, one for each two-character sequence:
册免, 免从, and 从冘.
Now, in a search like
SELECT * FROM t WHERE MATCH(text_column) AGAINST ('免从');
a bigram-supporting full-text index will have a chance. It’s wasteful and there will be false hits whenever the bigram isn’t really a “word”, but the folks in CJK-land have found that bigrams (or the three-character counterpart, trigrams) actually work.
One way to get bigrams for MySQL or MariaDB is to get mroonga.
Why care about Yet Another Storage Engine)?
Back in 2008 a project named Senna attracted the attention of my colleagues at MySQL, but didn’t go on to world conquest.
Since around 2011 the groonga project, billed as a “successor” to Senna, has been outing regular releases of a generic library that can connect to more than one DBMS. “Mroonga” is the “M[ySQL storage engine that interfaces with the] groonga [code]”. So, although it hasn’t been packaged with MySQL or MariaDB until now, it’s not all new or untested code. What’s new is that MariaDB will, real soon now, include mroonga as part of the regular MariaDB download. Poof, credibility at last.
I understand that mroonga has features that make it interesting:
* It’s a column-storage engine, which I suppose makes it an alternative to Infobright or InfiniDB
* Some of its users or developers also have an involvement with the Spider storage engine, which I suppose means there wouldn’t be too much trouble using the two engines in concert: mroonga for full-text and Spider for sharding.
… but I didn’t look at the column storage or the Spider compatibility. I cared only that SHOW ENGINES said it’s “CJK-ready fulltext search”.
Of course, SHOW ENGINES can also show MyISAM and InnoDB and SphinxSE, and they can all do full-text searching too. One might choose MyISAM because for a long time that was the only engine that had full-text, or choose InnoDB because it’s the default nowadays, or choose SphinxSE because it has lots of features including stemming. But those aren’t targeted for the CJK niche. For example, MariaDB has no bigrams. Sphinx’s documentation says it does have bigrams, but a glance shows instantly “those are not the bigrams you’re looking for”.
The only questions, then, are (a) does mroonga really handle full-text, and (b) does mroonga really handle CJK?
Does mroonga work?
At the time I’m writing this, MariaDB 10.0.8 doesn’t have mroonga yet. There are instructions for getting packages with Windows and Ubuntu etc., but such things never work for me — they’ll always be out of synch with something else that I’ve got, or with what the main vendor (Oracle or MariaDB in this case) is updating. So I decided to build from source. Getting mroonga was easy since I already have Bazaar:
bzr branch lp:~mroonga/maria/mroonga
and then build. Actually the initial build failed because mroonga required CMake 2.8.8 which doesn’t come with Ubuntu 12.04. But after I worked around that, I had a server and all I had to say was
INSTALL PLUGIN mroonga SONAME 'ha_mroonga.so'; CREATE FUNCTION last_insert_grn_id RETURNS INTEGER SONAME 'ha_mroonga.so'; SET GLOBAL mroonga_log_level=NONE;
I found more out by looking at some documentation, which is nowhere near Oracle quality but is mostly in readable English.
Then I was able to do this:
CREATE TABLE t ( id INT NOT NULL DEFAULT '0', `text_column` VARCHAR(100) CHARACTER SET utf8 DEFAULT NULL, PRIMARY KEY (id), FULLTEXT KEY `text_column` (text_column) ) ENGINE=mroonga DEFAULT CHARSET=latin1 COMMENT='engine "innodb"'
It’s probably less than obvious that I’m looking at a good-looking feature. The point is: with this syntax I can use mroonga with an InnoDB table. Whoopie. Although that means I lose mroonga’s other features, I can use it without losing whatever I find good about InnoDB. And then I was able to do this:
SELECT * FROM t WHERE MATCH(text_column) AGAINST ('x');
Again it’s probably less than obvious that I’m looking at a good-looking feature. The MATCH … AGAINST syntax is idiosyncratic and unobvious — don’t expect this to arrive in an SQL standard near you any time soon. But it’s what the long-term MyISAM user is used to, so the transition isn’t painful.
Does mroonga handle CJK?
The J (Japanese) part is certainly there. The developers are Japanese. One of the optional extras is integration with MeCab which is a tool that can handle Japanese morphology — it’s like solving the “no spaces” problem by understanding a bit about the Japanese language, which after all is the solution that a human would use with no-spaces text. I don’t see, though, that there’s been equivalent attention paid for the C (Chinese) and K (Korean) parts of CJK. So I just looked at the bigrams, since they’re all that C or K could benefit from.
I created a million-row table containing randomly-chosen characters, mostly Kanji, but with a mix of Latin and Kana letters. How I made it is tedious, but perhaps somebody out there will want to know how to make randomly populated tables with such “data”, so I’ll put the code in a comment on this posting.
I had a choice between a bewildering variety of ways to tokenize. The default one, TokenBigram, did the job. The good news for me was that it didn’t do bigrams when the text was entirely Latin — that would be silly — but in a separate test I did see that it indexed Latin characters as ordinary words. So one of the worries that I had — that mroonga would be only good for CJK but not for non-CJK mixed inside the same text column — turned out not to be a worry.
And now, the essential point, the “l’essence du bigram” (which would look good on a restaurant menu, eh?) …
MariaDB [test]> SELECT COUNT(*) FROM t WHERE MATCH(text_column) AGAINST ('免从');
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
It found a row with a bigram! But is that the right count?
MariaDB [test]> SELECT COUNT(*) FROM t WHERE text_column LIKE '%免从%'; +----------+ | COUNT(*) | +----------+ | 1 | +----------+ 1 row in set (2.48 sec)
Yes, it’s the right count — a LIKE search confirms it.
The difference is that the LIKE search took 2.5 seconds because it had to scan a million rows. The mroonga full-text search took approximately zero seconds because it used an index. That doesn’t mean that mroonga is fast — not every search is a benchmark. I did find a graph that shows mroonga throughput is better than MyISAM’s or SphinxSE’s but probably if I looked hard I could find a graph that says the opposite.
And the crowd goes wild
Although I have done no benchmarks or bug hunts, I have acquired the impression that mroonga is capable of doing what its makers say it ought to be able to do.
The Third Most Popular Open Source DBMS
We all know that MySQL says it is “the world’s most popular open-source database”. And PostgreSQL has a firm hold on second place while claiming to be, instead, “the world’s most advanced open source database”. But the horse that comes in third can return some money to gamblers who bet “to show”. And the horse that shows momentum or gets close is worth watching for next time.
So I’ll just ignore the dolphin and the elephant in the room, and go on to a harder question: who’s number three?
According to Wikipedia
To find out how many times someone has expressed interest in a topic, I can go to stats.grok.se and ask how many times someone has looked at that topic’s page in Wikipedia. Evil-thinking people could manipulate these numbers with ease, but until now they have had no reason to do so.
So here is the count of accesses on the Wikipedia pages of the nine contending SQL DBMSs, for September last year (blue) and September this year (red).
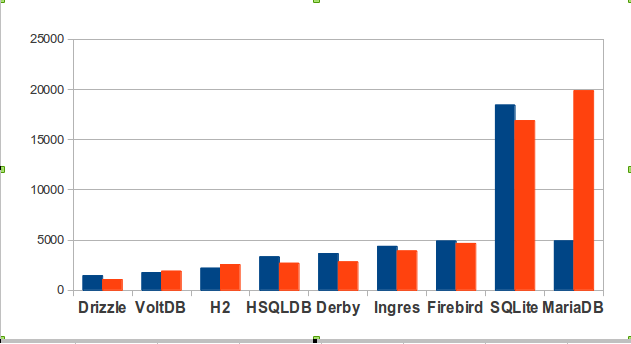
In absolute terms, MariaDB is only slightly ahead. But if you look at momentum (what direction the hit counts have gone between September 2012 and September 2013), interest in MariaDB has risen a great deal while interest in most other DBMSs has declined.
Now here is the chart for open-source NoSQL DBMSs, made the same way. This time I can’t be comprehensive — there are 150 NoSQL products! I’ll show only the ten with the most hits.
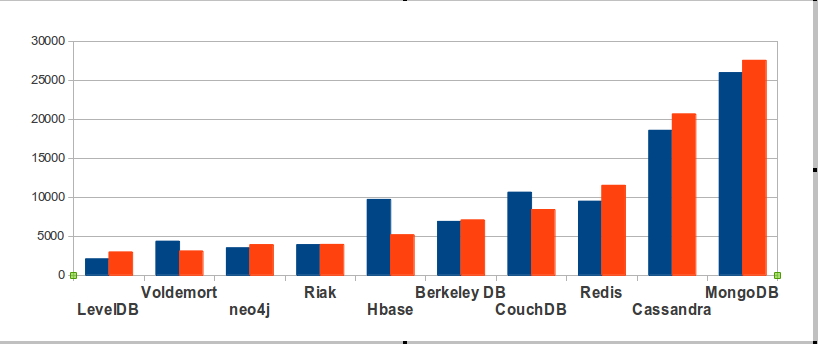
Of course MongoDB is in front. The surprise is that MongoDB’s in-frontness isn’t glaring.
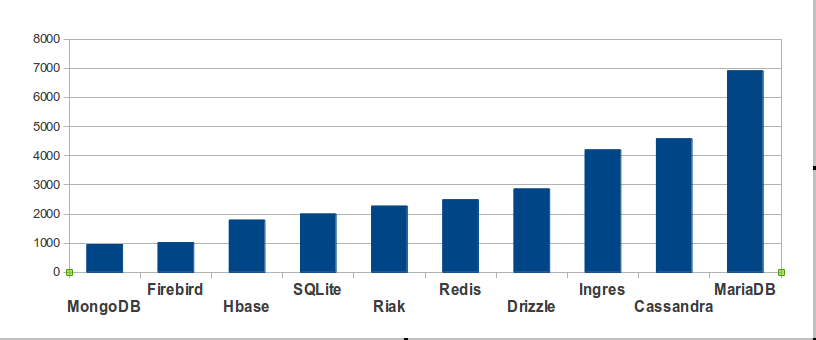
According to The Register
To find out how many times the mass media mentioned a DBMS, I can go to google.com and enter site:theregister.co.uk [DBMS name] -mozilla. Simply googling the DBMS name would fail because Google seems to become more inexact as numbers get bigger, and because “Ingres” and “Firebird” and “Drizzle” and “Cassandra” have alternative meanings that have nothing to do with databases.
So this term is more specific, it’s asking: how many times does search-term appear in The Register (in a non-Mozilla context)? For this purpose I’m positing that “the mass media” and the well-known medium “The Register” are synonymous terms.
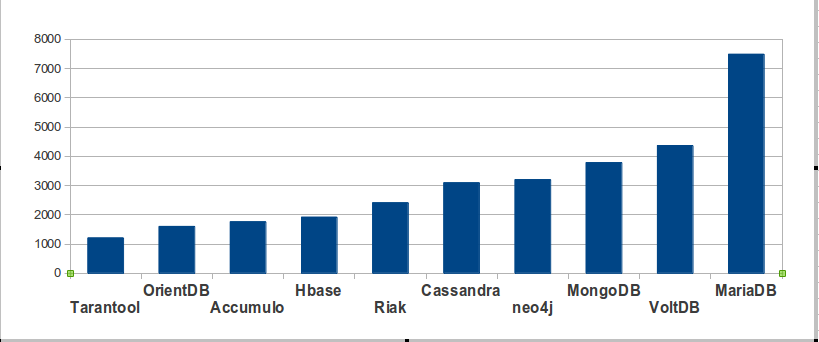
According to Ohloh
To find out how much activity an open-source project has, I can go to ohloh.net and look up the count of commits in the last year. (Ohloh “provides a single aggregate source of information about the world’s open source projects from over 5,000 repositories and forges including GitHub, SourceForge and Google Code, as well as open source foundation repositories including the Eclipse, Mozilla, Apache, and Linux.”) This method has been justly criticized, but is an indicator for developer enthusiasm. Again I am only showing the top ten, other than MySQL or PostgreSQL, for any kind of open-source DBMS.
According to db-engines
An Austrian company named solid IT maintains a site named db-engines.com. On it there is “a list of DBMS ranked by their current popularity … updated monthly.” Their ranking is based on (a) Google and Bing hits, (b) Google Trends, (c) Stack Overflow and DBA Stack Exchange (counting the number of technical discussions), (d) indeed.com and simplyhired.com (counting the number of job offers), (e) LinkedIn (counting the number of people who mention the product in their profiles). In other words, none of their criteria match the criteria that I prefer. If one excludes closed-source and MySQL and PostgreSQL from their list, their top 10 hits are:
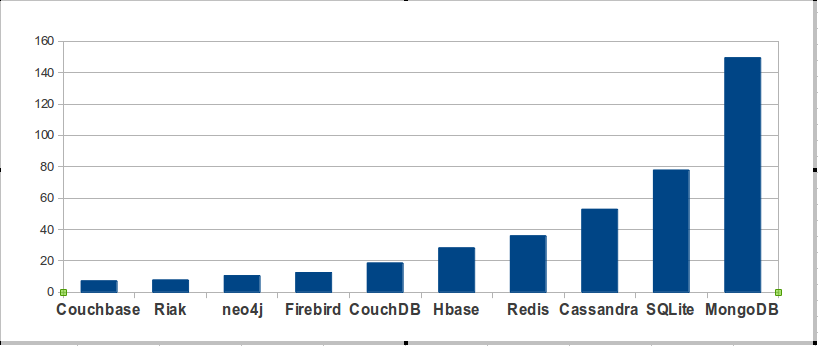
Woe and alas. If their results had been similar to mine, despite their different criteria, then that might have validated both our methods. But they’re very different. I think that’s because my criteria are the only valid ones, but obviously I’m not the only evaluator.
According to the makers
“We believe that there are more copies of SQLite in use around the world than any other SQL database engine, and possibly all other SQL database engines combined.”
— sqlite.org
“Mountain View, Calif. – February 8, 2012 – Couchbase, Inc. [is] the NoSQL market share leader …”
— couchbase.com
“Firebird® is the universal open source database used by approximately 1 million of software developers worldwide.”
— facebook.com/FirebirdSQL
“MongoDB is the leading NoSQL database, with significant adoption among the Fortune 500 and Global 500.”
— mongodb.com
Announcing the finishers
MariaDB is in third place among the open-source SQL DBMSs, and would be third overall if we gave more weight to the numbers “according to Ohloh” and “according to The Register”. But MongoDB and Cassandra nose past it “according to Wikipedia”, and MongoDB is definitely the third-place finisher “according to db-engines”. The claim of SQLite is strongest “according to the makers”.
We have a photo finish, with a blurry camera.