About pgulutzan
View all posts by pgulutzan
Short note re Progress and NuSphere
Progress Software on 2024-04-19 said more about “considering” an offer for MariaDB plc (the company not the foundation).
They own NuSphere which had a dispute with MySQL AB which was settled in 2002. My happy history as a MySQL employee biases me but I thought that NuSphere was not acting angelically.
I think it won’t happen.
Update: Apparently it didn’t. The 2024-04-26 K1 recommended offer differed.
Make SHOW as good as SELECT even with InnoDB
Here’s a snippet of what I’d like SHOW ENGINE INNODB STATUS to look like:
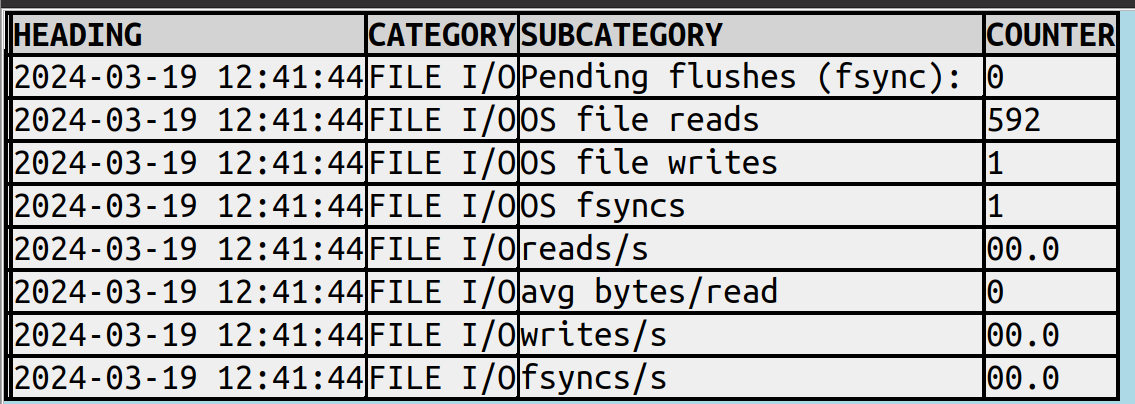
as opposed to what the server sends:
... -------- FILE I/O -------- Pending flushes (fsync): 0 295 OS file reads, 1 OS file writes, 1 OS fsyncs 0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s ...
In my last post I described a way to
Make SHOW as good as SELECT”
which was possible because most result sets from SHOW etc. are at least table-like, but
STATUS’s wall of text isn’t table-like. So I forced it into a table with these basic rules:
- A line inside ——s, like FILE I/O, is the category of what follows.
- Otherwise a line is a row but if it contains commas it is multiple rows.
- Numbers can usually be extracted from text as different columns..
After that there’s still a bunch of fiddling, I put the details in source-code comments.
Version 2.3
The new features related to SHOW etc. are now in a released version as well as in source code,
downloadable from github.
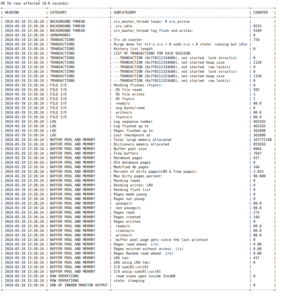
In the rest of this post I’ll show a complete result from SHOW ENGINE INNODB STATUS; (“before”),
and the same data from SHOW ENGINE INNODB STATUS WHERE 1 > 0; after ocelot_statement_syntax_checker
has been set to ‘7’ (“after”). (Instead of copying the Grid Widget I copied from the History Widget
after setting Max Row Count to 100.)
“before”
| InnoDB | | ===================================== 2024-03-19 12:39:45 0x7f80f01f3700 INNODB MONITOR OUTPUT ===================================== Per second averages calculated from the last 43 seconds ----------------- BACKGROUND THREAD ----------------- srv_master_thread loops: 0 srv_active, 2455 srv_idle srv_master_thread log flush and writes: 2454 ---------- SEMAPHORES ---------- ------------ TRANSACTIONS ------------ Trx id counter 754 Purge done for trx's n:o < 0 undo n:o < 0 state: running but idle History list length 0 LIST OF TRANSACTIONS FOR EACH SESSION: ---TRANSACTION (0x7f8111334680), not started 0 lock struct(s), heap size 1128, 0 row lock(s) ---TRANSACTION (0x7f8111333b80), not started 0 lock struct(s), heap size 1128, 0 row lock(s) -------- FILE I/O -------- Pending flushes (fsync): 0 295 OS file reads, 1 OS file writes, 1 OS fsyncs 0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s --- LOG --- Log sequence number 463193 Log flushed up to 463193 Pages flushed up to 362808 Last checkpoint at 362808 ---------------------- BUFFER POOL AND MEMORY ---------------------- Total large memory allocated 167772160 Dictionary memory allocated 853016 Buffer pool size 8064 Free buffers 7647 Database pages 417 Old database pages 0 Modified db pages 164 Percent of dirty pages(LRU & free pages): 2.033 Max dirty pages percent: 90.000 Pending reads 0 Pending writes: LRU 0, flush list 0 Pages made young 0, not young 0 0.00 youngs/s, 0.00 non-youngs/s Pages read 273, created 144, written 0 0.00 reads/s, 0.00 creates/s, 0.00 writes/s No buffer pool page gets since the last printout Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 417, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0] -------------- ROW OPERATIONS -------------- 0 read views open inside InnoDB state: sleeping ---------------------------- END OF INNODB MONITOR OUTPUT ============================ |
“after”
/
Make SHOW as good as SELECT
For example, this works:
SHOW AUTHORS GROUP BY `Location` INTO OUTFILE 'tmp.txt';
You’re thinking “Hold it, MySQL and MariaDB won’t allow SHOW (and similar statements like ANALYZE or CHECK or CHECKSUM or DESCRIBE or EXPLAIN or HELP) to work with the same clauses as SELECT, or in the same places.” You’re right — but they work anyway. “Eppur si muove”, as Galileo maybe didn’t say.
I’ll explain that the Ocelot GUI client transforms the queries so that this is transparent, that is, the user types such things where SELECTs would work, and gets result sets the same way that SELECT would do them.
Flaws and workarounds
I’ll call these statements “semiselects” because they do what a SELECT does — they produce result sets — but they can’t be used where SELECT can be used — no subqueries, no GROUP BY or ORDER BY or INTO clauses, no way to way to choose particular columns and use them in expressions.
There are three workarounds …
You can select from a system table, such as sys or information_schema or performance_schema if available and if you have the privileges and if their information corresponds to what the semiselect produces.
For the semiselects that allow WHERE clauses, you can use the bizarre “:=” assignment operator, such as
SHOW COLUMNS IN table_name WHERE (@field:=`Field`) > '';
and now @field will have one of the field values.
You can get the result set into a log file or copy-paste it, then write or acquire a program that parses, for example by extracting what’s between |s in a typical ASCII-decorated display.
Those three workarounds can be good solutions, I’m not going to quibble about their merits. I’m just going to present a method that’s not a workaround at all. You just put the semiselect where you’d ordinarily put a SELECT. It involves no extra privileges or globals or file IO.
Example statements
CHECK TABLE c1, m WHERE `Msg_text` <> 'OK'; SELECT * FROM (DESCRIBE information_schema.tables) AS x ORDER BY 1; SHOW COLLATION ORDER BY `Id` INTO OUTFILE 'tmp.txt'; SELECT `Type` FROM (SHOW COLUMNS IN Employees) AS x GROUP BY `Type`; SELECT UPPER(`Name`) from (SHOW Contributors) as x; SHOW ENGINES ORDER BY `Engine`; (SELECT `Name` FROM (SHOW CONTRIBUTORS) AS x UNION ALL SELECT `Name` FROM (SHOW AUTHORS) AS y) ORDER BY 1; CREATE TABLE engines AS SHOW ENGINES;
How does this work?
The client has to see where the semiselects are within the statement. That is easy, any client that can parse SQL can do it.
The client passes each semiselect to the server, and gets back a result, which ordinarily contains field names and values.
The client changes the field names and values to SELECTs, e.g. for SHOW CONTRIBUTORS the first row is
(SELECT 'Alibaba Cloud' AS `Name`, 'https://www.alibabacloud.com' AS `Location`, 'Platinum Sponsor of the MariaDB Foundation' AS `Comment")
and that gets UNION ALLed with the second row, and so on.
The client passes this SELECT to the server, and gets back a result as a select result set.
Or, in summary, what the client must do is: Pass the SHOW to the server, intercept the result, convert to a tabular form, send or SELECT … UNION ALL SELECT …; to the server, display.
However, these steps are all hidden. the user doesn’t have to care how it works.
Limitations
It requires two trips to the server instead of one. The client log will only show the semiselect, but the server sees the SELECT UNION too.
It will not work inside routines. You will have to CREATE TEMPORARY TABLE AS semiselect; before invoking a routine, in order to use the semiselect’s result set inside CREATE FUNCTION | PROCEDURE | TRIGGER.
Speaking of CREATE TEMPORARY TABLE AS semiselect, if there are VARCHAR columns, they will only be as big as the largest item in the result set.
It will not work inside CREATE VIEW.
Sometimes it will not work with nesting, that is semiselects within semiselects might not be allowed.
Some rare situations will expose the SELECT result in very long column names.
Try it today if you can build from source
On Linux this is easy — download libraries that ocelotgui needs, download ocelotgui, cmake, make. (On Windows it’s not as easy, sorry.) The source, and the README instructions for building, are on github.
After you’ve started up ocelotgui and connected to a MySQL or MariaDB server, there is one preparatory step: you have to enable the feature. (It’s not default because these aren’t standard SQL statements.) You can do this by going to the Settings|Statement menu and changing the Syntax Checker value to 7 and clicking OK. Or you can enter the statement
SET OCELOT_STATEMENT_SYNTAX_CHECKER = '7';
Now the feature is enabled and you can try all the examples I’ve given. You’ll see that they all work.
Of course it’s made available this way because the status is beta.
Try it a bit later if you can’t build from source
This will be available in executable form in the next release of ocelotgui, real soon now. If you have a github account, you can go to the github page and click Watch to keep track of updates.
Update: the release happened on 2024-03-18, source and executables are at https://github.com/ocelot-inc/ocelotgui.
Packages in MariaDB default mode
MariaDB 11.4 has a new feature: CREATE PACKAGE with routine syntax for the default mode as opposed to sql_mode=’Oracle’. It’s a well-written and long-desired feature but, since it’s alpha, a few things might still need change. I’ll say how it works, with details that aren’t in the manual and probably never will be.
The point
A package is a group of routines (procedures or functions) for which I can CREATE and GRANT and DROP as a unit, all at once.
Roland Bouman wrote a feature request for it in 2005 for MySQL, but MySQL hasn’t got it yet, the workaround is to create whole databases. MariaDB has had CREATE PACKAGE since version 10.3 but only when sql_mode=’oracle’, and only with Oracle syntax (“PL/SQL”) for defining the routines.
Now MariaDB has CREATE PACKAGE with the default sql_mode, i.e. anything except sql_mode=’oracle’, and with ordinary standard-like syntax (“SQL/PSM”) for defining the routines. But it’s a bit of a hybrid because, although the routine definitions within the package are SQL/PSM, the CREATE PACKAGE statements themselves are not.
Package versus Module
CREATE PACKAGE is a PL/SQL statement. CREATE MODULE is the SQL/PSM statement for something functionally very similar.
Here I compare the way MariaDB creates packages versus the way the standard prescribes for modules. I ignore trivial clauses that appear in most CREATE statements.
The MariaDB way
+------------------------------------------------------------+ | CREATE PACKAGE package_name | | [ COMMENT or SQL SECURITY clause ... ] | | [ FUNCTION | PROCEDURE name + COMMENT or SQL clauses ... ] | | END | +------------------------------------------------------------+ +-------------------------------+ | CREATE PACKAGE BODY | | [ variable declaration ... ] | | | routine definition ... ] | | END | +-------------------------------+
The standard way
+-------------------------------------+ | CREATE MODULE module_name | | [ NAMES ARE character_set_name ] | [ [ SCHEMA default_schema_name ] | [ [ path specification ] | | [ temporary table declaration ... ] | | [DECLARE] routine-definition; ... ] | END MODULE | +-------------------------------------+
The most prominent vendor with CREATE PACKAGE is of course Oracle, but others, for example PostgreSQL and IBM, have it too.
The most prominent vendor with CREATE MODULE is IBM but Mimer has it too.
The basic example
So the absolute smallest example of statements that have all the relevant features is:
CREATE PACKAGE pkg1 PROCEDURE p1(); FUNCTION f1() RETURNS INT; END; CREATE PACKAGE BODY pkg1 DECLARE var1 INT; FUNCTION f1() RETURNS INT RETURN var1; PROCEDURE p1() SELECT f1(); SET var1=1; END; SELECT pkg1.f1(); CALL pkg1.p1(); SHOW CREATE PACKAGE pkg1; SHOW CREATE PACKAGE BODY pkg1; GRANT EXECUTE ON PACKAGE db.pkg TO PUBLIC; DROP PACKAGE pkg1;
Documentation and Terminology
In the Canadian Football League there used to be an official term “non-import” for a player who, essentially, wasn’t from the States or Europe or Samoa etc. This caused some complaint because there were simpler terms, like, um, “Canadian” or “national” i.e. native.
Eventually the League realized that adding “non-” was being negative about the default player situation.
I was reminded of that when reading the MariaDB manual, which now has split up the sections for CREATE PACKAGE and CREATE PACKAGE BODY to put “Oracle mode” and “non-Oracle mode”. I am hopeful that someday MariaDB, like the Canadian Football League, will come up with a less negative term such as “default”, or “when sql_mode is the default”. Also I am hopeful — here I speak as the former head of documentation for MySQL — that there will be rearrangement so that the default is shown first, as it will be more important than sql_mode=’oracle’, won’t it?
Another change will happen soon — perhaps by the time you read this — to the BNF. Currently it is
CREATE
[ OR REPLACE]
[DEFINER = { user | CURRENT_USER | role | CURRENT_ROLE }]
PACKAGE [ IF NOT EXISTS ]
[ db_name . ] package_name
[ package_characteristic ... ]
[ package_specification_element ... ]
END [ package_name ]
… which is wrong, adding [ package_name ] after END will just cause an error.
And later
package_specification_function:
func_name [ ( func_param [, func_param]... ) ]
RETURN func_return_type
[ package_routine_characteristic... ]
… which is wrong, it should be RETURNS not RETURN.
Also, since CREATE FUNCTION documentation says “RETURNS type” not “RETURNS func_return_type”, there’s no need to introduce a new term here.
As for CREATE PACKAGE BODY the default mode BNF is undocumented, only Oracle mode BNF is documented. So my description above might be missing some detail, for example maybe it’s possible somehow to declare package-wide cursors and handlers as well as variables.
Error messages
I see two package-related error messages in sql/share/errmsg-utf8.txt
"Subroutine '%-.192s' is declared in the package specification but is not defined in the package body"
and
"Subroutine '%-.192s' has a forward declaration but is not defined"
… which is wrong, there is no such thing as a subroutine, the term is “routine”. (Oracle has a thing called “subprogram” but it too would be a wrong term.)
After I create a package named pkg6 with a procedure p1, if I say
DROP PROCEDURE pkg6.p1;
I get told “PROCEDURE pkg6.p1 does not exist”.
… which is wrong, pkg6.p1 does exist, I can CALL it. It would be better to re-use the message “The used command is not allowed with this MariaDB version”. (Yes, it’s a statement not a command, but I can’t ask for the moon.)
If I say
GRANT EXECUTE ON PACKAGE no_such_package TO PUBLIC;
I get told “FUNCTION or PROCEDURE no_such_package does not exist”
which is wrong, I’m trying to grant on a nonexistent package not a nonexistent routine.
Qualifiers
Suppose we have a package named pkg containing a procedure p1. “CALL p1();” is legal inside another routine in the same package, but outside the package we have to add a qualifier: “CALL pkg.p1();”.
Here is an example that shows why this is dangerous. (Delimiters added so mysql client understands.)
DROP DATABASE pkg; DROP PACKAGE pkg; CREATE DATABASE pkg; CREATE PROCEDURE pkg.p1() SELECT 'database'; CALL pkg.p1(); DELIMITER $ CREATE PACKAGE pkg PROCEDURE p1(); END; $ DELIMITER ; DELIMITER $ CREATE PACKAGE BODY PKG PROCEDURE p1() SELECT 'package'; END; $ DELIMITER ; CALL pkg.p1();
…
The first “CALL pkg.p1();” will display “database”, the second “CALL pkg.p1();” will display “package”. The package has shadowed the database!
People can avoid the danger by adopting a naming convention that database names and package names will always have different prefixes, but they won’t.
Or people can “fully” qualify the package’s P1 by saying “CALL [database_name.].[package_name.].p1();”. But they cannot “fully” qualify the database’s P1 by saying “CALL [catalog_name.][database_name.]p1();” — you’ll see a CATALOG_NAME column in INFORMATION_SCHEMA tables, but it is useless.
Therefore MariaDB should emit a warning message when there’s ambiguity, or support a different qualifier syntax. I’m hopeful that will happen in some future version.
By the way, Mimer “solves” this by disallowing: “The module name is never used to qualify the name of a routine.” It’s unstated, but I suppose this would mean that no two procedures can have the same name in the same schema, even if they are in different packages of the schema.
Also the standard allows SCHEMA and PATH which might be another way to evade the ambiguity, but it’s not necessary.
Metadata
The obvious question after creation is: how can I see what’s in a package?
SHOW CREATE PACKAGE works. SHOW CREATE PACKAGE BODY works.
SHOW PACKAGE STATUS works. SHOW PACKAGE BODY STATUS works.
But they’re SHOW statements and therefore they’re no good.
In INFORMATION_SCHEMA.ROUTINES the package will appear with routine_type = ‘PACKAGE’ and routine_definition = ‘procedure pkg(); end’.
This is odd because
(a) a package is not a routine
(b) there is no procedure named pkg
(c) the actual routine is not a row in information_schema!
I can dig the routine out of another row that has routine_type = ‘PACKAGE BODY’ but I can do it because I have an SQL parser available, other people would be stalled because the body is a mishmash of routines and contents.
Similar cluttering occurs for mysql.proc, although at least there I see PROCEDURE and FUNCTION entries. Remember that the the ‘body’ field might be blank unless you have appropriate privileges.
The obvious answer, similar to what the standard has, is: put routines in INFORMATION_SCHEMA.ROUTINES, and add a PACKAGE_NAME column. Probably something needs to be added to mysql.proc too. Until that happens, since SHOW is not useful, getting metadata for package routines is awkward.
The answer hasn’t appeared in code yet but I’ll assume that what’s obvious will happen.
Variables
I can declare variables that are accessible from all routines in the package. This is possible in CREATE PACKAGE BODY and alas might soon be in CREATE PACKAGE too, if this is done.
Here is an illustration.
DELIMITER $
CREATE OR REPLACE PACKAGE BODY pkg
-- variable declarations
DECLARE a INT DEFAULT 11;
DECLARE b INT DEFAULT 10;
FUNCTION f1() RETURNS INT
BEGIN
SET a=a-1;
RETURN a;
END;
-- routine declarations
PROCEDURE p1()
BEGIN
SELECT a,f1(),a;
END;
-- package initialization section
SET a=a-b;
END;
$
DELIMITER ;
And the question is: what should “CALL pkg.p1();” display?
If you guessed 1, 0, 0 then good for you, but notice what’s unpleasant here. First: we have a procedure’s variable’s value being changed in a way that the procedure doesn’t see. Second: the value changes between the first time it’s selected and the second time it’s selected, in the same statement.
Now, This won’t startle any experienced person, since MariaDB user variables (the ones whose names start with ‘@’) have always worked that way. But I can’t think of any case where that can happen with a DECLAREd variable, so it might startle people who have only worked with standard-like syntax.
I like globals, but I am just expecting that some people will consider it should be noted in a style guide. One of the suggestions I’ve seen (for Oracle) is that package variables are a way to do “constants”. I must emphasize, though, that I’m only talking about what some people might like in style guides, and I’m recognizing that many more people will see an advantage to sharing dynamic variables.
Private routines
Suppose I say
CREATE PACKAGE pkg12 PROCEDURE p1(); END; CREATE PACKAGE BODY pkg12 PROCEDURE p0() SELECT 5; PROCEDURE p1() CALL p0(); END; CALL pkg12.p1() /* This succeeds */; CALL pkg12.p0() /* This fails */;
Thus p0 is not in CREATE PACKAGE but p0 is in CREATE PACKAGE BODY. That is legal provided p0 comes before p1 (no forward references please). In this case p1 is a “public” routine — I can CALL pkg12.p1() from outside the package. However, p0 is a “private” routine — I cannot CALL pkg12.p0() from outside the package. I will see “Error 1305 (42000) PROCEDURE pkg12.p0 does not exist”.
Nothing against private, but since pkg12.p0 does exist, I think a message that’s more explicit would help somebody in ages to come. Otherwise, it should be made obvious. Probably a naming convention would be a good way to do that. A comment would not be a good way because many clients, including mysql and ocelotgui, have –skip-comments as a default.
Privileges
To allow CREATE PACKAGE (example);
GRANT CREATE ROUTINE ON w2.* TO k@localhost;
To allow EXECUTE of a package (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost;
This is a good thing, the usual privileges affecting routines will affect packages, as a whole. It’s a bit odd that a qualifier is necessary for GRANT but not for CALL; however.
To allow SHOW CREATE PACKAGE (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost; GRANT ALTER ROUTINE ON PACKAGE w2.pkg TO k@localhost;
This is a strange thing, currently one way to make SHOW CREATE possible is to grant ALTER ROUTINE.
ALTER
MariaDB has eleven ALTER statements, but ALTER PACKAGE is not one of them. Given that Oracle has one, and DB2 has ALTER MODULE, and it’s mentioned in a MariaDB document, I expect this will eventually be added with an excuse of “orthogonality”.
Debugger
The debugger in the Ocelot GUI does not yet work with routines inside packages. However, in a version which will be released soon, the “recognizer” will see MariaDB 11.4 syntax and be able to alert typists about what syntax is expected as they type, the same experience that they get for other statements.
This enhancement is already in the source code, in this patch.
Update
2024-02-15: MariaDB has done some fixes for the documentation matters that I mentioned, and there are plans for others in their bugs database, including: MDEV-33382 Documentation fixes for CREATE PACKAGE and CREATE PACKAGE BODY, MDEV-33384 ALTER PACKAGE [ BODY ] statement, MDEV-33385 Support package routines in metadata view, MDEV-33386 Wrong error message on `GRANT .. ON PACKAGE no_such_package ..`, MDEV-33395 I_S views to list stored packages, MDEV-33399 Package variables return a wrong result when changed inside a function, MDEV-33403 Document stored packages overview, MDEV-33428 Error messages ER_PACKAGE_ROUTINE_* are not good enough. For further developments follow MariaDB’s announcements. Meanwhile ocelotgui 2.2 has appeared which recognizes the new syntax.
Version 2.1
Ocelotgui, the Ocelot Graphical User Interface, version 2.1, is now available for download. The principal new feature is the chart modifications described in the last post, Charts. Packages are for Linux or Windows, compatible DBMSs are MySQL or MariaDB or Tarantool. Get description and instructions and clone source from GitHub Code area, or get the release from GitHub Releases area.
Charts
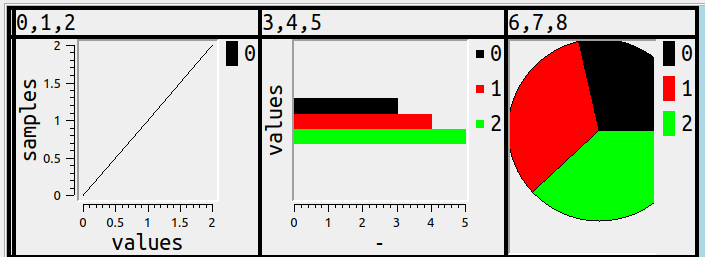
SELECT 0,1,2,3,4,5,6,7,8; result can look like this
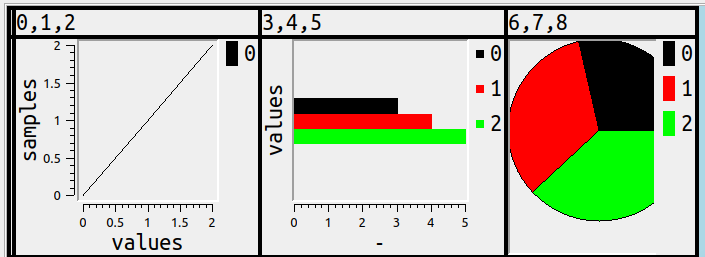
but should it?
I’ll try to cover here what would be an obvious way to show number columns in charts, or if not obvious then at least simple, or if not obvious or simple then at least understandable, or if none of the above, well, good looking.
The initial part of this description will look a bit like what you see with DB2 magic commands for bar or line or pie charts, but I like to think the later part of this description shows something more sophisticated.
Bars
Start with the most obvious: any group of numbers can be shown as a group of bars.
Should they be horizontal by default? That appears to be the less common choice, A Complete Guide to Bar Charts says “While the vertical bar chart is usually the default …”, ChartJs says “The default for this property is ‘x’ and thus will show vertical bars.”
But a SAS blog 3 reasons to prefer a horizontal bar chart persuaded me because, when we’re a GUI displaying an SQL result set, we usually have more room on the x (width) axis than on the y (height) axis.
Now, as for simpleness: that should mean there’s no extra work or time for exporting, manipulating in a non-SQL environment, learning Python, or even having to think — if the total time including user time is more than a second, that’s a fail. Therefore it has to be possible to get
SELECT 1,2,3;
which ordinarily displays as

to display as
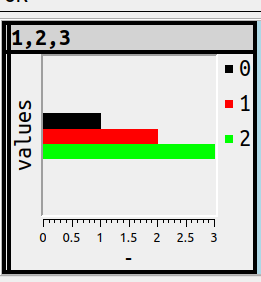
with a shortcut that includes a mnemonic. Therefore hitting Alt+Shift+B should switch immediately to the bar-chart display.
But it can get more complex, and that means users must enter instructions, and the only way to make that simpler is to provide instruction syntax that looks like SQL, thus:
SET ocelot_grid_chart = 'bar vertical';
… since users will know that SET value = literal is the SQL way to assign, and will know that ''s enclose literals, and will know what vertical means. So this is the result and it won’t be surprising:
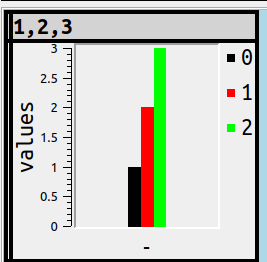
Another bar-chart variant is stacking, that is, putting 3 values in one bar instead of 3 side-by-side bars. For example
SET ocelot_grid_chart = 'bar stacked';
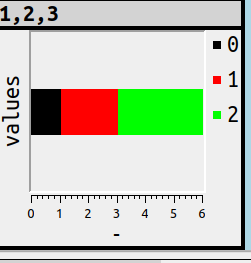
or
SET ocelot_grid_chart = 'bar vertical stacked';
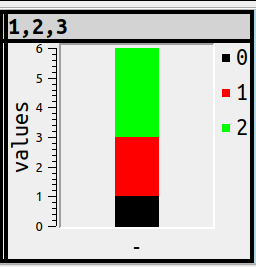
Lines
Lines are a bit less obvious than bars, because if there’s only one number in the series, they’re meaningless. Nevertheless, there should be a simple way to show a chart. Therefore Alt+Shift+L will cause
x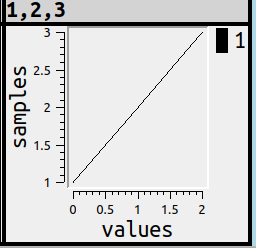
Maybe, although I suppose everyone has seen this sort of thing before, I should make some terminology notes around now …
X-axis: usually this is the horizontal, with the word “samples”
Y-axis: usually this is the vertical, with the word “values”
Legend: in the upper right corner, with a colour icon and a short indicator
Ticks: the tiny marks along the values, so users can see what the scale is.
For the French terms, see Statistique Canada.
But if users don’t know the terms, that’s fine, they understand the picture anyway.
Pies
Pies are obvious and simple too, all they require is
Alt+Shift+P or
SET ocelot_grid_chart='pie';
and SELECT 1,2,3; will look like this:
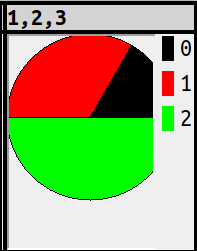
Fine. But putting numbers along the x-axis and y-axis wouldn’t be informative, and nobody has figured out what should happen with negative numbers. I think Microsoft Excel would take the absolute value, I think it makes more sense to ignore, but the point is: no solution is intuitive for all, therefore there’s a gotcha, therefore it’s not obvious and simple after all.
Groups
Every illustration so far has been simple, a 3-number series. There’s no complicated decision-making, the algorithm is just “if it’s a number, i.e. any of the data types that the DBMS fits in a general numeric category, it’s in, otherwise it’s out”.
It would follow, then, that
>SELECT 1,2,3,'',4,5,6,'',7,8,9;
would result in this if the setting was for bar charts:
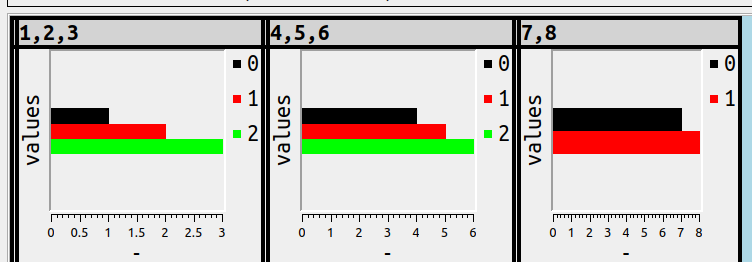
There are three “groups” here, and “groups” is a better word than “series” because GROUP is an SQL-standard term.
Subgroups
Now things get a bit more complex. What makes us decide that every individual numeric-column occurrence should be part of a separate bar or line or pie segment? Answer: nothing does, that’s simple but not really the best for representing some of the typical chart situations.
Take the possibility that all the columns which have something in common are combined. The commonness could be the value. For example
SET ocelot_grid_chart='bar vertical subgroup by value % 3';
SELECT 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15;
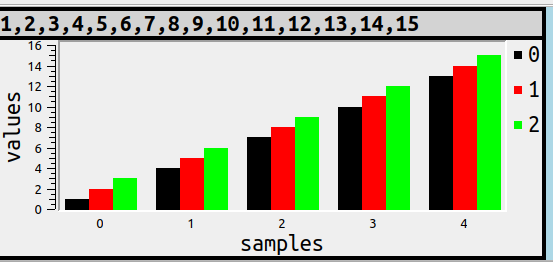
That is, the values which are divisible by 3 are together, but distributed across the landscape. Each of the things that are together are usually called “samples” if one uses chart terminology, and that’s why in this illustration the word “samples” appears at the bottom, and each subgroup has a separate colour, which is echoed by the legend.
More usefully, I think, the commonness could be the column_name prefix. The usefulness lies in the fact that users know how to put AS clauses after column names in the select list, so they can determine what the subgroups are. For example
SET ocelot_grid_chart='bar vertical subgroup by left(column_name, 1)';
SELECT 1 AS x_1, 2 AS y_1, 3 AS z_1, 4 AS x_2, 6 AS y_2, 7 AS z_2;
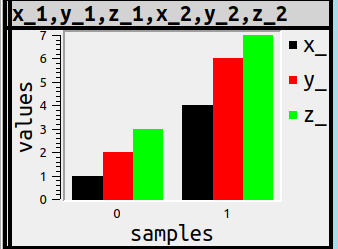
There might be other criteria for deciding how to subgroup, but they’re probably less important. What’s important is that once again the syntax is something any SQL user will understand.
Actually the word that chart-lovers prefer here is “categories”, and “subgroups” isn’t really a word you’ll find in typical SQL, but at the moment I’m thinking it’s “SQL-ish”.
Nulls
Since this is SQL, NULLs exist.
There’s no such thing as obvious when NULL might mean unknown or inapplicable, but this isn’t Oracle so it would be too trite to say NULLs are zeros, at least when it’s possible to hint otherwise. Thus
SET ocelot_grid_chart='bar vertical subgroup by left(column_name, 1)';
SELECT 1 AS m, 2 AS m, 3 AS m, 4 AS o, 5 AS o, NULL AS o;
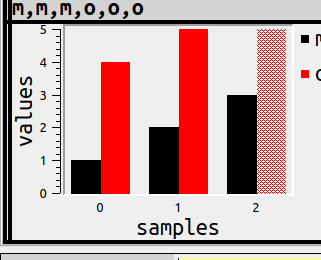
doesn’t use a solid colour, but has the same size as whatever the largest bar is.
I worry that by now we’ve evolved from “obvious” to merely “understandable”, so I’ll explain this example more deeply. In this example there are three samples of ‘m’ and ‘o’. The first sample, label 0, has the first ‘m’ and it has value = 1, the black bar, and it has the first ‘o’ and it has value = 4, the red bar. Sample 1 has the second ‘m’ and the second ‘o’. Sample 2 has the third ‘m’ and ‘o’, and, since the third ‘o’ is NULL, it is not solid. The legend in the right corner is helpful for showing that
black is ‘m’ and red is ‘o’.
WHERE clauses
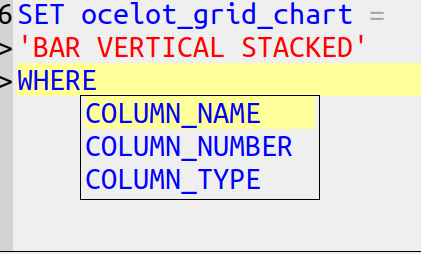
But surely not every numeric column should always be in a chart? I think of column names that end with ‘_id’, or the possibility that one will want to display both the chart and the numbers as text.
The SQL syntax for deciding what’s in a group could be CASE … WHEN, or IF … THEN, but what even the novice SQL user has seen is WHERE. The condition could be COLUMN_NAME relative-operator value, COLUMN_NUMBER relative-operator value, COLUMN_TYPE relative-operator value. By the way, since this is a GUI, users will see hints for autocompletion when they type WHERE, for example
and after
SET ocelot_grid_chart='bar vertical stacked' WHERE column_type = 'integer';
SELECT 1,1.1,2,7,-44;
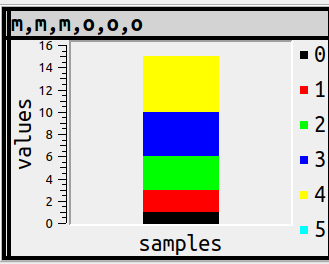
the result will not include 1.1 in a chart because it is not an integer.
And this is where it becomes possible at last to show the statements that caused the example at the start of this post, where some of the columns were in a bar chart, some in a line chart, and some in a pie.
SET ocelot_grid_chart = 'line' WHERE column_number <= 3;
SET ocelot_grid_chart = 'bar' WHERE column_number >= 4 AND column_number <= 6;
SET ocelot_grid_chart = 'pie' WHERE column_number > 6;
SET ocelot_grid_chart = '' WHERE column_number > 100;
SELECT 0,1,2,3,4,5,6,7,8;
and we’ve arrived at the example we started with.
Turning it off
Alt+Shift+N or
SET ocelot_grid_chart='';will erase all earlier chart statements. So there’s a simple way to go back to the regular way to display results.
Source Code
My main purpose describing all this is to show what the design of a GUI should look like, if my observations about goals make sense.
The illustrations show what the implementation looks like as of today, they’re screenshots of ocelotgui, and they work as I’ve described. But currently they’re only distributed in source code. Anyone who wants to reproduce them today can download the source from github, follow the special build instructions in file chart_options.txt, connect to MySQL or MariaDB or Tarantool, and see the same things. You will notice that you need to use the Qwt library, which should be no problem (ocelotgui is GPLv2, Qwt is LGPL, Qwt is on many distros). Pay no attention to the bug in the room.
But I’m not sure whether to call this the final look for the next executable release. Let me know in the comments if I’m missing tricks.
SQL:2023 and how well MySQL and MariaDB comply
SQL:2023 is now the official SQL standard. I’ll compare some of the new optional features with what MySQL and MariaDB support already, and say whether I judge they are compliant.
At the moment I don’t have draft documents (my membership on the standard committee ended long ago), so I gratefully get my news from Oracle and Peter Eisentraut. It’s early days, I may be making mistakes and may be guessing wrong about what new features are important.
LPAD and RPAD
MySQL and MariaDB examples:
SELECT LPAD('hi',3,'?'); causes '?hi'.
SELECT RPAD('hi',3,'?'); causes 'hi?'.
Judgment: compliant with SQL:2023 optional feature T055.
The third argument is optional and default is the space character. For some reason I’m not seeing the documentation in the manuals, but it is standard behaviour.
LTRIM and RTRIM and BTRIM
MySQL and MariaDB examples:
SELECT LTRIM(' *'); -- causes '*'.
SELECT RTRIM('* '); -- causes '*'.
Judgment: not compliant with SQL:2023 optional feature T056.
Although SQL:2023 now has LTRIM and RTRIM, they are two-argument,
perhaps a bit like Oracle.
Also SQL:2023 has BTRIM for trimming from both ends. Although MySQL and MariaDB have TRIM(BOTH …), it’s not quite the same thing.
VARCHAR instead of VARCHAR(length)
MySQL and MariaDB example:
CREATE TABLE t(s1 VARCHAR(1)); -- (length) is mandatory
Judgment: not compliant with SQL:2023 optional feature T081
A DBMS that supports feature T081 doesn’t have to include a maximum length, it’s up to the implementation, which in this situation could be 65535 bytes. This is unfortunate and it might be my fault, I think I used to insist that length should be mandatory in MySQL.
Although I can use the TEXT data type instead for indefinite-length strings, it has different characteristics.
ANY_VALUE, emphasizing use with GROUP BY
MySQL and MariaDB example:
SELECT s1, s2 FROM t GROUP BY s1;
Judgment: compliant with SQL:2023 optional feature T626, almost, alas
Probably you noticed that s2 is not in the GROUP BY clause, and yet the syntax is legal — any of the original t values could appear.
The standard would yield something similar with different syntax: SELECT s1, ANY_VALUE(s2) FROM t GROUP BY s1;
Or, as Oracle describes it, “[ANY_VALUE] eliminates the necessity to specify every column as part of the GROUP BY clause”.
That means it’s non-deterministic. Usually I’ve cared more about non-standardness. But now that argument is weaker.
ORDER BY, emphasizing use with GROUP BY
MySQL and MariaDB example:
CREATE TABLE t (s1 int, s2 int, UNIQUE (s2)); INSERT INTO t VALUES (1,1),(7,2),(5,3); SELECT s1 FROM t GROUP BY s1 ORDER BY s2;
Judgment: not compliant with SQL:2023 optional feature F868.
I’m probably misunderstanding something here about the intent, but the effect is that something that’s not in the GROUP BY clause can determine the ordering. In this case, because column s3 is unique, it’s maybe not utterly absurd. But in MySQL and MariaDB, the result is not guaranteed to be in order by column s3.
GREATEST and LEAST
MySQL and MariaDB syntax:
SELECT GREATEST(2,1,3); -- result = 3 SELECT LEAST(2,1,3); -- result = 1
Judgment: compliant with SQL:2023 optional feature T054
UNIQUE NULLS DISTINCT
MySQL and MariaDB example:
CREATE TABLE t (s1 INT, UNIQUE(s1)); INSERT INTO t VALUES (NULL),(NULL);
Judgment: partly compliant with SQL:2023 feature F292 unique null treatment
To understand this, your required reading is my old blog post
NULL and UNIQUE.
You have to read the whole thing to understand that the
standard document was not contradictory, and that MySQL
and MariaDB have always been compliant, because …
In a UNIQUE column, you can insert NULLs multiple times.
However, because lots of people never understood, there are implementations where you cannot do so. Therefore feature F292 allows new syntax:
CREATE TABLE t (s1 INT, UNIQUE NULLS DISTINCT (s1)); or CREATE TABLE t (s1 INT, UNIQUE NULLS NOT DISTINCT (s1));
MySQL and MariaDB could easily half-comply by allowing the first option and saying it is the default. (The standard now says the default is implementation-defined.) (A backward step.)
Hexadecimal and octal and binary integer literals
MySQL and MariaDB example:
SELECT 0x4141;
Judgment: not compliant with SQL:2023 optional feature T661
Did you notice that I said “integer literals”? That’s what’s wrong, 0x4141 in standard SQL is now supposed to be an integer, decimal 16705. But MySQL and MariaDB will treat it as a string, ‘AA’.
It is always legal for an implementation to have “non-conforming” syntax that causes “implementation-dependent” results. That’s what happened with 0x4141, in the mists of time. But now, if one decides to “conform” with the syntax of this optional feature, one must change the behaviour drastically: not merely a different value but a different data type.
I suppose that the road to compliance would involve deprecations, warnings, sql_mode changes, etc., lasting years.
Underscore digit separators
MySQL and MariaDB example:
CREATE TABLE t (10_000_000 INT); INSERT INTO t VALUES (1); SELECT 10_000_000;
Judgment: not compliant with SQL:2023 optional feature T662 Underscores in numeric literals
Big numbers like 10,000,000 cannot be expressed in SQL using commas because that looks like three separate values. The solution, which I see was implemented a few years ago in Python, is to express 10,000,000 as 10_000_000 — that is, underscores instead of commas.
In standard SQL, an identifier cannot begin with a digit. But in MySQL and MariaDB, it can, so 10_000_000 is a legal regular identifier. This is another example of an extension that causes trouble in a long term.
There is an idiom about this, usually about chickens: “come home to roost”. As Cambridge Dictionary puts it: “If a past action, mistake, etc. comes home to roost, it causes problems at a later date, especially when this is expected or seems deserved …”
JSON
MariaDB example:
CREATE TABLE t (s1 JSON);
Judgment: partial compliance with SQL:2023 feature T801 JSON data type etc.
I’m not going to try to analyze all the new JSON options because it’s a big subject. Also there’s a CYCLE clause and a new section of the standard, part 16 Property Graph Queries (SQL/PGQ), which I don’t think is appropriate to get into during this comparison of features in the foundation. Maybe some other time.
Score
Actually, despite pointing to some non-compliance, I have to give credit to the people who decided to implement some features long before they became standard. (And I don’t credit myself at all because they appeared before I was a MySQL architect, and in fact I objected to some of them while I was with MySQL AB.)
Well done.
ocelotgui news
The new version of the Ocelot GUI application, ocelotgui, is 2.0. As always the source and executable files are on github. The biggest new feature is charts. I’ll say more in a later blog post.
Update added 2023-06-12: Re ANY_VALUE: see comment by Øystein Grøvlen. As for the question from Federico Razzoli, I cannot give an authoritative answer. Also I’ve been reminded that MariaDB request MDEV-10426 regarding ANY_VALUE is marked as part of MariaDB 11.2 flow, but until then I guess MySQL is a bit ahead.
Delimiters in MySQL and MariaDB
In the SQL standard delimiters are for separating tokens; in MySQL/MariaDB they’re for ending statements, particularly compound statements as in
CREATE PROCEDURE p() BEGIN VALUES (5); END;
The problem is that a dumb client could stop at the first semicolon “;” in the statement (the one after VALUES (5)) instead of the one that truly ends (the one after END). The solution is to say that semicolon is no longer the default delimiter, and the way to specify a replacement is with a non-standard DELIMITER statement, such as
DELIMITER //
and after that the true statement end is //.
The idea isn’t unusual — in PostgreSQL’s psql client you can enclose compound statements with $$ which they call dollar quoting, with Microsoft you get used to saying “go” when you want something shipped to the server, with Oracle you might sometimes see SQLTERMINATOR. But it shouldn’t always be necessary — despite the fact that words like BEGIN are not reserved, a client with even a slight ability to recognize syntax can see where a compound statement ends without needing special tags.
Quirks
Some DELIMITER quirks are documented in either the MySQL manual or MariaDB manual, some are common to all mysql-client commands, but all are weird. They are:
() DELIMITER itself is not delimited
() After DELIMITER A B the delimiter is A
() After DELIMITER A; the delimiter is A;
() After DELIMITER 12345678901234567890 the delimiter is 123456789012345
() After DELIMITER ‘x’ or DELIMITER “x” or DELIMITER `x` the delimiter is x
() After DELIMITER ;; the delimiter is ;;
() Delimiters inside comments or character string literals or delimited identifiers are ignored
() After \dA the delimiter is A (\d is a substitute for DELIMITER and no space is necessary)
() After DELIMITER \ the effect can be odd, the MySQL manual recommends not to use \
() SELECT 5; DELIMITER ; will cause an error message
() DELIMITER ;; followed by SELECT 5;;; has a different effect from DELIMITER // followed by SELECT 5;//
() \G and \g will work whether or not there is a delimiter
It is not a gotcha that, when statements are in a .sql file and read by the SOURCE file-name statement, the rules are different: Compound statements will be recognized without special delimiters, and semicolons will always end non-compound statements even after a different delimiter has been specified.
It is not a quirk or a gotcha, it’s merely bad design, that DELIMITER forces the fundamental requirement of a parser — the tokenizer — to change what the tokenizing rules are while the tokenizing is going on.
Best practice
Both the MySQL and the MariaDB manual have example statements where the delimiter is // and that’s unlikely to cause confusion, since the only other uses of / are as a beginning of a bracketed comment or as a division operator, or in arguments to PROMPT or SOURCE or TEE.
Less frequently there is a recommendation for $$ but that is bad because $$ can occur inside regular identifiers.
DELIMITER !! is equally bad because !, unlike /, is a repeatable operator, for example SELECT !!5; returns 1.
DELIMITER ;; is worse and has caused bugs in the past, but the mysqldump utility will generate it before CREATE TRIGGER statements.
Avoid non-printable or non-ASCII characters, some clients will support them but others won’t.
You could set a delimiter at the start of a session and let it persist. But I believe the more common practice is to put DELIMITER [something appropriate] immediately before any CREATE PROCEDURE or CREATE TRIGGER or CREATE FUNCTION or BEGIN NOT ATOMIC statement, and DELIMITER ; immediately after. This might help readability by humans since otherwise they’d look at statements that end with mere semicolons and assume they’d go to the server immediately, not realizing that long ago there was a DELIMITER statement.
See also the Descriptive SQL style guide section “Semicolons”.
ocelotgui
The ocelotgui client doesn’t need DELIMITER statements because obviously a client that includes a stored-procedure debugger can recognize compound statements, but it will accept them because it tries to be compatible with the mysql client. It does not duplicate mysql client behaviour for the SOURCE statement but that should be fixed in the next version, and the fix is now in the source code which can be downloaded from github.
Draw Database Diagrams
It’s pleasant to admire drawings of database tables and their foreign-key relationships, which are
“data structure diagrams”
or more grandiosely
“entity relationship (ER) diagrams”.
I’ll show what the esthetic considerations are i.e. “does this look nice”,
and what the engineering considerations are i.e. “what do I have to do to make it at all”.
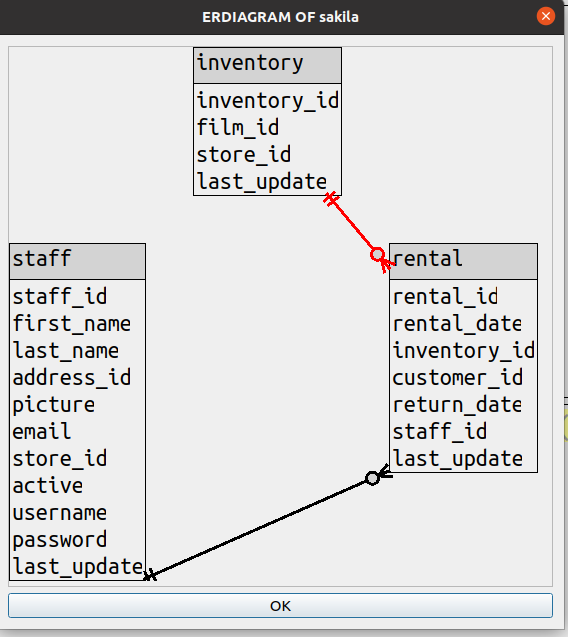
I’ll begin with the conclusion — here is a drawing of the well-known sakila database.
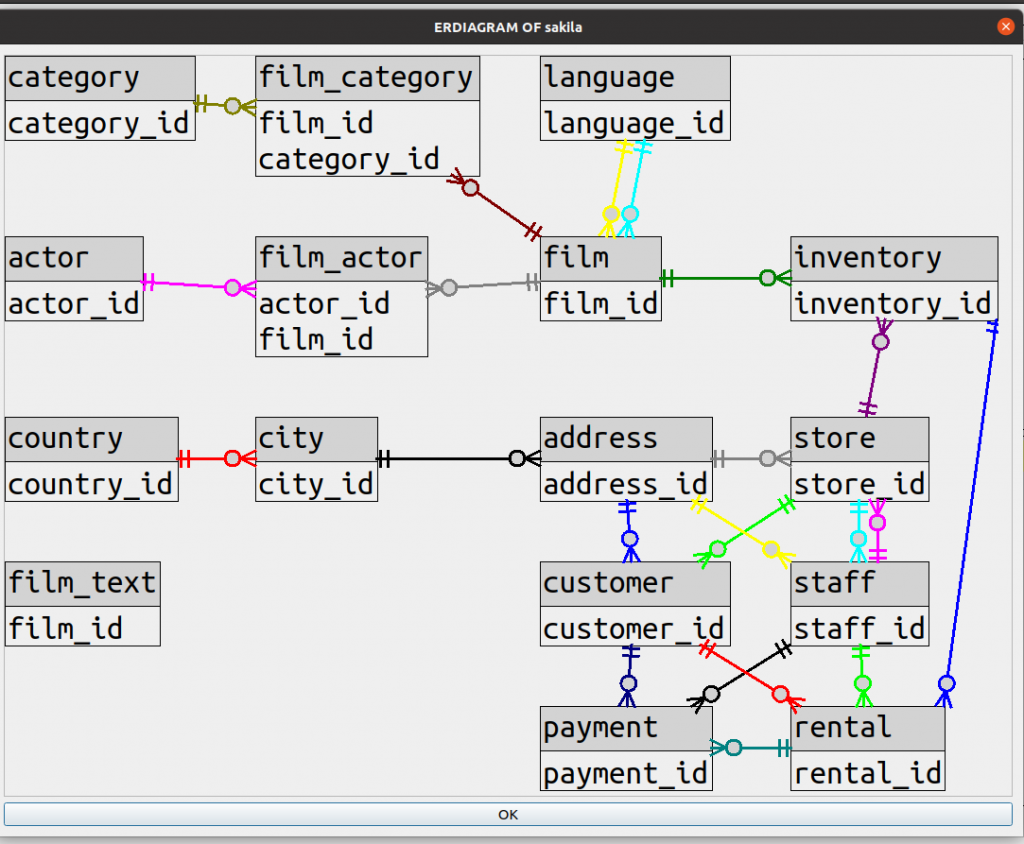
To find diagrams that other products draw for the same database, just google “sakila er diagram”.
You’ll see something like this:
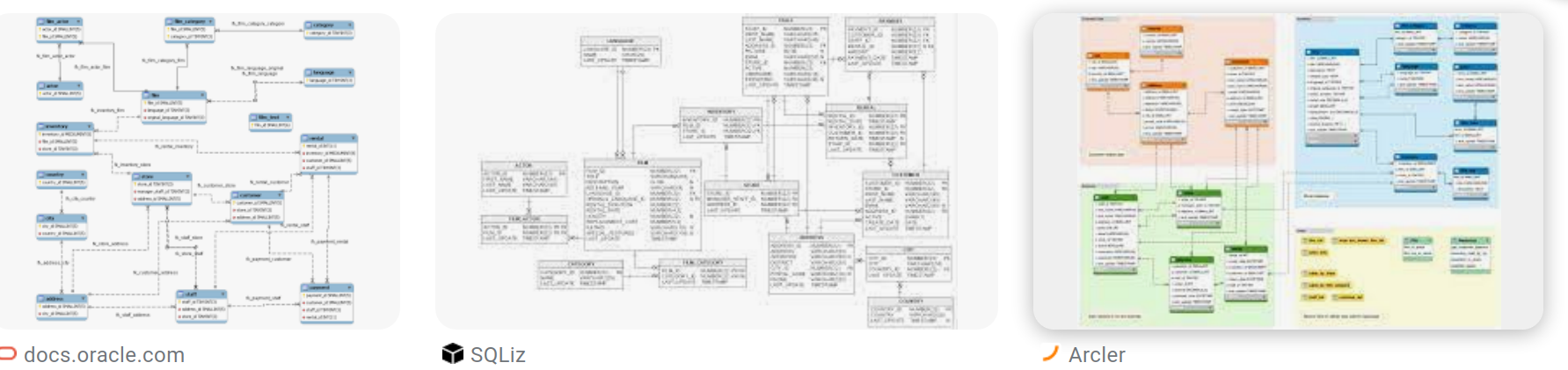
and what I’m trying to address first is: who’s the fairest?
Esthetics
Esthetics, also spelled aesthetics, is “the formal study of the principles of art and beauty”. And there really have been formal studies where academics look for criteria that people judge are important. A fine description is in a Radboud University thesis by Bart van de Put, “Scoring Entity-Relationship Diagrams Drawn by a Computer Algorithm”. I will consider five criteria that the thesis mentions:
![]() Bends when a line makes a sharp direction change.
Bends when a line makes a sharp direction change.
![]() Crossings when two lines intersect or nearly intersect.
Crossings when two lines intersect or nearly intersect.
![]()
Edge non-orthogonality when lines are not all horizontal or vertical with right angles.
![]()
Node non-orthogonality when tables are not in a fixed rank-and-file grid.
![]() Inconsistent line lengths when some of a table’s relationships are short and others are long.
Inconsistent line lengths when some of a table’s relationships are short and others are long.
Although a computer program may not be great as a beauty contest judge, it can simply count bends and crossings, assign numeric weights to them, and come up with a negative score. Then picking for display a drawing with the best score can be achieved with brute-force comparisons or with functions that are slightly more sophisticated but enormously harder to write.
Bends
Unlike what happens in most of the google-result diagrams I mentioned above, I just declare “there are no bends”. All lines are straight, with many more angles than 90-degree up/down/left/right.
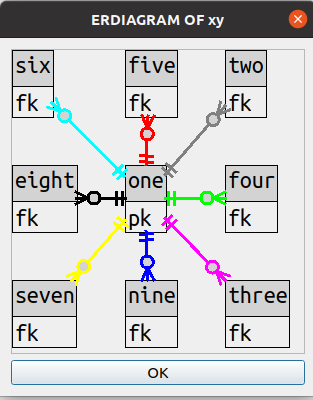
For example this is a table that had foreign-key relationships with 8 other tables.
Bend count: zero.
Let’s admit the downsides too:
(a) The original idea of structure diagrams was that lines could be done with as few as four ASCII characters
– | > <
and so were easy to reproduce. Drawing angles is perhaps technically possible with
ASCII art
but would need more screen space.
(b) In the situations where the classic style would bend around, the straight-line style will draw right through
a table. This can be illustrated with a sakila diagram that has all the columns, and the line between
rental and inventory goes right over the staff table.
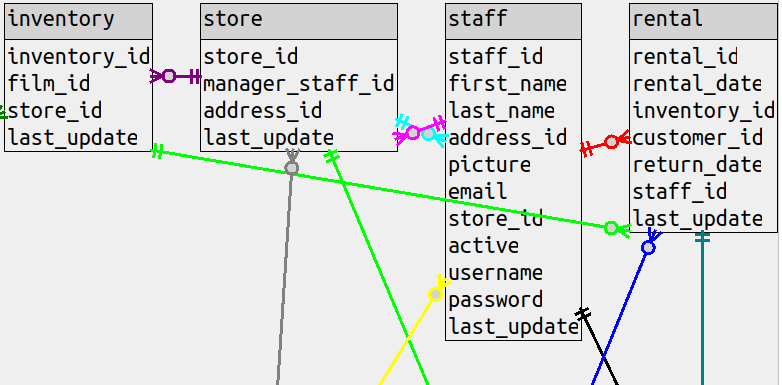
There’s an option to put the line in the background instead
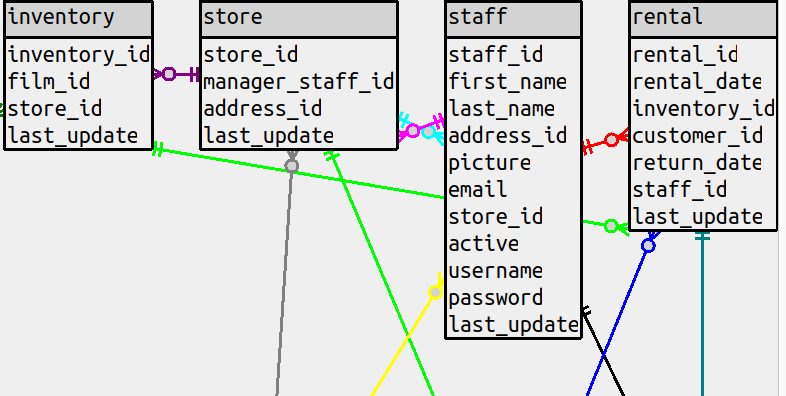
but either way, there’s an esthetic problem which should be weighted the same as a count of bends, or higher.
(c) we can’t put labels on any non-horizontal lines, so the only way to know the foreign-key constraint is to
hover over the line and wait for a tooltip to appear.
Crossings
Unlike the monochrome google-result diagrams I mentioned above, I just declare “different lines have different colours”. This has limited possibilities since the palette has to consist of only colours that are easily distinguishable and are not similar to the background colour, which would have a camouflage effect. So the practical limit is about a dozen colours. However, usually, when two lines are close or intersecting it’s easy to distinguish them.
Let’s admit the downside here too:
(a) this doesn’t reduce the number of crossings, it just patches over the problem
(b) it’s a matter of chance whether a bunch of colours is esthetic or not.
Edge non-orthogonality
The algorithm produces straight lines and almost no right angles so it is almost always edge non-orthogonal. As the Radboud University thesis says, edge non-orthogonality is considered a negative. But the thesis also admits that there are unnecessary bends otherwise. I’m giving bends more weight. I see in other products that edge orthogonality has more weight.
Node non-orthogonality
The algorithm places high weight on node orthogonality and one result is that tables are in fixed ranks and files, always. Again, this is unlike what I see in other products. I suppose that their criterion is compactness: if there are fewer spaces between tables, then there is less scrolling necessary to see the whole picture. So this is another case of a beautification with a downside, but I insist on it because of another consideration: specifiability.
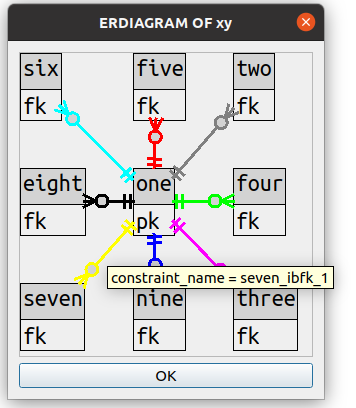
Users will sometimes want to specify, instead of “ERDIAGRAM OF whole_schema”,
“ERDIAGRAM OF schema TABLES (table-list)”. Once we allow that much, it’s reasonably simple
to allow for users to say which tables should go in which fixed positions. For example,
consider this specification
SHOW ERDIAGRAM OF sakila TABLES (staff 0 1, inventory 1 0, rental 2 1)
which results in this
Users can figure out graphic coordinates such as 0 1 “position 0 on the X axis position 1 on the Y axis”.
They would be , however, if the coordinates had to be pixel positions instead.
Having straight ranks and files makes it possible to specify with small integers.
By the way, the automatic production of drawings based on databases is sometimes called “reverse engineering”. So I suppose the appropriate term for specifying a diagram like this is “forward engineering”, but the real engineering job is of course the CREATE TABLE statements.
Positioning
Suppose we have three tables A B C, and A references C, well then we wouldn’t want to draw B between A and C, we’d want the diagram to look like A C B. In other words, if we could just get related tables to be drawn close to each other with no intervening tables, we’d have no bends. For a tiny number of tables this is easy to see and to fix. But as the number of tables grows the possible number of possible table positions in the drawing grows geometrically, like a travelling salesman problem. So positioning is far more difficult than bend denialism or crossings anti-camouflage.
The Radboud University thesis mentions a tried-and-mathematically-solid way to get the fewest bends with a large number of related tables. I saw it too late, though, so the method I implemented might be inferior. Also I might have saved time by bringing in the Open Graph Drawing Algorithm library, but didn’t.
The method is like crystal formation.
Start by drawing the table A that has the most relationships, either referencing-from or referenced-to. Then, for each table that A is related to, draw nearby (as closely as possible without interfering with other tables) the related tables … starting with the table B which is related to A which has the most relationships, and so on until there are no more. This involves a lot of recursion.
The initial result of a crystal formation is sometimes pretty good, and then there are last-microsecond patchups that can enhance it. Look for pairs of tables that are not near each other and see whether, if they were exchanged with each other or if one of them was moved close to the other, the total bend count for the table would go down. This usually helps just a little bit and adds more than a little bit to the computer time, so it can only go on for a limited number of looks.
Touchup
So much for the esthetics that are specifically for ER diagrams. I suppose I should add that there have to be further esthetic features that apply to widgets in general. The diagram must be changeable with respect to fonts, header and detail background colours, and line widths.
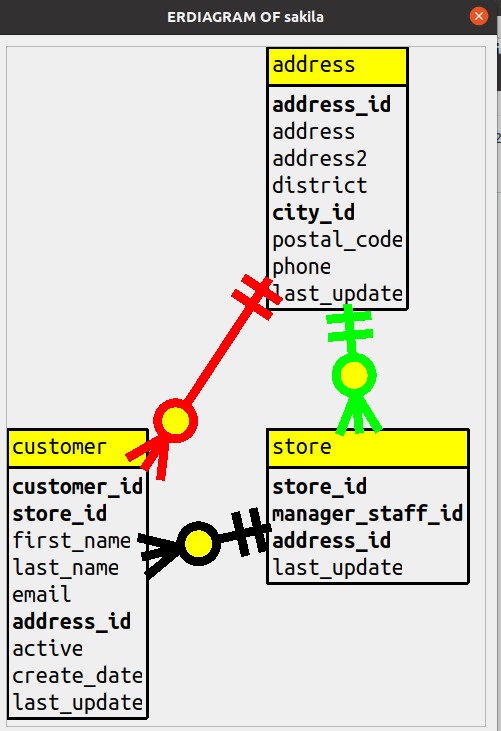
For example, for this diagram of a limited number of tables in sakila
I specified that column names ending with _id should be in bold, the lines should be extra wide,
and header background should be yellow.
(One thing users can’t change is the way that an arrow looks, the so-called Crow’s foot. At least one other product offers choices for this.)
I imagine that other high-class GUI clients can do such touchups so this is nothing special, but in a post about esthetics I figure I ought to mention this final step.
But where’s the SQL?
In this case the SQL statements are the easy part, especially if the DBMS supports SQL-standard INFORMATION_SCHEMA access.
All the necessary information about foreign-key relationships can be picked up with
SELECT … FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE …
There’s a quirk that is non-standard: your favourite DBMS insists that primary-key constraints must be
named PRIMARY, so KEY_COLUMN_USAGE has all we need for deciding which columns are part of the a primary key,
as well as which columns are part of a foreign key.
And if the user specifies that the drawing should have all columns instead of just primary-key columns,
SELECT … FROM INFORMATION_SCHEMA.COLUMNS WHERE …
does the job.
However, I don’t think it’s a good idea for the program to do those SELECTS every time the user asks for a drawing. They’re expensive on the server. (Rule: taking time on a client computer is trivial, taking time on the server might not be.) So this is done as part of an “explorer”, which means the user can slowly slowly pick up all the table and column and relationship information at once, so it’s stored in the local computer’s memory, and subsequent requests to draw don’t affect the server at all unless the user decides to refresh potentially-obsolete information.
ocelotgui
The feature I’ve just described comes with ocelotgui 1.9 which is available for download on github.
Foreign Key Displays
For foreign keys, I like to see what references what, It’s easy to find but the challenge is to decide how to display.
The cute
Showing a result with the mysql client:
prompt> call show_fk('t2');
+-------------+-----------------+------------+
| referencing | constraint_name | referenced |
+-------------+-----------------+------------+
| t2 | mx | t3 |
| s1 | | s1 |
| s2 | | s2 |
| | | |
| t2 | t2_ibfk_1 | t1 |
| s1 | | s1 |
+-------------+-----------------+------------+
6 rows in set (0.08 sec)
Query OK, 6 rows affected (0.08 sec)
That is, for table T2, I show the table name and foreign-key name and referenced-table name, then the columns of that table in the order they appear in the foreign key, then if there is another foreign key repeat after a blank line.
Here is a long but simple stored procedure that produces such a display.
DROP PROCEDURE show_fk;
CREATE PROCEDURE show_fk(ref_table_name VARCHAR(128))
BEGIN
DECLARE d_table_name VARCHAR(128);
DECLARE d_column_name VARCHAR(128);
DECLARE d_ordinal_position INT;
DECLARE d_constraint_name VARCHAR(128);
DECLARE d_referenced_table_name VARCHAR(128);
DECLARE d_referenced_column_name VARCHAR(128);
DECLARE counter INT DEFAULT 0;
DECLARE err INT DEFAULT 0;
DECLARE x CURSOR FOR
SELECT table_name, column_name, ordinal_position,
constraint_name,
referenced_table_name, referenced_column_name
FROM information_schema.key_column_usage
WHERE table_name = ref_table_name AND referenced_column_name IS NOT NULL
ORDER BY constraint_name, ordinal_position;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET err = 1;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION set err = 1;
CREATE TEMPORARY TABLE fks (referencing VARCHAR(128),
constraint_name VARCHAR(128),
referenced VARCHAR(128));
OPEN x;
WHILE err = 0 DO
FETCH x INTO d_table_name,d_column_name, d_ordinal_position,
d_constraint_name,
d_referenced_table_name, d_referenced_column_name;
IF err = 0 THEN
IF counter <> 0 AND d_ordinal_position = 1 THEN
INSERT INTO fks VALUES ('', '', '');
END IF;
IF d_ordinal_position = 1 THEN
INSERT INTO fks VALUES (d_table_name, d_constraint_name, d_referenced_table_name);
END IF;
INSERT INTO fks VALUES (d_column_name, '', d_referenced_column_name);
SET counter = counter + 1;
END IF;
END WHILE;
CLOSE x;
SELECT * FROM fks;
DROP TABLE fks;
END;
CALL show_fk('t2');
This is vaguely like an entity-relationship diagram, but with tables rather than pictures.
The flaws are: (1) it needs extra privileges, (2) it mixes different object types. So let’s look at the simpler and more common type of display.
The usual
Everything necessary can come from information_schema.key_column_usage.
For example, there’s a GUI that displays with these columns:
Name | Schema | Table | Column |Referenced Schema | Referenced Table | Referenced Column
That’s easy to reproduce with
SELECT constraint_name AS `Name`, table_schema AS `Schema`, table_name AS `Table`, column_name AS `Column`, referenced_table_schema AS `Referenced Schema`, referenced_table_name AS `Referenced Table`, referenced_column_name AS `Referenced Column` FROM information_schema.key_column_usage WHERE referenced_column_name IS NOT NULL ORDER BY constraint_name, ordinal_position;
Or if that takes too long to type, make a view.
There’s another GUI that displays with these columns:
Key name | Columns | Reference Table | Foreign Columns | On UPDATE | On DELETE
(The “On UPDATE” and “On DELETE” values would have to come from information_schema.referential_constraints.)
The objection that I’d make is that such headers are not standard. So anybody who knows the actual column names has to do a double take, wondering whether the first column is the same as “constraint_name” or something exotic, and so on. Use of multiple different names for the same thing is poetry not programming.
The new
So I think this display, which admittedly makes cosmetic changes (replacing ‘_’ with ‘ ‘ and changing upper case to mixed case and emphasizing one column) is better:
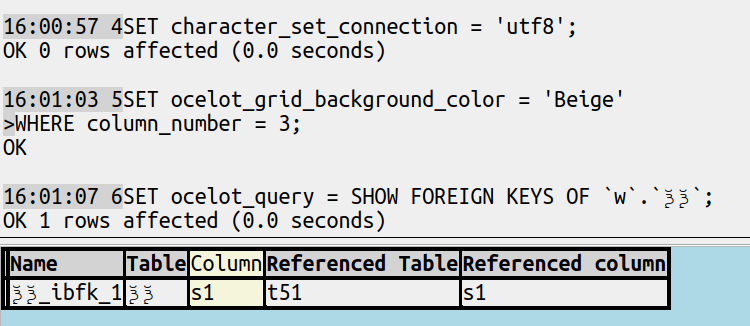
I’ve made it so that can come from user statements or from the explorer. The source code is downloadable now and the released executables will come soon.