About pgulutzan
View all posts by pgulutzan
Releasing ocelotgui 1.0.0
Today ocelotgui, the Ocelot Graphical User Interface for MySQL and MariaDB, version 1.0.0, is generally available for Linux. Read the manual, see the screenshots, and download binary (.deb or .rpm) packages and GPL-licensed C++ source here.
MariaDB 10.2 Window Functions
Today the first MariaDB 10.2 alpha popped up and for the first time there is support for window functions.
I’ll describe what’s been announced, what’s been expected, comparisons to other DBMSs, problems (including crashes and wrong answers), how to prepare, what you can use as a substitute while you wait.
I assume some knowledge of what window functions are. If you’d prefer an introductory tutorial, I’d suggest reading articles like this one by Joe Celko before you continue reading this post.
What’s been announced
The MariaDB sources are:
The release notes
The source code trees — the feature tree up till now has been github.com/MariaDB/server/commits/bb-10.2-mdev9543 but the version-10.2 download page has more choices and is probably more stable.
Sergei Petrunia and Vicentiu Ciorbaru, two developers who I think deserve the credit, made a set of slides for a conference in Berlin earlier this month. It seems to have some typos but is the best description I’ve seen so far.
On Wednesday April 20 Mr Petrunia will give a talk at the Percona conference. Alas, it coincides with Konstantin Osipov’s talk about Tarantool — which I’ve done some work for — which, if you somehow haven’t heard, is a NoSQL DBMS that’s stable and faster than others according to independent benchmarks like the one from Coimbra. What a shame that two such important talks are scheduled for the same time.
Anyway, it’s clear that I’ll have to update this post as more things happen.
What’s been expected
There have been several wishes / feature requests for window functions over the years.
Typical feature requests or forum queries are “Oracle-like Analytic Function RANK() / DENSE_RANK() [in 2004]”, “analytical function like RANK etc to be implemented [in 2008]”, “Is MySQL planning to implement CTE and Window functions? [in 2010]”.
Typical blog posts are Shlomi Noach’s “Three wishes for a new year [in 2012]” and Baron Schwartz’s “Features I’d like in MySQL: windowing functions [in 2013]”..
Typical articles mentioning the MySQL/MariaDB lack of window functions are “What PostgreSQL has over other open source SQL databases” and “Window Functions Comparison …”.
So it’s clear that there has been steady demand, or reason for demand, over the years.
My first applause moment is: Mr Petrunia and Mr Ciorbaru have addressed something that’s been asked for, rather than what they wished had been asked for.
Comparisons to other DBMSs
I know twelve DBMSs that support window functions. No screen is wide enough for a chart showing them all, so I’ll just list their windows-function documents here so that you can click on the names to get the details:
APACHE DRILL,
CUBRID,
DB2 LUW,
DB2 z/OS 10,
DERBY,
FIREBIRD,
INFORMIX,
ORACLE,
POSTGRESQL,
SQL SERVER,
SYBASE,
TERADATA. I’ll show MariaDB against The Big Three.
These functions are mentioned in the standard document as required by optional feature T611 ELementary OLAP operations:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| DENSE_RANK | yes | yes | yes | yes |
| RANK | yes | yes | yes | yes |
| ROW_NUMBER | yes | yes | yes | yes |
These functions are mentioned in the standard document as required by optional feature T612 Advanced OLAP operations:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| CUME_DIST | yes | yes | no | yes |
| PERCENT_RANK | yes | yes | no | yes |
These functions are mentioned in the standard document as required by optional features T614 through T617:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| FIRST_VALUE | no | yes | yes | yes |
| LAG | no | yes | yes | yes |
| LAST_VALUE | no | yes | yes | yes |
| LEAD | no | yes | yes | yes |
| NTH_VALUE | no | yes | no | no |
| NTILE | yes | yes | no | yes |
These are common functions which are in the standard and which can be window functions:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| AVG | yes | yes | yes | yes |
| COUNT | yes | yes | yes | yes |
| COVAR_POP/SAMP | no | yes | yes | yes |
| MAX | no | yes | yes | yes |
| MIN | no | yes | yes | no |
| SUM | yes | yes | yes | yes |
| VAR_POP/SAMP | no | yes | yes | yes |
Yes MariaDB also supports non-standard functions like BIT_XOR, but they’re worthless for comparison purposes. What’s more important is that the MariaDB functions cannot be DISTINCT.
As for the options in OVER clause … just the important ones …
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| ORDER BY | yes | yes | yes | yes |
| NULLS FIRST|LAST | no | “yes” | yes | no |
| PARTITION BY | yes | yes | yes | yes |
| PRECEDING|FOLLOWING | sometimes | yes | yes | yes |
Those are the options that matter. The NULLS clause is important only because it shows how far an implementor will go to support the standard, rather than because most people care. MariaDB in effect supports NULLS HIGH|LOW, which is as good as Oracle — The Oracle manual puts it this way: “NULLS LAST is the default for ascending order, and NULLS FIRST is the default for descending order.” People who think that’s not cheating can add a comment at the end of this post.
From the above I suppose this second applause moment is justifiable: MariaDB has all the basics, and half of the advanced features that other DBMSs have.
Problems (including crashes and wrong answers)
The MariaDB announcement says:
“Do not use alpha releases on production systems! … Thanks, and enjoy MariaDB!”
Indeed anyone who used 10.2.0 in production would discover that enjoyable things can be bad for you.
I started with this database: …
create table t1 (s1 int, s2 char(5)); insert into t1 values (1,'a'); insert into t1 values (null,null); insert into t1 values (1,null); insert into t1 values (null,'a'); insert into t1 values (2,'b'); insert into t1 values (-1,'');
The following statements all cause the server to crash:
select row_number() over (); select 1 as a, row_number() over (order by a) from dual; select *, abs(row_number() over (order by s1)) - row_number() over (order by s1) as X from t1; select rank() over (order by avg(s1)) from t1;
The following statements all give the wrong answers:
select count(*) over (order by s2) from t1 where s2 is null; select *,dense_rank() over (order by s2 desc), dense_rank() over (order by s2) from t1; select *, sum(s1) over (order by s1) from t1 order by s1; select avg(s1), rank() over (order by s1) from t1;
The following statement causes the client to hang (it loops in mysql_store_result, I think this is the first time I’ve seen this type of error)
select *, avg(s1) over () from t1;
And now for the third applause line … to which you might be saying: huh? Aren’t those, er, less-than-desirable results? To which I would reply: yes, but two weeks ago there were far more and far bigger problems. We should be clapping for how quickly progress has been made, and guessing that this section of my post will be obsolete soon.
How to prepare
You have lots of time to get ready for 10.2, but may as well start now by getting rid of words that have special meaning for window functions.
The word OVER is reserved.
The newly supported function names — DENSE_RANK RANK ROW_NUMBER CUME_DIST PERCENT_RANK NTILE — are not reserved, and the names of functions which will probably be supported soon — FIRST_VALUE LAG LEAD LAST_VALUE NTH_VALUE — will probably not be reserved. But they might as well be, because you won’t be able to use those names for your own functions. Besides, they’re reserved in standard SQL.
What you can use as a substitute
Suppose you don’t want to wait till MariaDB is perfect, or you’d like to stay with MySQL (which as far as I know has made less progress than MariaDB toward this feature). Well, in short: gee that’s too bad. But I have seen three claims about getting a slight subset.
One: Shlomi Noach claimss you can use a trick with GROUP_CONCAT:
Two: Adrian Corston claims you can make delta functions with assignments.
Three: I claim that in ocelotgui you can put ‘row_number() over ()’ in a SELECT and get a row-number column even with older versions of MySQL or MariaDB (this is a recent change, it’s in the source not the binary).
In fact all the “window_function_name() OVER ()” functions could be done easily in the client, if they’re in the select list and not part of an expression,
and the result set is ordered. But I’m not sure whether that’s something to excite the populace.
There might be a “Four:”. I have not surveyed the various applications that can do cumulations. I suspect that mondrian is one, and open OLAP might be another, but haven’t looked at them.
Our own progress
For ocelotgui (Ocelot’s GUI client for MySQL and MariaDB) we had to adjust the syntax checker to highlight the new syntax in 10.2, as this screenshot shows 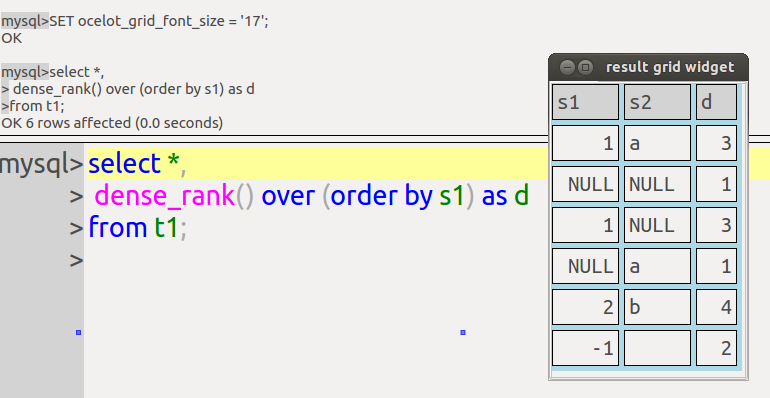
So we now can claim to have “the only native-Linux GUI that correctly recognizes MariaDB 10.2 window functions”. Catchy slogan, eh? The beta download is at https://github.com/ocelot-inc/ocelotgui. I still expect that it will be out of beta in a few weeks.
Client-Side Predictive Parsing of MySQL/MariaDB Grammar
The Ocelot GUI client for MySQL/MariaDB is now beta. The final feature is client-side predictive parsing of every SQL clause and statement. Readers who only care how we did it can skip to the section Recursive Descent Parsers”. I’ll start by illustrating why this is a good feature.
Error Checks
Compare this snapshot from mysql client:

with this from ocelotgui:
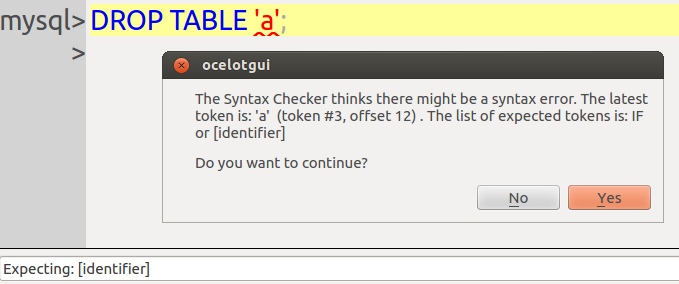
The GUI advantage is that the error message is more clear and the error location is more definite. This is not always true. However, anybody who dislikes the famous message “You have an error …” should like that there is another way to hear the bad news. It’s like getting an extra opinion.
In theory the further advantage is: this saves time on the server, because the client catches the syntax errors. In practice that should not be important, because: (a) ocelotgui is lax and can be erroneous; (b) there are better ways to catch some syntax errors before sending them to the server, for example setting up a test machine.
Finding the end
All respectable clients can scan an SQL statement to find its tokens. For example the mysql client knows that anything enclosed in quote marks, except a pair of quote marks, is a single token. This is pretty well essential, because it has to know whether a semicolon is just part of a string, or is the end of a statement.
Unfortunately a semicolon might not be the end of a compound statement, and that’s where simple “tokenizers” like mysql’s can’t cope. So in my MySQL days we had to come up with the concept of delimiters (I say “we” because I think the hassle of delimiters might have been my idea, but others are welcome to take the credit). It should be clear that a statement like
CREATE PROCEDURE p() BEGIN WHILE 0 = 0 DO ... END WHILE;
is not complete and should not go to the server, so it’s nice that we can say we don’t need delimiters.
But they still can have their uses. The scenario I dread is that a user has a spelling error, causing the client to think that input is complete, and shipping it off to the server prematurely. If there was some symbol that always meant “ship it!” and no other symbol ever meant “ship it!”, that would become unlikely. That’s what delimiters are. But we should have decided on a fixed unchangeable symbol instead of a user-defined one.
Highlighting
All respectable GUIs have highlighting, that is, they can display different colours for literals, operators, or keywords. But most GUIs cannot figure out what is a keyword, unless they ask the MySQL-server’s parser. The SQL problem is that there are two kinds of keywords: reserved words (which are guaranteed to have syntactic meaning if they’re not errors), and ordinary keywords (which might have syntactic meaning but might be identifiers, depending where they appear). An example statement is
CREATE PROCEDURE begin () end: BEGIN END;
where “end” and “begin” are identifiers, but BEGIN and END are not.
(A much easier problem is that you’d need two keyword lists, because in MySQL 5.7 GENERATED and GET and IO_AFTER_GTIDS and IO_BEFORE_GTIDS and MASTER_BIND and STORED and VIRTUAL are reserved words, but in MariaDB they’re not. But, since we don’t think the MariaDB manual’s reserved-word list is correct, we think those are the only reserved-word differences.)
So we have to beware of anything that depends on a list of keywords. For example my favoured editor is a variant of Kate, which recognizes a hodgepodge of symbols in its “SQL Keyword” list, and displays utterly useless highlighting when my file’s extension is .sql. Apparently Vim would be similar. Most clients that claim to work with MySQL or MariaDB are better than editors — they at least use a DBMS-specific keyword list rather than a generic one — and they’re generally good because in a sense they train users not to use keywords as identifiers. For example, if users see that “begin” has a non-identifier colour while they’re typing, they’ll avoid creating objects named “begin” even though it’s not a reserved word.
I’m not sure whether, in the wider SQL world, well known GUI clients have advanced past the keyword-list stage. I see hints here and there that SQL Server Management Studio has not and Toad has not, and Oracle SQL Developer has, but nothing explicit, and I repeat I’m not sure.
(UPDATE 2016-03-28: Mike Lischke’s description of Oracle’s new approach is here.)
In the end, then, a GUI with keyword-list highlighting will be right 90% of the time (I’m just guessing here, but I think it will sound right to experienced readers). On the other hand, a GUI that recognizes grammar should be right 97% of the time, and — just guessing again — I expect that’s preferable.
Predicting
The next step upwards in intelligence is knowing what the next token might be before the user starts typing it, or knowing how the current token ends before the user finishes typing it. And here, if you contemplate the Error Message example that we started with, you might realize: the MySQL/MariaDB server parser can’t do this. Which is why I emphasized right in the title: this is “predictive” parsing.
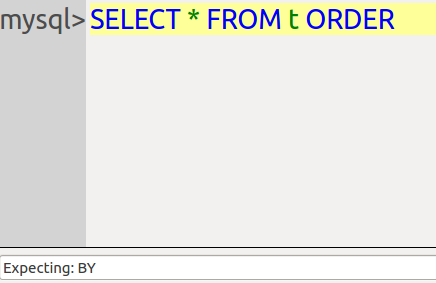
Example 1: suppose you’ve typed SELECT * FROM T ORDER. The GUI will show what the next word must be …
Example 2: suppose you’ve typed CREATE T. The GUI will show what possible words start with T …
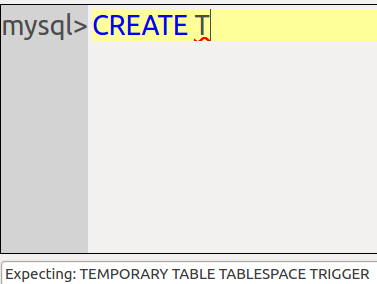
And in either case, hitting the Tab key will save a bit of typing time. I should note that “hitting the Tab key to complete” is something many can do, even the mysql client — but for identifiers not keywords. Technically we can do both, though we prefer to avoid discussing identifiers.
Initial Summary
For error checking, finding the end, highlighting, and predicting: whoopie for predictive parsing of the whole MySQL / MariaDB grammar.
As an additional point, I suppose it’s obvious that we wouldn’t have been able to incorporate a stored-procedure debugger in ocelotgui without parsing. Admittedly it is not using the new parsing code, but it is necessary for it to do a lot more than looking at keywords. So I class debugger capability as the fifth advantage of having client-side parsing.
Recursive Descent Parsers
The algorithms for recursive descent parsers are in most textbooks for compilers, and even in Wikipedia. The “recursive” means that the process can call itself; the rest of the algorithm looks like this:
If (next thing is X) accept it and get the next thing
if (next thing is Y) accept it and get the next thing
if (next thing is Z) accept it and get the next thing
…
else give up and say there’s an error.
Simple, eh?
Now for some quotes from those textbooks for compilers:
“The advantages of recursive descent parsers are that it’s easy to write, and once written, it’s easy to read and understand. The main disadvantage is that it tends to be large and slow.” — Ronald Mak, Writing Compilers And Interpreters, page 810
“The parser text shows an astonishingly direct relationship to the grammar for which it was written. This similarity is one of the great attractions of recursive descent parsing. … In spite of their initial good looks, recursive descent parsers have a number of drawbacks … repeated backtracking … often fails to produce a correct parser [text] … error handling leaves much to be desired.” — Dick Grune, Henri Bal, Ceriel Jacobs, Koen Langendoen, pages 117-119
And they’re right. Have a look at the parsing code of ocelotgui, which can be done by opening a source file here and searching for the first line that begins with “void MainWindow::hparse_f_” (line 9565 in today’s beta). Then scroll downwards till there are no more routines that begin with hparse_f_ — 5000 lines later. Readable, sure, because it’s the simplest of C code. But also tedious, repetitive, and yes, “large and slow”. And this is without knowing anything about object names, since it’s a purely syntactic syntax checker and won’t look at metadata.
On a server the disadvantages could be crippling, but on a client they don’t matter — the meanest laptop has megabytes to spare and the response time is still way faster than a user can blink. And SQL doesn’t require repeated backtracking because it’s rarely necessary to look ahead to the next tokens in order to figure out what the current token means. Here is the worst example that we ran into (I’m quoting the MariaDB 10.1 manual
GRANT role [, role2 ... ] TO grantee [, grantee2 ... ]
which can be instantiated as
GRANT EXECUTE, ROLE55 TO JOE;
See the problem? It’s perfectly okay for EXECUTE to be a role name — it’s not reserved — but typically it’s in statements like GRANT EXECUTE … ON PROCEDURE. So we have to look ahead to find whether ON follows, or whether TO follows. Which we did … and then found out that MariaDB couldn’t. I’d mentioned that this looked tough when I wrote about MariaDB roles two years ago. But for some reason it was attempted anyway and the inevitable bug report has been labelled “stalled” for a long time.
Oh, and one more detail that you’ll find in those compiler textbooks: correctly speaking, ocelotgui has a “recognizer” not a “parser” because it doesn’t generate a tree. That’s why I’ve carefully said it “does parsing” but not said it contains a parser.
Beta Status
The above represents the last feature that we intend to add. It’s at last “ocelotgui beta” rather than “ocelotgui alpha”. The C source and Linux executables, as usual, are at
https://github.com/ocelot-inc/ocelotgui.
Comments in SQL Statements
First I will say what the comment syntax is for various vendors’ dialects. Then I will get specific about some matters that specifically affect MySQL or MariaDB.
Syntax Table
| DBMS | –… | /*…*/ | #… | Nesting | Hints |
|---|---|---|---|---|---|
| Standard | YES | YES | NO | YES | NO |
| Oracle 12c | YES | YES | NO | NO | YES |
| DB2 | YES | YES | NO | YES | NO |
| SQL Server | YES | YES | NO | YES | NO |
| PostgreSQL | YES | YES | NO | YES | NO |
| MySQL/MariaDB | YES(99%) | YES | YES | NO | YES |
The first column is for the type of DBMS. “Standard” is the ISO/IEC SQL standard document. For the others, just click on the DBMS name to see the relevant documentation. The standard, incidentally, clarifies that strings of comments are to be treated as a newline, so if you hear somebody say “comments are ignored”, that’s slightly wrong.
The first column is for comments that begin with “–” (two hyphen-minus signs), what the standard document calls “simple comments”, the ones that look like this:
SELECT * FROM t; -- SIMPLE COMMENT
Everyone supports simple comments, the only problem with MySQL/MariaDB is their insistence that the — must be followed by a space. I’ve had it explained to me that otherwise the parser had problems.
The second column is for comments enclosed by /* and */, what the standard document calls “bracketed comments”, the ones that look like this:
SELECT * FROM t; /* BRACKETED COMMENT */
According to the standard document, bracketed comments are not mandatory, they are optional feature T351. However, it would be surprising to find a modern SQL implementation that doesn’t support them.
The third column is for comments that begin with “#” (what Unicode calls Number Sign but an American dictionary allows for the word Octothorpe ), the ones that look like this:
SELECT * FROM t; # OCTOTHORPE COMMENT
Notice how, in every row but the MySQL/MariaDB row, the key word is NO? In fact I’ve only encountered one other SQL DBMS that is octothorpophiliac: mSQL. Old-timers may recall that mSQL from Hughes Technologies was, for a while, an inspiration for one of MySQL’s founders. Anyway, it’s unnecessary because simple comments do the job just as well.
The fourth column is for nesting, that is, putting bracketed comments within bracketed comments, that look like this:
SELECT * FROM t; /* OUTER /* INNER */ COMMENT */
I’ve often been irritated that I can’t nest in C, so I approve of the DBMSs that support this standard requirement. But I never saw it as important in my MySQL-architect days. There were a few what I guess could be categorized
as “feature requests” (here and here and here) and I approved of my colleagues’ clear responses, it’s low priority.
The final column is for hints. A hint is a bit of syntax that the server might ignore, signalled by an extra character or two in a bracketed comment, like this:
SELECT /*+ HINT COMMENT */ * FROM t;
Typically a hint is a suggestion for an optimizer, like “use index X instead of the default”. It’s found in Oracle; it’s not found in PostgreSQL and some PostgreSQL folks don’t like it; but it’s found in EnterpriseDB’s “advanced PostgreSQL”; and of course it’s found in MySQL and MariaDB. A newish point is that MariaDB has an extra signal “/*M!###### MariaDB-specific code */” that MySQL won’t recognize, which is a good thing since the optimizers have diverged somewhat.
Passing comments to the server
In the MySQL 5.7 manual we see the client has an interesting option:
–comments, -c
Whether to preserve comments in statements sent to the server. The default is –skip-comments (discard comments), enable with –comments (preserve comments).
and a good question is: huh? Surely we should preserve comments, especially in stored procedures, no? Well, the obvious answer is that the parser has to spend time skipping over them, but I doubt that the effect is significant nowadays. The better answer is merely that behaviour changes are serious so let’s leave this up to the users. Our GUI client supports –comments too, which is no surprise since we support all mysql-client options that make sense in a GUI.
But what happens if it’s hard to tell where comments belong? Buried in the source download is a file named mysql-test/t/mysql_comments.sql which is checking these questions:
* Ignore comments outside statements, on separate lines?
* Ignore comments at the end of statements, on the same line but after the semicolon?
* Ignore comments inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT, but not in the body?
The test should be updated now that compound statements in MariaDB don’t have to be inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT.
Therefore
Steve McConnell’s “Code Complete” book advises: “A common guideline for Java and C++ that arises from a similar motivation is to use // synax for single-line comments and /* … */ syntax for larger comments.”
I guess that the equivalent for SQL purposes would be to say: use — for single-line comments and /* … */ for longer ones. But don’t use #, and be wary with standalone or endline comments, and turn –comments on.
Update
In an earlier blog post I predicted that ocelotgui, our GUI client for MySQL and MariaDB, would be beta in February. Now it’s February 29, so I have to modify that to: “any day now (watch this blog for updates or click Watch on the github project page)”. The latest feature additions are in the downloadable source code, by the way, but not in the binary release.
Privileges in MySQL and MariaDB: The Weed Of Crime Bears Bitter Fruit
Let’s look at how well MySQL and MariaDB support privileges (part of “access control” in standard terms), compared to other DBMSs, and consequences thereof.
Count the Privileges
I go to the DBMS manuals (here and starting here and here) and I count the privileges. This is like judging a town by the number of traffic lights it claims to have, but I’m trying to get an indicator for how granular the DBMS’s “authorization” is.
Number of privileges listed in the manuals MySQL/MariaDB Oracle 12c DB2 9.7 SQL Server 2014 31 240 52 124
Pretty small number in the first column, eh? There are historical reasons that MySQL was reluctant to add new privileges, illustrated by Bug#43730.
What is the effect of having a limited number of privileges? Sometimes the same privilege has to be used for two different things. For example, the SUPER privilege is good for “CHANGE MASTER TO, KILL, PURGE BINARY LOGS, SET GLOBAL, and mysqladmin debug command”, while the PROCESS privilege is what you need for SHOW PROCESSLIST — but also for selecting from information_schema.innodb_sys_tables.
Why is this a flaw? If administrators want to allow access to a goose, they are forced to allow access to a gander as well — even when the gander is none of the grantee’s business. As an example that affected us: to make Ocelot’s stored-procedure debugger work, we have to be able to set values in a single global variable, which is impossible without the SUPER privilege, therefore to allow people to use the debugger you have to allow them to purge binary logs too.
Standard Requirements
The SQL standard mentions 9 privileges: INSERT UPDATE DELETE SELECT REFERENCES USAGE UNDER TRIGGER EXECUTE. MySQL and MariaDB do a fair job of handling them:
INSERT: perfect support, including column-level grants.
UPDATE: perfect support, including column-level grants.
DELETE: perfect support.
SELECT: perfect support, including column-level grants.
REFERENCES: perfect support, not including column-level grants. I think this is not well known yet. Deep in the caverns of the manual are the words: “The REFERENCES privilege is unused before MySQL 5.7.6. As of 5.7.6, creation of a foreign key constraint requires the REFERENCES privilege for the parent table.” Kudos to MySQL. The MariaDB manual, on the other hand, still says the REFERENCES privilege is “unused”. For some background about this new feature, click the high-level architecture tab in the old worklog task Foreign keys: reference privilege.
USAGE: no support. In standard SQL, USAGE is for access to domains or UDTs or sequence generators or transliterations or character sets or collations. In MySQL/MariaDB, USAGE is the minimum privilege — you can log in, that’s all. So USAGE is unsupported, but unimportant.
UNDER: no relevance. This is for optional UDT features.
TRIGGER: perfect support.
EXECUTE: perfect support.
Looking at the down side, MySQL and MariaDB don’t allow for the standard GRANT OPTION. Yes, they have a GRANT OPTION privilege, but that’s not standard — what’s needed (and what’s supported by the other serious DBMSs) is an option to grant a particular privilege, not a privilege to grant any privileges.
Packaging
The objection about having hundreds of possible privileges is: it’s hard to keep track of them, or even remember what they are. This should be a solved problem: allow a package of privileges, in other words support CREATE ROLE. This time the kudos go to MariaDB which has allowed roles for over two years. But what if you have MySQL and it’s tedious to grant multiple times?
It’s still simple. You either make a script which contains a bunch of GRANT statements, or you create a stored procedure. Certainly I’d recommend a stored procedure, because it will be “inside the database”, and therefore subject to tracking. Scripts are a tad more dicey security-wise, since changing or deleting files is a process outside the DBMS’s control.
After all, doing grants via an insecure mechanism would kinda mess up the idea of using grants for extra security.
information_schema
There is a standard and reasonable way to get at metadata: you can see the information_schema table, but you won’t see rows for database objects that you don’t have access to.
MySQL and MariaDB follow this plan, but there is a major exception: InnoDB. Consider INNODB_SYS_TABLES, which has information about other tables. Of course this table should not exist at all (the sensible place is information_schema.TABLES), but the more troubling fact is that the relevant privilege is not “whether you have access to the other tables”, but — wow — the PROCESS privilege. And to top it off, in MySQL (though not MariaDB) instead of an empty table you get an error message.
Statement: select * from information_schema.innodb_sys_tables;
Response from MySQL 5.7: ERROR 1227 (42000): Access denied; you need (at least one of) the PROCESS privilege(s) for this operation
We Live In A Just World
Therefore, here is how I can crash my MySQL 5.7 server. Provided, ironically, that I do not have any privileges on any database objects. In other words, I’ve logged in as a user who has been granted the minimum:
GRANT USAGE ON *.* to ‘peter’@’localhost’;
The important prerequisites are: MySQL 5.7.9 compiled from source, a new installation, and an unprivileged user. It doesn’t seem to happen under any other circumstances. So this is not a vulnerability alert. I like to show it, though, as an illustration of the punishment that awaits violators of the precepts of privileges.
As I indicated, I’ve logged in, and the database is empty. Now I say:
SELECT A.NAME, B.NAME FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES A LEFT JOIN INFORMATION_SCHEMA.INNODB_SYS_TABLES B ON A.SPACE = B.SPACE;
On the client I see
ERROR 2013 (HY000): Lost connection to MySQL server during query
On the server I see
mysqld: /home/pgulutzan/Downloads/mysql-5.7.9/sql/sql_error.cc:444: void Diagnostics_area::set_error_status(uint, const char*, const char*): Assertion `! is_set() || m_can_overwrite_status’ failed.
18:37:12 UTC – mysqld got signal 6 ;
…
As this is a crash and something is definitely wrong, the information collection process might fail.
etc.
Those who live in glass houses
I don’t think it would be fair to end this without confessing: us too.
For example, the ocelotgui GUI client for MySQL and MariaDB can crash if I ask it not to send /* comments */ to the server, and there is a very long comment at the end of a statement after the semicolon. We are all sinners.
However, that bug, and a few minor ones, have been found during alpha tests. I’m still hopeful that we’ll go beta within a few weeks, and invite anyone to try and find an embarrassing problem before that happens. The readme and the download are on github at https://github.com/ocelot-inc/ocelotgui.
Generated columns in MariaDB and MySQL
It has been seven years since the last time I blogged about generated columns, and a lot has happened — now both MariaDB and MySQL support them. So it’s time to look again, see how well they’re doing, and compare to the SQL standard’s Optional feature T175 Generated columns.
This is not an introductory description or an explanation why you’d want to use generated columns rather than (say) triggers and views. For that, I’d recommend the relevant manuals or the blog posts by Alexander Rubin and Anders Karlsson.
The Generation Clause
Standard MariaDB 10.1 MySQL 5.7
--------- ------------ ---------
[data type] data_type data type
GENERATED ALWAYS [GENERATED ALWAYS] [GENERATED ALWAYS]
AS AS AS
(expression) (expression) (expression)
[VIRTUAL | PERSISTENT] [VIRTUAL | STORED]
[constraints] [constraints] [constraints]
[COMMENT 'string'] [COMMENT 'string']
The above side-by-side BNFs show the standard syntax and the syntax that MariaDB and MySQL actually allow at the time I’m writing this. The MariaDB manual says incorrectly that either VIRTUAL or PERSISTENT is mandatory. The MySQL manual suggests incorrectly that the clause order is fixed, and has a typo: there should be two “]]”s after “STORED”.
The first important deviation from standard SQL is that “data type” is not an optional clause in either MariaDB or MySQL. The data type can be figured out from the type of the expression, after all.
The second important deviation is that [GENERATED ALWAYS] is optional and there’s a way to say whether the column is virtual (column value is generated when it’s accessed) or persistent/stored (column value is generated when it’s set, and kept in the database). I call this a single deviation because it’s got a single backgrounder: compatibility with Microsoft SQL Server. In fact the original title of the worklog task (WL#411) was “Computed virtual columns as MS [i.e. Microsoft] SQL server has”. We changed it to “Generated columns”, but the perfume of Microsoftness lingers, and you’ll see traces in the vocabulary too. For example, MariaDB has an error message: “”HY000 A computed column cannot be based on a computed column”.
So the tip sheet is: for the sake of compatibility with the standard rather than with Microsoft, always say GENERATED ALWAYS, and call it a “generated” column not a “computed” column. It’s okay to say VIRTUAL, though, because Oracle does.
Restrictions
In standard SQL these restrictions apply:
“Every column reference contained in [the generation expression) shall reference a base column of [the same table].”
In other words, a generated column cannot be based on another generated column. MariaDB adheres to this, but MySQL, as a harmless extension, allows
CREATE TABLE t (a INT, b INT GENERATED ALWAYS AS (a), c INT GENERATED ALWAYS AS (b));
“[The generation expression] shall be deterministic.”
This is pretty reasonable, and both MariaDB and MySQL comply.
“[The generation expression] shall not contain a routine invocation whose subject routine possibly reads SQL-data.”
This is reasonable too, but MariaDB and MySQL go much further — they forbid every user-defined function, even if it’s declared that it’s deterministic and reads no SQL data.
“[The generation expression] shall not contain a query expression”.
In other words, GENERATED ALWAYS AS (SELECT …)” is a no-no. Again, reasonable, and I doubt it will occur to anyone to try.
Differences between MariaDB and MySQL
We’re actually looking at two different implementations — MariaDB’s generated columns come ultimately from a user contribution by Andrey Zhakov, while MySQL’s generated columns are younger and are more of an in-house development. (Update added later: Mr Zhakov deserves credit for the MySQL development too, see the comments.) Things worth noticing are:
* the PERSISTENT versus STORED syntax detail, mentioned earlier,
* GENERATED is a reserved word in MySQL but not in MariaDB,
* MariaDB has some restrictions about foreign keys that MySQL doesn’t have.
MySQL lacks some restrictions about foreign keys, eh? That could lead to interesting results. I tried this sequence of statements:
CREATE TABLE t1 (s1 INT PRIMARY KEY);
CREATE TABLE t2 (s1 INT,
s2 INT AS (s1) STORED,
FOREIGN KEY (s1) REFERENCES t1 (s1)
ON UPDATE CASCADE);
INSERT INTO t1 VALUES (1);
INSERT INTO t2 VALUES (1, DEFAULT);
UPDATE t1 SET s1 = 2;
SELECT * FROM t1;
SELECT * FROM t2;
And the results from the two SELECTs looked like this:
mysql> SELECT * FROM t1; +----+ | s1 | +----+ | 2 | +----+ 1 row in set (0.00 sec) mysql> SELECT * FROM t2; +------+------+ | s1 | s2 | +------+------+ | 2 | 1 | +------+------+ 1 row in set (0.00 sec)
If you’re thinking “whoa, that shouldn’t be right”, then I’m sure you’ll understand why MariaDB doesn’t allow this trick.
Metadata
In the standard there are two relevant INFORMAIION_SCHEMA columns: IS_GENERATED and GENERATION_EXPRESSION. In MySQL all we get is a value in the EXTRA column: “VIRTUAL GENERATED”. In MariaDB also we get a value in the EXTRA column: “VIRTUAL”.
I’d say that both implementations are deficient here — you can’t even see what the “(expression)” was.
Hurray For Everybody
Both MariaDB and MySQL have slight flaws in their implementations of generated columns, but my complaints here shouldn’t cause worry. Both are robust, as I found out by wasting time looking for bugs. This feature can be used.
What about us?
In my last blog post I may have been over-confident when I predicted ocelotgui (our GUI for MariaDB and MySQL) would allow multiple connections and go beta this month. We will have something that, I hope, will be far more exciting.
SQL qualified names
Bewilderedly behold this SQL statement:
SELECT * FROM a.b.c;
Nobody can know the meaning of “a.b.c” without knowing the terminology, the context, and the varying intents of various DBMS implementors.
The terminology
It’s pretty clear that a.b.c is a name, that is, a unique reference to an SQL object, which in this case is a table.
The name happens to be qualified — it has three parts separated by periods. A generalist would say that each part is a container, with the first part referring to the outermost container a, which contains b, which contains c. Analogies would be: a directory with a subdirectory and a sub-subdirectory, or an element within a struct within a struct.
That is true but incomplete. Now we fight about what kind of container each
identifier refers to, and what is the maximum number of levels.
What kind of container
The standard suggests that the levels are
[catalog.] [schema.] objectAnd here are the possible ways to do it:
1. Ignore catalog and schema, the only legal statement is “SELECT * FROM c;”, so c is a table name and there is no qualification. This is what happens in Firebird.
2. Ignore catalog, the legal statements are “SELECT * FROM b.c;” or “SELECT * FROM c;”, so b is a schema name, or the schema name is some default value (in MySQL/MariaDB this default value is specified by the USE statement, in standard SQL by the SET SCHEMA statement). In this case the schema identifier is the same as the database identifier. This is what happens in MySQL/MariaDB, and in Oracle. I am ignoring the fact that MySQL/MariaDB has a single catalog named def, since that has no practical use.
3. Ignore nothing, the legal statements are “SELECT * FROM a.b.c;” or “SELECT * FROM b.c;” or “SELECT * FROM c;”. The outermost (catalog) container is for a server. This is what happens in DB2.
4. There is a fourth level. This is what happens in SQL Server.
Naturally the variety causes trouble for JDBC or ODBC applications, which have to connect to any sort of DBMS despite the contradictory meanings. But when you’re connecting to the same DBMS every time, it can be okay.
The standard meaning of catalog
In SQL-99 Complete, Really — which is reproduced on mariadb.org — the idea of a catalog is expressed as a named container in an “SQL-environment”. Okay, but that leaves some uncertainty. We know that an SQL-environment can mean “the server and the client” or “the server as seen by the client”. And beyond that, we see the words “implementation-defined” because different vendors have different ideas.
The standard is neutral. Optional Feature F651 “Catalog name qualifiers” says simply that there can be a catalog identifier, there can be a “SET CATALOG ‘identifier’;” statement which has “no effect other than to set up default information”, there is no defined way to create a catalog (that is, there is no official analogue for CREATE SCHEMA), and the rest is up to the implementor.
The PostgreSQL idea is that the catalog is the cluster. The word “cluster” appears in database literature but it’s vague, it doesn’t have to mean “a group of servers connected to each other and known to each other which co-operate”. But that’s how PostgreSQL interprets, so “SELECT * FROM a.b.c;” implies “in cluster a, in which there is a schema b which should be uniquely defined within the cluster, there is a table c”.
The DB2 idea is that the catalog is the server, or an instance of the server. Presumably, if there’s only one server in a cluster, this would be the same as the PostgreSQL idea. So “SELECT * FROM a.b.c;” implies “in server a, in which there is a schema b, there is a table c”. This might be what C.J.Date was talking about when he wrote, in A Guide To The SQL Standard: “Or different catalogs might correspond to databases at different sites, if the SQL-environment involved some kind of distributed processing.” This also might be what the Hitachi manual is implying when it says a table can be qualified as node_name . authorization_identifier . table_name.
The Microsoft idea is pretty well the same thing, except that SQL Server considers “server” to be at the outermost (fourth) level.
Oracle, also, can specify a server in a table name; however, Oracle does it by appending rather than prefixing, for example “schema.table@database_link”.
In all cases the levels are separated by dots or at-signs, so it’s clear what the parts are. Astonishingly, there is a NoSQL DBMS that uses dot separators
but allows unquoted names to include dots(!); mercifully I’ve only seen this once.
Speaking of NoSQL, Apache Drill’s levels for a pseudo-table-name are plugin . workspace . location. That is an excellent way to specify what plugin to use, but I don’t see how it would work if there are two instances of a plugin.
Default schema name
The default schema name is typically implementation-defined when “the schema” is synonymous with “the database”. For example, MySQL and MariaDB say it’s null, but it’s common to start off by saying –database=test or “USE test”.
The default schema name can be the user name when the qualification is “table-qualifier . table-owner . table-name”. For example, if you log in as joe, then “SELECT * FROM t;” will be interpreted as “SELECT * FROM joe.t;”. This is becoming uncommon, but you’ll still see hints about it in old guides to ODBC, and in the Hitachi manual that I mentioned earlier.
The folks at Microsoft have an interesting BNF:
server . [catalog] . [schema] . table
| catalog . [schema] . table
| schema . table
| table
… which is not the same as the standard’s:
[catalog .] [schema .] table>
… See the difference? It means that one can leave catalog-name and schema-name blank if they’re default. So this is legal:
SELECT * FROM RemoteServer…t;
Alas, it’s easy to misread and think “[schema].table” is legal too. The MySQL manual is apparently alluding to that, but without trying to explain it, when it says: “The syntax .tbl_name means the table tbl_name in the default database. This syntax is accepted for ODBC compatibility because some ODBC programs prefix table names with a “.” character.”
Below the bottom level
What happens if an object has sub-objects? I don’t mean columns — it’s obvious that “SELECT x.y FROM t AS x;” assumes there’s a column y in table t — but I do mean partitions. As far as I know, nobody has partition identifiers within table names, although sometimes it’s okay to put them as hints after table names.
I also should mean sub-parts of columns, as one could find when (for example) the column is XML or JSON. But that’s a big enough subject for separate blog posts.
What is the use?
I was thinking of qualifiers when considering an enhancement to ocelotgui, our GUI client for MySQL and MariaDB. Suppose that one could have more than one DBMS connection. This isn’t possible with the regular mysql client, but we can go beyond it. So suppose we connect to two different DBMSs, or suppose we connect to the same DBMS twice. The first hurdle is that the usual parameters (–host, –port, –user, –password) are scalar, so we have to supplement them with new options, such as –connection2_host, –connection2_port, –connection2_user, –connection2_password. That’s easy, but now, if the user enters
SELECT * FROM b.c;
how do we know which connection the user wants to use, the one specified by –host or the one specified by –server2_host?
This could be done by saying “following statement is to be passed to connection X”, in a separate command or a menu choice. However, I rather like the idea of making catalog = server, so that “select * FROM b.c;” means send to the default server, “select * from server2.b.c;” means send to second server, and “USE server2.b” would change the default catalog as well as the default schema. This is easy and is all done by the client, so there’s no question it would work, the only thing to resolve is whether it’s a good idea.
Whatever happens, it will be in the next version of ocelotgui, along with a few bug fixes and other features. That next version will be 0.9, probably our first beta, in February 2016. But I do hope that people won’t wait — version 0.8 alpha is safe and good-looking and easy to download from github.
Standard SQL/JSON and MySQL 5.7 JSON
Support for storing and querying JSON within SQL is progressing for the ANSI/ISO SQL Standard, and for MySQL 5.7. I’ll look at what’s new, and do some comparisons.
The big picture
The standard document says
The SQL/JSON path language is a query language used by certain SQL operators (JSON_VALUE, JSON_QUERY, JSON_TABLE, and JSON_EXISTS, collectively known as the SQL/JSON query operators) to query JSON text.The SQL/JSON path language is not, strictly speaking, SQL, though it is embedded in these operators within SQL. Lexically and syntactically, the SQL/JSON path language adopts many features of ECMAScript, though it is neither a subset nor a superset of ECMAScript.The semantics of the SQL/JSON path language are primarily SQL semantics.
Here is a chart that shows the JSON-related data types and functions in the standard, and whether a particular DBMS has something with the same name and a similar functionality.
Standard Oracle SQL Server MySQL -------- ------ ---------- ----- Conventional data type YES YES NO JSON_VALUE function YES YES NO JSON_EXISTS function YES NO NO JSON_QUERY function YES YES NO JSON_TABLE function YES NO NO
My source re the standard is a draft copy of ISO/IEC 9075-2 SQL/Foundation. For Oracle 12c read Oracle’s whitepaper. For SQL Server 2016 read MSDN’s blog. My source re MySQL 5.7 is the MySQL manual and the latest source-code download of version 5.7.9.
Now, what is the significance of the lines in the chart?
Conventional data type
By “conventional”, I mean that in standard SQL JSON strings should be stored in one of the old familiar data types: VARCHAR, CLOB, etc. It didn’t have to be this way, and any DBMS that supports user-defined types can let users be more specific, but that’s what Oracle and Micosoft accept.
MySQL 5.7, on the other hand, has decided that JSON shall be a new data type. It’s closely related to LONGTEXT: if you say
CREATE TABLE j1 AS SELECT UPPER(CAST('{}' AS JSON));
SHOW CREATE TABLE j1;
then you get LONGTEXT. But if you use the C API to ask the data type, you get MYSQL_TYPE_JSON=245 (aside: this is not documented). And it differs because, if you try to put in non-JSON data, you get an error message.
At least, that’s the theory. It didn’t take me long to find a way to put non-JSON data in:
CREATE TABLE j2a (s1 INT, s2 JSON);
INSERT INTO j2a VALUES (1,'{"a": "VALID STUFF"}');
CREATE TABLE j2b AS SELECT s1, UPPER(s2) AS s2 FROM j2a;
INSERT INTO j2b VALUES (NULL, 'INVALID STUFF');
ALTER TABLE j2b MODIFY COLUMN s2 JSON;
… That unfortunately works, and now if I say “SELECT * FROM j2b;” I get an error message “The JSON binary value contains invalid data”. Probably bugs like this will disappear soon, though.
By making a new data type, MySQL has thrown away some of the advantages that come with VARCHAR or TEXT. One cannot specify a maximum size — everything is like LONGTEXT. One cannot specify a preferred character set and collation — everything is utf8mb4 and utf8mb4_bin. One cannot take advantage of all the string functions — BIN() gives meaningless results, for example. And the advantage of automatic validity checking could have been delivered with efficient constraints or triggers instead. So why have a new data type?
Well, PostgreSQL has a JSON data type. As I’ve noticed before, PostgreSQL can be a poor model if one wants to follow the standard. And it will not surprise me if the MariaDB folks also decide to make a JSON data type, because I know that they are following similar logic for an “IP address” data type.
By the way, the validity checking is fairly strict. For example, ‘{x:3}’ is considered invalid because quote marks are missing, and ‘{“x”:.2} is considered invalid because the value has no leading digit.
JSON_VALUE function
For an illustration and example it’s enough to describe the standard’s JSON_VALUE and MySQL’s JSON_EXTRACT.
The standard idea is: pass a JSON string and a JavaScript-like expression, get back an SQL value, which will generally be a scalar value. For example,
SELECT JSON_VALUE(@json, @path_string) FROM t; SELECT JSON_VALUE(json_column_name, 'lax $.c') AS c FROM t;
There are optional clauses for deciding what to do if the JSON string is invalid, or contains missing and null components. Again, the standard’s JSON_VALUE is what Oracle and Microsoft accept. There’s some similarity to what has gone before with SQL/XML.
MySQL, on the other hand, accomplishes some similar things with JSON_EXTRACT. For example,
SELECT JSON_EXTRACT(@json, @path_string); SELECT JSON_VALUE(json_column_name, '$.c') AS c FROM t;
And the result is not an ordinary MySQL scalar, it has type = JSON. In the words of physicist I.I.Rabi when confronted with a new particle, “Who ordered that?”
Well, JSON_EXTRACT and some of the other MySQL functions have fairly close analogues, in both name and functionality, with Google’s BigQuery and with SQLite. In other words, instead of the SQL standard, MySQL has ended up with something like the NoSQL No-standard.
I should stress here that MySQL is not “violating” the SQL standard with JSON_EXTRACT. It is always okay to use non-standard syntax. What’s not okay is to use standard syntax for a non-standard purpose. And here’s where I bring in the slightly dubious case of the “->” operator. In standard SQL “->”, which is called the “right arrow” operator, has only one purpose: dereferencing. In MySQL “->” has a different purpose: a shorthand for JSON_EXTRACT. Since MySQL will never support dereferencing, there will never be a conflict in practice. Nevertheless, technically, it’s a violation.
Observed Behaviour
When I tried out the JSON data type with MySQL 5.7.9, I ran into no exciting bugs, but a few features.
Consistency doesn’t apply for INSERT IGNORE and UPDATE IGNORE. For example:
CREATE TABLE t1 (date DATE, json JSON);
INSERT IGNORE INTO t1 (date) VALUES ('invalid date');
INSERT IGNORE INTO t1 (json) VALUES ('{invalid json}');
The INSERT IGNORE into the date column inserts null with a warning, the INSERT IGNORE into the json column returns an error.
Some error messages might still need adjustment. For example:
CREATE TABLE ti (id INT, json JSON) PARTITION BY HASH(json);
Result: an error message = “A BLOB field is not allowed in partition function”.
Comparisons of JSON_EXTRACT results don’t work. For example:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
JSON_EXTRACT(@json,'$.a'),
JSON_EXTRACT(@json,'$.b'));
The result is a warning “This version of MySQL doesn’t yet support ‘comparison of JSON in the LEAST and GREATEST operators'”, which is a symptom of the true problem, that JSON_EXTRACT returns a JSON value instead of a string value. The workaround is:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
CAST(JSON_EXTRACT(@json,'$.a') AS CHAR),
CAST(JSON_EXTRACT(@json,'$.b') AS CHAR));
… which returns “B” — a three-character string, including the quote marks.
Not The End
The standard might change, and MySQL certainly will change anything that’s deemed wrong. Speaking of wrong, I might have erred too. And I certainly didn’t give justice to all the other details of MySQL 5.7 JSON.
Meanwhile
The Ocelot GUI client for MySQL and MariaDB is still version 0.8 alpha, but since the last report there have been bug fixes and improvements to the Help option. Have a look at the new manual by going to https://github.com/ocelot-inc/ocelotgui and scrolling down till you see the screenshots and the words “User Manual”.
Send messages between sessions on MySQL or MariaDB
Suppose you want to send a message from one SQL session to one or more other sessions, like “Hey, session#13, here is the latest figure for your calculation, please acknowledge”. I’ll say what Oracle and EnterpriseDB and DB2 do, then rate the various ways to implement something similar in MySQL and MariaDB, and finish with a demo of the procedure that we use, which is available as part of an open-source package.
The syntax was established by Oracle, with EnterpriseDB and IBM following suit. The details are in the Oracle 12c manual and the DB2 9.7 manual. The oversimplification is this:
DBMS_PIPE.PACK_MESSAGE('message');
SET status = DBMS_PIPE.SEND_MESSAGE('channel#1');
SET status = DBMS_PIPE.RECEIVE_MESSAGE('channel#1');
DBMS_PIPE.UNPACK_MESSAGE(target_variable);
The idea is that PACK_MESSAGE prepares the message, SEND_MESSAGE ships the message on a channel, RECEIVE_MESSAGE receives something on a channel, and UNPACK_MESSAGE puts a received message in a variable. The whole package is called DBMS_PIPE because “pipe” is a common word when the topic is Inter-process communication.
MySQL and MariaDB don’t have DBMS_PIPE, but it’s possible to write it as an SQL stored procedure. I did, while working for Hewlett-Packard. Before saying “here it is”, I want to share the agony that we endured when deciding what, at the lowest level, would be the best mechanism.
The criteria are:
size -- how many bits can a message contain? isolation -- how many conversations can take place simultaneously? privilege -- how specific is the authorization, if any? is eavesdropping easy? danger -- what are the chances of fouling up some other process? reliability -- can messages be delayed or destroyed? utility -- can it be used at any time regardless of what's gone before?
There is no “overhead” criterion because messaging should be rare.
These are the 5 candidate mechanisms.
1. Tables.
Session#1 INSERTs to a table, Session#2 SELECTs from the table.
Rating: size=good, isolation=good, privilege=good, danger=low, reliability=good.
But utility=terrible. First: with some storage engines you have to COMMIT in order to send and this might not be a time that you want to COMMIT. Second and more important: there’s a bit of fine print in the MySQL Reference Manual:
A stored function acquires table locks before executing, to avoid inconsistency in the binary log due to mismatch of the order in which statements execute and when they appear in the log.
Think about it. It means that you can’t read a message that’s sent by a function while the function is running. And you can’t work around that by writing the messaging code in a stored procedure — there’s no guarantee that the stored procedure won’t be called from a function.
2. Files.
Session#1 uses SELECT … INTO OUTFILE. Session#2 says LOAD_FILE.
(We don’t consider LOAD DATA because it won’t work in stored procedures.)
Rating: size=good, isolation=good, privilege=good, utility=good.
But danger=high, reliability=bad. The problem is that you can’t overwrite a file, so the messages would pile up indefinitely.
3. information_schema.processlist.
Session#1 says SELECT SLEEP(0.5),’message’. Session#2 says SELECT from information_schema.processlist.
Rating: size=bad, isolation=bad, privilege=good, danger=low, utility=bad.
This is okay for short messages if you’re not worried about eavesdropping. But notice that the message can only be a literal, like ‘message’. It cannot always be a variable, because then it’s dynamic SQL, and dynamic SQL is illegal in functions, and now you’ve got the same problem as with mechanism number 1.
4. GET_LOCK.
Session#1 says GET_LOCK(). Session#2 says IS_USED_LOCK().
Rating: size=bad, isolation=good, privilege=good, danger=low, utility=good.
Technically reliability=low because the message disappears when the server goes down, but in many situations that would actually be a good thing. The rating “size=bad” is easy to understand: effectively there’s only one bit of information (yes/no) that Session#2 is getting by checking IS_USED_LOCK(). However, one-bit signals are great for lots of applications so this would still fit in a toolkit if it weren’t for The Great GET_LOCK Showstopper. Namely, you can only have one GET_LOCK at a time.
Now for the good news. Multiple GET_LOCK invocations are on their way. The person to thank (and I say “thank” because this was a contribution done to the whole community) is Konstantin Osipov, who wrote a patch and a blog post — “MySQL: multiple user level locks per connection”. As I understand matters, this was a basis for the code that is coming in a future MySQL version and is now in the MySQL 5.7.5 manual. Konstantin Osipov, by the way, nowadays writes for the Tarantool NoSQL DBMS and Lua application server, to which I am pleased to contribute in small ways.
5. System variables.
Session#1 says SET @@variable_name = ‘message’. Session#2 says target = @@variable_name.
Rating: size=bad, isolation=good, privilege=good, danger=high, utility=good.
The system variable must be a string, must be dynamically writable, and must not change the server’s behaviour if you write a bad value. Only one item does all that: @@init_connect. It’s actually easy to ensure that changes to @@init_connect won’t affect its official purpose — just put the message /* inside a comment */. However, I still rate it as danger=high because anybody could overwrite the message inadvertently.
And the winner, as far as we’re concerned, is … #5 System variables. Remember, Ocelot is supplying a debugger for MySQL/MariaDB routines. It would be a pretty poor debugger that used a message mechanism that wouldn’t work with functions, so mechanism#1 and mechanism#3 are out. The GET_LOCK of mechanism#4 is in fact used by a different debugger, but in my opinion that means it’s hard to have two debugger sessions on the same server, or to run without pausing after every statement. So our implementation involves setting @@init_connect.
If you want to see our implementation, here is how (on Linux).
Download, install, and start ocelotgui. The instructions are in the
README.md file at https://github.com/ocelot-inc/ocelotgui (just scroll past the list of files). Connect to a MySQL/MariaDB server as a user with privileges to create databases and tables, and execute routines. Then type in, on the statement widget
$INSTALL
After this, you actually won’t need ocelotgui any more. So, although I think the real “demo” would be to use the debugger now that you’ve installed it, I’ll show how to use pipes with the mysql client instead.
Start a shell. Start mysql. You need the SUPER privilege, and the EXECUTE privilege for routines in the xxxmdbug database. Send a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_send('channel#1','message');
Query OK, 0 rows affected (0.00 sec)
Start a second shell. Receive a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_receive
-> ('channel#1',1,@message_part_1,@message_part_2);
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> select @message_part_1;
+-----------------+
| @message_part_1 |
+-----------------+
| message |
+-----------------+
1 row in set (0.00 sec)
You can see how it’s implemented by saying
SELECT * FROM information_schema.routines WHERE routine_schema = 'xxxmdbug' AND routine_name like 'dbms_pipe_%';
The dbms_pipe_send and dbms_pipe_receive routines are GPL and copyrighted by Hewlett-Packard.
I might not moderate comments on this blog while on vacation. Tomorrow I leave for Reykjavik, Amsterdam and London.
MariaDB 10.1 Release Candidate
I installed the MariaDB 10.1 Release Candidate. Nothing interesting happened, which from MariaDB’s point of view is good. But here’s how I tried to make it interesting. Some of this applies to late releases of MariaDB 10.0 as well.
Loop with MAKE INSTALL
My habit is to download the source to directory X and then say “cmake -DCMAKE_INSTALL_PREFIX=/X” (the same directory), then “make”, then “make install”. That doesn’t work any more. Now I can’t install in the same directory that I downloaded in. Not a big deal; perhaps I’m the only person who had this habit.
Crash with ALTER
In an earlier blog post General Purpose Storage Engines in MariaDB I mentioned a crash, which I’m happy to say is fixed now. Here’s another way to crash, once again involving different storage engines.
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 2 Server version: 10.1.8-MariaDB Source distribution Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> INSTALL SONAME 'ha_tokudb'; Query OK, 0 rows affected (0.57 sec) MariaDB [(none)]> USE test Database changed MariaDB [test]> CREATE TABLE t (id INT UNIQUE, s2 VARCHAR(10)) ENGINE=tokudb; Query OK, 0 rows affected (0.56 sec) MariaDB [test]> INSERT INTO t VALUES (1,'ABCDEFGHIJ'); Query OK, 1 row affected (0.04 sec) MariaDB [test]> INSERT INTO t VALUES (2,'1234567890'); Query OK, 1 row affected (0.05 sec) MariaDB [test]> CREATE INDEX i ON t (s2); Query OK, 0 rows affected (0.64 sec) Records: 0 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=innodb; Query OK, 2 rows affected (0.53 sec) Records: 2 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=tokudb; ERROR 2013 (HY000): Lost connection to MySQL server during query
… Do not do this on a production system, as it will disable all your databases.
[ UPDATE 2015-09-29: This is apparently due to a problem with jemalloc which should only happen if one builds from source on Ubuntu 12.04. MariaDB was aware and had supplied extra information in its Knowledge Base, which I missed. Thanks to Elena Stepanova. ]
PREPARE within PREPARE
No doubt everyone encounters this situation at least once:
MariaDB [test]> prepare stmt1 from 'prepare stmt2 from @x'; ERROR 1295 (HY000): This command is not supported in the prepared statement protocol yet
… and then everyone else gets on with their lives, because preparing a prepare statement isn’t top-of-agenda. Not me. So I welcome the fact that I can now say:
MariaDB [test]> prepare stmt1 from 'begin not atomic prepare stmt2 from @x; end'; Query OK, 0 rows affected (0.00 sec) Statement prepared
So now if I execute stmt1, stmt2 is prepared. This is part of the “compound statement” feature.
Evade the MAX QUERIES PER HOUR limit
Suppose some administrator has said
GRANT ALL ON customer.* TO 'peter'@'localhost' WITH MAX_QUERIES_PER_HOUR 20;
Well, now, thanks again to the “compound statement” feature, I can evade that and do 1000 queries. Here’s the test I used:
SET @a = 0; DELIMITER // WHILE @a < 1000 DO INSERT INTO t VALUES (@a); SET @a = @a + 1; END WHILE;// DELIMITER ;
No error. So with a little advance planning, I could put 1000 different statements in a user variable, pick off one at a time from within the loop, and execute. One way of looking at this is: the WHILE ... END WHILE is a single statement. Another way to look at this is: new features introduce new hassles for administrators. Such, however, is progress. I clapped for the compound-statement feature in an earlier blog post and ended with: "But MariaDB 10.1.1 is an early alpha, and nothing is guaranteed in an alpha, so it's too early to say that MariaDB is ahead in this respect." I'm glad to say that statement is obsolete now, because this is MariaDB 10.1.8, not early alpha but release candidate.
The true meaning of the OR REPLACE clause
MariaDB has decided to try to be consistent with CREATE and DROP statements, because frankly nobody could ever remember: which CREATE statements allow CREATE IF NOT EXISTS, which CREATE statements allow CREATE OR REPLACE, which DROP statements allow DROP IF EXISTS? I wrote a handy chart in MySQL Worklog#3129 Consistent Clauses in CREATE and DROP. Now it's obsolete. The MariaDB version of the chart will have a boring bunch of "yes"es in every row.
But OR REPLACE behaviour is just a tad un-Oracle-ish. The Oracle 12c manual's description is "Specify OR REPLACE to re-create the [object] if it already exists. You can use this clause to change the definition of an existing [object] without dropping, re-creating, and regranting object privileges previously granted on it." That's not what MariaDB is doing. MariaDB drops the object and then creates it again, in effect. You can see that because you need to have DROP privilege on the object in order to say CREATE OR REPLACE.
And here's where it gets a tad un-MySQL-ish too. If you say "CREATE OR REPLACE x ...,", causing the dropping of an existing x, and then say SHOW STATUS LIKE 'Com%', you'll see that the Com_drop_* counter is zero. That is: according to the privilege requirements, x is being dropped. But according to the SHOW statement, x is not being dropped. Decent folk wouldn't use SHOW anyway, so this won't matter.
An effect on us
One of the little features of ocelotgui (the Ocelot GUI application for MySQL and MariaDB) is that one can avoid using DELIMITER when typing in a statement. The program counts the number of BEGINs (or WHILEs or LOOPs etc.) and matches them against the number of ENDs, so it doesn't prematurely ship off a statement to the server until the user presses Enter after the final END. However, this feature is currently working only for compound statements within CREATE statements. Now that compound statements are stand-alone, this needs adjusting.
Now that I've mentioned ocelotgui again, I'll add that if you go to the https://github.com/ocelot-inc/ocelotgui download page and scroll past the install instructions, you'll find more pictures, and a URL of the debugger reference, for version 0.7 alpha.