About pgulutzan
View all posts by pgulutzan
SQL qualified names
Bewilderedly behold this SQL statement:
SELECT * FROM a.b.c;
Nobody can know the meaning of “a.b.c” without knowing the terminology, the context, and the varying intents of various DBMS implementors.
The terminology
It’s pretty clear that a.b.c is a name, that is, a unique reference to an SQL object, which in this case is a table.
The name happens to be qualified — it has three parts separated by periods. A generalist would say that each part is a container, with the first part referring to the outermost container a, which contains b, which contains c. Analogies would be: a directory with a subdirectory and a sub-subdirectory, or an element within a struct within a struct.
That is true but incomplete. Now we fight about what kind of container each
identifier refers to, and what is the maximum number of levels.
What kind of container
The standard suggests that the levels are
[catalog.] [schema.] objectAnd here are the possible ways to do it:
1. Ignore catalog and schema, the only legal statement is “SELECT * FROM c;”, so c is a table name and there is no qualification. This is what happens in Firebird.
2. Ignore catalog, the legal statements are “SELECT * FROM b.c;” or “SELECT * FROM c;”, so b is a schema name, or the schema name is some default value (in MySQL/MariaDB this default value is specified by the USE statement, in standard SQL by the SET SCHEMA statement). In this case the schema identifier is the same as the database identifier. This is what happens in MySQL/MariaDB, and in Oracle. I am ignoring the fact that MySQL/MariaDB has a single catalog named def, since that has no practical use.
3. Ignore nothing, the legal statements are “SELECT * FROM a.b.c;” or “SELECT * FROM b.c;” or “SELECT * FROM c;”. The outermost (catalog) container is for a server. This is what happens in DB2.
4. There is a fourth level. This is what happens in SQL Server.
Naturally the variety causes trouble for JDBC or ODBC applications, which have to connect to any sort of DBMS despite the contradictory meanings. But when you’re connecting to the same DBMS every time, it can be okay.
The standard meaning of catalog
In SQL-99 Complete, Really — which is reproduced on mariadb.org — the idea of a catalog is expressed as a named container in an “SQL-environment”. Okay, but that leaves some uncertainty. We know that an SQL-environment can mean “the server and the client” or “the server as seen by the client”. And beyond that, we see the words “implementation-defined” because different vendors have different ideas.
The standard is neutral. Optional Feature F651 “Catalog name qualifiers” says simply that there can be a catalog identifier, there can be a “SET CATALOG ‘identifier’;” statement which has “no effect other than to set up default information”, there is no defined way to create a catalog (that is, there is no official analogue for CREATE SCHEMA), and the rest is up to the implementor.
The PostgreSQL idea is that the catalog is the cluster. The word “cluster” appears in database literature but it’s vague, it doesn’t have to mean “a group of servers connected to each other and known to each other which co-operate”. But that’s how PostgreSQL interprets, so “SELECT * FROM a.b.c;” implies “in cluster a, in which there is a schema b which should be uniquely defined within the cluster, there is a table c”.
The DB2 idea is that the catalog is the server, or an instance of the server. Presumably, if there’s only one server in a cluster, this would be the same as the PostgreSQL idea. So “SELECT * FROM a.b.c;” implies “in server a, in which there is a schema b, there is a table c”. This might be what C.J.Date was talking about when he wrote, in A Guide To The SQL Standard: “Or different catalogs might correspond to databases at different sites, if the SQL-environment involved some kind of distributed processing.” This also might be what the Hitachi manual is implying when it says a table can be qualified as node_name . authorization_identifier . table_name.
The Microsoft idea is pretty well the same thing, except that SQL Server considers “server” to be at the outermost (fourth) level.
Oracle, also, can specify a server in a table name; however, Oracle does it by appending rather than prefixing, for example “schema.table@database_link”.
In all cases the levels are separated by dots or at-signs, so it’s clear what the parts are. Astonishingly, there is a NoSQL DBMS that uses dot separators
but allows unquoted names to include dots(!); mercifully I’ve only seen this once.
Speaking of NoSQL, Apache Drill’s levels for a pseudo-table-name are plugin . workspace . location. That is an excellent way to specify what plugin to use, but I don’t see how it would work if there are two instances of a plugin.
Default schema name
The default schema name is typically implementation-defined when “the schema” is synonymous with “the database”. For example, MySQL and MariaDB say it’s null, but it’s common to start off by saying –database=test or “USE test”.
The default schema name can be the user name when the qualification is “table-qualifier . table-owner . table-name”. For example, if you log in as joe, then “SELECT * FROM t;” will be interpreted as “SELECT * FROM joe.t;”. This is becoming uncommon, but you’ll still see hints about it in old guides to ODBC, and in the Hitachi manual that I mentioned earlier.
The folks at Microsoft have an interesting BNF:
server . [catalog] . [schema] . table
| catalog . [schema] . table
| schema . table
| table
… which is not the same as the standard’s:
[catalog .] [schema .] table>
… See the difference? It means that one can leave catalog-name and schema-name blank if they’re default. So this is legal:
SELECT * FROM RemoteServer…t;
Alas, it’s easy to misread and think “[schema].table” is legal too. The MySQL manual is apparently alluding to that, but without trying to explain it, when it says: “The syntax .tbl_name means the table tbl_name in the default database. This syntax is accepted for ODBC compatibility because some ODBC programs prefix table names with a “.” character.”
Below the bottom level
What happens if an object has sub-objects? I don’t mean columns — it’s obvious that “SELECT x.y FROM t AS x;” assumes there’s a column y in table t — but I do mean partitions. As far as I know, nobody has partition identifiers within table names, although sometimes it’s okay to put them as hints after table names.
I also should mean sub-parts of columns, as one could find when (for example) the column is XML or JSON. But that’s a big enough subject for separate blog posts.
What is the use?
I was thinking of qualifiers when considering an enhancement to ocelotgui, our GUI client for MySQL and MariaDB. Suppose that one could have more than one DBMS connection. This isn’t possible with the regular mysql client, but we can go beyond it. So suppose we connect to two different DBMSs, or suppose we connect to the same DBMS twice. The first hurdle is that the usual parameters (–host, –port, –user, –password) are scalar, so we have to supplement them with new options, such as –connection2_host, –connection2_port, –connection2_user, –connection2_password. That’s easy, but now, if the user enters
SELECT * FROM b.c;
how do we know which connection the user wants to use, the one specified by –host or the one specified by –server2_host?
This could be done by saying “following statement is to be passed to connection X”, in a separate command or a menu choice. However, I rather like the idea of making catalog = server, so that “select * FROM b.c;” means send to the default server, “select * from server2.b.c;” means send to second server, and “USE server2.b” would change the default catalog as well as the default schema. This is easy and is all done by the client, so there’s no question it would work, the only thing to resolve is whether it’s a good idea.
Whatever happens, it will be in the next version of ocelotgui, along with a few bug fixes and other features. That next version will be 0.9, probably our first beta, in February 2016. But I do hope that people won’t wait — version 0.8 alpha is safe and good-looking and easy to download from github.
Standard SQL/JSON and MySQL 5.7 JSON
Support for storing and querying JSON within SQL is progressing for the ANSI/ISO SQL Standard, and for MySQL 5.7. I’ll look at what’s new, and do some comparisons.
The big picture
The standard document says
The SQL/JSON path language is a query language used by certain SQL operators (JSON_VALUE, JSON_QUERY, JSON_TABLE, and JSON_EXISTS, collectively known as the SQL/JSON query operators) to query JSON text.The SQL/JSON path language is not, strictly speaking, SQL, though it is embedded in these operators within SQL. Lexically and syntactically, the SQL/JSON path language adopts many features of ECMAScript, though it is neither a subset nor a superset of ECMAScript.The semantics of the SQL/JSON path language are primarily SQL semantics.
Here is a chart that shows the JSON-related data types and functions in the standard, and whether a particular DBMS has something with the same name and a similar functionality.
Standard Oracle SQL Server MySQL -------- ------ ---------- ----- Conventional data type YES YES NO JSON_VALUE function YES YES NO JSON_EXISTS function YES NO NO JSON_QUERY function YES YES NO JSON_TABLE function YES NO NO
My source re the standard is a draft copy of ISO/IEC 9075-2 SQL/Foundation. For Oracle 12c read Oracle’s whitepaper. For SQL Server 2016 read MSDN’s blog. My source re MySQL 5.7 is the MySQL manual and the latest source-code download of version 5.7.9.
Now, what is the significance of the lines in the chart?
Conventional data type
By “conventional”, I mean that in standard SQL JSON strings should be stored in one of the old familiar data types: VARCHAR, CLOB, etc. It didn’t have to be this way, and any DBMS that supports user-defined types can let users be more specific, but that’s what Oracle and Micosoft accept.
MySQL 5.7, on the other hand, has decided that JSON shall be a new data type. It’s closely related to LONGTEXT: if you say
CREATE TABLE j1 AS SELECT UPPER(CAST('{}' AS JSON));
SHOW CREATE TABLE j1;
then you get LONGTEXT. But if you use the C API to ask the data type, you get MYSQL_TYPE_JSON=245 (aside: this is not documented). And it differs because, if you try to put in non-JSON data, you get an error message.
At least, that’s the theory. It didn’t take me long to find a way to put non-JSON data in:
CREATE TABLE j2a (s1 INT, s2 JSON);
INSERT INTO j2a VALUES (1,'{"a": "VALID STUFF"}');
CREATE TABLE j2b AS SELECT s1, UPPER(s2) AS s2 FROM j2a;
INSERT INTO j2b VALUES (NULL, 'INVALID STUFF');
ALTER TABLE j2b MODIFY COLUMN s2 JSON;
… That unfortunately works, and now if I say “SELECT * FROM j2b;” I get an error message “The JSON binary value contains invalid data”. Probably bugs like this will disappear soon, though.
By making a new data type, MySQL has thrown away some of the advantages that come with VARCHAR or TEXT. One cannot specify a maximum size — everything is like LONGTEXT. One cannot specify a preferred character set and collation — everything is utf8mb4 and utf8mb4_bin. One cannot take advantage of all the string functions — BIN() gives meaningless results, for example. And the advantage of automatic validity checking could have been delivered with efficient constraints or triggers instead. So why have a new data type?
Well, PostgreSQL has a JSON data type. As I’ve noticed before, PostgreSQL can be a poor model if one wants to follow the standard. And it will not surprise me if the MariaDB folks also decide to make a JSON data type, because I know that they are following similar logic for an “IP address” data type.
By the way, the validity checking is fairly strict. For example, ‘{x:3}’ is considered invalid because quote marks are missing, and ‘{“x”:.2} is considered invalid because the value has no leading digit.
JSON_VALUE function
For an illustration and example it’s enough to describe the standard’s JSON_VALUE and MySQL’s JSON_EXTRACT.
The standard idea is: pass a JSON string and a JavaScript-like expression, get back an SQL value, which will generally be a scalar value. For example,
SELECT JSON_VALUE(@json, @path_string) FROM t; SELECT JSON_VALUE(json_column_name, 'lax $.c') AS c FROM t;
There are optional clauses for deciding what to do if the JSON string is invalid, or contains missing and null components. Again, the standard’s JSON_VALUE is what Oracle and Microsoft accept. There’s some similarity to what has gone before with SQL/XML.
MySQL, on the other hand, accomplishes some similar things with JSON_EXTRACT. For example,
SELECT JSON_EXTRACT(@json, @path_string); SELECT JSON_VALUE(json_column_name, '$.c') AS c FROM t;
And the result is not an ordinary MySQL scalar, it has type = JSON. In the words of physicist I.I.Rabi when confronted with a new particle, “Who ordered that?”
Well, JSON_EXTRACT and some of the other MySQL functions have fairly close analogues, in both name and functionality, with Google’s BigQuery and with SQLite. In other words, instead of the SQL standard, MySQL has ended up with something like the NoSQL No-standard.
I should stress here that MySQL is not “violating” the SQL standard with JSON_EXTRACT. It is always okay to use non-standard syntax. What’s not okay is to use standard syntax for a non-standard purpose. And here’s where I bring in the slightly dubious case of the “->” operator. In standard SQL “->”, which is called the “right arrow” operator, has only one purpose: dereferencing. In MySQL “->” has a different purpose: a shorthand for JSON_EXTRACT. Since MySQL will never support dereferencing, there will never be a conflict in practice. Nevertheless, technically, it’s a violation.
Observed Behaviour
When I tried out the JSON data type with MySQL 5.7.9, I ran into no exciting bugs, but a few features.
Consistency doesn’t apply for INSERT IGNORE and UPDATE IGNORE. For example:
CREATE TABLE t1 (date DATE, json JSON);
INSERT IGNORE INTO t1 (date) VALUES ('invalid date');
INSERT IGNORE INTO t1 (json) VALUES ('{invalid json}');
The INSERT IGNORE into the date column inserts null with a warning, the INSERT IGNORE into the json column returns an error.
Some error messages might still need adjustment. For example:
CREATE TABLE ti (id INT, json JSON) PARTITION BY HASH(json);
Result: an error message = “A BLOB field is not allowed in partition function”.
Comparisons of JSON_EXTRACT results don’t work. For example:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
JSON_EXTRACT(@json,'$.a'),
JSON_EXTRACT(@json,'$.b'));
The result is a warning “This version of MySQL doesn’t yet support ‘comparison of JSON in the LEAST and GREATEST operators'”, which is a symptom of the true problem, that JSON_EXTRACT returns a JSON value instead of a string value. The workaround is:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
CAST(JSON_EXTRACT(@json,'$.a') AS CHAR),
CAST(JSON_EXTRACT(@json,'$.b') AS CHAR));
… which returns “B” — a three-character string, including the quote marks.
Not The End
The standard might change, and MySQL certainly will change anything that’s deemed wrong. Speaking of wrong, I might have erred too. And I certainly didn’t give justice to all the other details of MySQL 5.7 JSON.
Meanwhile
The Ocelot GUI client for MySQL and MariaDB is still version 0.8 alpha, but since the last report there have been bug fixes and improvements to the Help option. Have a look at the new manual by going to https://github.com/ocelot-inc/ocelotgui and scrolling down till you see the screenshots and the words “User Manual”.
Send messages between sessions on MySQL or MariaDB
Suppose you want to send a message from one SQL session to one or more other sessions, like “Hey, session#13, here is the latest figure for your calculation, please acknowledge”. I’ll say what Oracle and EnterpriseDB and DB2 do, then rate the various ways to implement something similar in MySQL and MariaDB, and finish with a demo of the procedure that we use, which is available as part of an open-source package.
The syntax was established by Oracle, with EnterpriseDB and IBM following suit. The details are in the Oracle 12c manual and the DB2 9.7 manual. The oversimplification is this:
DBMS_PIPE.PACK_MESSAGE('message');
SET status = DBMS_PIPE.SEND_MESSAGE('channel#1');
SET status = DBMS_PIPE.RECEIVE_MESSAGE('channel#1');
DBMS_PIPE.UNPACK_MESSAGE(target_variable);
The idea is that PACK_MESSAGE prepares the message, SEND_MESSAGE ships the message on a channel, RECEIVE_MESSAGE receives something on a channel, and UNPACK_MESSAGE puts a received message in a variable. The whole package is called DBMS_PIPE because “pipe” is a common word when the topic is Inter-process communication.
MySQL and MariaDB don’t have DBMS_PIPE, but it’s possible to write it as an SQL stored procedure. I did, while working for Hewlett-Packard. Before saying “here it is”, I want to share the agony that we endured when deciding what, at the lowest level, would be the best mechanism.
The criteria are:
size -- how many bits can a message contain? isolation -- how many conversations can take place simultaneously? privilege -- how specific is the authorization, if any? is eavesdropping easy? danger -- what are the chances of fouling up some other process? reliability -- can messages be delayed or destroyed? utility -- can it be used at any time regardless of what's gone before?
There is no “overhead” criterion because messaging should be rare.
These are the 5 candidate mechanisms.
1. Tables.
Session#1 INSERTs to a table, Session#2 SELECTs from the table.
Rating: size=good, isolation=good, privilege=good, danger=low, reliability=good.
But utility=terrible. First: with some storage engines you have to COMMIT in order to send and this might not be a time that you want to COMMIT. Second and more important: there’s a bit of fine print in the MySQL Reference Manual:
A stored function acquires table locks before executing, to avoid inconsistency in the binary log due to mismatch of the order in which statements execute and when they appear in the log.
Think about it. It means that you can’t read a message that’s sent by a function while the function is running. And you can’t work around that by writing the messaging code in a stored procedure — there’s no guarantee that the stored procedure won’t be called from a function.
2. Files.
Session#1 uses SELECT … INTO OUTFILE. Session#2 says LOAD_FILE.
(We don’t consider LOAD DATA because it won’t work in stored procedures.)
Rating: size=good, isolation=good, privilege=good, utility=good.
But danger=high, reliability=bad. The problem is that you can’t overwrite a file, so the messages would pile up indefinitely.
3. information_schema.processlist.
Session#1 says SELECT SLEEP(0.5),’message’. Session#2 says SELECT from information_schema.processlist.
Rating: size=bad, isolation=bad, privilege=good, danger=low, utility=bad.
This is okay for short messages if you’re not worried about eavesdropping. But notice that the message can only be a literal, like ‘message’. It cannot always be a variable, because then it’s dynamic SQL, and dynamic SQL is illegal in functions, and now you’ve got the same problem as with mechanism number 1.
4. GET_LOCK.
Session#1 says GET_LOCK(). Session#2 says IS_USED_LOCK().
Rating: size=bad, isolation=good, privilege=good, danger=low, utility=good.
Technically reliability=low because the message disappears when the server goes down, but in many situations that would actually be a good thing. The rating “size=bad” is easy to understand: effectively there’s only one bit of information (yes/no) that Session#2 is getting by checking IS_USED_LOCK(). However, one-bit signals are great for lots of applications so this would still fit in a toolkit if it weren’t for The Great GET_LOCK Showstopper. Namely, you can only have one GET_LOCK at a time.
Now for the good news. Multiple GET_LOCK invocations are on their way. The person to thank (and I say “thank” because this was a contribution done to the whole community) is Konstantin Osipov, who wrote a patch and a blog post — “MySQL: multiple user level locks per connection”. As I understand matters, this was a basis for the code that is coming in a future MySQL version and is now in the MySQL 5.7.5 manual. Konstantin Osipov, by the way, nowadays writes for the Tarantool NoSQL DBMS and Lua application server, to which I am pleased to contribute in small ways.
5. System variables.
Session#1 says SET @@variable_name = ‘message’. Session#2 says target = @@variable_name.
Rating: size=bad, isolation=good, privilege=good, danger=high, utility=good.
The system variable must be a string, must be dynamically writable, and must not change the server’s behaviour if you write a bad value. Only one item does all that: @@init_connect. It’s actually easy to ensure that changes to @@init_connect won’t affect its official purpose — just put the message /* inside a comment */. However, I still rate it as danger=high because anybody could overwrite the message inadvertently.
And the winner, as far as we’re concerned, is … #5 System variables. Remember, Ocelot is supplying a debugger for MySQL/MariaDB routines. It would be a pretty poor debugger that used a message mechanism that wouldn’t work with functions, so mechanism#1 and mechanism#3 are out. The GET_LOCK of mechanism#4 is in fact used by a different debugger, but in my opinion that means it’s hard to have two debugger sessions on the same server, or to run without pausing after every statement. So our implementation involves setting @@init_connect.
If you want to see our implementation, here is how (on Linux).
Download, install, and start ocelotgui. The instructions are in the
README.md file at https://github.com/ocelot-inc/ocelotgui (just scroll past the list of files). Connect to a MySQL/MariaDB server as a user with privileges to create databases and tables, and execute routines. Then type in, on the statement widget
$INSTALL
After this, you actually won’t need ocelotgui any more. So, although I think the real “demo” would be to use the debugger now that you’ve installed it, I’ll show how to use pipes with the mysql client instead.
Start a shell. Start mysql. You need the SUPER privilege, and the EXECUTE privilege for routines in the xxxmdbug database. Send a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_send('channel#1','message');
Query OK, 0 rows affected (0.00 sec)
Start a second shell. Receive a message.
MariaDB [(none)]> call xxxmdbug.dbms_pipe_receive
-> ('channel#1',1,@message_part_1,@message_part_2);
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> select @message_part_1;
+-----------------+
| @message_part_1 |
+-----------------+
| message |
+-----------------+
1 row in set (0.00 sec)
You can see how it’s implemented by saying
SELECT * FROM information_schema.routines WHERE routine_schema = 'xxxmdbug' AND routine_name like 'dbms_pipe_%';
The dbms_pipe_send and dbms_pipe_receive routines are GPL and copyrighted by Hewlett-Packard.
I might not moderate comments on this blog while on vacation. Tomorrow I leave for Reykjavik, Amsterdam and London.
MariaDB 10.1 Release Candidate
I installed the MariaDB 10.1 Release Candidate. Nothing interesting happened, which from MariaDB’s point of view is good. But here’s how I tried to make it interesting. Some of this applies to late releases of MariaDB 10.0 as well.
Loop with MAKE INSTALL
My habit is to download the source to directory X and then say “cmake -DCMAKE_INSTALL_PREFIX=/X” (the same directory), then “make”, then “make install”. That doesn’t work any more. Now I can’t install in the same directory that I downloaded in. Not a big deal; perhaps I’m the only person who had this habit.
Crash with ALTER
In an earlier blog post General Purpose Storage Engines in MariaDB I mentioned a crash, which I’m happy to say is fixed now. Here’s another way to crash, once again involving different storage engines.
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 2 Server version: 10.1.8-MariaDB Source distribution Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> INSTALL SONAME 'ha_tokudb'; Query OK, 0 rows affected (0.57 sec) MariaDB [(none)]> USE test Database changed MariaDB [test]> CREATE TABLE t (id INT UNIQUE, s2 VARCHAR(10)) ENGINE=tokudb; Query OK, 0 rows affected (0.56 sec) MariaDB [test]> INSERT INTO t VALUES (1,'ABCDEFGHIJ'); Query OK, 1 row affected (0.04 sec) MariaDB [test]> INSERT INTO t VALUES (2,'1234567890'); Query OK, 1 row affected (0.05 sec) MariaDB [test]> CREATE INDEX i ON t (s2); Query OK, 0 rows affected (0.64 sec) Records: 0 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=innodb; Query OK, 2 rows affected (0.53 sec) Records: 2 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=tokudb; ERROR 2013 (HY000): Lost connection to MySQL server during query
… Do not do this on a production system, as it will disable all your databases.
[ UPDATE 2015-09-29: This is apparently due to a problem with jemalloc which should only happen if one builds from source on Ubuntu 12.04. MariaDB was aware and had supplied extra information in its Knowledge Base, which I missed. Thanks to Elena Stepanova. ]
PREPARE within PREPARE
No doubt everyone encounters this situation at least once:
MariaDB [test]> prepare stmt1 from 'prepare stmt2 from @x'; ERROR 1295 (HY000): This command is not supported in the prepared statement protocol yet
… and then everyone else gets on with their lives, because preparing a prepare statement isn’t top-of-agenda. Not me. So I welcome the fact that I can now say:
MariaDB [test]> prepare stmt1 from 'begin not atomic prepare stmt2 from @x; end'; Query OK, 0 rows affected (0.00 sec) Statement prepared
So now if I execute stmt1, stmt2 is prepared. This is part of the “compound statement” feature.
Evade the MAX QUERIES PER HOUR limit
Suppose some administrator has said
GRANT ALL ON customer.* TO 'peter'@'localhost' WITH MAX_QUERIES_PER_HOUR 20;
Well, now, thanks again to the “compound statement” feature, I can evade that and do 1000 queries. Here’s the test I used:
SET @a = 0; DELIMITER // WHILE @a < 1000 DO INSERT INTO t VALUES (@a); SET @a = @a + 1; END WHILE;// DELIMITER ;
No error. So with a little advance planning, I could put 1000 different statements in a user variable, pick off one at a time from within the loop, and execute. One way of looking at this is: the WHILE ... END WHILE is a single statement. Another way to look at this is: new features introduce new hassles for administrators. Such, however, is progress. I clapped for the compound-statement feature in an earlier blog post and ended with: "But MariaDB 10.1.1 is an early alpha, and nothing is guaranteed in an alpha, so it's too early to say that MariaDB is ahead in this respect." I'm glad to say that statement is obsolete now, because this is MariaDB 10.1.8, not early alpha but release candidate.
The true meaning of the OR REPLACE clause
MariaDB has decided to try to be consistent with CREATE and DROP statements, because frankly nobody could ever remember: which CREATE statements allow CREATE IF NOT EXISTS, which CREATE statements allow CREATE OR REPLACE, which DROP statements allow DROP IF EXISTS? I wrote a handy chart in MySQL Worklog#3129 Consistent Clauses in CREATE and DROP. Now it's obsolete. The MariaDB version of the chart will have a boring bunch of "yes"es in every row.
But OR REPLACE behaviour is just a tad un-Oracle-ish. The Oracle 12c manual's description is "Specify OR REPLACE to re-create the [object] if it already exists. You can use this clause to change the definition of an existing [object] without dropping, re-creating, and regranting object privileges previously granted on it." That's not what MariaDB is doing. MariaDB drops the object and then creates it again, in effect. You can see that because you need to have DROP privilege on the object in order to say CREATE OR REPLACE.
And here's where it gets a tad un-MySQL-ish too. If you say "CREATE OR REPLACE x ...,", causing the dropping of an existing x, and then say SHOW STATUS LIKE 'Com%', you'll see that the Com_drop_* counter is zero. That is: according to the privilege requirements, x is being dropped. But according to the SHOW statement, x is not being dropped. Decent folk wouldn't use SHOW anyway, so this won't matter.
An effect on us
One of the little features of ocelotgui (the Ocelot GUI application for MySQL and MariaDB) is that one can avoid using DELIMITER when typing in a statement. The program counts the number of BEGINs (or WHILEs or LOOPs etc.) and matches them against the number of ENDs, so it doesn't prematurely ship off a statement to the server until the user presses Enter after the final END. However, this feature is currently working only for compound statements within CREATE statements. Now that compound statements are stand-alone, this needs adjusting.
Now that I've mentioned ocelotgui again, I'll add that if you go to the https://github.com/ocelot-inc/ocelotgui download page and scroll past the install instructions, you'll find more pictures, and a URL of the debugger reference, for version 0.7 alpha.
MYSQL_HISTFILE and .mysql_history
The MySQL manual says:
“mysql Logging
On Unix, the mysql client logs statements executed interactively to a history file. By default, this file is named .mysql_history in your home directory. To specify a different file, set the value of the MYSQL_HISTFILE environment variable.”
The trouble with that is: it doesn’t tell you what you don’t need to know. So I’ll tell you.
Heritage
The history-file concept that MySQL and MariaDB are following is indeed “on Unix” and specifically is like the GNU History Library. There is a dependence on external libraries, Readline or EditLine/libedit, depending on the licence. The similarity to (say) the Bash shell history is clear when one compares some names and some actions.
| Thing | Bash | MySQL |
|---|---|---|
| Default file name | $HOME/.bash_history | $HOME/.mysql_history |
| Environment variable for name | HISTFILE | MYSQL_HISTFILE |
| Environment variable for ignoring | HISTIGNORE | MYSQL_HISTIGNORE |
This explains why the history file is hidden, why the facility doesn’t work on Windows, and why there’s no orthogonality (that is, one can set an environment variable but one cannot set a configuration-file or command-line parameter).
Is it really a log?
The manual says .mysql_history is a log, but that’s a bit misleading, since it’s not much like the “logs” that the server produces (the transaction log, the slow query log, etc.). There are no timestamps; there is a large class of SQL statements that are ignored such as ones that come via file input; there is no way to know which statements succeeded and which ones ended with errors.
So the only thing .mysql_history is truly good for is making some edits easier. If you like to say “repeat last statements”, or some sophisticated variant that requires knowing what earlier statements were, then the mysql client — actually, the Readline or EditLine library — needs the history for that.
Also it’s occasionally useful for answering questions like “How did I get myself into this mess?” when odd things start to happen, and especially so when you have to write a bug report and your friendly MySQL or SkySQL or Percona support worker enquires: “Could you please show us the things you were doing just before the, er, anomaly occurred.” A tee file would be better, but sometimes a histfile might do.
Format
Not all versions of the mysql client will write the .mysql_history file in the same way. That is why sometimes you will see “X Y” if you print the file, but sometimes you will see “X\040Y”. Of course 040 is the octal for the ASCII for the space character, but this has led to bug reports such as Bug#14634386 – “History written by Libedit is not readable by Readline” and Bug#16633124 – Compatibility issue with mysql history (“\040” instead of space). These are Oracle internal bug numbers, so don’t bother trying to find them on bugs.mysql.com. They’re unimportant bugs, since they should not cause problems for editing.
A more severe matter is that multi-line statements are logged twice. First there is a record of each line. Then there is a record of the statement as a whole.
Stopping
Although disk space is cheap, people do worry sometimes when they realize their computer might be writing secret stuff in a file that burglars could see. The easiest prevention is to start the mysql client with –batch or an option that implies –batch. However, those options all do something else, as well as stopping writing to .mysql_history, so they’re not “well targeted” solutions.
There’s a recommendation to set the MYSQL_HISTFILE environment variable to say “/dev/null”, or to link the .mysql_history file to /dev/null. Loosely one might think: oh, statements are being sent to /dev/null and therefore they won’t get saved. More accurately, they might not be sent anywhere at all, as one can see from these snippets of mysql.cc code (Copyright (c) 2000, 2014, Oracle and/or its affiliates):
if (my_readlink(link_name, histfile, 0) == 0 &&
strncmp(link_name, "/dev/null", 10) == 0)
{
my_free(histfile);
histfile= 0;
}
...
if (histfile && strncmp(histfile, "/dev/null", 10) == 0)
histfile= NULL;
Limiting
Despite the similarities to Bash, there is no MYSQL_HISTSIZE environment variable to be like Bash’s HISTSIZE. With some unreliable fiddling, one can try to tell the underlying library what the maximum history size should be, that is, how many lines are allowed in the history file before starting to discard. For example, instead of saying “/usr/bin/mysql”, say
rlwrap -a --histsize=5 /usr/bin/mysql
Usually this particular trick is best avoided because of its side effects.
MYSQL_HISTIGNORE
In MySQL’s mysql, there’s a newish environment variable:
export MYSQL_HISTIGNORE=pattern
It’s not in my copy of MariaDB’s mysql, but I suppose we can expect it soon. The idea is: if a statement matches the pattern, then it doesn’t get saved in the history file. But there are some flaws …
- There are only two wildcards for the pattern: “?” meaning “one occurrence of any character”, and “*” meaning “zero or more occurrences of any character”. There is no regular-expression variation, and the choice is un-SQL-ish (in SQL one would use _ and % not ? and *).
- A certain pattern is always in effect so that passwords won’t be saved. A fine default, but it’s regrettable that there’s no way to remove it.
- It appears to be impossible to escape certain characters. For example, if I wanted the pattern to include a colon, I couldn’t say “export MYSQL_HISTIGNORE=a\:b”.
ocelotgui
The objective of Ocelot Computer Services Inc. is that the ocelotgui program will do anything that the mysql client can do, and one can dream that there are ways to do even more (porting to Windows, recognizing history size, matching more expressions, etc.) along with the advantages that a GUI automatically has over a command-line editor. But at the moment we don’t have a histfile, we only support tee. I think that’s the last big feature that ocelotgui needs before we call it ‘feature complete’, which is why I’ve been looking at .mysql_history details.
The latest ocelotgui release is 0.6.0, source and binaries are on github.com/ocelot-inc/ocelotgui.
Connecting to MySQL or MariaDB with sockets on Linux
The MySQL manual says
–socket=file_name, -S file_name … On Unix, the name of the Unix socket file to use, for connections made using a named pipe to a local server.
The default Unix socket file name is /tmp/mysql.sock.
which might surprise folks who’ve had to contend with the error message
“Can’t connect to local MySQL server through socket ‘[something-other-than-/tmp/mysql.sock]'”.
I’ll try to explain here why the name is often something quite different, how to know what the MySQL server is really listening for, what the fixes are for either users or application developers, and why it still matters.
Why the name is not always /tmp/mysql.sock
First, the Linux Foundation publishes a document “Filesystem Hierarchy Standard”. Version 2.3 says in the section about the /var/run directory: “Programs that maintain transient UNIX-domain sockets must place them in this directory.” Unfortunately Version 3 says something a bit different
in the section about the /run directory: “System programs that maintain transient UNIX-domain sockets must place them in this directory or an appropriate subdirectory as outlined above.” But version 3 also says: “In general, programs may continue to use /var/run to fulfill the requirements set out for /run for the purposes of backwards compatibility.” so /var/run is still standard.
Second, there’s a bit of fine print tucked away in an appendix of the MySQL manual: “For some distribution formats, the directory might be different, such as /var/lib/mysql for RPMs.” That’s a vague way of saying it’s determined at source-installation time by -DINSTALL_LAYOUT={STANDALONE|RPM|SVR4|DEB} which in effect causes this:
SET(INSTALL_UNIX_ADDRDIR_STANDALONE "/tmp/mysql.sock") SET(INSTALL_UNIX_ADDRDIR_RPM "/var/lib/mysql/mysql.sock") SET(INSTALL_UNIX_ADDRDIR_DEB "/var/run/mysqld/mysqld.sock") SET(INSTALL_UNIX_ADDRDIR_SVR "/tmp/mysql.sock")
but anybody can override that by setting MYSQL_UNIX_ADDR to something else.
And so different machines have different defaults. The following comes from notes I made long ago so may not be the latest information:
Non-Linux e.g. FreeBSD or Solaris: /tmp/mysql.sock Debian-based e.g. Ubuntu, and archlinux: /var/run/mysqld/mysqld.sock SUSE (after v11.2): /var/run/mysql/mysql.sock Red Hat, and SUSE (before v11.2): /var/lib/mysql/mysql.sock archlinux (very old versions): /tmp/mysqld.sock
Sometimes you can find out what the real default on your machine was,
by typing mysql_config –socket.
Finding what the server is really listening for
If you’re not the one who started the server, or the starting has disappeared in the mists of memory, there are various flawed ways to find what socket
it’s really opened.
Possible Method #1: netstat -lpn | grep mysqld
Example:
$ netstat -lpn | grep mysqld (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 :::3306 :::* LISTEN 4436/mysqld unix 2 [ ACC ] STREAM LISTENING 101567 4436/mysqld ./mysql_sock
… This method’s flaw is that, as the warning says, you won’t see everything unless you’re root. Also the “grep mysqld” filtering means it’s assumed the server’s name is mysqld.
Possible Method #2: find directory-list -name “mysql*.sock”
Example:
$ find /tmp /var/lib/mysql /var/run/mysqld -name "mysql*.sock" find: 'var/lib/mysql': Permission denied /var/run/mysqld/mysqld.sock
… This method’s flaw is that you have to guess in advance what directories the socket might be on.
Possible Method #3: ask via TCP
Example:
mysql -h 127.0.0.1 -e "select @@socket" +-----------------------------+ | /var/run/mysqld/mysqld.sock | +-----------------------------+
… This method’s flaw is in the assumption that the port is the default (3306), that the local host is accessible (I think it’s theoretically possible that it won’t be), and that everyone has the privilege to access MySQL this way.
Possible Method #4: look at the running process
Example (after finding with ps -A that mysqld process ID = 3938):
$ ps -fp 3938 UID PID PPID C STIME TTY TIME CMD 1000 3938 18201 0 09:58 pts/2 00:00:00 bin/mysqld --socket=./sock
… This method’s flaw is that it only works if –socket was specified explicitly on a mysqld command line, overriding the default configuration.
What a user can do
Once you know that the server is listening on socket X, you can redirect with ln, for example
ln -s /var/run/mysqld/mysqld.sock /tmp/mysql.sock
… The flaw this time is that it’s trying to solve a MySQL/MariaDB problem with a Linux workaround. The only reason that I mention it is that I’ve seen it recommended on Internet forums, so I guess some people see advantages here, which I don’t.
A better answer, then, would be: tell the client program what the socket is. On a client that follows the MySQL guidelines (such as the mysql client itself, or ocelotgui), this would mean setting the MYSQL_UNIX_PORT environment variable, or starting with –socket=X on the command line, or changing one of the configuration files such as ~/.my.cnf to add the line socket = X. Beware that the socket location might also be stored in other places, such as /etc/mysql/debian.cnf or php.ini.
What a client program should do
People who write client programs shouldn’t pass this socket hassle on to the user, if they don’t have to.
The mysql client tries to make things easier by, in effect, hard-coding a socket name so it’s the same as what the server got installed with. That’s a good try. My only criticism is that mysql –help will say that the socket parameter has “(No default value)” when, in a sense, it does.
I’ve been told that another client-GUI product tries to make things easier by automatically going with TCP. It’s difficult to criticize this — I’ve always thought that MySQL made trouble for itself by deciding that even when a user says “host=localhost” we should ignore the usual implication that the user is trying to use TCP and try to find a socket anyway — but here at Ocelot we try to behave the way the mysql client behaves, flawed or not.
So ocelotgui will try to make things easier by hard-coding the most likely paths. That is, if the user doesn’t specify a socket but the host is either default or ‘localhost’, then ocelotgui will try to connect via /tmp/mysql.sock, and if that fails then /var/lib/mysql/mysql.sock, and if that fails then /var/run/mysqld/mysqld.sock. That’s just the plan; currently ocelotgui isn’t doing it.
Is it worth caring about?
Couldn’t the Gordian socket be cut by saying protocol=TCP? What’s the point of finding the socket, anyway?
The answer usually is performance. The transfer rate with sockets is faster than with TCP because why do I need to worry about protocol when I’m talking to myself? I haven’t done a benchmark myself but Brandon D. Northcutt did and it does appear that sockets are worth the trouble if huge quantities of data are coming through.
However, really the TCP-versus-socket difference is a Linux problem, so why isn’t it being solved by the Linux crowd rather than the MySQL or MariaDB crowds? Well, unsurprisingly, that question has been asked before. So there is a fix, or more precisely there is a Google patch, which turns a TCP/IP connection into a socket connection if the target is localhost. There was an article about it on lwn.net in 2012. What happened after that, I don’t know.
By the way
The current state of ocelotgui (our open-source GUI client for MySQL and MariaDB) is still alpha, but it’s stable and good-looking now. Some screenshots are here. The latest release is 0.7, here.
Decrypt .mylogin.cnf
General-purpose MySQL applications should read MySQL option files like /etc/my.cnf, ~/.my.cnf, … and ~/.mylogin.cnf. But ~/.mylogin.cnf is encrypted. That’s a problem for our ocelotgui GUI application, and I suppose other writers of Linux applications could face the same problem, so I’ll share the code we’ll use to solve it.
First some words of defence. I think that encryption (or more correctly obfuscation) is okay as an option: a customer asked for it, and it prevents the most casual snoopers — rather like a low fence: anyone can get over it, but making it a bit troublesome will make most passersby pass by. I favoured the idea, though other MySQL employees were against it on the old “false sense of security” argument. After all, by design, the data must be accessible without requiring credentials. So just XORing the file contents with a fixed key would have done the job.
Alas, the current implementation does more: the configuration editor not only XORs, it encrypts with AES 128-bit ecb. The Oxford-dictionary word for this is supererogation. This makes reading harder. I’ve seen only one bug report / feature request touching on the problem, but I’ve also seen that others have looked into it and provided some solutions. Kolbe Kegel showed how to display the passwords, Serge Frezefond used a different method to display the whole file. Great. However, their solutions require downloading MySQL source code and rebuilding a section. No good for us, because ocelotgui contains no MySQL code and doesn’t statically link to it. We need code that accesses a dynamic library at runtime, and unless I missed something big, the necessary stuff isn’t exported from the mysql client library.
Which brings us to … ta-daa … readmylogin.c. This program will read a .mylogin.cnf file and display the contents. Most of it is a BSD licence, so skip to the end to see the twenty lines of code. Requirements are gcc, and libcrypto.so (the openSSL library which I believe is easily downloadable on most Linux distros). Instructions for building and running are in the comments. Cutters-and-pasters should beware that less-than-sign or greater-than-sign may be represented with HTML entities.
/*
readmylogin.c Decrypt and display a MySQL .mylogin.cnf file.
Uses openSSL libcrypto.so library. Does not use a MySQL library.
Copyright (c) 2015 by Ocelot Computer Services Inc.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name of the nor the
names of its contributors may be used to endorse or promote products
derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
To compile and link and run with Linux and gcc:
1. Install openSSL
2. If installation puts libcrypto.so in an unusual directory, say
export LD_LIBRARY_PATH=/unusual-directory
3. gcc -o readmylogin readmylogin.c -lcrypto
To run, it's compulsory to specify where the file is, for example:
./readmylogin .mylogin.cnf
MySQL may change file formats without notice, but the following is
true for files produced by mysql_config_editor with MySQL 5.6:
* First four bytes are unused, probably reserved for version number
* Next twenty bytes are the basis of the key, to be XORed in a loop
until a sixteen-byte key is produced.
* The rest of the file is, repeated as necessary:
four bytes = length of following cipher chunk, little-endian
n bytes = cipher chunk
* Encryption is AES 128-bit ecb.
* Chunk lengths are always a multiple of 16 bytes (128 bits).
Therefore there may be padding. We assume that any trailing byte
containing a value less than '\n' is a padding byte.
To make the code easy to understand, all error handling code is
reduced to "return -1;" and buffers are fixed-size.
To make the code easy to build, the line
#include "/usr/include/openssl/aes.h"
is commented out, but can be uncommented if aes.h is available.
This is version 1, May 21 2015.
More up-to-date versions of this program may be available
within the ocelotgui project https://github.com/ocelot-inc/ocelotgui
*/
#include <stdio.h>
#include <fcntl.h>
//#include "/usr/include/openssl/aes.h"
#ifndef HEADER_AES_H
#define AES_BLOCK_SIZE 16
typedef struct aes_key_st { unsigned char x[244]; } AES_KEY;
#endif
unsigned char cipher_chunk[4096], output_buffer[65536];
int fd, cipher_chunk_length, output_length= 0, i;
char key_in_file[20];
char key_after_xor[AES_BLOCK_SIZE] = {0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
AES_KEY key_for_aes;
int main(int argc, char *argv[])
{
if (argc < 1) return -1;
if ((fd= open(argv[1], O_RDONLY)) == -1) return -1;
if (lseek(fd, 4, SEEK_SET) == -1) return -1;
if (read(fd, key_in_file, 20) != 20) return -1;
for (i= 0; i < 20; ++i) *(key_after_xor + (i%16))^= *(key_in_file + i);
AES_set_decrypt_key(key_after_xor, 128, &key_for_aes);
while (read(fd, &cipher_chunk_length, 4) == 4)
{
if (cipher_chunk_length > sizeof(cipher_chunk)) return -1;
if (read(fd, cipher_chunk, cipher_chunk_length) != cipher_chunk_length) return -1;
for (i= 0; i < cipher_chunk_length; i+= AES_BLOCK_SIZE)
{
AES_decrypt(cipher_chunk+i, output_buffer+output_length, &key_for_aes);
output_length+= AES_BLOCK_SIZE;
while (*(output_buffer+(output_length-1)) < '\n') --output_length;
}
}
*(output_buffer + output_length)= '\0';
printf("%s.\n", output_buffer);
}
The ocelotgui debugger
I have merged a debugger for MySQL/MariaDB stored procedures and functions into our GUI client and posted the source and binaries on github. It allows breakpoint, clear, continue, next, skip, step, tbreakpoint, and variable displays. Features which are rare or missing in other debuggers include:
its current platform is Linux;
it allows breakpoints on functions which are invoked within SQL statements;
it never changes existing stored procedures or functions;
it is integrated with a general GUI client;
it allows commands like gdb and allows menu items / shortcut keys like ddd;
it is available on github as C++ source with GPL licence.
It’s alpha and it’s fragile but it works. Here is a demo.
Start the client and connect to a running server, as root. Actually the required privileges are merely for creation of certain objects and SUPER, but I’m making this simple.
Type the statement: DELIMITER // (For all typed-in instructions, execute by typing carriage-return after the delimiter or by clicking Run|Execute.)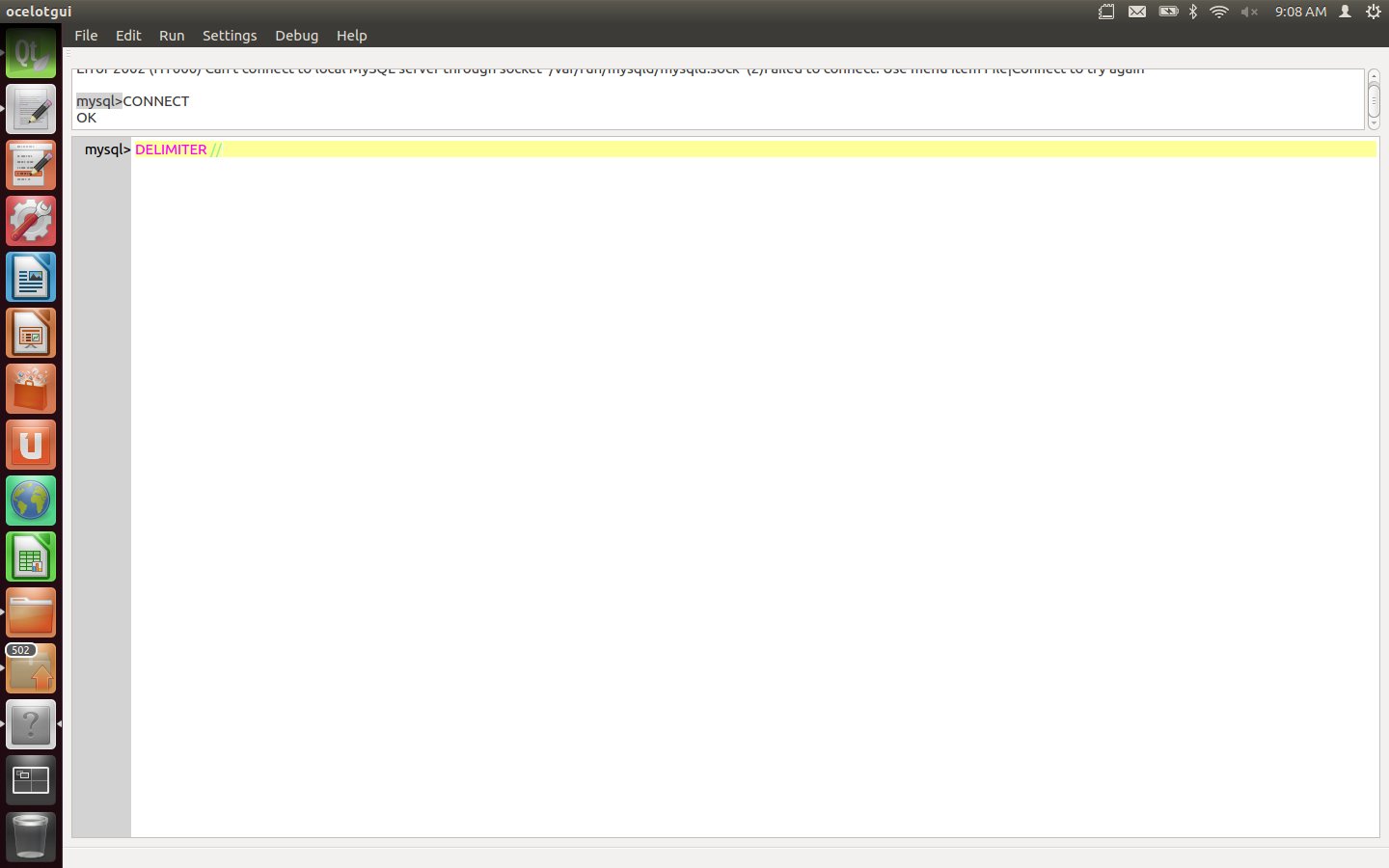
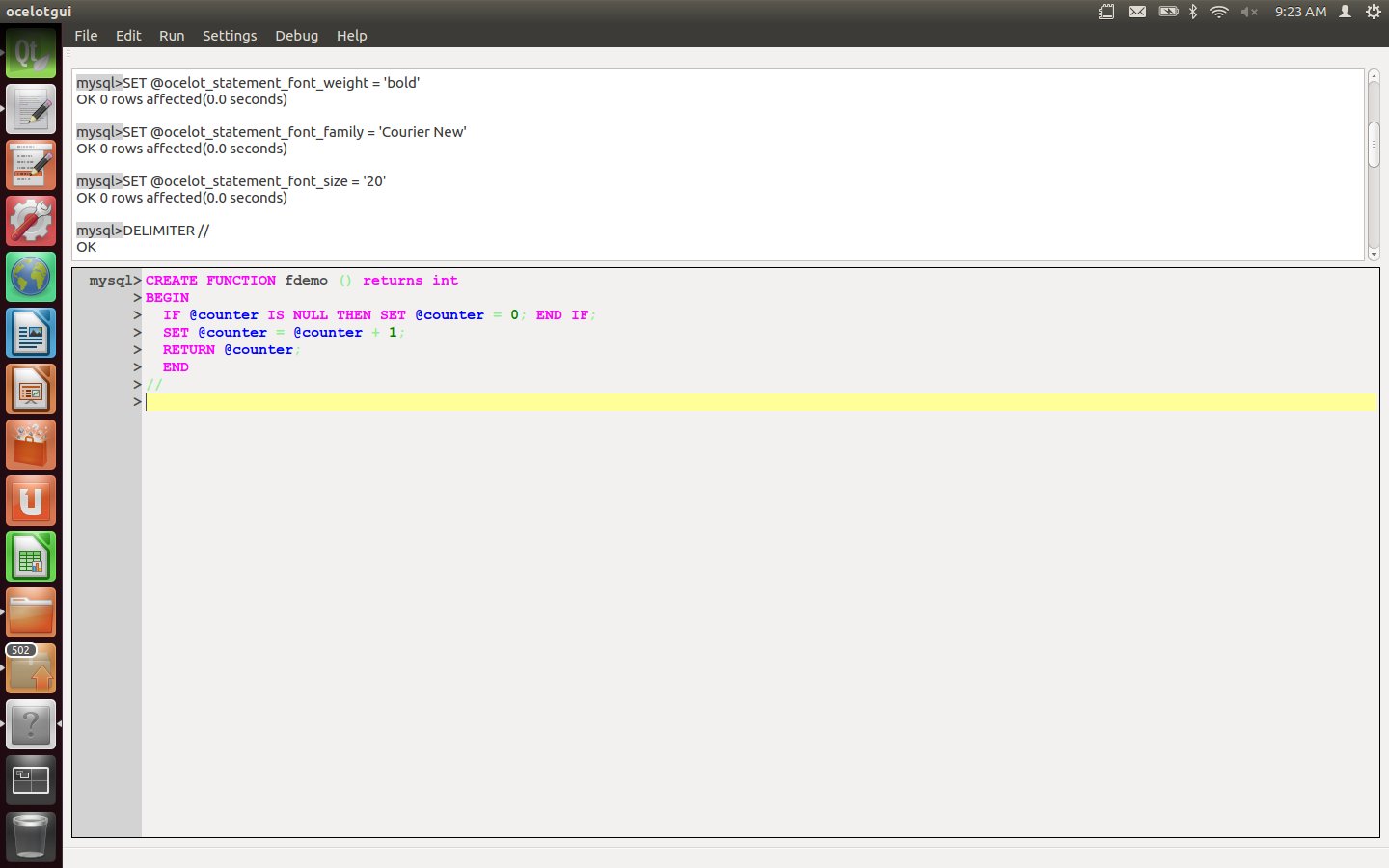
Create a function fdemo which updates and returns a counter.
CREATE FUNCTION fdemo () RETURNS INT
BEGIN
IF @counter IS NULL THEN SET @counter = 0; END IF;
SET @counter = @counter + 1;
RETURN @counter;
END
//
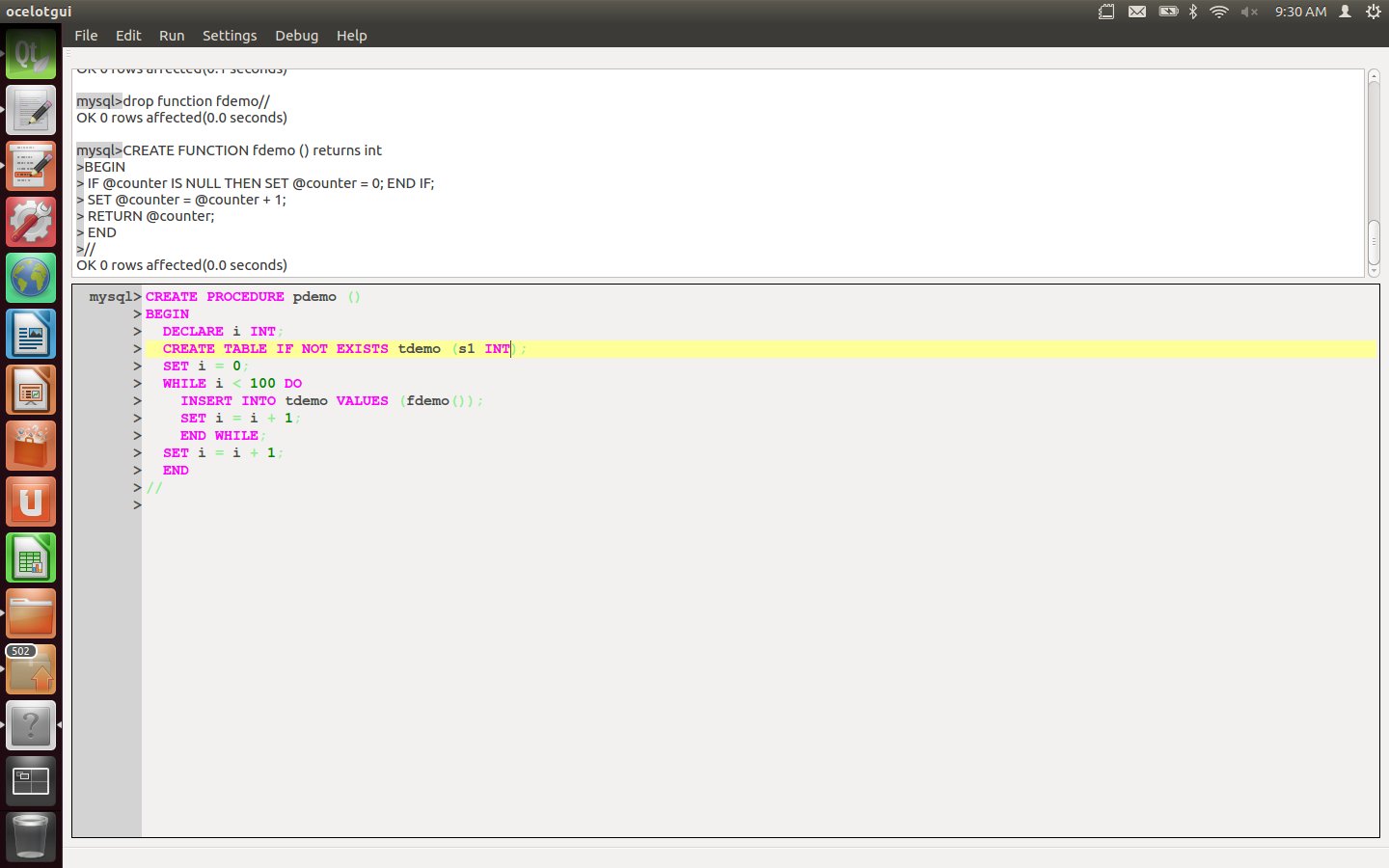
Create a procedure pdemo which contains a loop of “INSERT INTO tdemo VALUES (fdemo())” statements.
CREATE PROCEDURE pdemo ()
BEGIN
DECLARE i INT;
CREATE TABLE IF NOT EXISTS tdemo (s1 INT);
SET i = 0;
WHILE i < 100 DO
INSERT INTO tdemo VALUES (fdemo());
SET i = i + 1;
END WHILE;
SET i = i + 1;
END
//
Type the statement: DELIMITER ;
Type the statement: $install;
Type the statement: $setup fdemo, pdemo;
Type the statement: $debug pdemo;
After this statement is executed a tabbed widget appears. The first line of pdemo is highlighted. There is always a breakpoint before the first line.
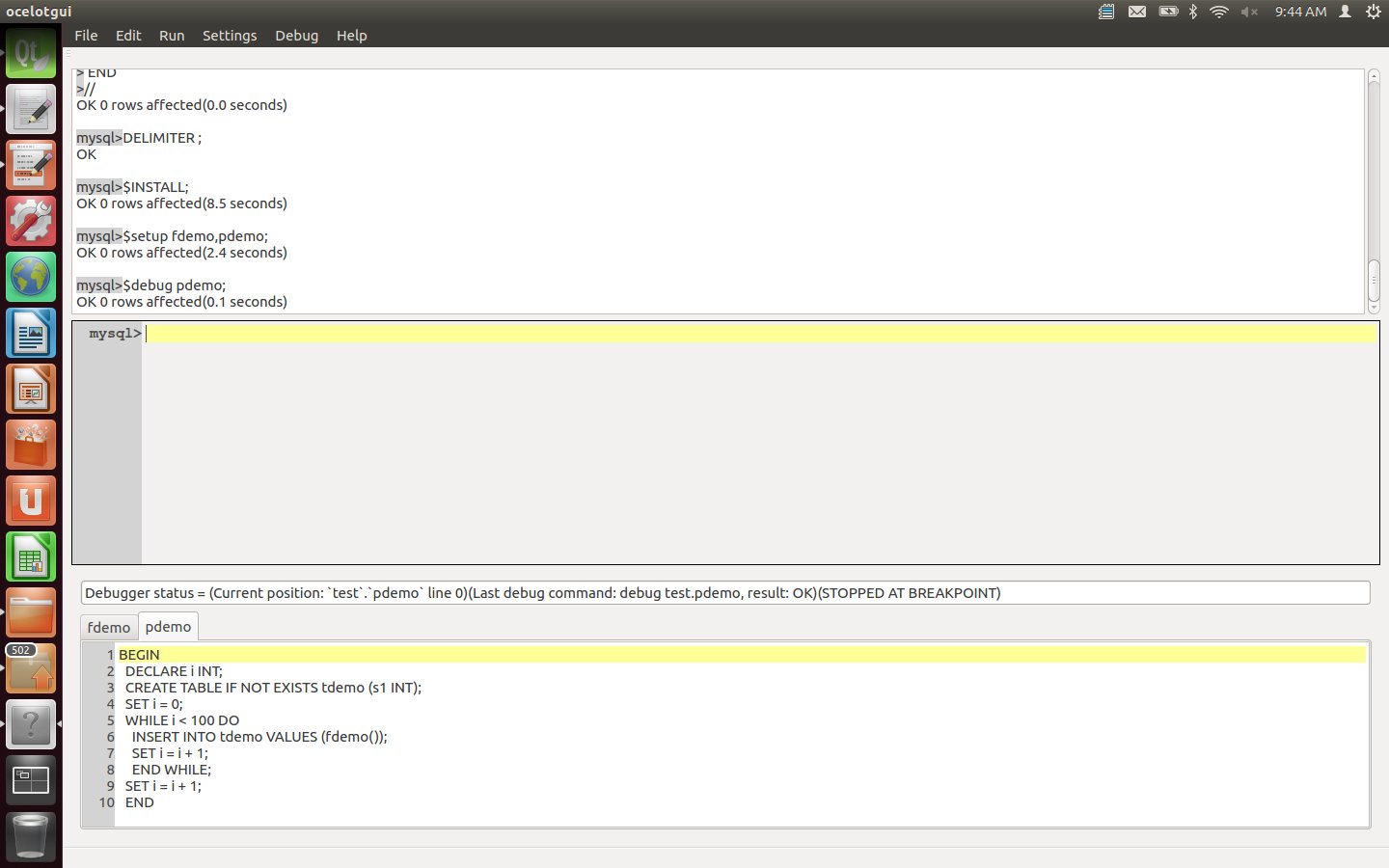
Click on the Debug menu to see what options are available. Debugger instructions may be done via the menu, via Alt keys, or via command-line statements. For example to enter a Next instruction one may now click Debug|Next, or type Alt+3, or type the statement: "$next;".
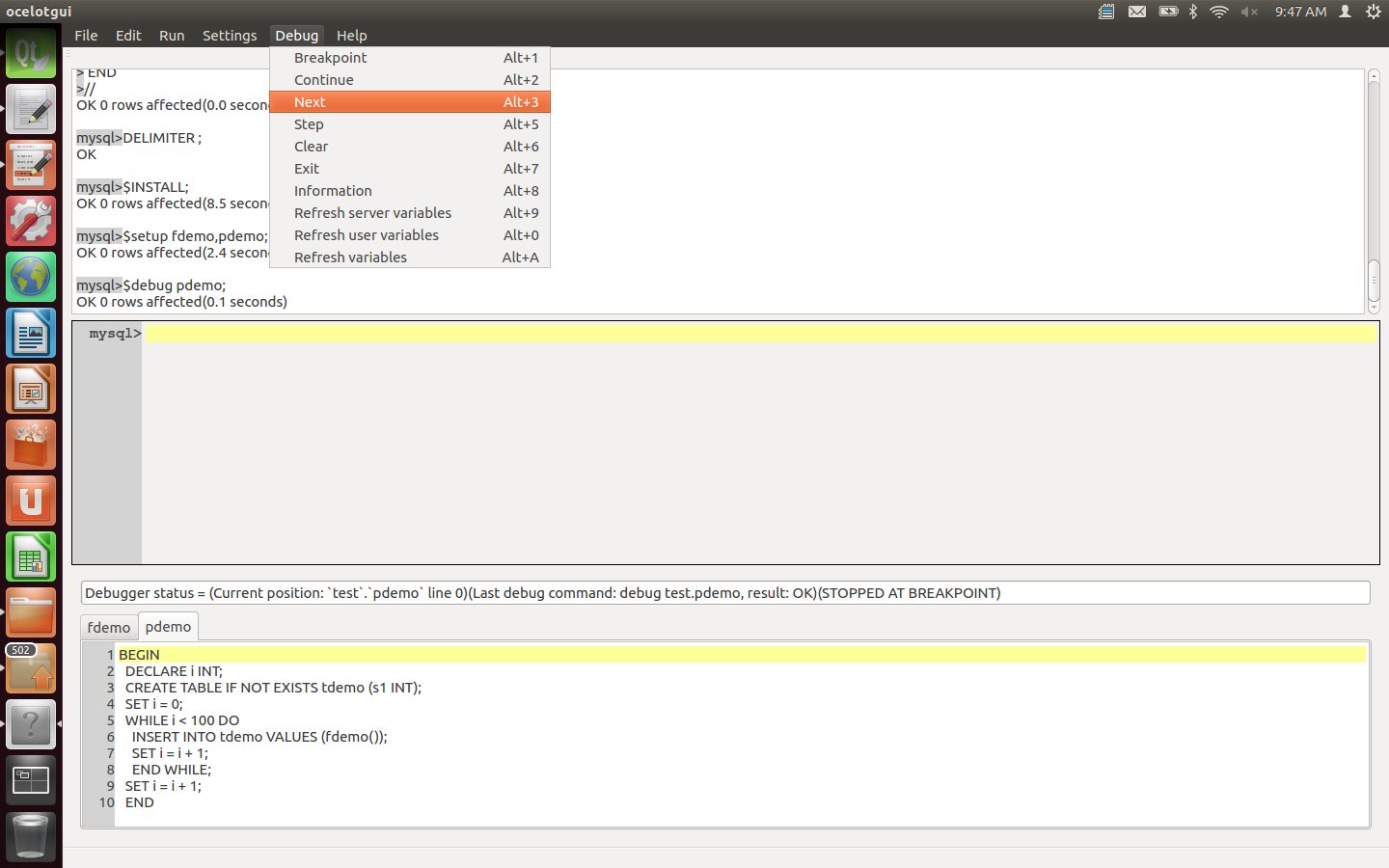
Enter a Next instruction repeatedly, watching how the highlighted line changes, until the INSERT line is highlighted.
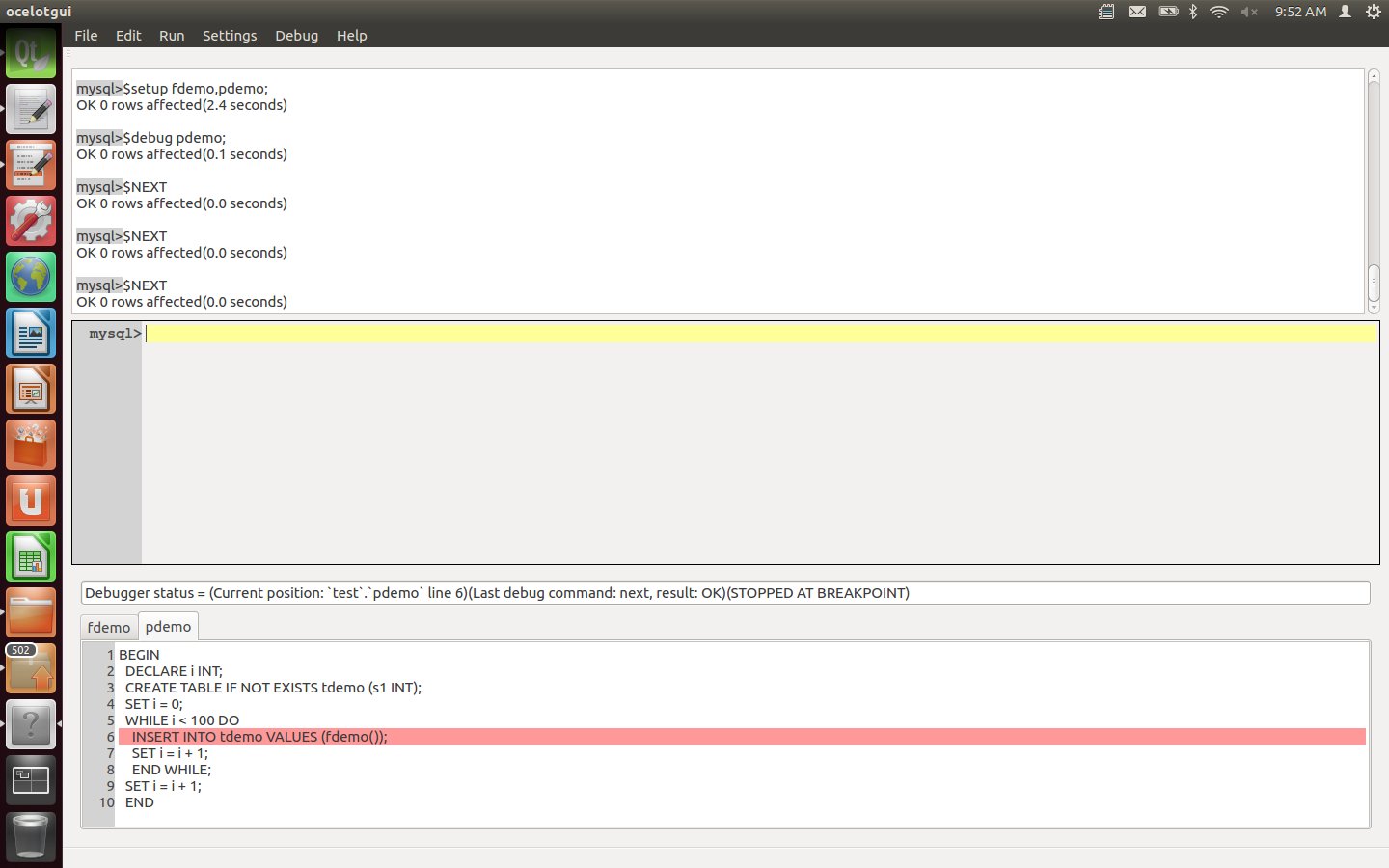
Enter a Step instruction. After this is executed, the function now comes into the foreground.
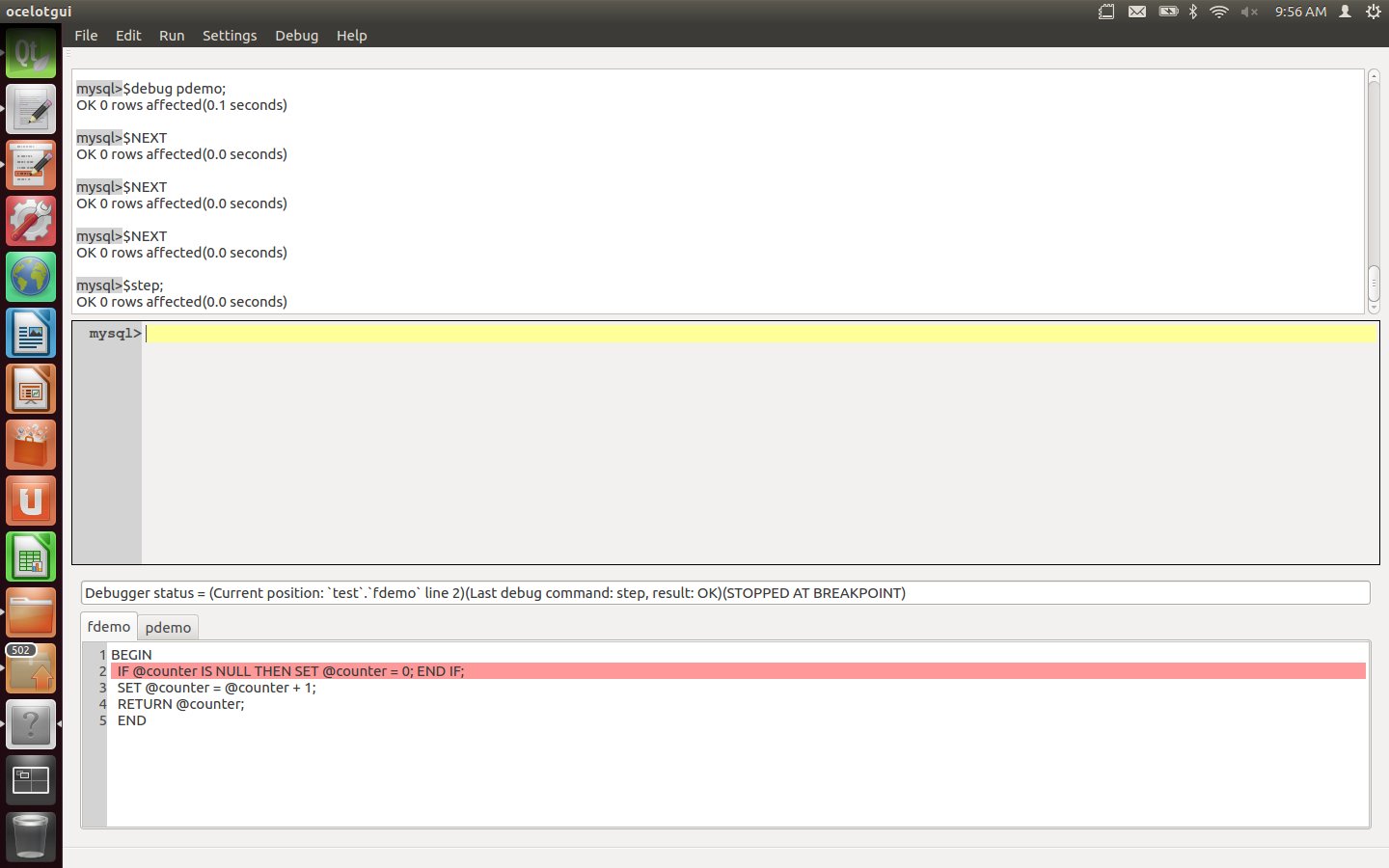
Enter three more Step (or Next) instructions. After these are executed, the procedure now is in the foreground again.
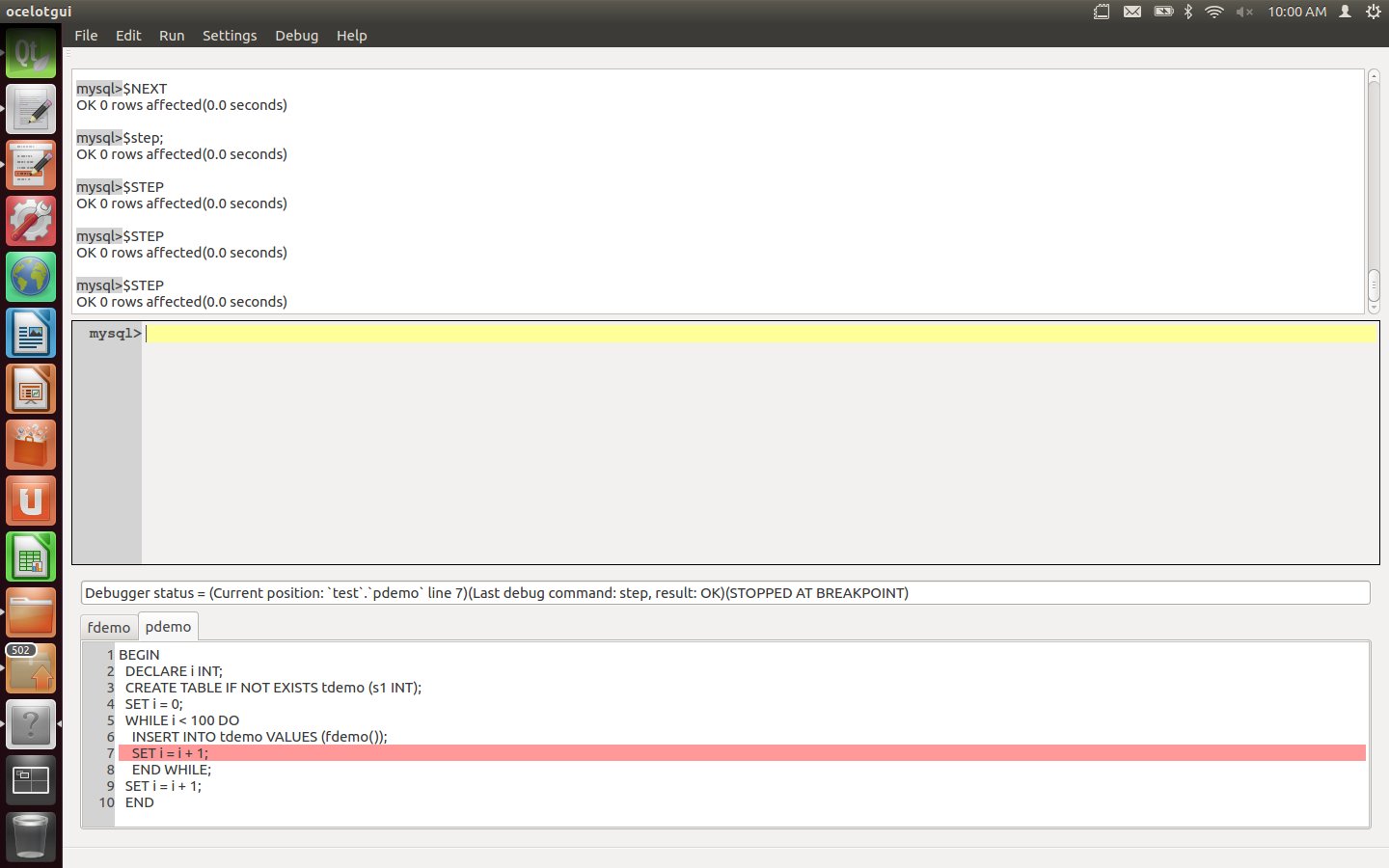
Set a breakpoint for the final executable line of the procedure. This can be done by clicking over the line number, or by moving the cursor to the line and then clicking Debug|Breakpoint, or by typing the statement "$breakpoint pdemo 9;". After this is executed, line 9 of pdemo has a small red mark showing that it has a breakpoint.
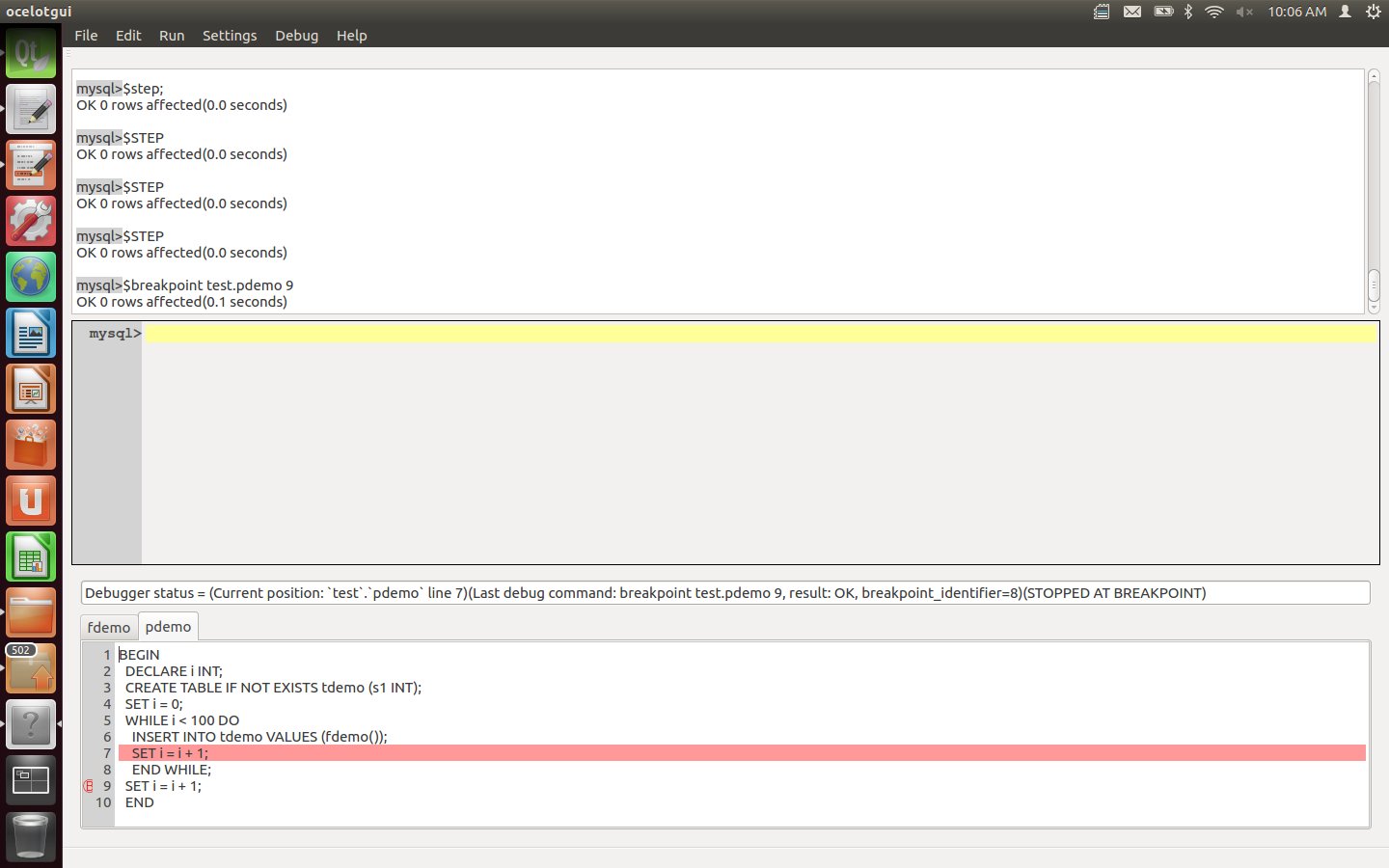
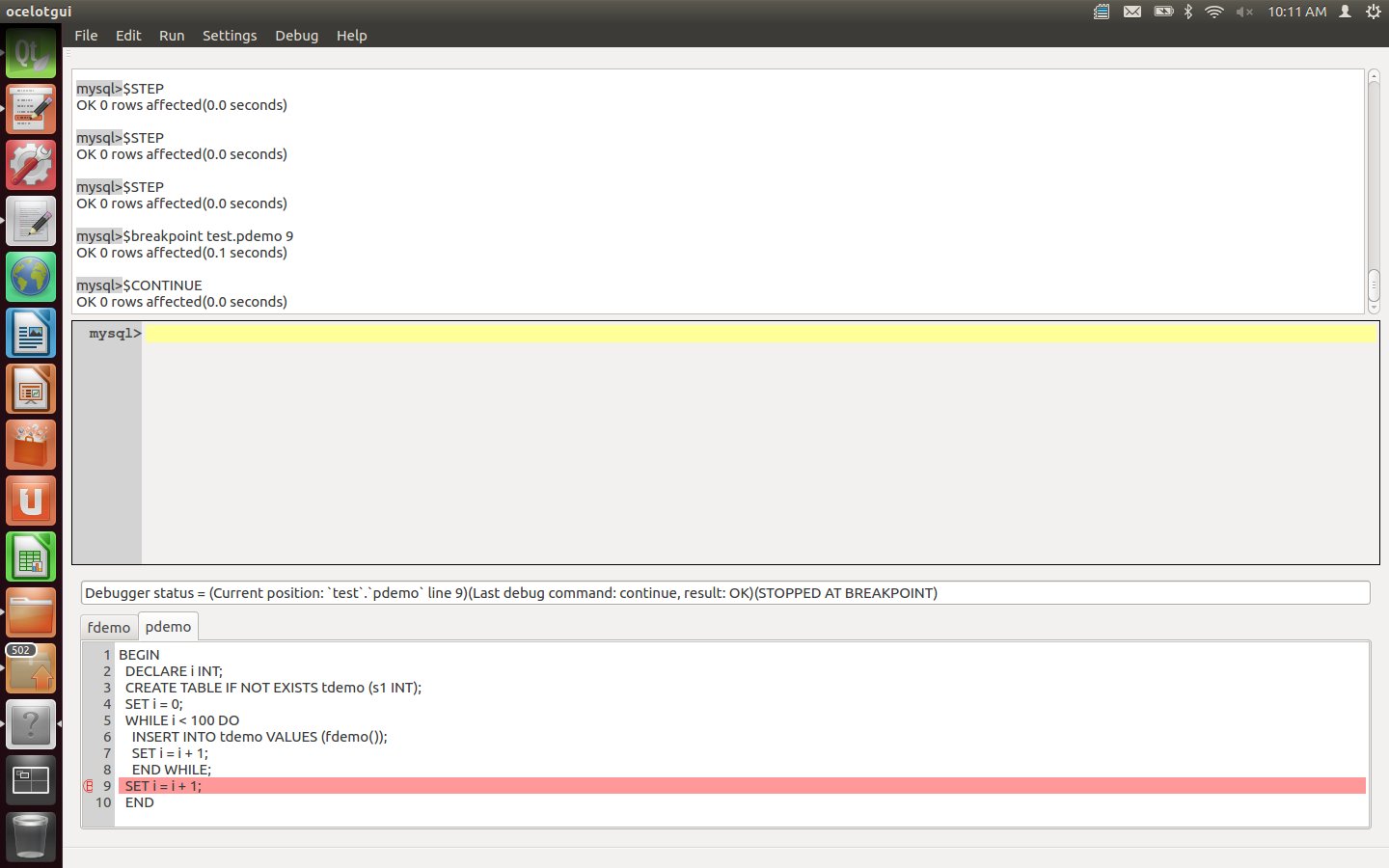
Enter a Continue instruction. After this is executed, watch the debugger highlight hop around 100 times as it moves through the loop, and finally settle on line 9.
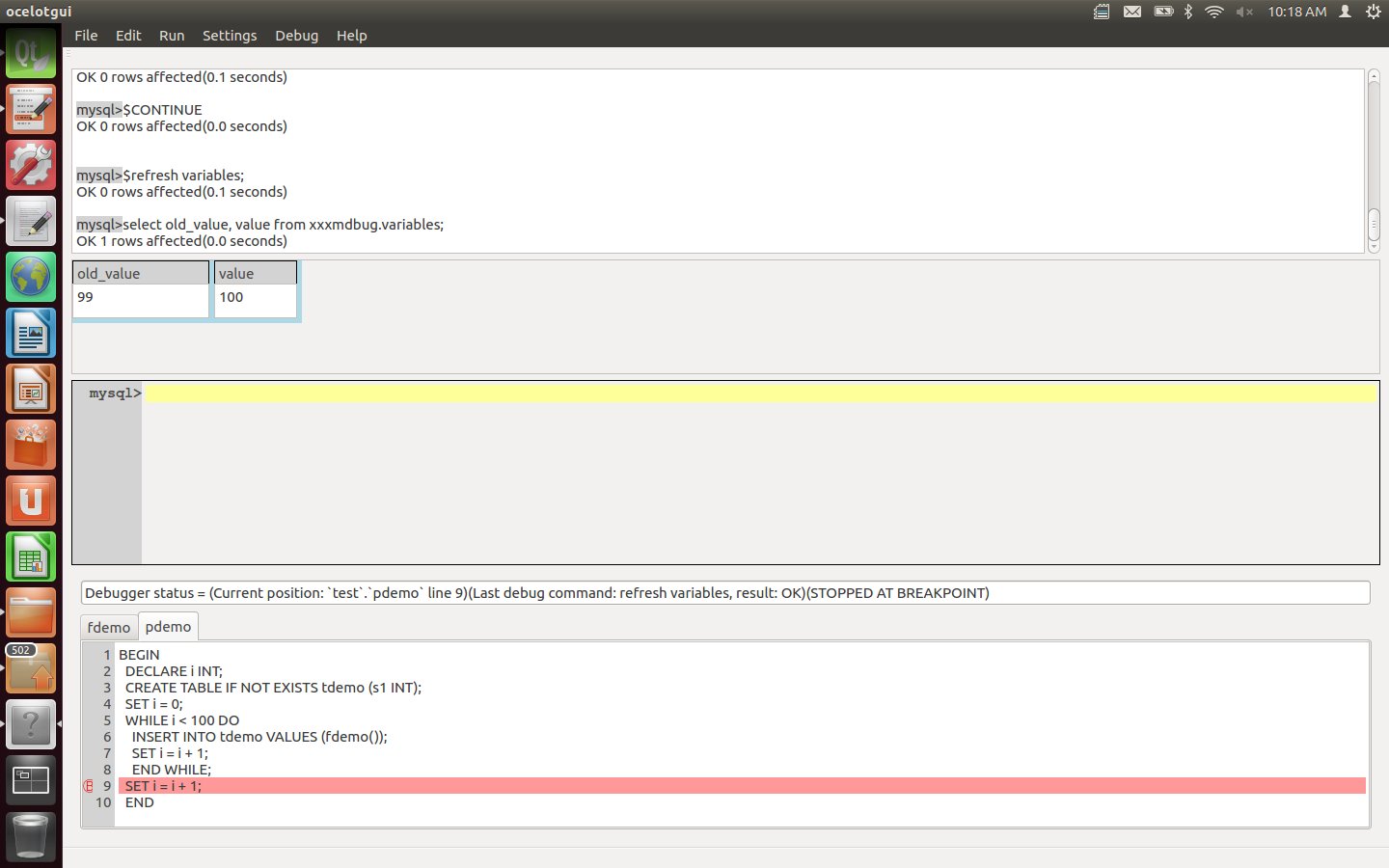
Type the statements "$refresh variables;" and "select old_value, value from xxxmdbug.variables;". After this is executed, the result-set widget will contain the old value of variable i (99) and the current value (100), This is the way that one examines DECLAREd variables (there are other statements for user variables and server variables).
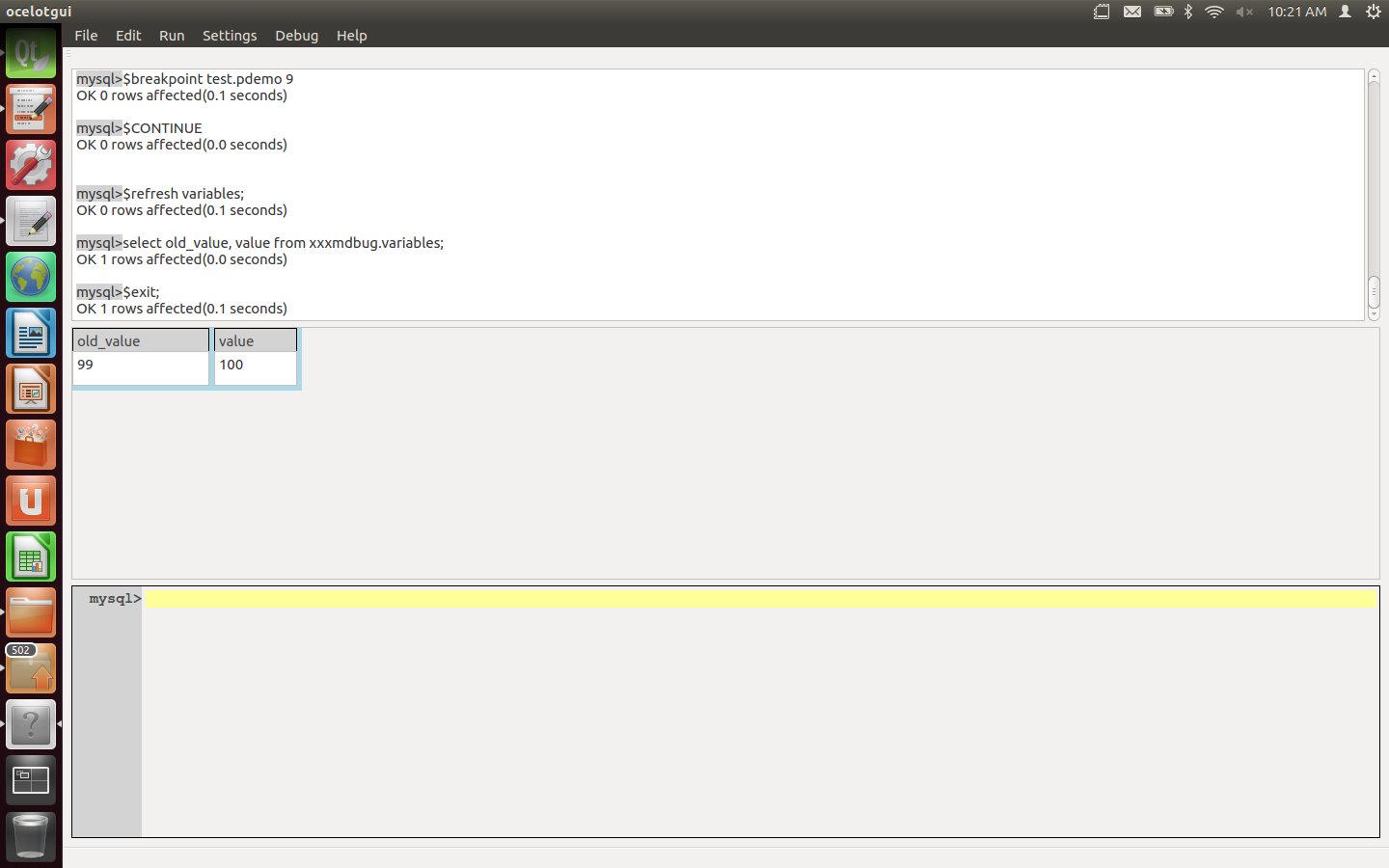
Enter an $exit instruction. This stops the debugging session, so the effects of the earlier $debug instruction are cancelled. The effects of the earlier $install and $setup instructions are not cancelled, so they will not have to be repeated for the next debugging session involving pdemo and fdemo.
Thus ends our demo. If you would like to confirm it: an introduction for how ocelotgui in general works is in the earlier blog post An open-source MySQL/MariaDB client on Linux" and the source + executable download files for version 0.3.0 are on github.com/ocelot-inc/ocelotgui.
If there is anything Ocelot can do to make your next debugging trip more enjoyable, please leave a comment. If you have private thoughts, please write to pgulutzan at ocelot.ca.
Stored Procedures: critiques and defences
I’ve gathered the main critiques of MySQL / MariaDB stored procedures, and will try some defences.
Monoglots
The critique:
SQL/PSM is the standard 4GL and it was the work of Andrew Eisenberg. Andy based it on ADA. Unless you are military, you have never seen ADA. Be grateful it is dead.
— Joe Celko, reminiscing about his days on the SQL standard committee
Actually I believe Mr Celko likes SQL/PSM, which is the standard that MySQL and MariaDB follow. Here at last is your chance to see some Ada code, and compare with MySQL code …
Ada |
MySQL |
|---|---|
declare a: integer;
begin
a := 0;
loop
a := a + 100;
exit when a = 200;
end loop;
if a /= 300 then
a := 400;
else
a := 500;
end if;
case a is
when 600 a := 700;
when others a := 800;
end case;
end;
|
begin
declare a integer;
set a = 0;
x:loop
set a = a + 100;
if a = 200 then leave x; end if;
end loop;
if a <> 300 then
set a = 400;
else
set a = 500;
end if;
case a
when 600 then set a = 700;
else set a = 800;
end case;
end;
|
The trouble is, Ada isn’t even among the top ten programming languages according to O’Reilly’s count of book sales, and the choice of only 1.6% of programmers according to the Language Popularity Index. So programmers aren’t used to seeing syntax like the above. And I, who am just as good a psychologist as I am an Ada programmer, explain: they’re not familiar with it, so they call it ugly.
The defence:
Look at the first alternative: UDFs. Percona posts point out that UDFs can be faster. of course.
But look at the example in Managing & Using MySQL Second Edition. Do you understand it without reading the long commentary?
Now look at the second alternative: External stored procedures. There’s a worklog task for stored procedures in other languages, of course.
But it’s moribund. An implementation on launchpad, “External Language Stored Procedures for MySQL”, exists but doesn’t seem to have been updated since 2009. Are you going to go to the trouble of downloading and adjusting it?
If you answered yes to either of the above questions, please check the length of your nose now.
Migrants
The critique:
“Migrating a stored procedure is much more complex than rewriting one because the relevant standards of various vendors differ greatly. In this situation, users have no choice but stick to one database vendor rigidly. There is not any room left for users to beat down the price if database vendors overcharge them on upgrading their servers, storages, and user license agreements.”
— Couchbase, “Alternative to Difficult Stored Procedures in Big Data Computation”
The defence: That’s not true. There’s only one relevant standard, there are multiple migration paths, and there’s no charge.
The other DBMSs that follow the ANSI/ISO SQL/PSM standard are: DB2, Mimer, SolidDB, Sybase iAnywhere (Advantage Database Server).
Selective quotes from a case study about “experiences with porting stored procedures written in SQL PL (DB2) to MySQL”:
To find out how “standardized” the MySQL implementation of the SQL/PSM specification really is, we tried to port all our DB2 stored procedures to MySQL. First, we ran into DB2 non-standard extensions of SQL PL that were used in our existing procedures. Actually, there was only one such extension [SQLCODE] … So we first rewrote our DB2 procedures –in DB2–, making sure not to use SQLCODE anymore. Instead we had to introduce the corresponding continue handler(s), thereby introducing an additional “flag” variable. This worked out fine: the new procedures ran perfectly in DB2. … Now we observed some syntactic differences, luckily not in the body of the procedures but in the optional clauses specified just before the body … The only option clause which we could keep was the “LANGUAGE SQL”: required in DB2, optional with MySQL. After these small modifications, the CREATE PROCEDURE statements from DB2 worked on MySQL!
But did they run properly? To verify this, we had to create identical tables on both systems, have the same test data in both, and migrate then run the unit test programs from DB2 on MySQL. And indeed: it turned out that MySQL worked exactly as expected!
— Peter Vanroose (ABIS), MySQL: stored procedures and SQL/PSM
As for Oracle, its PL/SQL language is not standard, but read the Oracle documentation: “PL/SQL is based on the programming language Ada.” Due to the common Ada heritage that PL/SQL and SQL/PSM share, I’ve been able to convert Oracle stored procedures to MySQL stored procedures at a rate of about a line per minute. I expect I’d achieve the same speed with NuoDB (NuoDB architect Jim Starkey once assured me that their stored procedures will follow PL/SQL), and with PostgreSQL (PostgreSQL’s stored procedures are deliberately Oracle-like). There’s also an SQL/PSM add-on for PostgreSQL, although I don’t think it’s popular.
Finally, there are some commercial tools that try to automate the migration process. I think the one from ispirer is the best known.
Toolmakers
The critique:
Your stored routines are not likely to integrate well with your IDE. … [SQL-oriented GUI tools] do not integrate (well?) with your source control … While engineers are keen on writing unit tests for every class and method they create, they are less keen on doing the same for stored routines. … MySQL routines have [no?] built in debugging capabilities …
— Shlomi Noach, “Why delegating code to MySQL Stored Routines is poor engineering practice”
The defence:
These are important considerations, but strictly speaking they’re about what people should have written to go with stored procedures, not about stored procedures themselves. It’s not the wiener’s fault if there’s no mustard.
Take versioning. For Oracle it can be done with a client GUI named Oracle SQL Developer. For MySQL there are open-source utilities like dbv. Either way, it’s not a server task.
Take unit tests. Hmm, okay, you can’t, but some people might be satisfied with MyTAP or maybe even STK/Unit. And did you notice in the quote above that one can make unit tests with DB2 tools and run them in MySQL?
Take debuggers. I’m aware of five, although I haven’t tried any of them, except the one that I wrote myself. I am going to integrate it with ocelotgui.
Could-do-betters
The critique:
Stored Procedures … do not perform very well
— Percona employee, How can we bring query to the data”
The defence:
Supposedly there are more than 12 million installations and that means there are 12 million which are, as the old saying goes, “not Facebook”. I haven’t interviewed them all (only Monty Widenius can do that), but the ones that I’ve talked to are concerned more about the effects of badly-written queries or database design mistakes.
Grapevines
The critique:
It’s easy to find articles and blog posts with titles like “Why I hate stored procedures”, “Goodbye Stored procedures, It’s the time to move on”, “Stored Procedures – End of days”, “Why I avoid stored procedures and you should too”.
The defence:
Usually those articles are about SQL Server. They are by people who got fed up with Microsoft’s T-SQL language, or got enamoured of ORM (Object Relational Management). Inevitably some of the bad vibes get picked up in the MySQL / MariaDB community due to morphic resonance. Filter out the Microsoft material, and it gets harder to find such articles or blog posts, and it gets easier to find articles with more walking-in-the-sunshine outlook.
Besides, some of the alternatives might just be fads. As Winston Churchill said:
Many forms of Database Code have been tried, and will be tried in this world of sin and woe. No one pretends that Stored Procedures are perfect or all-wise. Indeed, it has been said that Stored Procedures are the worst form of Database Code except all those other forms that have been tried from time to time.
— Winston Churchill, Hansard, November 11 1947
Okay, he didn’t actually say Database Code or Stored Procedures, he said Government and Democracy. Close enough.
Sloths
The critique:
“The following features have been added to MySQL 5.6: … GET DIAGNOSTICS”
“The following features have been added to MySQL 5.7: … GET STACKED DIAGNOSTICS”
— MySQL user manual for 5.6 and 5.7
All right, you have to read between the lines a bit to see the critique here.
What MySQL/Oracle is implying, by omission, is: progress is glacial. As I said in a previous post I think GET DIAGNOSTICS is good to see. But the first MySQL 5.6 releases were four years ago. So, one significant new feature every two years.
What about MariaDB? Well, I did see a new trick recently in a blog post by Federico Razzoli: How MariaDB makes Stored Procedures usable, about using cursors even for SHOW statements. And I suppose that MariaDB’s “compound statements” feature could be looked on as at least a feature that’s closely related to stored procedures. Still, small potatoes.
The defence:
* The current implementation has pretty well all the significant matters required by the standard.
* There has been no official announcement that any significant stored procedure feature is deprecated.
What is a data type?
I’d suppose that these statements are generally accepted:
A data type is a set of values.
So any value that belongs to that set is said to “have” or “belong to” that data type.
And any column which is defined as “of” that data type is going to contain values which have that data type, only.
For example a column C may be defined as of type INTEGER and will only contain values which belong to the set of integers.
And now for the exceptions, details, caveats, and errors.
What is synonymous with data type?
There are no synonyms; no other term should ever be used.
Not datatype. Oracle’s manual has “datatype” but IBM’s doesn’t and Microsoft’s doesn’t, and it’s not in the standard.
Not domain. C.J.Date (Date on Database, Writings 2000-2006) says
I observe that some people don’t understand even yet that domains and types are the same thing. The SQL standard muddies the water, too, because it used the term DOMAIN to mean something else …”
From your perspective the implication should be: you can’t use domain as a synonym because users of SQL products will think you mean something else.
Not class. Although some people uses class and type interchangeably, class can also mean a set of objects (rather than just a set of values), so it’s a less precise term.
What does the standard say
Move now to what’s in the SQL:2011 standard document. We find:
A data type is a set of representable values. Every representable value belongs to at least one data type and some belong to several data types.
This is restating the common definition — “a data type is a set of values” — without significant limitations. By saying “representable”, the standard seems to be merely accepting that a DBMS shouldn’t include what it can’t store or display. By saying “several data types”, it’s acknowledging that the value denoted by the literal 9999 could fit in either INTEGER or SMALLINT.
Does a data type include length, character set, etc.?
Suppose the definition of a column is
COLUMN_NAME CHARACTER(32)
Is the data type CHARACTER, or is the data type CHARACTER(32)?
This is a difficult question. The best answer I can give, which I’ll claim is what the SQL:2011 standard would say if it could, is: “CHARACTER(32)”.
Yes the name of the data type is CHARACTER. The standard only defines a small set of data type names — CHARACTER, CHARACTER VARYING, CHARACTER LARGE OBJECT, BINARY, BINARY VARYING, BINARY LARGE OBJECT, NUMERIC, DECIMAL, SMALLINT, INTEGER, BIGINT, FLOAT, REAL, DOUBLE PRECISION, BOOLEAN, DATE, TIME, TIMESTAMP, INTERVAL — and of course “CHARACTER” is on that list but “CHARACTER(32)” is not, it is not a name.
On the other hand — and I think the standard’s vocabulary choice is unfortunate — the data type’s name does not identify the data type! The data type is actually identified by a “data type descriptor” which is defined with the entire <data type> clause, and which, as well as name, includes precision, character set, etc.
That is not explicitly stated, so I’ll support the interpretation with several quotes which show that it’s implicit.
“A data type is predefined even though the user is required (or allowed) to provide certain parameters when specifying it (for example the precision of a number).”
“Two data types,T1 and T2, are said to be compatible if T1 is assignable to T2,T2 is assignable to T1, and their descriptors include the same data type name.”
“The data types “CHARACTER(n) CHARACTER SET CS1” and “CHARACTER(m) CHARACTER SET CS2”,where CS1 ≠ CS2, have descriptors that include the same data type name (CHARACTER), but are not mutually assignable”
“If a <data type> is specified, then let [the data type of a domain] be the data type identified by <data type>.”
“If <data type> is specified, then [the declared type of the column] is that data type.”
“If the maximum length of the subject data type is fixed [then default literals shall not be too long].”
“All data types in [destination strings] shall be character string, and all of them shall have the same character repertoire.”
“[If the result of an operation is] not exactly representable with the precision and scale of the result data type [then it’s an error].”
“A site declared with a character string type may be specified as having a collation, which is treated as part of its data type.”
… I quote them merely for the sake of showing that length and character set and repertoire are all part of data type, and that the <data type> clause is what specifies or identifies the data type, and that two different data types can both have the same data type name.
This does not mean that CHARACTER(32) is a subtype of CHARACTER, because the standard is clear that predefined data types cannot have subtypes or supertypes. (User-defined types can have subtypes or supertypes; however, for user-defined types questions like “is the data type character(32)?” don’t arise.)
This does not mean that saying “the data type is CHARACTER” is wrong, because, whenever we’re talking abstractly or generally, that’s appropriate.
It does mean that “data type is CHARACTER(32)” is much more correct when the definition is known.
What about funny-looking values?
If a data type is supposed to be a set of values, but NULLs are allowed, then what is the set?
Taking the line that NULL represents UNKNOWN, and using MySQL/MariaDB limits for SMALLINT, we could say that the set is {-32768, -32767, -32766, … 0, …, +32767} — NULL is somewhere in that enumeration, we just don’t happen to know where. But NULL could mean other things besides UNKNOWN, and sometimes it definitely does — think of ROLLUP. The standard just says “Every data type has a special value, called the
If the limits of the floating-point sets are supposed to be “based on the IEEE standard”, as the MySQL manual says they are, then where are NaN (not a number) and INF (pseudo-infinity)?
This has been the subject of feature requests like Bug#57519 Documentation for IEEE 754 compliance is missing from Daniël van Eeden, and Bug#41442 Support ieee754 by supporting INF and NaN from Mark Callaghan.
Bug#41442, incidentally, says “the SQL spec doesn’t allow [INF and NaN]”. I’d put it less severely — the standard effectively disallows them for all the standard predefined numeric data types including FLOAT or DOUBLE PRECISION (for example it says that an approximate-numeric literal must have the form <mantissa>E<exponent>). The standard does not forbid new implementation-defined data types.
Other specific effects on our favourite DBMSs
As for “what is a data type in MySQL (or by extension in MariaDB)?”, the
correct answer is: whatever the MySQL or MariaDB documentation says. There used to be arguments about this, but I think they’re all in the past now.
Equally, there’s no point arguing about how TINYBLOB etc. should have been specified in terms of maximum length or precision, or about how ENUM should have been a [VAR]CHAR plus a constraint. The more feasible feature request would be along the lines of: more complete support for the standard types.