Category: MySQL / MariaDB
Roles Review
A role is a bundle of GRANTed privileges which can be assigned to users or which can take the place of users. When there are hundreds or thousands of users, administration becomes a horrible burden if the DBMS doesn’t support roles. Our online ANSI-standard book has syntax descriptions. Other DBMSs do support roles, and MySQL has had a worklog task “WL#988 Roles” for many years. Earlier attempts to implement them included a Google Summer of Code project and a MySQL tool released by Google.
Now another google-summer-coder, Vicențiu Ciorbaru, has put together something which will be in MariaDB. MariaDB’s official blog says this is “a big thing”. I’ll compare the MySQL specification to the MariaDB feature.
Unfortunately Oracle made WL#988 Roles a hidden task about a year and a half ago — you can’t find it by looking on dev.mysql.com/worklog. Fortunately the Wayback Machine had crawled the page in 2012 — you can find it by looking on http://web.archive.org/web/20120508072213/http://forge.mysql.com/worklog/task.php?id=988. Remember that worklog pages are tabbed, and you must click the “High Level Architecture” button to see most of the specification.
I’m using MariaDB 10.0.8 built from source. This is an early version and changes will happen before General Availability happens. Although MariaDB has its own worklog task which I’ll refer to as MDEV-4397, I prefer WL#988 for obvious reasons. For this review I’ll use the same order and same section names as WL#988 high-level architecture. It will be hard to follow unless you read WL#988 first.
CREATE ROLE
“CREATE ROLE role_1;” works. Good.
“CREATE ROLE IF NOT EXISTS role_2;” does not work. I’m ambivalent about this. I don’t like the IF NOT EXISTS clause myself, but I thought it was the way of the future, according to another MySQL Worklog task, WL#3129 Consistent clauses in CREATE and DROP.
Here’s the first bug: I get a crash if I use a bad name:
MariaDB [test]> CREATE ROLE ``; ERROR 2013 (HY000): Lost connection to MySQL server during query
Notes about role names
MariaDB allows role names to be wildcards or privilege names, for example
MariaDB [test]> CREATE ROLE super; Query OK, 0 rows affected (0.00 sec) MariaDB [d]> create role '%'; Query OK, 0 rows affected (0.00 sec)
I regard that as a flaw. Somewhere, ages hence, somebody will get confused because these names have special meanings.
DROP ROLE
“DROP ROLE role_1;” works. Good.
“DROP ROLE IF EXISTS role_1;” does not work. Once again I’m ambivalent. WL#988 specifies that a NOT EXISTS clause should be permissible. On the other hand, “DROP USER IF EXISTS u;” doesn’t work either.
DROP ROLE does not take effect immediately. If a user has enabled role_x, then that user continues to have the privileges of role_x even after role_x is dropped. I regard that as a flaw. [UPDATE: it’s normal, see the comments.]
Here’s the second bug: DROP USER crashes if I specify a role name:
MariaDB [test]> CREATE ROLE role_55; Query OK, 0 rows affected (0.00 sec) MariaDB [test]> DROP USER role_55; ERROR 2013 (HY000): Lost connection to MySQL server during query
GRANT privilege TO role_name
“GRANT SELECT ON t TO role_1;” works. Good.
“GRANT PROXY ON a TO role_1;” works too. I’m ambivalent yet again. As WL#988 says, it’s meaningless to grant a privilege to a role if it only can affect a user. There will always be an argument between people who think this must mean the user is making a mistake, and people who think it doesn’t do any harm.
The privilege change does not take effect immediately. Consider what WL#988 says:
“The privilege change takes effect for the next statement that any affected user executes. (A user is affected if he/she has an enabled role that is affected by the privilege change.)
That seems reasonable — after all, if I say “GRANT … TO user_x” then user_x gets the privilege immediately. But it doesn’t happen for roles. If I say “GRANT … TO role_x”, then role_x gets the privilege — but users who have enabled role_x do not. I regard this as a flaw. [UPDATE: my test was bad, I was not granting the same type of privilege to both the role and the user, see the comments.]
Here’s the third bug: if a user and a role have the same name, GRANT only works on the role. If I say
CREATE USER u_1; CREATE ROLE u_1; GRANT INSERT ON *.* TO u_1; SELECT host,user,insert_priv,is_role FROM mysql.user WHERE mysql.user.user='u_1';
I’d expect that INSERT would be granted to both the user and the role. It’s not, it’s granted only to the role. Moral: users and roles should not have the same names!
GRANT role_name TO user_name
“GRANT role_1 TO user_1;” works. Good. “GRANT role_1 ON *.* TO user_1;” would be good too but an [ON *.*] clause should never be necessary.
“GRANT role_1 TO user_1 WITH GRANT OPTION;” does not work. I’m ambivalent yet again. What we actually have is an ability to say “GRANT role_1 TO user_1 WITH ADMIN OPTION;” and that’s okay (WITH ADMIN OPTION is a standard clause), but I’m not sure it’s a good idea that it’s the default.
“GRANT role_1, role_2 to user_1;” does not work. I regard this as a flaw, but it might have been tough to implement. (UPDATE: 2016-03-20: It is indeed tough to implement. Two months after this blog comment was made, since the manual said that it would work, this flaw was reported as a bug: MDEV-5772 Granting multiple roles in single statement does not work. But two years later it was still unresolved.)
Who has GRANT role_name privileges?
As WL#988 puts it:
Some People will say that, if Peter said CREATE ROLE Role1, Peter should automatically have GRANT Role1 privilege. The analogy is with the way that we grant for routines. This is what would happen with Oracle.
Other People will say that, no, the only way for Peter to get GRANT Role1 privileges is if somebody grants to Peter. The analogy is with the way that we grant for tables.
The implementer decided to follow the advice of Some People for this one. Good.
GRANT role_name TO role_name
“GRANT role_1 TO role_2;” works. Good.
“GRANT role_1 TO role_1;” does not work — and that’s good too. This is a special instance of what WL#988 calls a “cyclical GRANT”. Nobody would want that.
GRANT CREATE / ALTER / DROP ROLE
“GRANT CREATE ROLE …” does not work. I regard that as a flaw.
WL#988 has quite a bit of verbiage about how there has to be a CREATE ROLE privilege, and why. MariaDB sidesteps — the decision was that all you need is a CREATE USER privilege. Although I cannot think of a way that this could lead to security breaches, I am fairly sure that cases exist where administrators who want to allow user-creation do not want to allow role-creation, and vice versa.
REVOKE
“REVOKE role_1 FROM user_1;” works. Good.
SET ROLE
“SET ROLE role_1;” works. And it only works if somebody previously said “GRANT role_1 TO user_1;” for the user that’s doing the SET ROLE. Good.
“SET role ‘role_1′;” works, that is, the role name can be a string literal. But “SET @x=’role_1’; SET ROLE @x;” does not work. I regard that as a flaw because it’s a lack-of-orthogonality thing. By that I mean: if a string literal is okay in a certain place in an SQL statement, then The User On The Clapham Omnibus will expect that a string variable would be okay in the same place.
“SET ROLE role_1,role_2;” does not work. That’s because MariaDB, unlike Oracle, doesn’t allow assignment of multiple roles. And that’s what WL#988 asks for, so no complaints here.
SET ROLE DEFAULT does not work. I regard that as a flaw. Yes, I recognize there is no non-null default, but that just means that SET ROLE DEFAULT should have the same effect as SET ROLE NONE.
Big Example
The big example didn’t work due to incompatible syntax, but I see that there is some evidence that testing has been done. Good.
CURRENT_ROLE
“SELECT CURRENT_ROLE;” works. Good. As expected, it’s possible to find out what the last “SET ROLE” statement did.
“SELECT CURRENT_ROLE();” also works. I regard this as a flaw but I suppose it was inevitable. After all, “SELECT CURRENT_USER();” works.
CURRENT_ROLE is not on the current reserved words list and this will cause a minor incompatibility with MySQL.
ALTER ROLE
“ALTER ROLE role_1 …” does not work. Good.
ALTER ROLE exists in Oracle for changing the IDENTIFIED BY clause, but MariaDB doesn’t support the IDENTIFIED BY clause, so ALTER ROLE would have nothing to do.
RENAME ROLE
“RENAME ROLE role_1 TO role_2;” does not work. Good.
Although “RENAME USER user_1 TO user_2;” works, WL#988 reminds us that renaming a role is going to have cascading effects that wouldn’t exist for renaming a user.
SHOW PRIVILEGES
“SHOW PRIVILEGES;” is the same as it used to be. Good.
Since MariaDB doesn’t have a CREATE ROLE privilege, it doesn’t have to list it.
SET DEFAULT ROLE
“SET DEFAULT ROLE role_1 TO user_1;” does not work. I regard this as a flaw.
It’s a good thing if, when user_1 connects, user_1 automatically gets the privileges associated with a default role. It’s less good if user_1 has to do her own SET ROLE whenever she connects, probably with mysql –init_command=’SET ROLE role_1′. The point of roles was supposed to be the elimination of administrator hassle, and –init-command won’t help there.
The Initial State
The initial state when a user connects is, effectively, SET ROLE NONE. That’ll have to do for now.
SHOW
“SHOW GRANTS FOR user_1;” works and shows roles too. Good.
“SHOW GRANTS FOR CURRENT_ROLE;” also works. WL#988 failed to suggest this obvious addition, so maybe I should call it: better than good.
INFORMATION_SCHEMA
“SELECT * FROM INFORMATION_SCHEMA.ENABLED_ROLES;” works. Good.
“SELECT * FROM INFORMATION_SCHEMA.APPLICABLE_ROLES;” also works. Also good.
And it does show contained roles. That is, “If role1 is contained in role2, then both roles appear.” However: It only shows the roles that have been granted for the current user, it does not show all roles. I regard that as a flaw.
[UPDATE: In an earlier version of this blog this observation was in the wrong place.] [UPDATE again: I missed what the cause was, the real problem was that I couldn’t grant to public — but that’s another bug. See comments.]
Command line options
“–role=role_name” doesn’t work (on the command line). Good.
The way to go for setting a role name at connect time is to support defaults. Any other “solution” would just get in the way.
For Replication
As WL#988 says, “The plan is to ignore replication till the last minute.” I can’t tell whether MariaDB is following such a plan.
Plan for Backup
Backup is simplified by the fact that users and roles come from the same table in the mysql database. I did not test it, so let’s say: assumed good.
Stored Procedures and Definer Privileges
After “SET ROLE role_1; CREATE PROCEDURE p () SQL SECURITY DEFINER SELECT CURRENT_ROLE; CALL p();” the result is NULL. Good.
The idea is supposed to be that, within an SQL SECURITY DEFINER routine, an implicit SET ROLE NONE takes place temporarily. It’s great that the implementer caught on to this rather obscure point.
Logging in with a Role Name
After “CREATE ROLE ‘role_5@localhost’;” or “CREATE ROLE role_5;” I was not able to log in as role_5. Good.
However, “CREATE DEFINER=role_5 PROCEDURE p2() SET @x=5;” works. I regard that as a flaw. There should at least be a warning that the DEFINER clause is being used with a nonexistent user. I get the impression from MDEV-4397 that this is deliberate behaviour, so don’t expect a fix.
DML statements and role privileges
The Oracle-style restriction for CREATE VIEW isn’t there. Good.
Other worklog tasks affected by roles
Well, WL#988 anticipated that roles would come first, and pluggable authentication support would come later. It didn’t happen that way. No problem.
Glossary
It doesn’t seem that the terminology differs from what’s expected. Good.
New columns in mysql.user
When I say “CREATE ROLE role_1;” the effect is that a new row goes into the mysql.user table. The mysql.user table definition had to be adjusted to take that into account. But I don’t think it’s all good.
WL#988 expected that the length of a role name would be 16 characters, but mysql.user.user is now CHAR(80). Well, that was a flaw, but just an old bug that wasn’t caused by introduction of roles.
The mysql.user.host column is blank (”). I’d expected it would be ‘%’. I suppose that this was intended as a way to disambiguate users and roles that had the same names, but that’s not working well anyway. The column should be ‘%’ because that means “any or all hosts”.
There is one new column at the end, named is_role, which can be ‘Y’ or ‘N’. I regard that as a flaw. The future-considerations way would have been to add a new column named user_type, which could be NULL or ‘Role’ — or something else that somebody will dream up in a future release. The way it is now, if somebody dreams up another type later, they’ll have to add yet another column in mysql.user.
Storing role names
The implementer picked “Alternative #2: (loosely based on a suggestion from Monty Widenius)”. So there’s a new table in the mysql database:
CREATE TABLE mysql.roles_mapping (Host CHAR(60), User CHAR(80), Role CHAR(80), Admin_option ENUM(‘N’,’Y’))
… And it works. Good. Although ROLE was a reserved word in SQL-99, and although WL#988 suggested an additional column and different names, it works.
However, storing the WITH ADMIN OPTION value should only be in one place and that place is mysql.user, so mysql.roles.mapping should not contain a column named Admin_option. I regard this as a flaw. [UPDATE: not it is not a flaw, see the comments.]
The Decisions about Options
The early decisions of Monty Widenius were: we don’t want passwords, we do want defaults, we don’t want multiple current roles, and PUBLIC should not be a role. That’s what ended up happening, except that there are no defaults. Good.
Overall
For all of the bugs, and for some of the flaws, there’s no worry — they’ll probably disappear. The MariaDB advantage here is the release-early policy, because there’s lots of advance time if there’s a decision to make a few corrections or course changes.
The MariaDB disadvantage is illustrated by its worklog task for roles, MDEV-4397. I’m biased, but I think it’s fair to say that MySQL’s WL#988 “high level architecture” specification covered the necessary ground and MariaDB’s MDEV-4397 did not. This means Oracle made the right decision when it “hid” its worklog task. Too bad it didn’t work out this particular time.
The USA’s healthcare.gov site and LAMP
The USA’s health care exchange site, healthcare.gov, has had well-publicized initial woes.
The New York Times has said one of the problems was the government’s choice of DBMS, namely MarkLogic. A MarkLogic employee has said that “If the exact same processes and analysis were applied to a LAMP stack or an Oracle Exa-stack, the results would have likely been the same.”
I don’t know why he picked Exastack for comparison, but I too have wondered whether things would have been different if the American government had chosen a LAMP component (MySQL or MariaDB) as a DBMS, instead of MarkLogic.
What is MarkLogic?
The company is a software firm founded in 2001 based in San Carlos California. It has 250 employees. The Gartner Magic Quadrant classes it as a “niche player” in the Operational DBMS Category.
The product is a closed-source XML DBMS. The minimum price for a perpetual enterprise license is $32,000 but presumably one would also pay for support, just as one does with MySQL or MariaDB.
There are 250 customers. According to the Wall Street Journal “most of its sales come from dislodging Oracle Corp.”
One of the customers, since 2012 or before, is CMS (the Centers for Medicare and Medicaid), which is a branch of the United States Department of Health and Human Services. CMS is the agency that built the healthcare.gov online portal.
Is MarkLogic responsible for the woes?
Probably MarkLogic is not the bottleneck.
It’s not even the only DBMS that the application queries. There is certainly some contact with other repositories during a get-acquainted process, including Oracle Enterprise Identity management — so one could just as easily blame Oracle.
There are multiple other vendors. USA Today mentions Equifax, Serco, Optum/QSSI, and the main contractor
CGI Federal.
A particular focus for critics has been a web-hosting provider, Verizon Terremark. They have been blamed for some of the difficulties and will eventually be replaced by an HP solution. HP also has a fairly new contract for handling the replication.
Doubtless all the parties would like to blame the other parties, but “the Obama administration has requested that all government officials and contractors involved keep their work confidential”.
It’s clear, though, that the site was launched with insufficient hardware. Originally it was sharing machines with other government services. That’s changed. Now it has dedicated machines.
But the site cost $630 million so one has to suppose they had money to buy hardware in the first place. That suggests that something must have gone awry with the planning, and so it’s credible what a Forbes article is saying, that the government broke every rule of project management.
So we can’t be sure because of the government confidentiality requirement, but it seems unlikely that MarkLogic will get the blame when the dust settles.
Is MarkLogic actually fast?
One way to show that MarkLogic isn’t responsible for slowness, would be to look for independent confirmations of its fastness. The problem with that is MarkLogic’s evaluator-license agreement, from which I quote:
…
MarkLogic grants to You a limited, non-transferable, non-exclusive, internal use license in the United States of America
…
[You must not] disclose, without MarkLogic’s prior written consent, performance or capacity statistics or the results of any benchmark test performed on Software
…
[You must not] use the Product for production activity,
…
You acknowledge that the Software may electronically transmit to MarkLogic summary data relating to use of the Software
— http://developer.marklogic.com/products
These conditions aren’t unheard of in the EULA world, but they do have the effect that I can’t look at the product at all (I’m not in the United States), and others can look at the product but can’t say what they find wrong with it.
So it doesn’t really matter that Facebook got 13 million transactions/second in 2011, or that the HandlerSocket extension for MySQL got 750,000 transactions/second with a lot less hardware. Possibly MarkLogic could do better. And I think we can dismiss the newspaper account that MarkLogic “continued to perform below expectations, according to one person who works in the command center.” Anonymous accounts don’t count.
So we can’t be sure because of the MarkLogic confidentiality requirements, but it seems possible that MarkLogic could outperform its SQL competitors.
Is MarkLogic responsible for absence of High Availability?
High Availability shouldn’t be an issue.
At first glance the reported uptime of the site — 43% initially, 90% now — looks bad. After all, Yves Trudeau surveyed MySQL High Availability solutions years ago and found even the laggards were doing 98%. Later the OpenQuery folks reported that some customers find “five nines” (99.999%) is too fussily precise so let’s just round it to a hundred.
At second glance, though, the reported uptime of the site is okay.
First: The product only has to work in 36 American states and Hawaii is not one of them. That’s only five time zones, then. So it can go down a few hours per night for scheduled maintenance. And uptime “exclusive of scheduled maintenance” is actually 95%.
Second: It’s okay to have debugging code and extra monitoring going on during the first few months. I’m not saying that’s what’s happening — indeed the fact that they didn’t do a 500-simulated-sites test until late September suggests they aren’t worry warts — but it is what others would have done, and therefore others would also be below 99% at this stage of the game.
So, without saying that 90 is the new 99, I think we can admit that it wouldn’t really be fair to make a big deal about some LAMP installation that has higher availability than healthcare.gov.
Is it hard to use?
MarkLogic is an XML DBMS. So its principal query language is XQuery, although there’s a section in the manual about how you could use SQL in a limited way.
Well, of course, to me and to most readers of this blog, XQuery is murky gibberish and SQL is kindergartenly obvious. But we have to suppose that there are XML experts who would find the opposite.
What, then, can we make out of the New York Times’s principal finding about the DBMS? It says:
“Another sore point was the Medicare agency’s decision to use database software, from a company called MarkLogic, that managed the data differently from systems by companies like IBM, Microsoft and Oracle. CGI officials argued that it would slow work because it was too unfamiliar. Government officials disagreed, and its configuration remains a serious problem.”
— New York Times November 23 2013
Well, of course, to me and to most readers of this blog, the CGI officials were right because it really is unfamiliar — they obviously had people with experience in IBM DB2, Microsoft SQL Server, or Oracle (either Oracle 12c or Oracle MySQL). But we have to suppose that there are XML experts who would find the opposite.
And, though I think it’s a bit extreme, we have to allow that it’s possible the problems were due to sabotage by Oracle DBAs.
Yet again, it’s impossible to prove that MarkLogic is at fault, because we’re all starting off with biases.
Did the problem have something to do with IDs?
I suspect there was an issue with IDs (identifications).
It starts off with this observation of a MarkLogic feature: “Instead of storing strings as sequences of characters, each string gets stored as a sequence of numeric token IDs. The original string can be reconstructed using the dictionary as a lookup table.”
It ends with this observation from an email written on September 27 2013 by a healthcare.gov worker: “The generation of identifiers within MarkLogic was inefficient. This was fixed and verified as part of the 500 user test.”
Of course that’s nice to see it was fixed, but isn’t it disturbing that a major structural piece was inefficient as late as September?
Hard to say. Too little detail. So the search for a smoking gun has so far led nowhere.
Is it less reliable?
Various stories — though none from the principals — suggest that MarkLogic was chosen because of its flexibility. Uh-oh.
The reported quality problems are “one in 10 enrollments through HealthCare.gov aren’t accurately being transmitted” and “duplicate files, lack of a file or a file with mistaken data, such as a child being listed as a spouse.”
I don’t see how the spousal problem could have been technical, but the duplications and the gone-missings point to: uh-oh, lack of strong rules about what can go in. And of course strong rules are something that the “relational” fuddy-duddies have worried about for decades. If the selling point of MarkLogic is in fact leading to a situation which is less than acceptable, then we have found a flaw at last. In fact it would suggest that the main complaints so far have been trivia.
This is the only matter that I think looks significant at this stage.
How’s that hopey-changey stuff working out for your Database?
The expectation of an Obama aide was: “a consumer experience unmatched by anything in government, but also in the private sector.”
The result is: so far not a failure, and nothing that shows that MarkLogic will be primarily responsible if it is a failure.
However: most of the defence is along the lines of “we can’t be sure”. That cuts both ways — nobody can say it’s “likely” that LAMP would have been just as bad.
TokuDB Features
Many people have tested whether the TokuDB storage engine runs faster and compresses better than the default storage engine, InnoDB. I am more concerned about TokuDB’s features. Or, to put it unfairly: can it do everything that InnoDB can do, in a current version?
Vadim Tkachenko of Percona supplied a binary download for a platform that I happen to have (Ubuntu 12.04), so I got MySQL 5.6 + TokuDB 7.1 up and running within 15 minutes. Then I found that I could not break anything within 60 minutes. I I conclude that “ease of use” and “stability” are okay. (For anyone who thinks I’m rushing: yes, but usually finding a bug in a new version takes less than an hour so I’m judging from experience.)
Almost everything = No problem
I tried compound indexes, long strings, the relatively-new TIMESTAMP(6) data type with fractional seconds, utf8mb4 varchar columns with German collation, transaction rollbacks with or without savepoints, crash recovery, and partitions.
I always got the same results as I get with InnoDB. It seems that the Tokutek folks looked at compatibility before declaring that their product is a “drop-in replacement storage engine for MySQL and MariaDB”.
Foreign keys
These statements didn’t cause an error but the FOREIGN KEY clause was ignored:
CREATE TABLE tp (s1 INT, PRIMARY KEY (s1)) engine=tokudb; CREATE TABLE tf (s1 INT, FOREIGN KEY (s1) REFERENCES tp (s1)) engine=tokudb;
If I use InnoDB, the statements succeed. In basic English, TokuDB doesn’t support referential integrity.
This is a big deal because foreign keys are part of “core” standard SQL. In mitigation, I have to allow that many users eschew foreign keys in this benighted sharded world, and that in theory one could replace some foreign-key functionality with triggers. But I doubt that anybody ever does.
Full text
These statements resulted in an error:
CREATE TABLE tq (s1 TEXT) engine=tokudb; CREATE FULLTEXT INDEX iq ON tq (s1);
If I use InnoDB, the statements succeed, because InnoDB (since version 5.6.4) supports full-text indexing, TokuDB doesn’t.
I’m sure I could hear objections like “that’s not what TokuDB is for” (true), “InnoDB’s implementation is bad” (actually that’s my own opinion but I’m sure somebody somewhere shares it), or “use Sphinx” (I don’t understand the logic here but I heard it when I complained about a full-text deficiency in another product).
To refute all objections, I went to bugs.mysql.com, clicked “Return only bugs with status = ALL”, clicked “Show = ALL”, clicked “Restrict to bugs in selected categories = MySQL Server: FULLTEXT search”, and clicked “Search”. I got 107 hits So full text must be important to somebody, else they wouldn’t report bugs.
Isolation
I started two connections, both with autocommit = 0 and default transaction isolation = REPEATABLE READ. On the first connection I said
CREATE TABLE t2 (s1 INT, UNIQUE(s1)) engine=tokudb; INSERT INTO t2 VALUES (0);
On the second connection I said:
INSERT INTO t2 VALUES (1);
Result: ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction.
If I use engine=innodb, I do not see this error, both INSERTs work.
I also see that there’s a documented behaviour difference with SELECT FOR UPDATE.
I conclude that TokuDB’s different locking methods mean that some SQL statements will have different effects in multi-user environments, if one switches from InnoDB.
Names
A storage engine maker cannot muck with MySQL’s syntax, with two exceptions: (1) this rule doesn’t apply to InnoDB; (2) new variables or information_schema tables can be added that are specific to tuning or monitoring.
So I said “SHOW VARIABLES LIKE ‘tokudb%'” … and I did see some things that bothered me. For example:
() tokudb_lock_timeout seems to be something like innodb_lock_wait_timeout so it’s unfortunate that they didn’t call it tokudb_lock_wait_timeout
() tokudb_commit_sync seems to do some things like innodb_flush_log_at_trx_commit so it’s unfortunate that they didn’t use the same numbers
() tokudb_fs_reserve_percent? well, I couldn’t tell if it’s unfortunate or not because I couldn’t find it in the TokuDB user manual.
Platforms
Tokutek’s FAQ says that TokuDB was tested on Centos 5 and CentOS 6. Doubtless it also works on all other Linux 64-bit distros (I downloaded for Ubuntu 12.04 and the MariaDB manual mentions Fedora). I see that Antony Curtis got it going on his Macbook.
That leaves three major items from the list of platforms that MySQL supports: FreeBSD, Solaris, and Windows. The trouble is that one of them, Windows, is what beginners or students might start with. As a result, MySQL + InnoDB or MariaDB + InnoDB will remain the default choice for introductory texts and some personal uses.
I can’t see how this will change, since there’s no money in the entry-level market and there’s no point in a “Windows server” for Tokutek’s real objective, which is to capture a piece of the must-have-performance market. But if they don’t care, the mind share won’t be there.
You’re forearmed
I fear that, by concentrating on TokuDB’s performance advantages, people have failed to worry about losing features that are available with InnoDB. Even if you conclude that you want to use TokuDB — especially if you conclude that you want to use TokuDB — you should be aware of them.
The UTF-8 world is not enough
In English there are very few words of Japanese origin but I think this one has a great future: mojibake. Mojibake is the garbage you see when MySQL or MariaDB has a column definition saying character set A, stores into it a string that’s actually in character set B, then ships it to a client which expects everything to be in character set C.
For some DBMSs (Drizzle and NuoDB spring to mind) it’s apparent that the developers decided that users could avoid mojibake, and developers could avoid a lot of extra trouble, if everybody had the same character set: UTF-8. Well, MySQL and MariaDB have web users and UTF-8 is popular on the web. According to Web Technology Surveys, 80% of web sites use UTF-8. There’s a Google study that came to a vaguely similar conclusion.
And yet, and yet, the arguments are devastating for why should MySQL or MariaDB continue to support character sets other than UTF-8, and even add one or two more.
Space
With a Greek character set like 8859-7, it takes one (1) byte to store one ordinary Greek character. With UTF-8 it takes two (2) bytes to store one ordinary Greek character. So 8859-7 is 50% cheaper for Greek words, and the same ratio holds for other 8-bit non-Latin language-specific character sets like Bulgarian.
With a multi-byte character set like euckr (for Korean) things get more complicated and results will vary. I took the lead paragraph for the Korean Wikipedia article on Seoul, dumped the contents into columns with different character set definitions, and compared the sizes with the octet_length() function:
utf8 1260 /* worst */ utf16 1138 /* middle */ euckr 916 /* best */
Unsurprisingly, it takes fewer bytes to store Korean text with a “made-in-Korea” character set. Also it’s a bit cheaper to use utf16 (which always requires two bytes per character for ordinary Korean words), which is doubtless one reason that the SQL Server folks prefer UTF-16 over UTF-8. I of course will ignore any objections that space doesn’t matter, or that compression algorithms exist.
Conversion trouble
It is true that Unicode’s repertoire is a superset of what’s in Japanese character sets like sjis or ujis. But that does not mean that you can start with sjis text, convert to Unicode, then convert back to sjis. On some rare occasions such a “round trip” will fail. This happens because the mapping is not always one-to-one. But it also happens because there are slight differences between various versions of sjis — that’s a fact which causes no difficulty if there’s no conversion, but causes some difficulty if something comes in from the client as sjis, gets converted to Unicode for storage, then gets converted back to sjis when the server retrieves something for the client.
Legacy
At the start of this post I mentioned that 80% of web sites use UTF-8. However, that is the world-wide figure. For a language-specific look, here are two sobering statistics:
* Only 54% of Chinese-language web sites predominantly use UTF-8 * Only 60% of Japanese-language web sites predominantly use UTF-8 Source: Web Technology Surveys
Hunting for examples, I went to the alexa.com page for “Top Sites in China”, then on my Firefox browser I clicked Tools > Page Info: Encoding. Five of the top ten said their encoding was UTF-8, but the other five said their encoding was GBK. This is not a reliable test because the site owner could be fibbing. But even if only a few are telling the truth, it’s clear there are many holdouts in the Non-UTF-8 crannies.
Of course for all of these arguments there are counter-arguments or even possible refutations. But they wouldn’t matter to the DBMS vendor. The vendor is supposed to help the customer with the customer’s plan, rather than explain that they should do something which, with suspicious convenience, would make the vendor’s life easier.
I had a look at the open-source SQL DBMSs, and as far as I could tell only five support both storage and input with a variety of encodings: MySQL and MariaDB of course, but also PostgreSQL, Ingres, and Firebird.
VoltDB definitely cannot. The Java-based ones apparently cannot, but I didn’t make certain.
Regular (RLIKE and REGEXP) expressions: Good News
Ten years ago, MySQL got a “bug report” about trouble with RLIKE. It got marked “won’t fix” because MySQL used a regular-expression library that couldn’t handle non-ASCII characters reliably. Over time there were multiple similar or duplicate bug reports but the only result was a note in the MySQL manual saying, in effect, “tough luck”. Until now.
Actually the fix is in a pre-release of the bzr branch for MariaDB 10.0.5, and I can’t predict that the MySQL folks will copy it, but it looks good to me, and I clap for the original coders who made the “Perl Compatible Regular Expressions” library, the “Google Summer of Code” folks who pay students to help with open source projects, the student coder in question — Sudheera Palihakkara from a Sri Lanka university — and finally Alexander Barkov from the MariaDB foundation.
So what were the problems and what’s been solved — or not solved?
Solved: Handling any characters
Most of the complaints about REGEXP have been about handling of accented Latin characters, Cyrillic characters, or, in short: regardless of character set or collation, if any character in the pattern was outside the ASCII range or was NUL, then there would be false hits, no hits, miscalculated lengths, or failed case conversions. I took examples from the “how to repeat” section of those bug reports, and tried them with MariaDB 10.0.5. Results:
/* Bug#34473 */
MariaDB [test]> SELECT 'Ørneborgen' RLIKE '^[Ö]';
+-----------------------------+
| 'Ørneborgen' RLIKE '^[Ö]' |
+-----------------------------+
| 0 |
+-----------------------------+
1 row in set (0.03 sec)
/* Bug#54576 */
MariaDB [test]> SELECT 'č' REGEXP '^.$';
+-------------------+
| 'č' REGEXP '^.$' |
+-------------------+
| 1 |
+-------------------+
1 row in set (0.00 sec)
/* Bug#52080 */
MariaDB [test]> SELECT 'Я' regexp 'я';
+------------------+
| 'Я' regexp 'я' |
+------------------+
| 1 |
+------------------+
1 row in set (0.02 sec)
/* Bug#63439 */
MariaDB [test]> SELECT 'ääliö' REGEXP '^[aä]{1}[aä]{1}li[oö]{1}$';
+--------------------------------------------------+
| 'ääliö' REGEXP '^[aä]{1}[aä]{1}li[oö]{1}$' |
+--------------------------------------------------+
| 1 |
+--------------------------------------------------+
1 row in set (0.03 sec)
/* Bug#70470 */
MariaDB [test]> SELECT 'abc\0def' REGEXP 'def';
+-------------------------+
| 'abc\0def' REGEXP 'def' |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
All the above answers are correct, for the first time ever.
In fact one could say that the new REGEXP handles too many characters. It’s adjusted for Unicode 6.2, a version that neither MySQL nor MariaDB support yet. This will of course be of concern to those who use the Meroitic alphabet, but they’re a fading minority.
Not solved: incompatibilities
I guess it was inevitable that, since there’s a different underlying library, the text of some error messages would change. For example I get this:
MariaDB [test]> select '1' rlike rpad('1',100,'(');
ERROR 1139 (42000): Got error 'missing ) at offset 100' from regexp
and that’s okay, but in MySQL 5.6.14 the error message is:
“ERROR 1139 (42000): Got error ‘parentheses not balanced’ from regexp”.
A bit more interesting is this query:
/* Bug#68153 */ MariaDB [test]> SELECT CHAR(126) REGEXP '[[.tilde.]]'; ERROR 1139 (42000): Got error 'POSIX collating elements are not supported at offset 1' from regexp
and that looks a little less okay. In MySQL 5.6.14 the same search condition doesn’t cause an error, it’s considered to be “true”.
Solved: Handling more Posix
The MariaDB folks have proudly announced that version 10.0.5 supports “recursive patterns, named capture, look-ahead and look-behind assertions, non-capturing groups, non-greedy quantifiers”. To which I’m sure that the response will be: What? How shocking that non-greedy quantifiers weren’t added ten years ago!
Well, maybe not. But when looking at new features, it’s wrong to ask merely whether there’s some advantage for the non-greedy man on the Clapham omnibus. The point is it’s supposed to be more compatible with modern Perl programs, with Posix, and with all the box-tickers who will ask: do you really support regular expressions? And if someday I reach that pinnacle of ambition, to figure out grep, then I’ll doubtless appreciate look-behind assertions in the way they deserve to be appreciated.
Unsolved: handling more standard SQL
In the operetta Die Fledermaus there’s a refrain: “Happy is the one who forgets what isn’t going to be changed”. But I, alas, can’t forget the comment that I wrote on Bug#746 ten years ago, showing there are at least six behavioural differences between REGEXP and the optional-SQL-standard operator, SIMILAR TO. The incompatibilities arise because SIMILAR TO works like LIKE, so it’s more SQL-ish, and less Posix-ish. Thus, improvements in REGEXP alone are not an advance towards more standard SQL. This would matter more if there were many other SQL implementations supporting SIMILAR TO. The only ones I know of are PostgreSQL and Firebird.
Triggers: Comparisons, New Features, and a Trick
I’ll show a chart which indicates the level of support for trigger features in major open-source DBMSs.
I’ll comment on new features in MySQL 5.7.
I’ll show how triggers can be used to abort statements which are taking too long.
Trigger features in major open-source DBMSs
| Feature | Firebird | Ingres | MySQL+MariaDB | PostgreSQL |
|---|---|---|---|---|
| Any compound statement | YES | – | YES | – |
| Alter | YES | – | – | – |
| Disable | YES | – | – | YES |
| For each statement | – | YES | – | YES |
| For each row | YES | YES | YES | YES |
| One trigger, multiple trigger events | YES | YES | – | YES |
| Multiple triggers for same situation | YES | – | YES | |
| Views’ “instead of” clause | – | – | – | YES |
| Deferrable | – | – | – | YES |
| Normally standardish syntax | YES | – | YES | YES |
| “New” and “Old” variables | YES | YES | YES | YES |
| “When” clause or equivalent | – | YES | – | YES |
Explanation of each column:
“Any compound statement”:
“YES” if trigger body can be something like BEGIN statement1;statement2; … END.
“-” if trigger body an only be something like a single CALL statement.
“Alter”:
“YES” if ALTER TRIGGER is legal and can do something significant (more than renaming). Non-standard.
“-” if the normal way to change a trigger is to drop and create again.
“Disable”:
“YES” if there is a persistent way to make a trigger inactive or disabled. Non-standard.
“-” if the normal way to disable a trigger is to drop it or add an IF clause.
“For each statement”:
“YES” if checking happens before/after rest of statement processing
“-” if checking is only for each row
“For each row”:
“YES” if checking happens before/after rest of row processing
“-” if checking is only for each statement
“One trigger, multiple trigger events”:
“YES” if clauses like “BEFORE INSERT OR UPDATE OR DELETE” are possible. Non-standard.
“-” if clause can only contain one verb (no OR allowed)
“Multiple triggers for same situation”:
“YES” if there can be (for example) two BEFORE UPDATE triggers on table t.
“-” if only one trigger is possible for the same action at the same time.
Views’ “instead of” clause:
“YES” if INSTEAD OF triggers are possible (usually for views only)
“-” if the only trigger action times are BEFORE and AFTER
“Deferrable”:
“YES” if it’s possible to defer “after” checking until end of transaction. Non-standard.
“-” if all checking is during statement execution
“Normally standardish syntax”:
“YES” if normal CREATE TRIGGER syntax is reminiscent of standard syntax
“-” if normal/recommended syntax is CREATE RULE, or normal body is EXECUTE clause.
“New” and “Old” variables:
“YES” if a trigger can use NEW.column_name and/or OLD.column_name
“-” if column values are invisible during trigger execution
“When” clause or equivalent:
“YES” if syntax is CREATE TRIGGER … [WHEN condition] …;
“-” if condition has to be in an IF statement in the trigger body
Information for this chart comes from the documentation for Firebird 1.5, Ingres 10.0, MySQL 5.6, and PostgreSQL 9.3.
Two New Features In MySQL 5.7
The first enhancement is that it is possible to say
CREATE TABLE t (s1 INT NOT NULL)//
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
IF new.s1 IS NULL THEN SET new.s1=0; END IF;
END//
INSERT INTO t VALUES (NULL)//
That is, NOT NULL no longer stops the INSERT if the trigger was going to change the value to non-null anyway. This was a long-standing feature request, and I doubt that anyone will complain.
The second enhancement is WL#3253: Triggers: multiple triggers per table.
In 5.6, if there are two actions to trigger, one must put them both in one trigger:
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement1
statement2
END
In 5.7 one can put them in two triggers:
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement1
END
CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement2
END
This is unnecessary for a DBMS like MySQL that supports compound statements for triggers, but it’s in the standard, and there was at least one feature request for it. The problem with multiple triggers is that there has to be some way to decide which one is activated first, and the standard isn’t helpful here — it says to follow the order of creation, but that’s rigid, and also
unreliable if one depends on CURRENT_TIMESTAMP. PostgreSQL “solved” this by saying the order is the alphabetical order of the trigger names, but then Oracle 11g came along with a syntax that MySQL 5.7 copies:
CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW FOLLOWS t1 ... or CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW PRECEDES t1 ...
“FOLLOWS t1” means “is activated immediately after t1”, and in INFORMATION_SCHEMA.TRIGGERS there is an integer column ACTION_ORDER which reflects this (this column is not new, but in earlier MySQL versions it is always zero).
The feature works, and the worklog task for it has good high-level architecture description. But, once you’ve made trigger t2 follow t1, you’re stuck — there’s still no ALTER TRIGGER. And I think that, even if you know what ACTION_ORDER is, you’ll still get confused. To test that, here is a quiz. After
CREATE TABLE t (s1 CHAR(3));
CREATE TRIGGER t1 BEFORE UPDATE ON t FOR EACH ROW
SET new.s1 = CONCAT(old.s1,'c');
CREATE TRIGGER t2 BEFORE UPDATE ON t FOR EACH ROW PRECEDES t1
SET new.s1 = CONCAT(new.s1,'b');
INSERT INTO t VALUES ('a');
UPDATE t SET s1 = '';
Does s1 contain ‘ab’ or ‘abc’ or ‘acb’ or ‘ac’? Answer at end of post. If you get it wrong, you should continue with the old way and put all actions in a single trigger; however, the coder (apparently Mr Dmitry Shulga) deserves congratulation.
Stopping an update after 10 seconds
Of course the legitimate uses of triggers are (a) to make up for MySQL’s lack of CHECK clauses by producing an error when a NEW value is wrong; (b) to add to a summary in table b whenever there’s a change to table a.
A less tame use — because it is non-deterministic — is aborting a statement if some external condition occurs. The example here is saying, in effect, “If 10 seconds have elapsed since the update began, stop and return an error”. Since the ordinary timers like CURRENT_TIMESTAMP don’t change during a statement, I use SYSDATE.
[ UPDATE: In an earlier version of this article, I used a low-level
counter from PERFORMANCE_SCHEMA. Thanks to Justin Swanhart for suggesting a simpler way. It won’t work if the server was started with –sysdate-is-now, but my original method could also have failed in some circumstances. ]
/* Make a test table with 25 rows. */
CREATE TABLE t (s1 INT);
INSERT INTO t VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),
(11),(12),(13),(14),(15),(16),(17),(18),(19),(20),
(21),(22),(23),(24),(25);
/* Make a trigger so (current time - start time) is checked after
each row update, and SIGNAL if the result is more than 10. */
delimiter //
CREATE TRIGGER abort_after_elapsed_time BEFORE UPDATE ON t FOR EACH ROW
IF TO_SECONDS(SYSDATE()) - @start_time > 10 THEN
SIGNAL SQLSTATE '57005' SET message_text='Timeout';
END IF;//
delimiter ;
/* Set a variable which will contain the current time. */
/* This should be done just before doing the UPDATE. */
SET @start_time = TO_SECONDS(SYSDATE());
/* Do a very slow UPDATE which would take
(25 rows * 1 second per row) if no timeout. */
select current_timestamp;
UPDATE t SET s1 = SLEEP(1);
select current_timestamp;
Example result showing “Timeout” error occurs after about 10 seconds:
MariaDB [test]> select current_timestamp; +---------------------+ | current_timestamp | +---------------------+ | 2013-10-07 12:54:39 | +---------------------+ 1 row in set (0.00 sec) MariaDB [test]> UPDATE t SET s1 = SLEEP(1); ERROR 1644 (57005): Timeout MariaDB [test]> select current_timestamp; +---------------------+ | current_timestamp | +---------------------+ | 2013-10-07 12:54:50 | +---------------------+ 1 row in set (0.00 sec)
Your mileage may vary but by luck it worked this way on my machine. Probably a progress bar would be more interesting, eh? I’ll get back to that theme if I ever finish one.
Answer to quiz question
‘ac’.
Sometimes MySQL is more standards-compliant than PostgreSQL
Here are examples comparing MySQL 5.6 against PostgreSQL 9.3 Core Distribution, where MySQL seems to comply with “standard SQL” more closely than PostgreSQL does. The examples are also true for MariaDB 10.0 so whenever I say “MySQL” I mean “MySQL and/or MariaDB”. When I say “more closely” I do not mean that MySQL is completely compliant, or that PostgreSQL is completely non-compliant.
Identifiers
Example:
CREATE TABLE ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ (s1 INT); /* 32-character name */
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name = 'ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ';
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name LIKE LOWER('Ž%');
Result:
PostgreSQL says count(*) is 0. MySQL says it’s 1.
Reason:
(1) PostgreSQL maximum identifier length is 63 bytes; MySQL maximum identifier length is 64 characters. The standard requirement is 128 characters.
(2) With PostgreSQL, if you insert an invalid value, PostgreSQL truncates — it “tries to make do” rather than failing. (If the name had been too long for MySQL, it would have thrown an error.)
(3) PostgreSQL does not convert to lower case during CREATE, and does a case-sensitive search during SELECT.
Character Sets And Collations
Example:
CREATE TABLE t (s1 CHAR(1) CHARACTER SET utf16);
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support named character sets; it can only handle one character set per database.
Example:
CREATE TABLE t (s1 CHAR(2), s2 VARCHAR(2));
INSERT INTO t VALUES ('y ','y ');
SELECT * FROM t WHERE s1 = 'y';
SELECT * FROM t WHERE s2 = 'y';
Result:
PostgreSQL finds one row for the first SELECT but zero rows for the second SELECT. MySQL finds one row both times.
Reason:
PostgreSQL does not always add spaces to the shorter comparand, or remove spaces from the longer comparand. MySQL is consistent. The behaviour is optional, but it is not supposed to depend on the data type.
Example:
CREATE TABLE t (s1 CHAR(1), uca CHAR(4),utf32 CHAR(6),utf8 CHAR(8),name VARCHAR(50)); INSERT INTO t VALUES (U&'\+003044','3197',' 3044',' E38184','HIRAGANA LETTER I'); INSERT INTO t VALUES (U&'\+003046','3198',' 3046',' E38186','HIRAGANA LETTER U'); INSERT INTO t VALUES (U&'\+0030A4','3197',' 30A4',' E382A4','KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+0030A5','3198',' 30a5',' E382A5','KATAKANA LETTER SMALL U'); INSERT INTO t VALUES (U&'\+00FF72','3197',' FF72',' EFBDB2','HALFWIDTH KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+00042B','1AF1',' 042B',' D0AB','CYRILLIC CAPITAL LETTER YERU'); INSERT INTO t VALUES (U&'\+0004F9','1AF5',' 04F9',' D3B9','CYRILLIC SMALL LETTER YERU WITH DIAERESIS'); INSERT INTO t VALUES (U&'\+0004CF','1B4A',' 04CF',' D38F','CYRILLIC SMALL LETTER PALOCHKA'); INSERT INTO t VALUES (U&'\+002C13','1B61',' 2C13',' E2B093','GLAGOLITIC CAPITAL LETTER RITSI'); INSERT INTO t VALUES (U&'\+0100CC','3872',' 100CC','F090838C','LINEAR B IDEOGRAM B240 WHEELED CHARIOT'); SELECT * FROM t ORDER BY s1 COLLATE "C",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "POSIX",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "C.UTF-8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "en_CA.utf8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "default",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "ucs_basic",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "zh_CN",uca DESC,name;
Result:
With PostgreSQL, no matter which collation one chooses, one does not get a linguistic standard ordering. Here is a typical result:
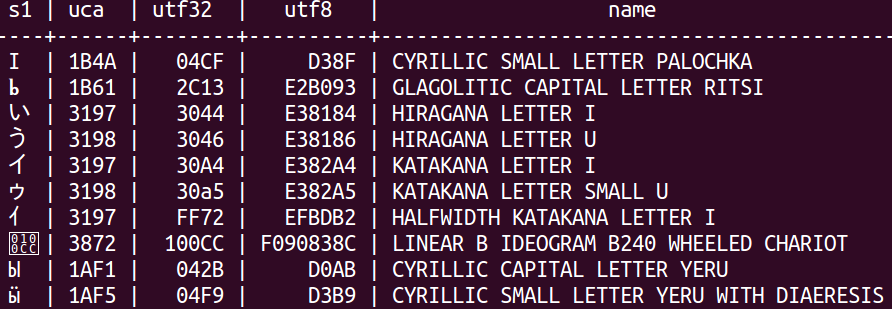
With MySQL, if one enters the same data (albeit in a different way), and chooses collation utf8mb4_unicode_520_ci, one gets a standard result.
Reason:
PostgreSQL depends on the operating system for its collations. In this case my Linux operating system offered me only 5 collations which were really distinct. I did not attempt to customize or add more. I tried all the ones that were supplied, and failed to get a result which would match the Unicode Collation Algorithm order (indicated by the ‘uca’ column in the example). This matters because the standard does ask for a UNICODE collation “in which the ordering is determined by applying the Unicode Collation Algorithm with the Default Unicode Collation Element Table [DUCET]”. MySQL is a cross-platform DBMS and does not depend on the operating system for its collations. So, out of the box and for all platform versions, it has about 25 distinct collations for 4-byte UTF8. One of them is based on the DUCET for Unicode 5.2.
MySQL’s character set and collation support is excellent in some other respects, but I’ll put off the paeans for another post. Here I’ve just addressed a standard matter.
Views
Example:
CREATE TABLE t (s1 INT); CREATE VIEW v AS SELECT * FROM t WHERE s1 < 5 WITH CHECK OPTION;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
MySQL has some support for core standard feature F311-04 “Create view: with check option”. PostgreSQL does not.
Transactions
Example:
START TRANSACTION; CREATE TABLE t (s1 SMALLINT); INSERT INTO t VALUES (1); INSERT INTO t VALUES (32768); /* This causes an error. */ COMMIT; SELECT * FROM t;
Result:
MySQL finds a row containing 1. PostgreSQL finds nothing.
Reason:
PostgreSQL rolls back the entire transaction when it encounters a syntax error. MySQL only cancels the statement.
Now, PostgreSQL is within its rights — the standard says that an implementor may do an “implicit rollback” for an error. But that is a provision for what a DBMS implementor MAY do. From other passages in the standard, it’s apparent that the makers didn’t anticipate that a DBMS would ALWAYS do it, even for syntax errors. (For example it says: “exception conditions for transaction rollback have precedence over exception conditions for statement failure”.) Even Microsoft SQL Server, in its optional “abort-transaction-on-error” mode, doesn’t abort for syntax errors. So MySQL appears to be nearer the spirit of the standard as generally understood.
Example:
CREATE TABLE t (s1 INT); INSERT INTO t VALUES (1); COMMIT; START TRANSACTION; SELECT CURRENT_TIMESTAMP FROM t; /* Pause 1 second. */ SELECT CURRENT_TIMESTAMP FROM t;
Result: PostgreSQL shows the same timestamp twice. MySQL shows two different timestamps.
Reason:
PostgreSQL keeps the same time throughout a transaction; MySQL keeps the same time throughout a statement.
The key sentences in the standard say that the result of a datetime value function should be the time when the function is evaluated, and “The time of evaluation of a datetime value function during the execution of S and its activated triggers is implementation-dependent.” In other words, it’s supposed to occur during the execution of S, which stands for Statement. Of course, this leads to arguable matters, for example what if the statement is in a function that’s invoked from another statement, or what if the statement is within a compound statement (BEGIN/END block)? But we don’t have to answer those questions here. We just have to observe that, for the example given here, the DBMS should show two different timestamps. For documentation of how DB2 follows this, see ibm.com.
Stored Procedures, Functions, Triggers, Prepared Statements
Example:
CREATE FUNCTION f () RETURNS INT RETURN 1;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support any functions, stored procedures, or triggers with standard syntax.
Instead PostgreSQL supports Oracle syntax. This is not as bad it sounds — the Oracle syntax is so popular that even DB2 also has decided to support it, optionally.
Example:
PREPARE stmt1 FROM 'SELECT 5 FROM t';
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL doesn’t support the standard syntax for PREPARE.
Data Types
Example:
CREATE TABLE t (s1 CHAR(1)); INSERT INTO t VALUES (U&'\+000000');
Result:
PostgreSQL returns an error. MySQL succeeds, although MySQL has to use a different non-standard syntax.
Reason:
PostgreSQL has an aversion to CHR(0) the NUL character.(“The character with the code zero cannot be in a string constant.”). Other DBMSs allow all characters in the chosen character set. In this case, the default character set is in use, so all Unicode characters should be okay.
Example:
CREATE TABLE t (s1 BINARY(1), s2 VARBINARY(2), s3 BLOB);
Result: PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support BINARY or VARBINARY or BLOB. It has equivalent non-standard data types.
The Devil Can Cite Scripture For His Purpose
I could easily find examples going the other way, if I wrote a blog post titled “Sometimes PostgreSQL is more standards-compliant than MySQL”. But can one generalize from such examples?
The PostgreSQL folks boldly go to conclusion mode:
As a quick summary, MySQL is the “easy-to-use, web developer” database, and PostgreSQL is the “feature-rich, standards-compliant” database.
Follow I do not dare.
Representing Sex In Databases
The MySQL Reference Manual advises:
Use a CREATE TABLE statement to specify the layout of your table:
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
-> species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
…
Several types of values can be chosen to represent sex in animal records, such as ‘m’ and ‘f’, or perhaps ‘male’ and ‘female’. It is simplest to use the single characters ‘m’ and ‘f’.
I will supplement that with this post about representing sex (gender) in people records. I have to consider the name, the possible values, the data type, and the constraints. It won’t be simplest.
Should the column name be ‘sex’?
First consider Naming Conventions. The word ‘sex’ is not too long, its characters are all Latin, there is no need to “delimit”, using lower case is okay, making it plural (‘sexes’) would be a mistake, and it’s not a reserved word. So far so good.
Next consider the alternative term ‘gender’. Some people make a distinction between gender and sex. In that case, ‘sex’ is better if only a physical characteristic matters, but ‘gender’ is better if you’re also taking into account the behaviour, self-identification, and washroom preference. However, gender’s primary dictionary meaning is as a grammatical category, and it is a far less popular word.
Conclusion: yes, the column name should be ‘sex’.
Should the possible values be ‘m’ and ‘f’?
Now consider interoperability. If there are application programs that use the database, what checkboxes are they likely to display? If the data must go to some other body (the government, say), do they tell you what the choices are? This is where standards come in. For pretty well anything that’s commonly used to describe a person (age, occupation, income, and of course sex) there will be a standard code list.
The German Wikipedia article about “Data standards for description of sex” describes many of them. It’s worth a look even if your German is weak, because most of the charts include English translations. I’ll try to use primary sources and then generalize:
- ISO 5218.
ISO/IEC 5218 Information technology — Codes for the representation of human sexes has single-digit numeric codes: 0 = not known, 1 = male, 2 = female, 9 = not applicable.
- Three-Way.
The CDC (Centers for Disease Control) prescription is ‘M’ = male, ‘F’ = female, ‘O’ = other.
On German birth certificates, starting in November the choices will be ‘M’, ‘F’, ‘ ‘.
For Australian passports the choices are ‘M’, ‘F’, ‘X’.
- European.
The Eurostat statistics group of the European Commission, and SDMX (Statistical Data and Metadata eXchange) which is sponsored by Eurostat and OECD, have produced a hodgepodge of incompatible recommendations. But the most recent list seems to be: T = Total, F = Females, M = Males, NAP = Not applicable, UNK = Unknown.
- Biological.
HL7 (Health Level 7), a standard for interoperability of health information adds a hermaphrodite category. CID 7455, a directive for physicians goes furthest of all with: M = Male, F = Female, U = Unknown Sex, MP = Male pseudohermaphrodite (see the Wikipedia article on Pseudohermaphroditism), FP = Female pseudohermaphrodite, H = Hermaphrodite, MC = Male changed to female, FC = Female changed to male, 121104 = Ambiguous, 121032 = Subject sex (for clinical purposes), 121102 = Other, 121103 = Temporarily undetermined (see the BBC article on determining sex or see “Everything you ever wanted to know about determining sex”).
ISO 5218 is the international standard, and gets a recommendation in a chapter about sex in “Joe Celko’s Data, Measurement and Standards in SQL”. The problem is it only uses digits. This eliminates the worry that it will look biased towards West European languages, but then it looks biased towards males (because ‘1’ comes before ‘2’), and on that basis has been called “offensive”.
More seriously, a digit has no mnemonic value and that means inputters and readers would have to learn more, or developers would have to write more.
Let’s look instead for something that the other “standards” can agree on.
They all say ‘M’ = male and ‘F’ = female, so that’s indisputable.
Most of them say there’s at least one other category, and although it is disputable it is prudent to add ‘O’ = other, forestalling complaints like the lack of ‘fluidity’ objection from the Gay, Lesbian, Bisexual, and Transgender Round Table of the American Library Association.
Most of them say there are codes for “unknown” and “not applicable”, and this should be disputed. Such codes are necessary for simple lists, but for SQL databases they are unnecessary because NULLs exist. If we said that the ‘sex’ column has special values for “unknown” or “not applicable”, but ‘owner’ and ‘species’ do not, we would need inconsistent rules. Therefore “unknown” and “not applicable” are to be handled with NULL.
They all say that ‘M’ and ‘F’ are upper case. Of course it might not matter in MySQL or MariaDB, where the default collation is case insensitive. But other DBMSs are stricter, and we’re thinking about interoperability here, so lower case codes like ‘m’ and ‘f’ are not acceptable equivalents.
Conclusion: allow ‘M’, ‘F’, ‘O’, and NULL.
Should the data type be CHAR(1)?
Now consider what best fits for the range of values, without totally forgetting efficient storage.
- ENUM(‘M’,’F’,’O’)
This has the advantage that input errors, like a sex value of ‘!’, won’t be allowed — the closest that MySQL can come to a CHECK clause. And it’s handy that ENUMs can be searched as numerics, which for this definition would be 1 = M and 2 = F, the same as the ISO/IEC requirement. But ENUM is not standard.
- SMALLINT or TINYINT
Well, any numeric type would be okay for storing an ISO-5218-style digit. However, saying it’s SMALLINT is telling the world “it’s a number”. Just because a digit can appear in a numeric column doesn’t mean that any of the things that are meaningful for numbers (averaging, multiplying, etc.) should be applicable to ‘sex’.
- BOOLEAN
MySQL’s BOOLEAN is just a synonym for TINYINT(1) so is of no use. If we were talking about the real idea of a Boolean — a binary TRUE/FALSE — we’d better change the column name to reflect that the answers are true or false — instead of ‘sex’, the column name should be ‘is_male’.
- VARCHAR(5)
This is a bit more flexible than CHAR(1) if one fears that someday there will be a mandate to store as CID 7455 which has 5-character codes, but VARCHAR might need more space.
- BIT(1) and CHAR(0)
Speaking of needing space, a bunch of BIT columns might be more economical for storage than a bunch of CHAR(1) columns, with MyISAM. And for the CHAR(0) trick, see a 2008 post from Percona. BIT(1) and CHAR(0) would only be for people desperate to save bytes; in other respects they are the worst choice.
Conclusion: yes, the data type should be CHAR(1).
Should there be constraints to prevent bad input?
Since we won’t use ENUM, and we can’t use a CHECK clause, how can we stop people from putting in something other than ‘M’, ‘F’, ‘O’, or NULL?
With old versions we’d have to make views with CHECK OPTION clauses, or perhaps foreign-key references. Nowadays we can make triggers. For example:
DELIMITER //
CREATE TRIGGER check_sex AFTER INSERT ON pet FOR EACH ROW BEGIN
IF new.sex COLLATE latin1_bin NOT IN ('M','F','O') AND new.sex IS NOT NULL THEN
SIGNAL SQLSTATE '22222' SET MESSAGE_TEXT='sex must be ''M'' or ''F'' or ''O'' or NULL';
END IF;
END//
For historical reasons that’s not a MySQLish practice, though. Ordinarily I’d expect that people will hope that application code will keep the input clean, and will do periodic cleanups when they find that application code does not keep the input clean.
The Real Point
The MySQL manual is correct about the way to design a “My Pets” database. But if a database description will consistently map to items in the real big wide world, there are going to be multiple things to consider.
NULL and UNIQUE
When I worked for MySQL I saw frequent complaints that the UNIQUE constraint didn’t stop users from inserting NULLs, multiple times. For example:
CREATE TABLE t (s1 INT, UNIQUE (s1));
INSERT INTO t VALUES (NULL);
INSERT INTO t VALUES (NULL); /* This does not cause a “unique constraint violation” error */
There are now eleven generously-commented bugs.mysql.com reports:
#5685, #6829, #7479, #8173, #9844, #17825, #19377, #25544, #27019, #27376, #66512. The essential points (along with observations about how we were stupid or deaf or lazy) are:
- the ANSI/ISO SQL standard said we should throw an error,
- all the other major DBMSs would throw an error,
- and throwing an error would be more sensible and convenient.
The first point is false; the second point depends what “major” means; the third point is a valid opinion.
I will now attempt to beat this subject to death with enough thoroughness that it will become dead.
Exactly what the ANSI/ISO standard says, and how it applies
Our example will be a table named t created thus:
CREATE TABLE t (s1 INT, UNIQUE (s1));
INSERT INTO t VALUES (NULL),(NULL);
So t looks like this:
+------------+ | s1 | +------------+ | NULL | | NULL | +------------+
Our question will be: is the constraint “UNIQUE (s1)” violated according to the SQL standard?
I’ll use a recent draft of SQL:2011 because it’s current and it’s available for all to see, at:
jtc1sc32.org/doc/N1951-2000/32N1964T-text_for_ballot-FCD_9075-2.pdf.
The wording is about the same in all earlier versions of the standard since SQL-89, which didn’t allow NULLs at all for UNIQUE constraints.
Section 11.7 says:
[Syntax Rules]
4) … let SC be the <search condition>:
UNIQUE ( SELECT UCL FROM TNN )
where UCL means “Unique Column List” and TNN means “Table Name”.
So for our example, search condition SC is “UNIQUE (SELECT s1 FROM t)”.
3) The unique constraint is not satisfied if and only if
EXISTS ( SELECT * FROM TNN WHERE NOT ( SC ) )
is True.
… Plugging in our values, that means
3) The unique constraint is not satisfied if and only if
EXISTS ( SELECT * FROM t WHERE NOT ( UNIQUE (SELECT s1 FROM t) ) )
is True.
So now we have to know how “UNIQUE(…)” is supposed to work.
Section 8.11 says:
If there are no two rows in T such that the value of each column in one row is non-null and is not distinct from the value of the corresponding column in the other row, then the result of the <unique predicate> is True; otherwise, the result of the <unique predicate> is False.
… where T is the table.
Now, apply the predicate “UNIQUE (s1)” to table t.
For either Row#1 or Row#2: Is the value of column s1 non-null?
Answer: NO. It is NULL.
Therefore the requirement “that the value of each column in one row is non-null” is met for zero rows in t.
But the <unique predicate> is only False if the requirement is met for two rows in t. Therefore the result of the <unique predicate> is True.
In other words,
UNIQUE (s1) is True.
Therefore
NOT (UNIQUE (s1)) is False.
Therefore
SELECT * FROM TNN WHERE NOT (UNIQUE (t)) returns zero rows.
Therefore
EXISTS ( SELECT * FROM TNN WHERE NOT ( UNIQUE (t) ) ) is false.
But Rule 3) says that the unique constraint is not satisfied if and only if that EXISTS clause is True.
Therefore the constraint is satisfied.
And when a constraint is satisfied, it is not violated.
Thus, according to the rules for <unique constraint definition>, our example table violates no constraint.
It’s tedious to work through this because there are multiple negatives, but it is not ambiguous.
Why, then, do some people have trouble? Partly because they look at a different statement in the introductory sections. Section 4.17 Integrity constraints says:
A unique constraint is satisfied if and only if no two rows in a table have the same non-null values in the unique columns.
And I have to admit that it’s not at all obvious what that’s supposed to mean. But, since you have now seen what is in the later and more detailed sections, you should read it as “no two rows have unique-column values which are the same (an undefined word which probably means equal) and which are also non-null”.
What other DBMSs do
Trudy Pelzer and I wrote this on page 260 of our book, SQL Performance Tuning:
| DBMS | Maximum number of NULLs when there is a UNIQUE constraint |
| IBM (DB2) | One |
| Informix | One |
| Ingres | Zero |
| InterBase | Zero |
| Microsoft (SQL Server) | One |
| MySQL | Many [although the BDB storage engine was an exception] |
| Oracle | Many |
| Sybase | One |
DB2 has an optional clause which can force standard behaviour.
Oracle is only allowing multiple NULLs because it doesn’t put NULLs in indexes; if we were talking about a multiple-column constraint, Oracle would be non-standard.
The book didn’t cover PostgreSQL and Access and Firebird, which all allow “Many” NULLs. A newer entrant, NuoDB, allows only one NULL (I told them that’s non-standard but they didn’t believe me).
Most of the complainers were apparently thinking of Microsoft SQL Server. So it’s interesting that on Microsoft’s discussion boards the complaints are (spoiler alert!) that SQL Server doesn’t follow the standard and should be more like other DBMSs. See, for example, NULL in unique index (where SQL Server gets it wrong) and Change UNIQUE constraint to allow multiple NULL values.
According to SQL Server Magazine, in 2008,
ANSI SQL supports two kinds of UNIQUE constraints — one that enforces uniqueness of NULLs just like with known values, and another that enforces uniqueness of known values but allows multiple NULLs. Microsoft SQL Server implemented only the former.
As we’ve seen, that’s false, and so is another claim, that “Informix and Microsoft SQL Server follow the other interpretation of the standard.” But perhaps Microsoft’s stories help explain people’s beliefs.
What is more sensible
An unfortunate defence of the allow-many-NULLs behaviour is that “Null values are not considered equal”. That’s what’s happening in effect in this particular case, but it’s not a general or useful rule.
- (a) if we were doing a NULL/NULL comparison, or a NULL/not-NULL comparison, the result would be UNKNOWN. For other constraints an UNKNOWN result is considered a violation.
- (b) “equality” is the wrong concept to consider here, it is more important to consider whether the values are “not distinct” — and in fact two NULL values are not distinct.
- (c) NULLs sort together for purposes of GROUP BY, ORDER BY, or duplicate elimination.
Therefore, the UNIQUE rules do not follow automatically from how NULLs behave elsewhere in SQL. That is why the standard had to add wording to specify that the uniqueness predicate applies only for “non-null” values.
So, regarding what looks more sensible, it seems that the complainers have a point.
What is more convenient?
It is better, now, to carry on as before. The current behaviour is the de facto and the de jure standard. It is neither a bug nor undesirable.
But would it be even better if MySQL or MariaDB allowed an option? The DB2 syntax to allow UNIQUE with many NULLs is:
CREATE TABLE t (s1 INT UNIQUE WHERE NOT NULL)
so presumably the way to specify UNIQUE with one NULL would be:
CREATE TABLE t (s1 INT UNIQUE WHERE NULL OR NOT NULL)
but it would be easier to understand if we said
CREATE TABLE t (s1 INT UNIQUE AND MAXIMUM NUMBER OF NULLS = 1).
Anyway, it would be possible. But a nice first step would be to acknowledge that it is a feature request rather than a bug.
Copyright (c) 2013 by Ocelot Computer Services Inc. All rights reserved.