Category: Standard SQL
Date arithmetic with Julian days, BC dates, and Oracle rules
Here are routines that can handle date arithmetic on BC dates, Julian day functions, and simulation of Oracle’s support of old-style-calendar dates — including simulation of an Oracle bug. So the routines are good for extending the range of useable dates, compact storage, and import/export between DBMSs that have different rules.
If you need to refresh your understanding of dates, read our old-but-lovely article first: The Oracle Calendar.
I wrote the main routines with standard SQL so they should run on
any DBMS that supports the standard, but tested only with
MySQL and MariaDB. (UPDATE on 2019-02-04: corrections were needed with HSQLDB, see the comments.)
ocelot_date_to_julianday
Return number of days since 4713-01-01, given yyyy-mm-dd [BC] date
ocelot_date_validate
Return okay or error, given yyyy-mm-dd BC|AD date which may be invalid
ocelot_date_datediff
Return number of days difference, given two yyyy-mm-dd [BC] dates
ocelot_date_test
Return ‘OK’ after a thorough test of the entire range of dates
All function arguments look like this:
yyyy-mm-dd [BC] … CHAR|VARCHAR. yyyy-mm-dd is the standard date format for year and month and date, optionally followed by a space and ‘BC’. If ‘BC’ is missing, ‘AD’ is assumed. Must be between 4713-01-01 BC and 9999-12-31 for Julian-calendar dates, or between 4714-11-24 BC and 9999-12-31 for Gregorian-calendar dates. Routines will return bad results if dates are invalid, if there is any doubt then run ocelot_date_validate() first.
julian_day … INTEGER. For an explanation of what a “Julian day number” is, see Wikipedia. Do not confuse with “Julian-calendar date” — the name is similar but Julian days can be converted to or from dates in the Gregorian calendar too. Must be between 0 (which is 4713-01-01 BC) and a maximum (which is 9999-12-31).
‘J’ or ‘G’ or ‘O’ … CHAR. This is an “options” flag. ‘J’ means use the Julian (old style) calendar. ‘G’ means use the Gregorian (new style) calendar.’O’ means use the Oracle rules, which we described in the earlier article. If options is not ‘J’ or ‘G’ or ‘O’, ‘G’ is assumed.
Example expressions:
#1 ocelot_date_to_julianday(‘0001-01-01′,’G’) returns 1721426
#2 ocelot_date_to_julianday(‘0001-01-01′,’J’) returns 1721424
#3 ocelot_date_to_julianday(‘4712-01-01 BC’, ‘O’) returns 0
#4 ocelot_date_datediff(‘0001-01-01′,’0001-01-01 BC’,’G’) returns 366
#5 ocelot_date_to_julianday(‘1492-10-12′,’J’)%7; returns 4
/* Explanations: #3 returns 0 because there’s a year 0000,
#4 returns 366 because 0001 BC is a leap year,
#5 returns weekday = 4 for the original Columbus Day
and he used a Julian calendar. */
The source code
The code is original but the general idea is not — I gratefully acknowledge Peter Baum’s 1998 article “Date Algorithms”.
I use the Ocelot GUI (ocelotgui) when I write routines for MySQL/MariaDB. Since it recognizes all their syntax quirks it can give me hints when I’m typing something wrong, and saves me from the hassles of “delimiter”. And it has a debugger. Version 1.0.8 was released yesterday for download via github.
I start with a standard 2-clause BSD license and then show the CREATE statements for each routine. To install: just cut-and-paste what follows this paragraph until the end of this section. If you are not using ocelotgui you will have to say DELIMITER // and put // at the end of each CREATE statement.
/*
Copyright (c) 2019 Ocelot Computer Services Inc.Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
/*
ocelot_date_to_julianday(yyyy-mm-dd[ BC], J|G|O) Return number of days
————————
If J: will return 0 for ‘4713-01-01 BC’, all calculations use Julian calendar
If G: will return 0 for ‘4714-11-24 BC’, all calculations use Gregorian calendar
If O: will return 0 for ‘4712-01-01 BC’, switch between calendars after 1582-10-04
*/
CREATE FUNCTION ocelot_date_to_julianday(in_date VARCHAR(25), options CHAR(1)) RETURNS DECIMAL(8)
LANGUAGE SQL DETERMINISTIC CONTAINS SQL
BEGIN
DECLARE year, month, day, century, leap INT;
DECLARE jd DOUBLE PRECISION;
DECLARE bc_as_char CHAR(2);
SET year = CAST(SUBSTRING(in_date FROM 1 FOR 4) AS DECIMAL(8));
SET month = CAST(SUBSTRING(in_date FROM 6 FOR 2) AS DECIMAL(8));
SET day = CAST(SUBSTRING(in_date FROM 9 FOR 2) AS DECIMAL(8));
SET bc_as_char = SUBSTRING(in_date FROM CHAR_LENGTH(in_date) – 1 FOR 2);
IF bc_as_char = ‘BC’ THEN
IF options = ‘O’ THEN SET year = 0 – year;
ELSE SET year = (0 – year) + 1; END IF;
END IF;
IF month <= 2 THEN SET year = year - 1; SET month = month + 12; END IF; IF options = 'G' OR (options = 'O' AND in_date >= ‘1582-10-05’ AND bc_as_char <> ‘BC’) THEN
SET century = FLOOR(year / 100.0);
SET leap = 2 – century + FLOOR(century / 4.0);
ELSE
SET leap = 0;
END IF;
SET jd = FLOOR(365.25 * (year + 4716)) + FLOOR(30.6001 * (month + 1)) + day + leap – 1524;
RETURN CAST(jd AS DECIMAL(8));
END;/*
ocelot_date_validate (yyyy-mm-dd[ BC] date, J|G|O) Return ‘OK’ or ‘Error …’
——————–
Possible errors:
Format of first parameter is not ‘yyyy-mm-dd’ or ‘yyyy-mm-dd BC’.
Second parameter is not ‘J’ or ‘G’ or ‘O’.
Minimum date = 4713-01-01 BC if J, 4712-01-01 BC if O, 4714-11-14 BC if G.
Maximum date = 9999-12-31.
If ‘O’: 0001-mm-dd BC, or between 1582-10-05 and 1582-10-14.
nnnn-02-29 if nnnn is not a leap year.
Month not between 1 and 12.
Day not between 1 and maximum for month.
Otherwise return ‘OK’.
*/
CREATE FUNCTION ocelot_date_validate(in_date VARCHAR(25), options CHAR(1)) RETURNS VARCHAR(50)
LANGUAGE SQL DETERMINISTIC CONTAINS SQL
BEGIN
DECLARE year, month, day, leap_days DECIMAL(8);
DECLARE bc_or_ad VARCHAR(3) DEFAULT ”;
IF options IS NULL
OR (options <> ‘J’ AND options <> ‘G’ AND options <> ‘O’) THEN
RETURN ‘Error, Options must be J or G or O’;
END IF;
IF in_date IS NULL
OR (CHAR_LENGTH(in_date) <> 10 AND CHAR_LENGTH(in_date) <> 13)
OR SUBSTRING(in_date FROM 1 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 2 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 3 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 4 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 5 FOR 1) <> ‘-‘
OR SUBSTRING(in_date FROM 6 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 7 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 8 FOR 1) <> ‘-‘
OR SUBSTRING(in_date FROM 9 FOR 1) NOT BETWEEN ‘0’ AND ‘9’
OR SUBSTRING(in_date FROM 10 FOR 1) NOT BETWEEN ‘0’ AND ‘9’ THEN
RETURN ‘Error, Date format is not nnnn-nn-nn’;
END IF;
IF CHAR_LENGTH(in_date) = 13 THEN
SET bc_or_ad = SUBSTRING(in_date FROM 11 FOR 3);
IF bc_or_ad <> ‘ BC’ THEN
RETURN ‘Error, only space + BC is allowed after yyyy-mm-dd’;
END IF;
END IF;
SET year = CAST(SUBSTRING(in_date FROM 1 FOR 4) AS DECIMAL(8));
SET month = CAST(SUBSTRING(in_date FROM 6 FOR 2) AS DECIMAL(8));
SET day = CAST(SUBSTRING(in_date FROM 9 FOR 2) AS DECIMAL(8));
IF year = 0 THEN
RETURN ‘Error, year 0’;
END IF;
IF bc_or_ad = ‘ BC’ THEN
IF options = ‘J’ AND year > 4713 THEN
RETURN ‘Error, minimum date = 4713-01-01 BC’;
END IF;
IF options = ‘O’ AND year > 4712 THEN
RETURN ‘Error, minimum date = 4712-01-01 BC’;
END IF;
IF OPTIONS = ‘G’ THEN
IF year > 4714
OR (year = 4714 AND month < 11) OR (Year = 4714 AND month = 11 AND day < 24) THEN RETURN 'Error, minimum date = 4714-11-24 BC'; END IF; END IF; END IF; IF month = 0 OR month > 12 THEN RETURN ‘Error, month not between 1 and 12’; END IF;
SET leap_days = 0;
IF month = 2 AND day = 29 THEN
IF bc_or_ad = ‘ BC’ AND options <> ‘O’ THEN SET year = year – 1; END IF;
IF year % 4 = 0 THEN
IF options = ‘J’ OR (options = ‘O’ AND (bc_or_ad = ‘ BC’ OR SUBSTRING(in_date FROM 1 FOR 10) < '1582-10-04')) THEN SET leap_days = 1; ELSE IF year % 100 <> 0 OR year % 400 = 0 THEN
SET leap_days = 1;
END IF;
END IF;
END IF;
IF leap_days = 0 THEN RETURN ‘Error, February 29, not a leap year’; END IF;
END IF;
IF month = 1 AND day > 31
OR month = 2 AND day – leap_days > 28
OR month = 3 AND day > 31
OR month = 4 AND day > 30
OR month = 5 AND day > 31
OR month = 6 AND day > 30
OR month = 7 AND day > 31
OR month = 8 AND day > 31
OR month = 9 AND day > 30
OR month = 10 AND day > 31
OR month = 11 AND day > 30
OR month = 12 AND day > 31 THEN
RETURN ‘Error, day > maximum day in mnth’;
END IF;
IF options = ‘O’
AND bc_or_ad <> ‘ BC’
AND SUBSTRING(in_date FROM 1 FOR 10) BETWEEN ‘1582-10-05’ AND ‘1582-10-14’ THEN
RETURN ‘Error, Date during Julian-to-Gregorian cutover’;
END IF;
RETURN ‘OK’;
END;/*
ocelot_date_datediff(date, date, J|G|O) Return number of days between two dates
——————–
Results for positive Gregorian will be the same as MySQL/MariaDB datediff().
This is an extension of datediff() which works with BC Gregorian and other calendars.
Mostly it’s just to show how easily a routine can be written if there is a
Julian-day function.
*/
CREATE FUNCTION ocelot_date_datediff(date_1 VARCHAR(25), date_2 VARCHAR(25), options CHAR(1)) RETURNS INT
LANGUAGE SQL DETERMINISTIC CONTAINS SQL
RETURN ocelot_date_to_julianday(date_1, options) – ocelot_date_to_julianday(date_2, options);/*
ocelot_date_test(J|G|O) Test that all legal dates have the correct Julian day
—————-
You only need to run this once. The Julian day routine looks bizarre so this
test is here to give assurance that the ocelot_date_to_julianday function is okay.
Start with a counter integer = 0 and a yyyy-mm-dd BC date = the minimum for the calendar.
For each iteration of the loop, increment the counter and increment the date,
call ocelot_date_to_julianday and check that it returns a value equal to the counter.
Stop when date is 9999-12-31.
For Oracle emulation we do not check dates which are invalid due to cutover or bugs.
Bonus test: positive Gregorian dates must match MySQL|MariaDB datediff results.
Bonus test: check validity of each incremented date.
*/
CREATE FUNCTION ocelot_date_test(options CHAR(1)) RETURNS CHAR(50)
LANGUAGE SQL DETERMINISTIC CONTAINS SQL
BEGIN
DECLARE tmp VARCHAR(25);
DECLARE tmp_validity VARCHAR(50);
DECLARE year_as_char, month_as_char, day_as_char VARCHAR(25);
DECLARE year_as_int, month_as_int, day_as_int DECIMAL(8);
DECLARE ju, ju2 INT;
DECLARE bc_as_char VARCHAR(3) DEFAULT ”;
DECLARE is_leap INT DEFAULT 1;
IF options = ‘J’ THEN
SET ju = 0; SET tmp = ‘4713-01-01 BC’; SET bc_as_char = ‘ BC’; SET is_leap = 1;
END IF;
IF options = ‘G’ THEN
SET ju = 0; SET tmp = ‘4714-11-24 BC’; SET bc_as_char = ‘ BC’; SET is_leap = 0;
END IF;
IF options = ‘O’ THEN
SET ju = 0; SET tmp = ‘4712-01-01 BC’; SET bc_as_char = ‘ BC’; SET is_leap = 1;
END IF;
WHILE tmp <> ‘10000-01-01’ DO
IF options <> ‘O’
OR SUBSTRING(tmp FROM 1 FOR 4) <> ‘0000’
OR bc_as_char <> ‘ BC’ THEN
SET tmp_validity = ocelot_date_validate(tmp, options);
IF tmp_validity <> ‘OK’ THEN RETURN tmp_validity; END IF;
END IF;
SET ju2 = ocelot_date_to_julianday(tmp, options);
IF ju2 <> ju OR ju2 IS NULL THEN RETURN CONCAT(‘Fail ‘, tmp); END IF;IF options = ‘G’ and bc_as_char <> ‘ BC’ THEN
IF ju2 – 1721426 <> DATEDIFF(tmp,’0001-01-01′) THEN
RETURN CONCAT(‘Difference from datediff() ‘, tmp);
END IF;
END IF;
SET year_as_char = SUBSTRING(tmp FROM 1 FOR 4);
SET month_as_char = SUBSTRING(tmp FROM 6 FOR 2);
SET day_as_char = SUBSTRING(tmp FROM 9 FOR 2);
SET year_as_int = CAST(year_as_char AS DECIMAL(8));
SET month_as_int = CAST(month_as_char AS DECIMAL(8));
SET day_as_int = CAST(day_as_char AS DECIMAL(8));
/* Increase day */
SET day_as_int = day_as_int + 1;
IF options = ‘O’ AND year_as_int = 1582 AND month_as_int = 10 AND day_as_int = 5 AND bc_as_char <> ‘ BC’ THEN
SET day_as_int = day_as_int + 10;
END IF;
IF month_as_int = 1 AND day_as_int > 31
OR month_as_int = 2 AND day_as_int – is_leap > 28
OR month_as_int = 3 AND day_as_int > 31
OR month_as_int = 4 AND day_as_int > 30
OR month_as_int = 5 AND day_as_int > 31
OR month_as_int = 6 AND day_as_int > 30
OR month_as_int = 7 AND day_as_int > 31
OR month_as_int = 8 AND day_as_int > 31
OR month_as_int = 9 AND day_as_int > 30
OR month_as_int = 10 AND day_as_int > 31
OR month_as_int = 11 AND day_as_int > 30
OR month_as_int = 12 AND day_as_int > 31 THEN
/* Increase month */
SET day_as_int = 1;
SET month_as_int = month_as_int + 1;
IF month_as_int > 12 THEN
/* Increase year */
SET month_as_int = 1;
IF bc_as_char = ‘ BC’ THEN SET year_as_int = year_as_int – 1;
ELSE SET year_as_int = year_as_int + 1; END IF;
IF (year_as_int = 0 AND (options = ‘J’ OR options = ‘G’))
OR (year_as_int =-1 AND options = ‘O’) THEN
SET year_as_int = 1;
SET bc_as_char = ”;
SET is_leap = 0;
END IF;
/* Recalculate is_leap */
BEGIN
DECLARE divisible_year_as_int INT;
SET divisible_year_as_int = year_as_int;
IF bc_as_char <> ‘ BC’ OR options = ‘O’ THEN
SET divisible_year_as_int = year_as_int;
ELSE
SET divisible_year_as_int = year_as_int – 1;
END IF;
SET is_leap = 0;
IF divisible_year_as_int % 4 = 0 THEN
SET is_leap = 1;
IF options = ‘G’
OR (options = ‘O’ AND bc_as_char <> ‘ BC’ AND year_as_int > 1582) THEN
IF divisible_year_as_int % 100 = 0
AND divisible_year_as_int % 400 <> 0 THEN
SET is_leap = 0;
END IF;
END IF;
END IF;
END;
END IF;
END IF;
SET day_as_char = CAST(day_as_int AS CHAR);
IF LENGTH(day_as_char) = 1 THEN SET day_as_char = CONCAT(‘0’, day_as_char); END IF;
SET month_as_char = CAST(month_as_int AS CHAR);
IF LENGTH(month_as_char) = 1 THEN SET month_as_char = CONCAT(‘0’, month_as_char); END IF;
SET year_as_char = CAST(year_as_int AS CHAR);
WHILE LENGTH(year_as_char) < 4 DO SET year_as_char = CONCAT('0', year_as_char); END WHILE; SET tmp = CONCAT(year_as_char, '-', month_as_char, '-', day_as_char, bc_as_char); SET ju = ju + 1; END WHILE; RETURN CONCAT('OK ', tmp); END;
The Tarantool SQL Alpha
Tarantool, a Lua application server plus NoSQL DBMS, is now an SQL DBMS too, in alpha version 1.8. I was interested in how the combination “Lua + NoSQL + SQL” works. Disclaimer: I do paid work related to Tarantool but it has nothing to do with this blog.
First let’s verify that it’s really SQL. The illustrations are all unretouched screenshots from ocelotgui for Windows, connected to a Tarantool 1.8 server on Linux, which I built from a source download on github.
Example of SELECT
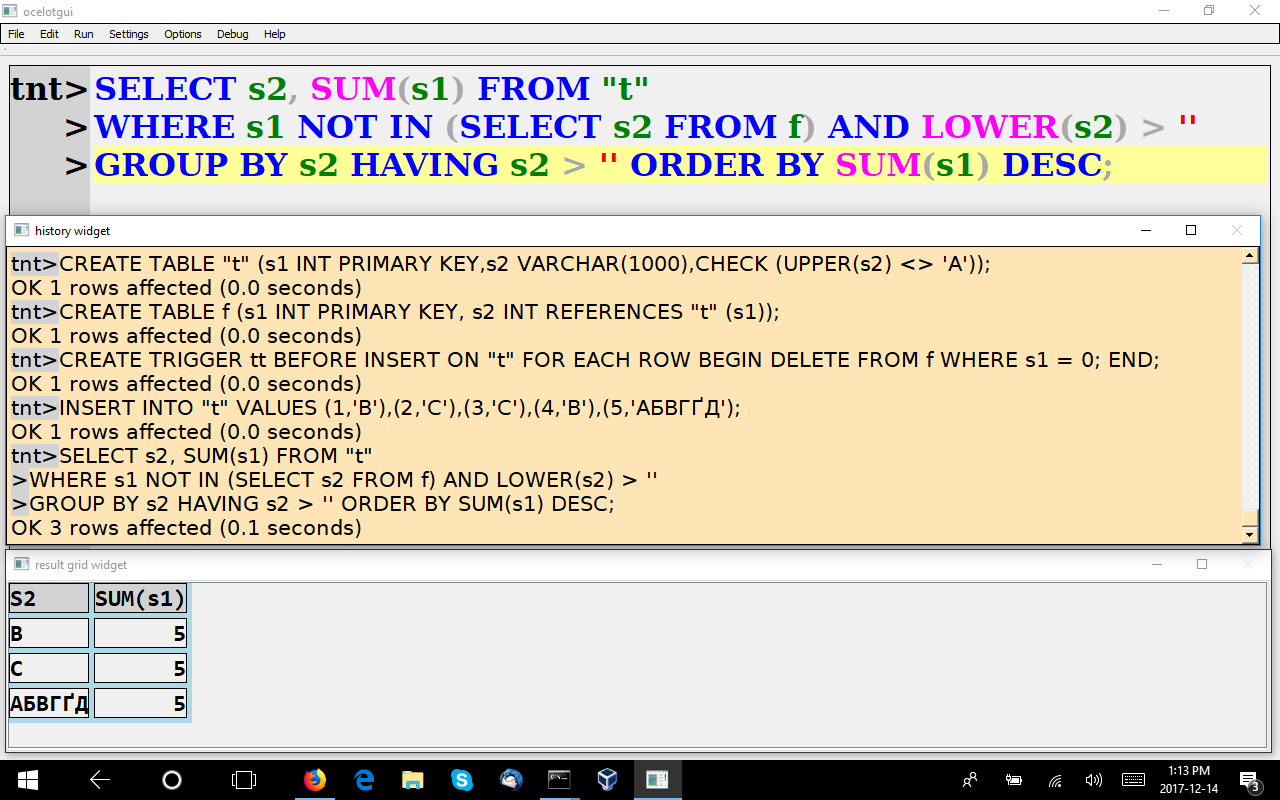
Yes, the “history” below the query window shows successful CREATE and INSERT statements, the “result set” at the bottom shows a successful SELECT statement’s output. A close look at the clauses shows that there’s support for constraints, foreign keys, triggers, … and so on. In all, it’s a reasonable subset of the SQL standard, pretty well the same as what I found for SQLite in an earlier post.
That’s not surprising because Tarantool started with SQLite’s parser; however, the storage layer is Tarantool’s NoSQL.
Combine Lua with SQL
Now it’s time for the first “combination”. I want to store and retrieve pictures, which are in .png and .jpg files. With MySQL/MariaDB I’d use load_file() but that’s a built-in function that Tarantool doesn’t have. Am I daunted? No, because I can write such a function in Lua — or actually I can copy such a function because it’s one of the examples in the Tarantool manual.
-- Lua function to set a variable to a file's contents
function load_file(file_name)
local fio = require('fio')
local errno = require('errno')
local f = fio.open(file_name, {'O_RDONLY' })
if not f then
error("Failed to open file: "..errno.strerror())
end
local data = f:read(1000000)
f:close()
return data
end;
Not a difficult matter. As is clear from the display,
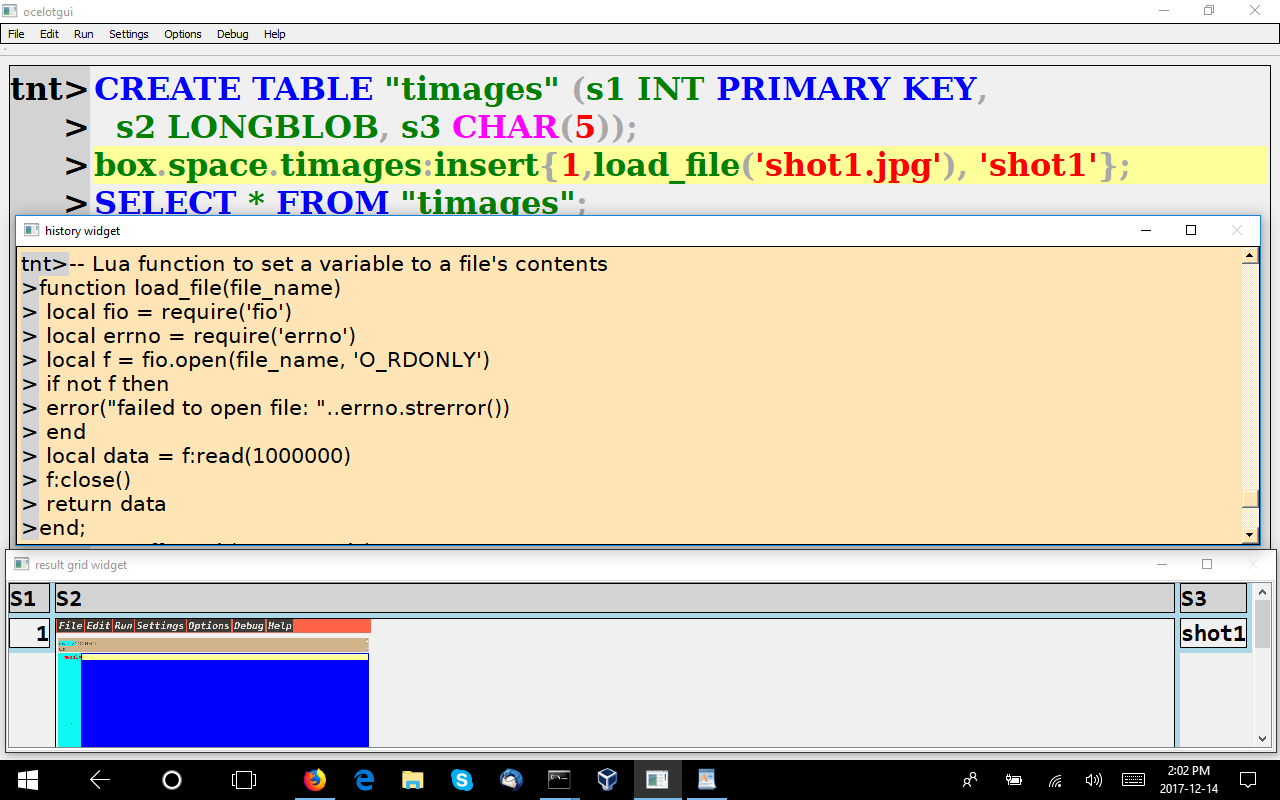
the function is syntactically okay (there would be squiggly red lines under the error if my Lua was bad). To explain the function: it says “read a file and return either an error message or the whole contents”.
I can’t call Lua functions directly from SQL yet, but I can do so from NoSQL, and with NoSQL I can INSERT into the same table that I created with SQL …
box.space.timages:insert{1,load_file(‘shot1.jpg’),’shot1′);
And then go back to SQL to handle the retrieval …
SELECT * FROM “timages”;
and the .jpg image is at the bottom of the screen.
So, although they’re not standard SQL/PSM or Oracle-like PL/SQL, Tarantool does have server-side stored procedures.
Combine NoSQL With SQL
Now it’s time for the second “combination”. I want to read some NoSQL data that was not produced or populated with SQL in mind. Specifically we’ve got: a variable number of fields, some of which are unnamed, and they’re not all scalar, there are arrays and structures. A typical tuple related to index metadata looks like this:
[[ Example of tuple ]]
- [312, 1, 'owner', 'tree', {'unique': false}, [[0, 'unsigned']]]
- [312, 2, 'object', 'tree', {'unique': false}, [[2, 'string'], [3, 'unsigned']]]
- [313, 0, 'primary', 'tree', {'unique': true}, [[1, 'unsigned'], [2, 'string'], [3, 'unsigned']]]
- [313, 1, 'owner', 'tree', {'unique': false}, [[0, 'unsigned']]]
- [313, 2, 'object', 'tree', {'unique': false}, [[2, 'string'], [3, 'unsigned']]]
- [320, 0, 'primary', 'tree', {'unique': true}, [[0, 'unsigned']]]
- [320, 1, 'uuid', 'tree', {'unique': true}, [[1, 'string']]]
For this I wrote some C code in the client instead of on the server, but I don’t think that’s cheating — it doesn’t show a Tarantool feature, but it does show that one can transfer the data into an SQL table and go from there. The syntax added to the client looks like this:
CREATE SERVER id FOREIGN DATA WRAPPER ocelot_tarantool OPTIONS (PORT 3301, HOST 'localhost', USER 'guest'); CREATE TABLE convertee SERVER id LUA 'return box.space._index:select()'; SELECT * FROM convertee;
The selection after converting looks like this:
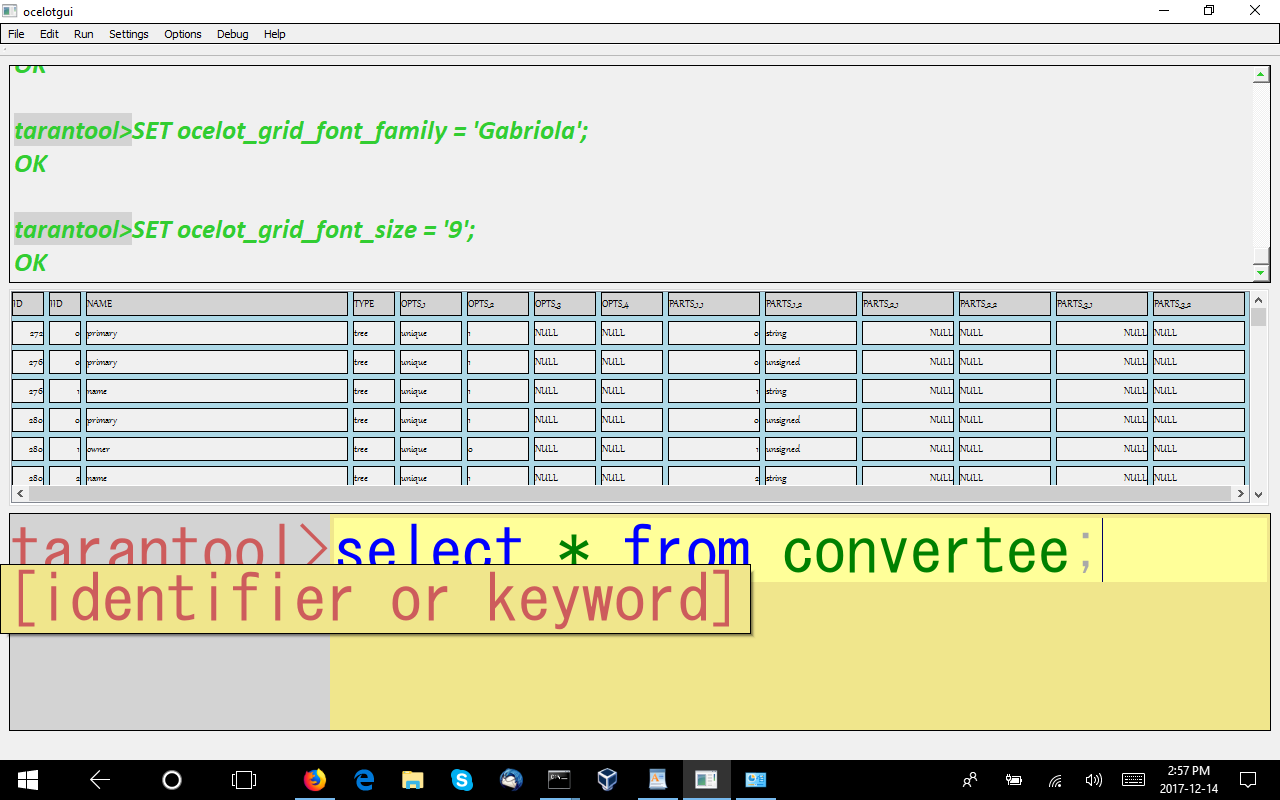
(I’m changing the fonts and the window order now to make relevant parts look bigger.)
I wish I could call this “flattening”, but that term has been hijacked for other concepts. Anyway, whatever it can be called, it’s the reason that schemaless data doesn’t need a new query language.
Things You Don’t Always See Elsewhere
I’ll mention a few things that are in Tarantool SQL that are not in MySQL/MariaDB, or are fairly new in MySQL/MariaDB. This short list does not mean Tarantool is “ahead”, I’m talking about an alpha where many things are to-be-announced. I like to look at what’s new and different.
COLLATE
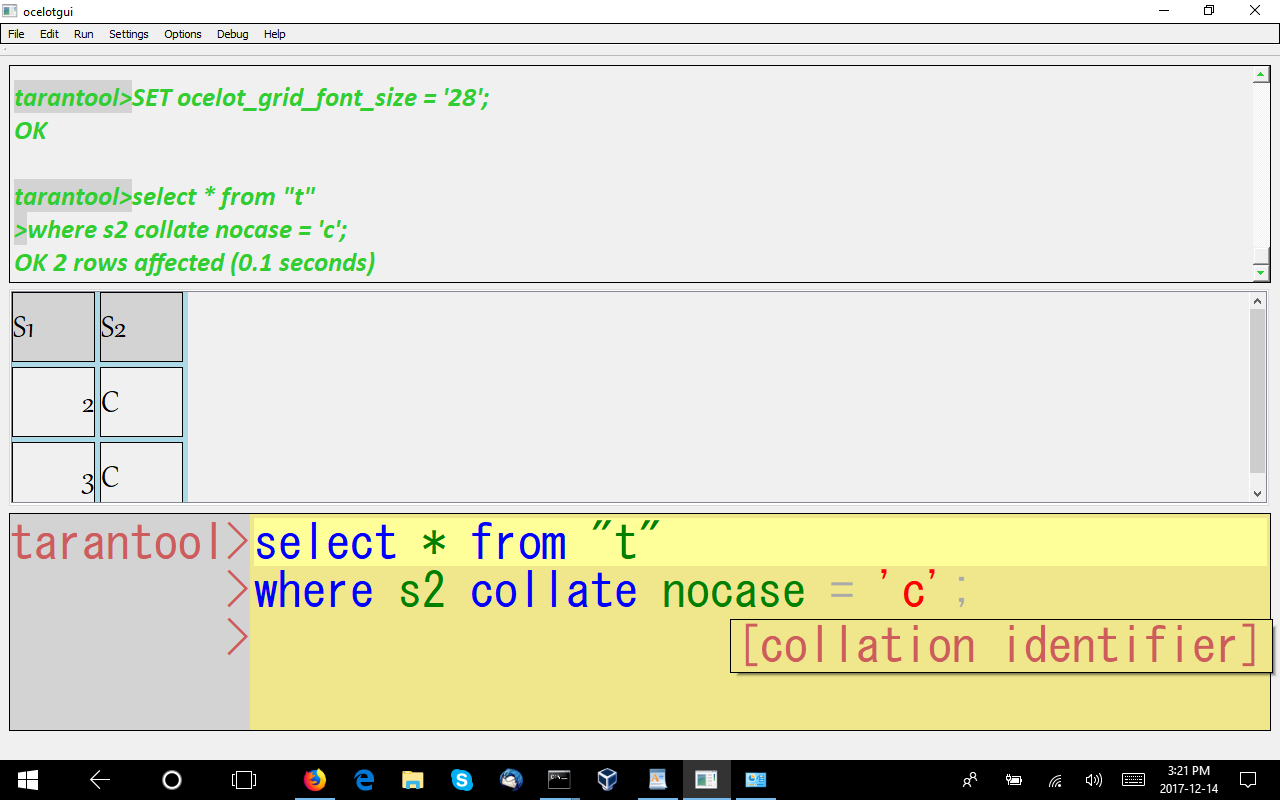
The point isn’t that there’s a COLLATE clause, the point is that the collation is ICU. I’ve talked about the advantages of ICU earlier. The collation name will change soon, probably to ‘unicode_s1’ or ‘unicode_ci’.
WITH
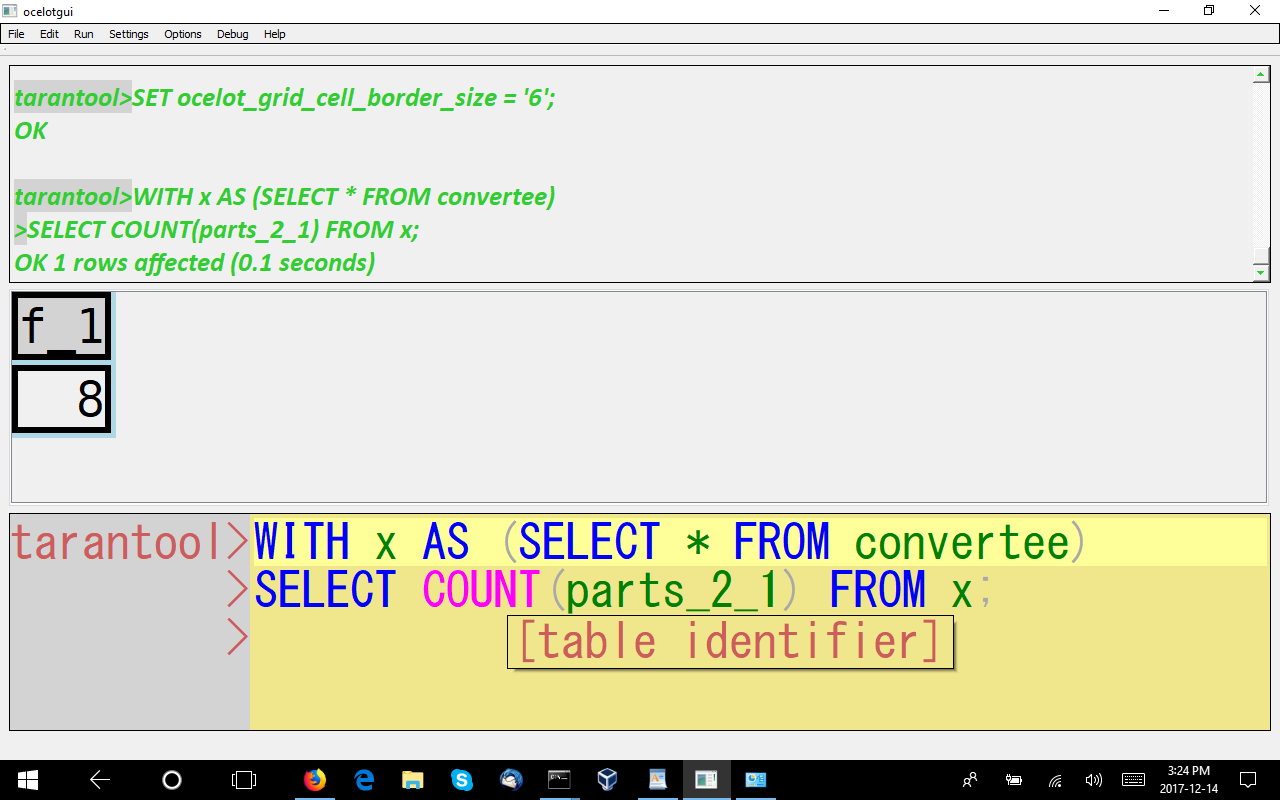
A non-recursive WITH clause is the same thing as a temporary view that lasts only for the statement that encloses it.
A recursive WITH clause is a temporary view that is populated by taking a seed (the query to the left of the UNION) and adding to it with a populator (the query to the right of the UNION), repeatedly, until some condition fails. I find it hard to understand, I suppose my problem is that this is procedural (a loop), and for procedural problems I prefer C or Lua or SQL/PSM.
EXCEPT and INTERSECT
SELECT * FROM "t" EXCEPT SELECT * FROM f;
These operators can fit in the same place as UNION, but have different effects. In the example, the EXCEPT would mean “take out the rows that match” instead of “add rows that do not match”.
NaN and Inf
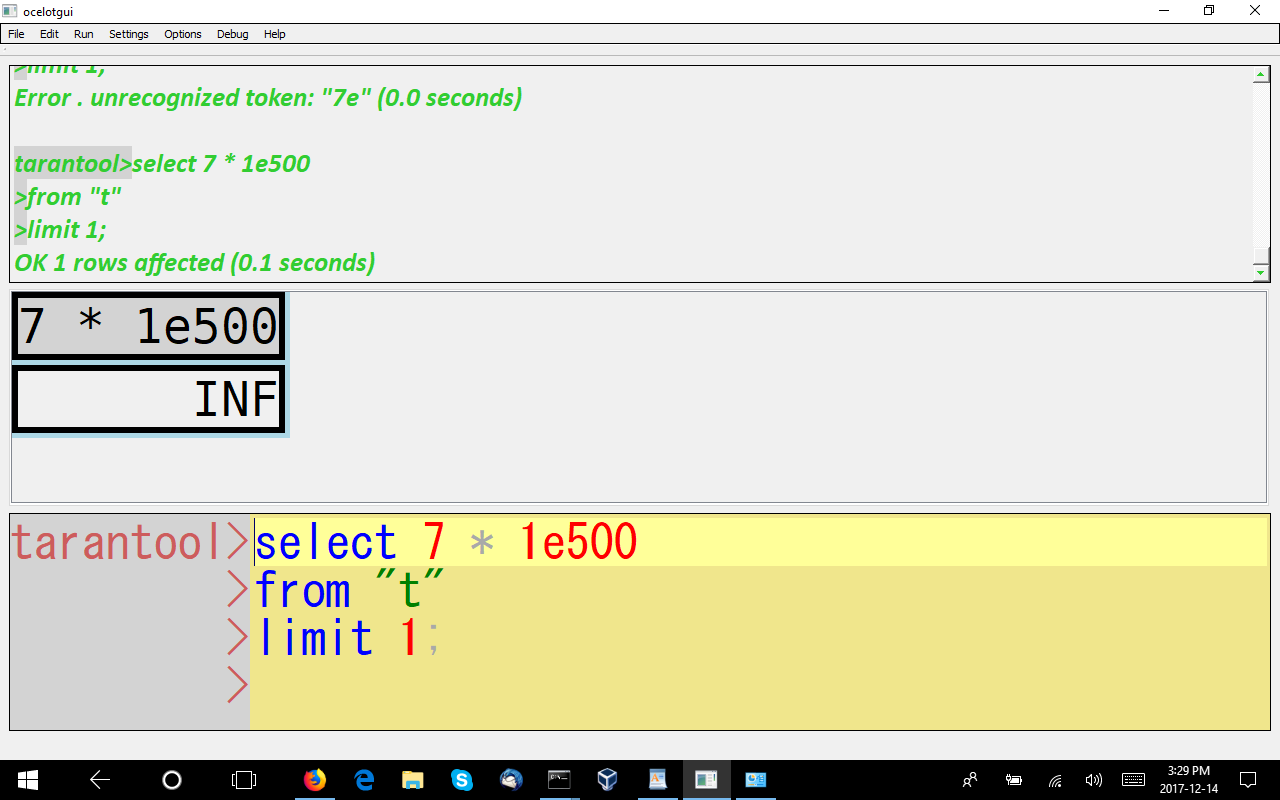
This is a differentiator, since in standard SQL and in some implementations these values are not supported, even though they’re supported in IEEE 754.
CHECK
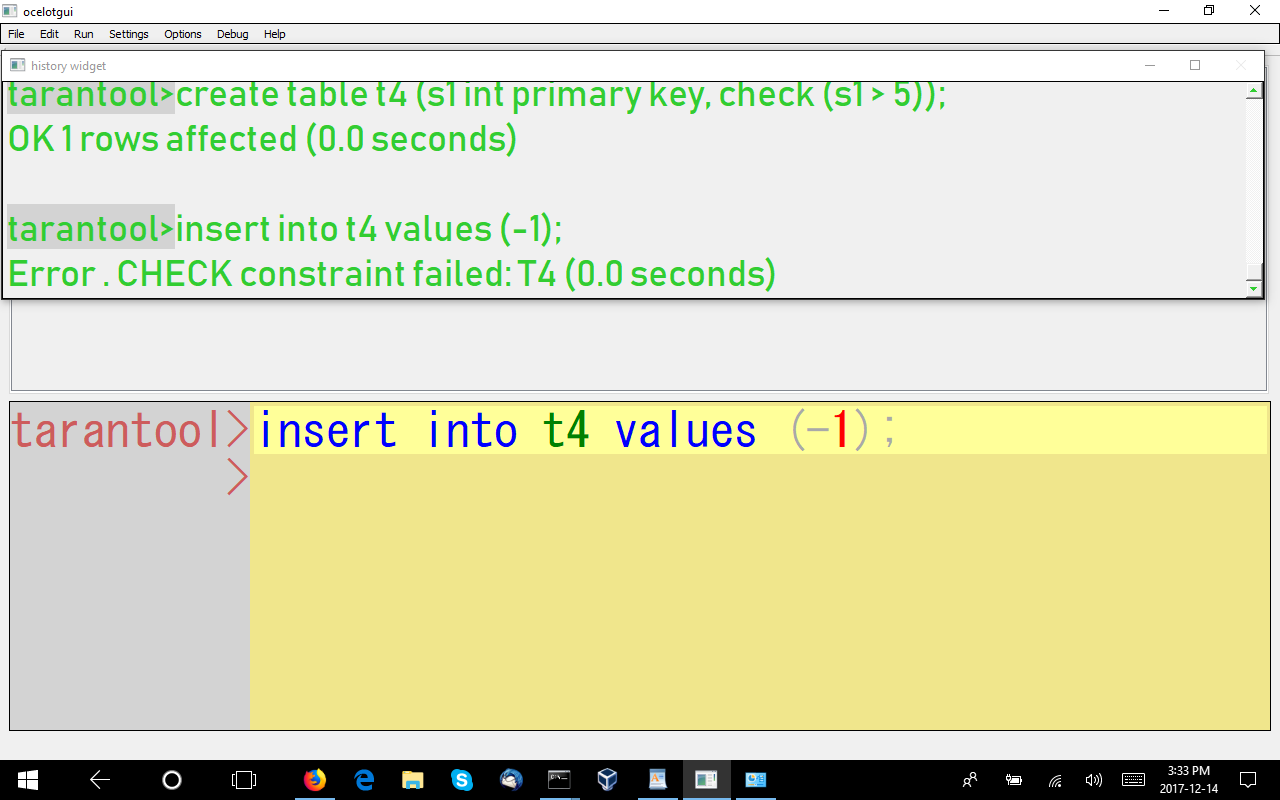
A constraint’s effect is: “if the condition inside the parentheses is true or unknown, then and only then it is legal to have this row.” This feature is also in MariaDB 10.2.1.
INDEXED BY
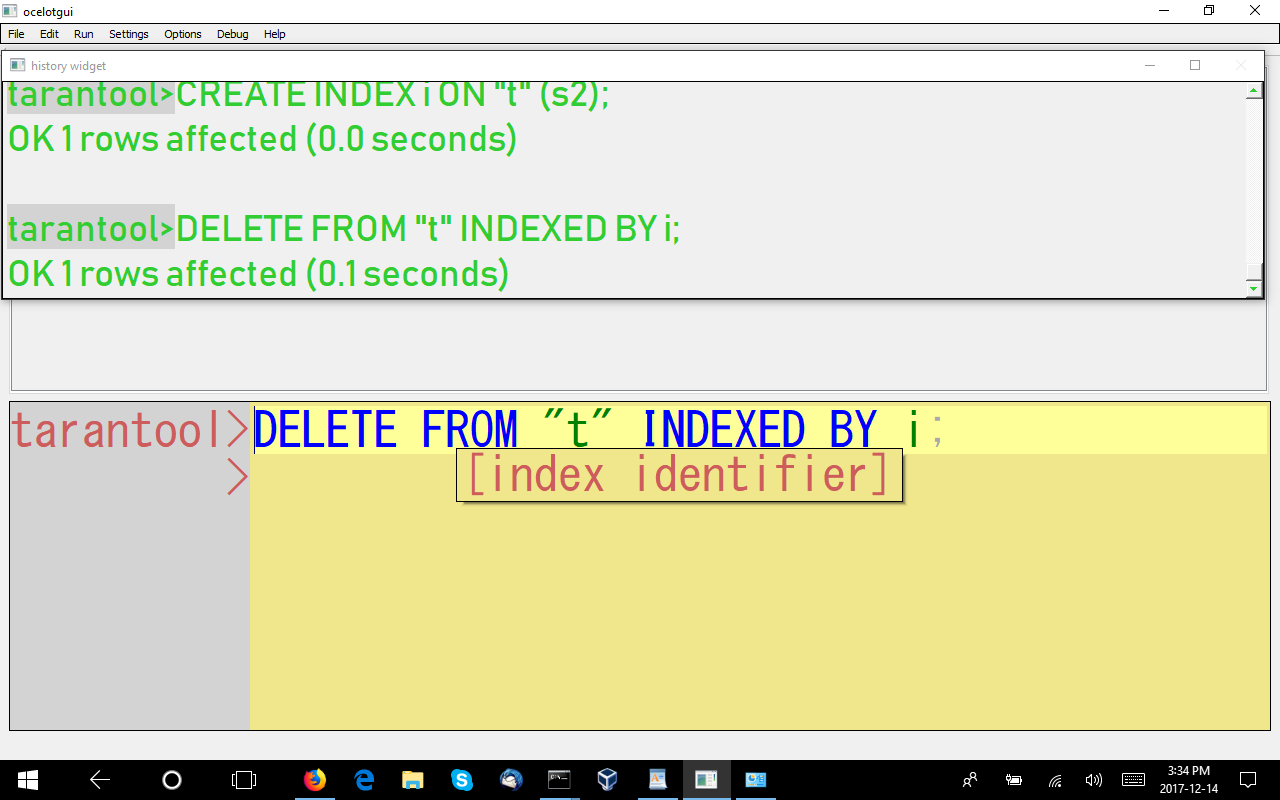
This is non-standard (and obviously always will be): you can force Tarantool to use a particular index, or no index at all, bypassing the optimizer.
VALUES
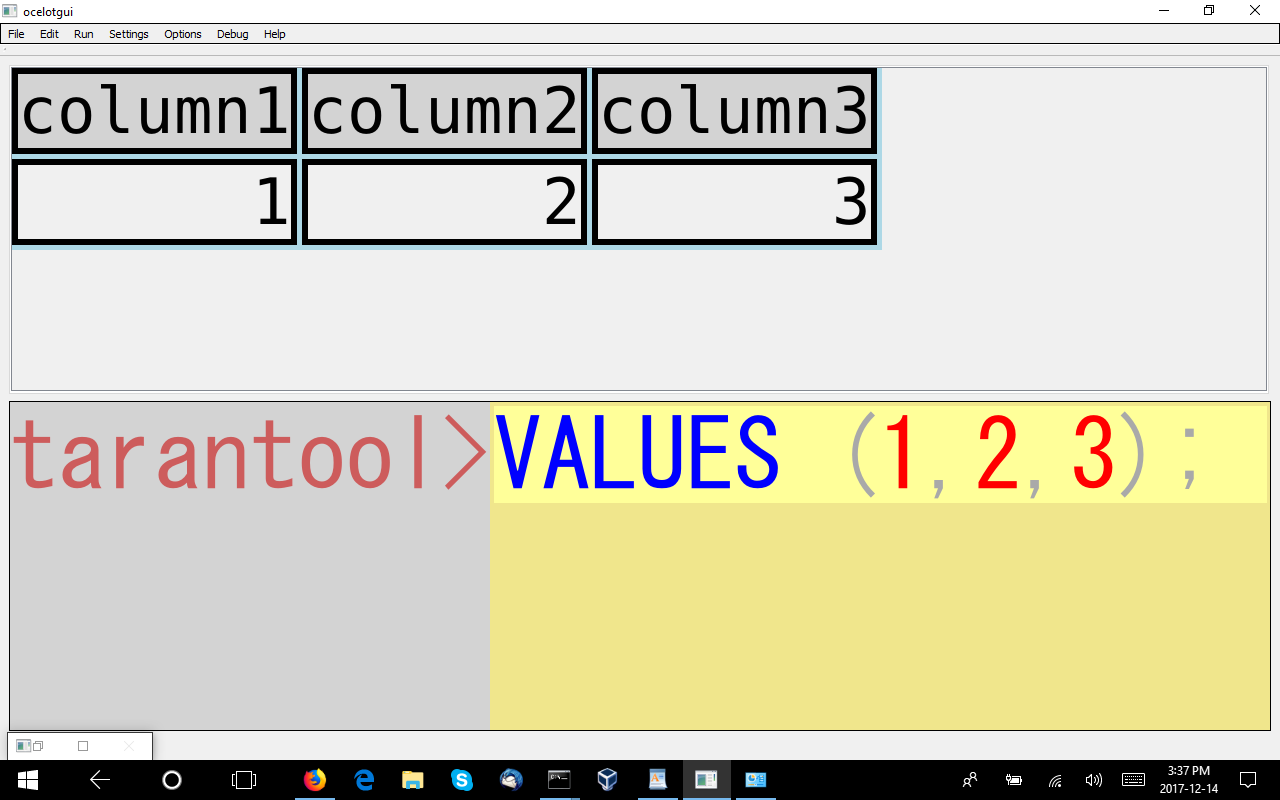
This means: return a result set containing a row with three columns containing 1, 2, 3. MySQL and MariaDB have a non-standard way to do this:
SELECT 1,2,3;
I like the logic of VALUES and the fact that I can say
VALUES (1,2,3),(4,5,6);
but Tarantool also supports the MySQL/MariaDB way, and I expect that it will always be more popular.
Game Changer?
Tarantool’s aiming high and Tarantool’s owner has a $9-billion market cap so the resources are there, but I’m not sure that Oracle sees them on its threat radar just yet. Tarantool SQL is not a drop-in replacement for all the code you’ve written for Oracle or MySQL/MariaDB, and the distinguishing features that I’ve mentioned are only going to cause a few people to migrate, at least in 2018. Other people will use Tarantool as an “add-on” or “engine”.
I do see that this is close enough to SQLite that it will probably be reasonable to switch from there, if people need the extra multi-user / replication capabilities and the Lua integration and the speed (the main engine is an in-memory DBMS).
More dimly, I see some other NoSQL DBMSs looking bad compared to Tarantool because their SQL support is trivial by comparison. I’m thinking especially of the ones that already get beaten by Tarantool in YCSB tests of NoSQL performance.
Tarantool’s licence is BSD.
Alphas Are Not Betas
Everything I’ve described above might change before Tarantool SQL is ready for use in production.
If you want to try to replicate the examples exactly, start with the old version-1.7 manual, move up to the SQL tutorial for version-1.8. The ocelotgui client additional instructions for connecting to Tarantool are here.
UPDATE: Tarantool’s SQL feature is now part of Tarantool 2.1 instead of Tarantool 1.8. The SQL tutorial is now here. The instructions for connecting ocelotgui to Tarantool are the same as before, except for the change in version number. Tarantool 2.1 is beta.
UPDATE: ocelotgui support for Tarantool was greatly enhanced after this post was written. See https://github.com/ocelot-inc/ocelotgui-tarantool.
The SQL Standard is SQL:2016
Now the words “SQL Standard” mean ISO/IEC 9075 Information technology — Database languages — SQL … 2016″ or more briefly SQL:2016. I am no longer a member of the committee, I don’t have the latest copy, but I believe these are the notable changes.
The LIST_AGG function
The example I’ve seen (credit to Markus Winand) is
SELECT grp, LIST_AGG(val, ',') WITHIN GROUP (ORDER BY val) FROM t ORDER BY grp;
and the result is supposed to be: take each “val” value and concatenate it with the previous one, separating by “,” as specified.
Notice a similarity to GROUP_CONCAT() in MySQL/MariaDB
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
So I think we can say this is functionally equivalent to SQL:2016, it would just have to be tweaked a bit to be exactly equivalent.
Polymorphic Table Functions
You’ve probably heard of “flexible schemas” as opposed to “fixed schemas”. To me it means the name and the data type can accompany the data instead of being fixed by the CREATE TABLE statement. You still need to figure out the metadata when you retrieve, though, so a Polymorphic Table Function (PTF) is one way of doing so. The functions have to be user-defined. I’m not in love with PTFs, but I keep putting off my description of a better idea.
JSON
I talked about JSON with respect to MySQL in a previous post.
The news I have seen subsequently is that MariaDB 10.2 has some JSON functions but I can’t say yet whether they’re better than MySQL’s implementation.
Meanwhile Oleg Bartunov is working on a JSON change for PostgreSQL,
and explicitly referencing SQL:2016.
Advantage PostgreSQL.
Row Pattern Matching
I think the main thing here is that the Oracle-like MATCH_RECOGNIZE is coming in. It’s vaguely related to the windowing functions, and MariaDB is way ahead of MySQL with respect to windowing functions, so if this feature ever appears I’d expect it to appear first in MariaDB.
Temporal Tables
Actually the big temporal things were introduced in SQL:2011, but clarifications came subsequently, so I could count this as a “post-2011 standard feature”. In this respect I see that MariaDB intends to add AS OF / temporal tables” based apparently on the work of Alexander Krizhanovsky, and Mr Krizhanovsky has talked about those clarifications — so I think we can hope for system versioning or something like it soon.
Sequences
What sequences are, who supports them, and why they’re better than GUIDs or auto-increment columns except when they aren’t.
What sequences are
When I say “sequence” I actually mean “sequence generator” because that’s what SQL’s CREATE SEQUENCE statement actually creates. So a sequence is a black box that produces an integer with a guarantee that this integer is greater than the previous integer that it produced, and less than the next integer that it will produce. Thus if I invoke it five times I might get 2, 4, 5, 6, 7. In poker that wouldn’t be considered a sequence because there’s a gap between 2 and 4. We can make sequences with few gaps or no gaps, but they’re expensive.
Sequences are good for generating unique keys, although they’re not the only tool for that.
How they work
This is the minimal scenario with a good DBMS.
An administrator says “create sequence x”, with most things default: start with 1, go up by 1, cache 20.
A user says “get the next value from x”.
The server grabs the numbers between 1 and 20. It writes to a log: “last grab value = 20”. It saves in memory: 1 number is used, 19 remain in the cache. The user gets a number: 1.
A user says “get the next value from x”. The server does not need to grab more numbers or write to a log. It saves in memory: 2 numbers are used, 18 remain in the cache. The user gets a number: 2.
This continues until there are no more numbers left in the cache — at that point the server does another “grab” and another “log write”, then proceeds with a new cache.
Ordinarily the process needs some mutexes but not DBMS locks, although some DBMS vendors like to maintain an in-memory system table that contains the highest value for user convenience. So sequence overhead might be cheap compared to the overhead of maintaining a persistent table with an auto-increment column.
There are two reasons that there will be gaps:
(1) because once a value is retrieved it’s gone, so ROLLBACK won’t cause the sequence generator to put a number back
(2) because a crash can happen any time after the grab, and when the server restarts it will use the last value written to the log, so up to 20 numbers can be left unused. Of course a different cache size would mean a different number of possible unused, or “burnt”, numbers.
Who supports them
In the table below, the left column has pieces of a CREATE SEQUENCE statement, the other columns show which DBMSs support it.
CREATE ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL [OR REPLACE] DB2 Syb [ TEMPORARY | TEMP ] Pos SEQUENCE ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL [IF NOT EXISTS] Inf Pos sequence-name ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL [AS data type] ANS DB2 HSQ Ing SQL [START WITH n] ANS DB2 HSQ Inf Ing Ora Pos Syb SQL [ INCREMENT BY n ] ANS DB2 HSQ Inf?Ing Ora Pos Syb SQL [ NO MINVALUE | MINVALUE n ] ANS DB2 Inf Ora Pos Syb SQL [ NO MAXVALUE | MAXVALUE n ] ANS DB2 Inf Ing Ora Pos Syb SQL [ NO CYCLE | CYCLE ] ANS DB2 Inf Ing Ora Pos Syb SQL [ NO CACHE | CACHE n ] DB2 Inf Ing Ora Pos Syb SQL [ OWNED BY column-name } ] Pos [ ORDER | NOORDER ] Ora [ KEEP | NOKEEP ] Ora [ SESSION | GLOBAL ] Ora [ SEQUENTIAL | UNORDERED] Ing
ANS = ANSI/ISO 9075-2 (the SQL:2011 standard) with optional feature T176 “external sequence generator”
DB2 = IBM DB2 for LUW
Fir = Firebird
HSQ = HSQLDB
Inf = Informix
Ing = Ingres
Ora = Oracle
Pos = PostgreSQL
Syb = Sybase IQ (not Sybase ASE)
SQL = Microsoft SQL Server
Example statement:
CREATE SEQUENCE x_seq AS DECIMAL(20) START WITH -1000000 CACHE 1000;
The chart doesn’t show some trivial variations, for example some DBMSs allow NOMAXVALUE along with or instead of NO MAXVALUE, and in some DBMSs WITH or n can be optional.
I believe that clauses like START WITH, INCREMENT BY, MIN[IMUM]VALUE have obvious meanings. The truly significant ones are [AS data-type] and CACHE.
[ AS data-type ]: this is the only clause that’s not supported by all three of the Big Three: DB2 and SQL Server have it but Oracle doesn’t. Oracle just says there are up to 28 digits. INTEGER (+ or minus 2 billion) might be enough, but if you do a billion “next value” calculations in a day, you’d run out of numbers in (4294967295 / 1000000000) = 4 days.
[CACHE n]: this is not an ANSI clause because it’s strictly for performance, and for an idea of how important it is I’ll quote IBM developerWorks:
“The main performance issue to be aware of for identity and sequence is that, for recoverability reasons, generated values must be logged. To reduce the log overhead, the values can be pre-reserved (cached), and one log record is written each time the cache is exhausted. … As the results of tests 41-51 in Appendix A show, not having a cache is extremely costly (almost nine times slower than the default).”
NEXT VALUE
The operation for “get next value” is NEXT VALUE FOR sequence-name. Some DBMSs shorten it to NEXTVAL and some DBMSs allow for “getting current value” or “getting previous value” i.e. repeating the NEXT VALUE result. But the main things to know are:
The DBMS increments once per row, not once per time that the DBMS sees “next value”. This is remarkable, because it’s not how a function invocation would work. In this respect PostgreSQL is non-standard, because it will increment every time it sees “next value”.
There is no race-condition danger for “getting current value”. User #1 does not see the number that User #2 gets, because it’s stored within the session memory not global memory.
Getting from a sequence is certainly not deterministic, and is usually disallowed for some operations that would require “next value” to come up often. Oracle disallows it with DISTINCT, ORDER BY, GROUP BY, UNION, WHERE, CHECK, DEFAULT, subqueries, and views; other DBMSs are more easygoing.
You’ll want to find out what you’re inserting. The simple way is to get the next value first into a variable, then insert it:
SET x = NEXT VALUE FOR x_seq;
INSERT INTO t VALUES (x, …)
but that involves two trips to the server. If possible, one wants to do the database operation and return the next value to the user, all via one statement, as in the SQL:2011 non-core (optional) feature T495 “Combined data change and retrieval”. Unfortunately (I’ve decried this heresy before), you’ll often see this done with UPDATE … RETURNING.
The GUID alternative
If I just want a unique number, why don’t I get the client or the middleware to generate a GUID for me? First let me state what’s good.
* Zero locks and zero log writes.
* A GUID has a 122-bit number. No, not a 128-bit number because there are a few bytes for version number and for future purposes. No, we can’t hope that there will be even distribution across the range so 2**122 is a dream. But (2**122) = 5.316912e+36, so the chances of generating duplicate numbers is still estimated as: not in this lifetime.
* So what if there’s a duplicate? If you’re generating a GUID for the sake of a surrogate key, then it will get inserted in a unique index, and so there will be a nice clean error message if the same value reappears.
Now this is what’s bad.
* GUIDs are long. It’s not just a difference between 128 bits and 64 bits, because serial numbers start at small numbers like ‘1’, while GUIDs are always long strings when you print them out. Not only does this mean that end-users wouldn’t want to be subjected to them, it means that they’d take more space to store. And, if they’re used for primary keys of an index-organized table, they might form part of secondary keys, so the extra space is being consumed more than once.
Therefore it’s not a settled matter. But people do prefer sequences for the other main reason: despite their problems, they’re generally sequential.
The IDENTITY alternative
The other way to get a sequence is to define a column as IDENTITY, or some close equivalent such as PRIMARY KEY AUTO_INCREMENT.
Clearly, SEQUENCE is better when the same generated value is useful for multiple tables, or for no tables. But what about the common situation where the generated value has something to do with a single column in a single table — then maybe IDENTITY is better for performance reasons.
I recently encountered a good insult: “You’re not stupid, you just have bad luck when you think.” Here is an example of thinking. See if you can spot the bad luck.
“The DBMS is going to generate a number as a primary key. Primary keys have B-tree indexes. The NEXT VALUE will be the current largest value, plus one. That value is in the last page of the index. I have to read that page anyway, because that’s where I’m going to add the key for the NEXT VALUE that I’m INSERTing. Therefore the overhead of using IDENTITY is negligible.”
Did you have any trouble spotting that that is not true, because the largest value might have been DELETEd? An identity value must not be re-used! Therefore there is a bit of overhead, to store what was the maximum value for all time, separately.
(Incidental note: MySQL and MariaDB and Oracle Rdb and SQL Server 2012 unfortunately do destroy the maximum auto_increment value when I say TRUNCATE TABLE. But DBMSs like DB2 for i will by default preserve the maximum IDENTITY-column value, as the SQL standard requires.)
People have compared IDENTITY versus SEQUENCE performance. On SQL Server 2012 one tester found that identity is always better but another tester found that sequence catches up when cache size = 100,000. On Oracle 12c a tester found that sequences took 26 seconds while identities took 28 seconds. On DB2 a tester found that “Identity performs up to a few percent better.” Averaging the results: it depends.
And it’s not necessarily a GUID versus SEQUENCE versus AUTO_INCREMENT contest. There are lots of ways that users can make their own unique values, with timestamps and branch-identifiers and moon phases. They’re not standardized, though, so I leave such ideas as exercises for readers who think they can do better.
Bottlenecks
The two things you want to avoid are hot spots and cache misses. Choose any one.
A hot spot is caused when multiple users are all trying to modify the same index pages. That’s inevitable if User #1 gets value 123456, User #2 gets value 123457, and User #3 gets value 123458. Naturally those will probably fall on the same page, and so cause contention. The solution is to hash or reverse the number before writing.
A cache miss is caused when multiple users are not all reading the same index pages. If they were, then the chances would be high that the page you want would be in the cache, and you’d save a disk read. The situation can arise when everybody needs to access a group of rows that were put in around the same time, for example “rows inserted today”. The solution is to not hash or reverse the number before writing.
Gaps
The easiest way to reduce gaps is to say CACHE 0 or NO CACHE when you create the sequence. As we’ve seen, this has bad effects on performance, so do it only when you have some rule saying “no gaps” (read “Gapless sequences” for an example due to German tax laws). It’s likely that you’ll still have something that’s faster than a separate auto-incrementing table.
Or you can try to plug the gaps after they’re made. Itzak ben-Gan wrote a few tips about that, and so did Baron Schwartz.
Hey, What about MySQL and MariaDB?
In 2003 in MySQL Worklog Task #827 I explained: “In the Bordeaux group leaders’ meeting (November 2003), “Oracle-type sequences” was specified as an item for version 5.1.” You can judge how well that came out.
MariaDB’s worklog task 10139 is somewhat more current — there’s an assignee and there’s recent activity. I’m dubious about the proposed plan, it specifies very little and it’s something involving a read-uncommitted table that contains the latest high number, and then the dread words appear “see [URL of postgresql.org documentation] for details”. However, plans often change.
Unless I’m behind the times, I predict that MySQL or MariaDB would have a problem imitating Oracle’s GRANT SEQUENCE (a separate privilege that only affects sequences). Making a new privilege is still hard, I believe.
When or if the syntax changes, our GUI client for MySQL and MariaDB will of course be updated to recognize it.
See also
My old DBAzine article “Sequences and identity columns” is still mostly valid.
Pronouncing Database Terms
It is the business of educated people to speak so that no-one may be able to tell in what county their childhood was passed. — A. Burrell, A Handbook for Teachers in Public Elementary School, 1891
The terms that reveal where a person (mis)spent a DBMS-related childhood are “char”, “data”, “GIF”, “gigabyte”, “GUI”, “JSON”, “query”, “schema”, “tuple”, “_”, “`”, and “«”.
CHAR
(1) Like “Care” because it’s short for “Character” (so hard C and most folks say “Character” that way)?
(2) Like “Car” because it’s short for “Character” (so hard C and a few folks in the British Isles say it that way and perhaps all other English words ending in consonant + “ar” are pronounced that way)?
(3) Like “Char” (the English word for a type of trout)?
C/C++ programmers say (3), for example Bjarne Stroustrup of C++ fame says that’s illogical but usual. However, people who have not come to SQL from another programming language may be more likely to go with (2), leading one online voter to exclaim “I’ve known a lot of people who say “car” though. (Generally SQL-y people; is this what they teach in DBA classes?)” and Tom Kyte of Oracle fame reportedly says “var-car” .
DATA
The Oxford English Dictionary (OED) shows 4 (four!) variations:
“Brit. /ˈdeɪtə/, /ˈdɑːtə/, U.S. /ˈdædə/, /ˈdeɪdə/”.
It’s only the first syllable that matters — DAY or DA?
I haven’t seen the Longman Pronunciation Dictionary, but a blog post says the results of Longman’s preference poll were:
“BrE: deɪtə 92% ˈdɑːtə 6% ˈdætə 2% AmE: ˈdeɪțə 64%ˈdæțə 35% ˈdɑːțə 1%” (notice it’s ț not t for our American friends). By the way OED says in a computing context it’s “as a mass noun” so I guess “data is” is okay.
GIF
It’s “jif”, says its creator.
GIGABYTE
That letter at the start is a hard G; The “Jigabyte” pronunciation is unknown to Merriam-Webster, Cambridge, and Oxford dictionaries.
GUI
No question it’s “gooey”, for all the dictionaries I checked. So pronounce our product as “osselot-goey”“osselot-gooey”.
GUID
The author of “Essential COM” says
The exact pronunciation of GUID is a subject of heated debate among COM developers. Although the COM specification says that GUID rhymes with fluid, the author [Don Box] believes that the COM specification is simply incorrect, citing the word languid as setting the precedent.
The COM specification is a standard and therefore cannot be incorrect, but I can’t find it, and I like setting-a-precedent games, so let’s use the exact word Guid, eh? It appears in Hugh MacDiarmid’s masterpiece “A Drunk Man Looks At The Thistle”
But there are flegsome deeps
Where the soul o’Scotland sleeps
That I to bottom need
To wauk Guid kens what deid
.. which proves that Guid is a one-syllable word, though doubtless MacDiarmid pronounced it “Gweed”.
JSON
Doug Crockford of Yahoo fame, seen on Youtube, says:
So I discovered JAYsun. Java Script Object Notation. There’s a lot of argument about how you pronounce that. I strictly don’t care. I think probably the correct pronunciation is [switching to French] “je sens”.
The argument is mostly between people who say JAYsun and people who say JaySAWN. It’s controversial, and in our non-JSON environment it’s a foreign word, so spelling it out J S O N is safe and okay.
QUERY
In the 1600s the spelling was “quaery”, so it must have rhymed with “very”, and it still does, for some Americans. But the OED says that both American and British speakers say “QUEERie” nowadays.
SCHEMA
It’s “Skema”. The “Shema” pronunciation is unknown to Merriam-Webster, Cambridge, and Oxford dictionaries.
SQL
See the earlier post “How to pronounce SQL” which concluded:
In the end, then, it’s “when in Rome do as the Romans do”. In Microsoft or Oracle contexts one should, like Mr Ellison, respect Microsoft’s or Oracle’s way of speaking. But here in open-source-DBMS-land the preference is to follow the standard.
TUPLE
See the earlier post “Tuples”. It’s “Tuhple”.
_
According to Swan’s “Practical English Usage” the _ (Unicode code point 005F) character is more often called underline by Britons, more often called underscore by Americans. (The SQL-standard term is underscore.) (The Unicode term is LOW LINE; SPACING UNDERSCORE was the old Unicode-version-1.0 term.)
` `
This is a clue for telling if people have MySQL backgrounds — they’ll pronounce the ` (Unicode code point 0060) symbol as “backtick”. Of course it also is found in other programming contexts nowadays, but there are lots of choices in the Jargon File:
Common: backquote; left quote; left single quote; open quote;
; grave. Rare: Backprime; [backspark]; unapostrophe; birk; blugle; back tick; back glitch; push; ; quasiquote.
By the way The Jargon File is a good source for such whimsical alternatives of ASCII names.
« »
You might be fooled by an Adobe error, as I was, into thinking that these French-quote-mark thingies are pronounced GEELmoes. Wrong. They are GEELmays. (The Unicode term is left-point or right-point double angle quotation marks.) This matter matters because, as Professor Higgins said, “The French don’t care what they do actually, as long as they pronounce it properly.”
Meanwhile …
Enhancements made to the source code for the next version of ocelotgui, Ocelot’s Graphical User Interface for MySQL and MariaDB, are: error messages are optionally in French, and grid output is optionally in HTML. As always, the description of the current version is on ocelot.ca and the downloadable source and releases are on github.
SQLite and Standard SQL
I’m going to need to use SQLite syntax for a project that I’m involved with, and predictably I wonder: how standard is it? The SQLite folks themselves make modest claims to support most of the features with a special focus on SQL-92, but (a) I like to do my own counting (b) there’s no official standard named SQL-92 because it was superseded 17 years ago.
By ignoring SQL-92 claims I eschew use of the NIST test suite. I’ll be far less strict and more arbitrary: I’ll go through SQL:2011’s “Feature taxonomy and definition for mandatory features”. For each feature in that list, I’ll come up with a simple example SQL statement. If SQLite appears to handle the example, I’ll mark it “Okay”, else I’ll mark it “Fail”. I’m hoping that arbitrariness equals objectivity, because the unfair pluses should balance the unfair minuses.
Skip to the end of this blog post if you just want to see the final score.
Standard SQL Core Features, Examples, and Okay/Fail Results
E-011 Numeric data types
E-011-01 INTEGER and SMALLINT
Example: create table t (s1 int);
Fail. A numeric column can contain non-numeric strings. There is a similar flaw for all data types, but let’s count them all as only one fail.
E-011-02 REAL, DOUBLE PRECISION,and FLOAT data types
Example: create table tr (s1 float);
Okay.
E-011-03 DECIMAL and NUMERIC data types
Example: create table td (s1 numeric);
Okay, although: when there are many post-decimal digits there is a switch to exponential notation, for example after “insert into t3 values (0.0000000000000001);” and “select *from t3” I get “1.0e-16”. I regard this as a display flaw rather than a fail.
E-011-04 Arithmetic operators
Example: select 10+1,9-2,8*3,7/2 from t;
Okay. SQLite is wrong to calculate that 7/0 is NULL, though.
E-011-05 Numeric comparison
Example: select * from t where 1 < 2;
Okay.
E-011-06 Implicit casting among the numeric data types
Example: select * from t where s1 = 1.00;
Okay, but only because SQLite doesn’t distinguish etween numeric data types.
E021 Character string types
E-021-01 Character data type (including all its spellings)
Example: create table t44 (s1 char);
Okay, but only because SQLite accepts any definition that includes the word ‘CHAR’, for example CREATE TABLE t (s1 BIGCHAR) is okay although there’s no such data type. There are no checks on maximum length, and no padding for insertions with less than the maximum length.
E021-02 CHARACTER VARYING data type (including all its spellings)
Example: create table t45 (s1 varchar);
Okay, but the behaviour is exactly the same as for CHARACTER.
E021-03 Character literals
Example: insert into t45 values (”);
Okay, and the bad practice of accepting “”s for character literals is avoided.Even hex notation, for example X’41’, is okay.
E021-04 CHARACTER_LENGTH function
Example: select character_length(s1) from t;
Fail. There is no such function. There is a function LENGTH(), which is okay.
E021-05 OCTET_LENGTH
Example: select octet_length(s1) from t;
Fail. There is no such function.
E021-06 SUBSTRING function.
Example: select substring(s1 from 1 for 1) from t;
Fail. There is no such function. There is a function SUBSTR(x,n,n) which is okay.
E021-07 Character concatenation
Example: select ‘a’ || ‘b’ from t;
Okay.
E021-08 UPPER and LOWER functions
Example: select upper(‘a’),lower(‘B’) from t;
Okay. It does not work well out of the box, but I loaded the ICU extension.
E021-09 TRIM function
Example: select trim(‘a ‘) from t;
Okay.
E021-10 Implicit casting among the fixed-length and variable-length character string types
Example: select * from tm where char_column > varchar_column;
Okay, but only because SQLite doesn’t distinguish between character data types.
E021-11 POSITION function
Example; select position(x in y) from z;
Fail. There is no such function.
E021-02 Character comparison
Example: select * from t where s1 > ‘a’;
Okay. I should note here that comparisons are case sensitive, and it is devilishly hard to change this except with ASCII,but case insensitivity is not a requirement for this feature.
E031 Identifiers
E031-01 Delimited
Example: create table “t47” (s1 int);
Fail. Although I can enclose identifiers inside double quotes, that doesn’t make them case sensitive.
E031-02 Lower case identifiers
Example: create table t48 (s1 int);
Okay.
E031-03 Trailing underscore
Example: create table t49_ (s1 int);
Okay.
E051 Basic query specification
E051-01 SELECT DISTINCT
Example: select distinct s1 from t;
Okay.
E051-02 GROUP BY clause
Example: select distinct s1 from t group by s1;
Okay.
E051-04 GROUP BY can contain columns not in select list
Example: select s1 from t group by lower(s1);
Okay.
E051-05 select list items can be renamed
Example: select s1 as K from t order by K;
Okay.
E051-06 HAVING clause
Example: select s1,count(*) from t having s1 < 'b';
Fail. GROUP BY is mandatory before HAVING.
If I hadn’t happened to omit GROUP BY, it would have been okay.
E051-07 Qualifie d * in select list
Example: select t.* from t;
Okay.
E051-08 Correlation names in the FROM clause
Example: select * from t as K;
Okay.
E051-09 Rename columns in the FROM clause
Example: select * from t as x(q,c);
Fail.
E061 Basic predicates and search conditions
E061-01 Comparison predicate
Example: select * from t where 0 = 0;
Okay. But less correct syntax would work too, for example “where 0 is 0”.
E061-02 BETWEEN predicate
Example: select * from t where ‘ ‘ between ” and ‘ ‘;
Okay.
E061-03 IN predicate with list of values
Example: select * from t where s1 in (‘a’,upper(‘a’));
Okay.
E061-04 LIKE predicate
Example: select * from t where s1 like ‘_’;
Okay.
E061-05 LIKE predicate: ESCAPE clause
Example: select * from t where s1 like ‘_’ escape ‘_’;
Okay.
E061-06 NULL predicate
Example: select * from t where s1 is not null;
Okay.
E061-07 Quantified comparison predicate
Example: select * from t where s1 = any (select s1 from t);
Fail. Syntax error.
E061-08 EXISTS predicate
Example: select * from t where not exists (select * from t);
Okay.
E061-09 Subqueries in comparison predicate
Example: select * from t where s1 > (select s1 from t);
Fail. There was more than one row in the subquery result set, but SQLite didn’t return an error.
E061-11 Subqueries in IN predicate
Example: select * from t where s1 in (select s1 from t);
Okay.
E061-12 Subqueries in quantified comparison predicate
Example: select * from t where s1 >= all (select s1 from t);
Fail. Syntax error.
E061-13 Correlated subqueries
Example: select * from t where s1 = (select s1 from t2 where t2.s2 = t.s1);
Okay.
E061-14 Search condition
Example: select * from t where 0 <> 0 or ‘a’ < 'b' and s1 is null;
Okay.
E071 Basic query expressions
E071-01 UNION DISTINCT table operator
Example: select * from t union distinct select * from t;
Fail. However, “select * from t union select * from t;” is okay.
E071-01 UNION ALL table operator
Example: select * from t union all select * from t;
Okay.
E071-03 EXCEPT DISTINCT table operator
Example: select * from t except distinct select * from t;
Fail. However, “select * from t except select * from t;” is okay.
E071-05 Columns combined via table operators need not have exactly the same data type.
Example: select s1 from t union select 5 from t;
Okay, but only because SQLite doesn’t distinguish data types very well.
E071-06 Table operators in subqueries
Example: select * from t where ‘a’ in (select * from t union select * from t);
Okay.
E081 Basic privileges
E081-01 Select privilege at the table level
Fail. Syntax error. (SQLite doesn’t support privileges.)
E081-02 DELETE privilege
Fail. (SQLite doesn’t support privileges.)
E081-03 INSERT privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-04 UPDATE privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-05 UPDATE privilege at column level
Fail. (SQLite doesn’t support privileges.)
E081-06 REFERENCES privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-07 REFERENCES privilege at column level
Fail. (SQLite doesn’t support privileges.)
E081-08 WITH GRANT OPTION
Fail. (SQLite doesn’t support privileges.)
E081-09 USAGE privilege
Fail. (SQLite doesn’t support privileges.)
E081-10 EXECUTE privilege
Fail. (SQLite doesn’t support privileges.)
E091 Set functions
E091-01 AVG
Example: select avg(s1) from t7;
Fail. No warning that nulls were eliminated.
E091-02 COUNT
Example: select count(*) from t7 where s1 > 0;
Okay.
E091-03 MAX
Example: select max(s1) from t7 where s1 > 0;
Okay.
E091-04 MIN
Example: select min(s1) from t7 where s1 > 0;
Okay.
E091-05 SUM
Example: select sum(1) from t7 where s1 > 0;
Okay.
E091-06 ALL quantifier
Example: select sum(all s1) from t7 where s1 > 0;
Okay.
E091-07 DISTINCT quantifier
Example: select sum(distinct s1) from t7 where s1 > 0;
Okay.
E101 Basic data manipulation
E101-01 INSERT statement
Example: insert into t (s1) values (”),(null),(55);
Okay.
E101-03 Searched UPDATE statement
Example: update t set s1 = null where s1 in (select s1 from t2);
Okay.
E01-04 Searched DELETE statement
Example: delete from t where s1 in (select s1 from t);
Okay.
E111 Single row SELECT statement
Example: select count(*) from t;
Okay.
E121 Basic cursor support
E121-01 DECLARE CURSOR
Fail. SQLite doesn’t support cursors.
E121-02 ORDER BY columns need not be in select list
Example: select s1 from t order by s2;
Okay. Update on 2016-06-27: Originally I wrongly said “Fail”, see the comments.
E121-03 Value expressions in select list
Example: select s1 from t7 order by -s1;
Okay.
E121-04 OPEN statement
Fail. SQLite doesn’t support cursors.
E121-06 Positioned UPDATE statement
Fail. SQLite doesn’t support cursors.
E121-07 Positioned DELETE statement
Fail. SQLite doesn’t support cursors.
E121-08 CLOSE statement
Fail. SQLite doesn’t support cursors.
E121-10 FETCH statement implicit next
Fail. SQLite doesn’t support cursors.
E121-17 WITH HOLD cursors
Fail. SQLite doesn’t support cursors.
E131 Null value support (nulls in lieu of values)
Example: select s1 from t7 where s1 is null;
Okay.
E141 Basic integrity constraints
E141-01 NOT NULL constraints
Example: create table t8 (s1 int not null);
Okay.
E141-02 UNIQUE constraints of NOT NULL columns
Example: create table t9 (s1 int not null unique);
Okay.
E141-03 PRIMARY KEY constraints
Example: create table t10 (s1 int primary key);
Okay, although SQLite wrongly assumes s1 is auto-increment.
E141-04 Basic FOREIGN KEY constraint with the NO ACTION default for both referential delete action and referential update action.
Example: create table t11 (s1 int references t10);
Fail. The foreign-key check will only be checked when I have said “pragma foreign_keys = on;”.
E141-06 CHECK constraints
Example: create table t12 (s1 int, s2 int, check (s1 = s2));
Okay.
E141-07 Column defaults
Example: create table t13 (s1 int, s2 int default -1);
Okay.
E141-08 NOT NULL inferred on primary key
Example: create table t14 (s1 int primary key);
Fail. I am able to insert NULL if I don’t explicitly say the column is NOT NULL.
E141-10 Names in a foreign key can be specified in any order
Example: create table t15 (s1 int, s2 int, primary key (s1,s2));
create table t16 (s1 int, s2 int, foreign key (s2,s1) references t15 (s1,s2));
Okay.
E151 Transaction support
E151-01 COMMIT statement
Example: commit;
Fail. I have to say BEGIN TRANSACTION first.
E151-02 ROLLBACK statement
Example: rollback;
Okay.
E152 Basic SET TRANSACTION statement
E152-01 SET TRANSACTION statement ISOLATION SERIALIZABLE clause
Example: set transaction isolation level serializable;
Fail. Syntax error.
E152-02 SET TRANSACTION statement READ ONLY and READ WRITE clauses
Example: set transaction read only;
Fail. Syntax error.
E153 Updatable queries with subqueries
E161 SQL comments using leading double minus
Example: –comment;
Okay.
E171 SQLSTATE suport
Example: drop table no_such_table;
Fail. At least, the error message doesn’t hint that SQLSTATE exists.
E182 Host language binding
Okay. The existence of shell executable proves there is a C binding.
F031 Basic schema manipulation
F031-01 CREATE TABLE statement to create persistent base tables
Example: create table t20 (t20_1 int not null);
Okay.
F031-02 CREATE VIEW statement
Example: create view t21 as select * from t20;
Okay.
F031-03 GRANT statement
Fail. SQLite doesn’t support privileges.
F031-04 ALTER TABLE statement: add column
Example: alter table t7 add column t7_2 varchar default ‘q’;
Okay.
F031-14 DROP TABLE statement: RESTRICT clause
Example: drop table t20 restrict;
Fail. Syntax error, and RESTRICT is not assumed.
F031-14 DROP VIEW statement: RESTRICT clause
Example: drop view v2 restrict;
Fail. Syntax error, and RESTRICT is not assumed.
F031-10 REVOKE statement: RESTRICT clause
Fail. SQLite does not support privileges.
F041 Basic joined table
F041-01 Inner join but not necessarily the INNER keyword
Example: select a.s1 from t7 a join t7 b;
Okay.
F041-02 INNER keyword
Example: select a.s1 from t7 a inner join t7 b;
Okay.
F041-03 LEFT OUTER JOIN
Example: select t7.*,t22.* from t22 left outer join t7 on (t22_1=s1);
Okay.
F041-04 RIGHT OUTER JOIN
Example: select t7.*,t22.* from t22 right outer join t7 on (t22_1=s1);
Fail. Syntax error.
F041-05 Outer joins can be nested
Example: select t7.*,t22.* from t22 left outer join t7 on (t22_1=s1) left outer join t23;
Okay.
F041-07 The inner table in a left or right outer join can also be used in an inner join
Example: select t7.* from t22 left outer join t7 on (t22_1=s1) inner join t22 on (t22_4=t22_5);
Okay. The query fails due to a syntax error but that’s expectable.
F041-08 All comparison operators are supported (rather than just =)
Example: select * from t where 0=1 or 0>1 or 0<1 or 0<>1;
Okay.
F051 Basic date and time
F051-01 DATE data type (including support of DATE literal)
Example: create table dates (s1 date);
Okay. (SQLite doesn’t enforce valid dates or times, but we’ve already noted that.)
F051-02 TIME data type (including support of TIME literal)
Example: create table times (s1 time default time ‘1:2:3’);
Fail. Syntax error.
F051-03 TIMESTAMP data type (including support of TIMESTAMP literal)
Example: create table timestamps (s1 timestamp);
Okay.
F051-04 Comparison predicate on DATE, TIME and TIMESTAMP data types
Example: select * from dates where s1 = s1;
Okay.
F051-05 Explicit CAST between date-time types and character string types
Example: select cast(s1 as varchar) from dates;
Okay.
F051-06 CURRENT_DATE
Example: select current_date from t;
Okay.
F051-07 CURRENT_TIME
Example: select * from t where current_time < '23:23:23';
Okay.
F051-08 LOCALTIME
Example: select localtime from t;
Fail. Syntax error.
F051-09 LOCALTIMESTAMP
Example: select localtimestamp from t;
Fail. Syntax error.
F081 UNION and EXCEPT in views
Example: create view vv as select * from t7 except select * from t15;
Okay.
F131 Grouped operations
F131-01 WHERE, GROUP BY, and HAVING clauses supported in queries with grouped views
Example: create view vv2 as select * from vv group by s1;
Okay.
F131-02 Multiple tables supported in queries with grouped views
Example: create view vv3 as select * from vv2,t30;
Okay.
F131-03 Set functions supported in queries with grouped views
Example: create view vv4 as select count(*) from vv2;
Okay.
F131-04 Subqueries with GROUP BY and HAVING clauses and grouped views
Example: create view vv5 as select count(*) from vv2 group by s1 having count(*) > 0;
Okay.
F181 Multiple module support
Fail. SQLite doesn’t have modules.
F201 CAST function
Example: select cast(s1 as int) from t;
Okay.
F221 Explicit defaults
Example: update t set s1 = default;
Fail. Syntax error.
F261 CASE expression
F261-01 Simple CASE
Example: select case when 1 = 0 then 5 else 7 end from t;
Okay.
F261-02 Searched CASE
Example: select case 1 when 0 then 5 else 7 end from t;
Okay.
F261-03 NULLIF
Example: select nullif(s1,7) from t;
Okay.
F261-04 COALESCE
Example: select coalesce(s1,7) from t;
Okay.
F311 Schema definition statement
F311-01 CREATE SCHEMA
Fail. SQLite doesn’t have schemas or databases.
F311-02 CREATE TABLE for persistent base tables
Fail. SQLite doesn’t have CREATE TABLE inside CREATE SCHEMA.
F311-03 CREATE VIEW
Fail. SQLite doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-04 CREATE VIEW: WITH CHECK OPTION
Fail. SQLite doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-05 GRANT statement
Fail. SQLite doesn’t have GRANT inside CREATE SCHEMA.
F471 Scalar subquery values
Example: select s1 from t where s1 = (select count(*) from t);
Okay.
F481 Expanded NULL Predicate
Example: select * from t where row(s1,s1) is not null;
Fail. Syntax error.
F812 Basic flagging
Fail. SQLite doesn’t support any flagging
S011 Distinct types
Example: create type x as float;
Fail. SQLite doesn’t support distinct types.
T321 Basic SQL-invoked routines
T321-01 User-defined functions with no overloading
Example: create function f () returns int return 5;
Fail. SQLite doesn’t support user-defined functions.
T321-02 User-defined procedures with no overloading
Example: create procedure p () begin end;
Fail. SQLite doesn’t support user-defined procedures.
T321-03 Function invocation
Example: select f(1) from t;
Fail. SQLite doesn’t support user-defined functions.
T321-04 CALL statement.
Example: call p();
Fail. SQLite doesn’t support user-defined procedures.
T321-05 RETURN statement.
Example: create function f() returns int return 5;
Fail. SQLite doesn’t support user-defined functions.
T631 IN predicate with one list element
Example: select * from t where 1 in (1);
Okay.
F031 Basic information schema.
Example: select * from information_schema.tables;
Fail. There is no schema with that name (not counted in the final score).
The Final Score
Fail: 59
Okay: 75
Update 2016-06-26: Originally I counted 60 to 74, that was an error.
So SQLite could claim to support most of the core features of the current standard, according to this counting method, after taking into account all the caveats and disclaimers embedded in the description above.
I anticipate the question, “Will ocelotgui (the Ocelot Graphical User Interface for MySQL and MariaDB) support SQLite too?” and the answer is “I don’t know.” The project would only take two weeks, but I have no idea whether it’s worth that much effort.
In the last while, I’ve concentrated on some ocelotgui bug fixes and on checking whether it runs on Windows as well as on Linux. It does, but only from source — see the instructions at https://github.com/ocelot-inc/ocelotgui/blob/master/windows.txt.
Comments in SQL Statements
First I will say what the comment syntax is for various vendors’ dialects. Then I will get specific about some matters that specifically affect MySQL or MariaDB.
Syntax Table
| DBMS | –… | /*…*/ | #… | Nesting | Hints |
|---|---|---|---|---|---|
| Standard | YES | YES | NO | YES | NO |
| Oracle 12c | YES | YES | NO | NO | YES |
| DB2 | YES | YES | NO | YES | NO |
| SQL Server | YES | YES | NO | YES | NO |
| PostgreSQL | YES | YES | NO | YES | NO |
| MySQL/MariaDB | YES(99%) | YES | YES | NO | YES |
The first column is for the type of DBMS. “Standard” is the ISO/IEC SQL standard document. For the others, just click on the DBMS name to see the relevant documentation. The standard, incidentally, clarifies that strings of comments are to be treated as a newline, so if you hear somebody say “comments are ignored”, that’s slightly wrong.
The first column is for comments that begin with “–” (two hyphen-minus signs), what the standard document calls “simple comments”, the ones that look like this:
SELECT * FROM t; -- SIMPLE COMMENT
Everyone supports simple comments, the only problem with MySQL/MariaDB is their insistence that the — must be followed by a space. I’ve had it explained to me that otherwise the parser had problems.
The second column is for comments enclosed by /* and */, what the standard document calls “bracketed comments”, the ones that look like this:
SELECT * FROM t; /* BRACKETED COMMENT */
According to the standard document, bracketed comments are not mandatory, they are optional feature T351. However, it would be surprising to find a modern SQL implementation that doesn’t support them.
The third column is for comments that begin with “#” (what Unicode calls Number Sign but an American dictionary allows for the word Octothorpe ), the ones that look like this:
SELECT * FROM t; # OCTOTHORPE COMMENT
Notice how, in every row but the MySQL/MariaDB row, the key word is NO? In fact I’ve only encountered one other SQL DBMS that is octothorpophiliac: mSQL. Old-timers may recall that mSQL from Hughes Technologies was, for a while, an inspiration for one of MySQL’s founders. Anyway, it’s unnecessary because simple comments do the job just as well.
The fourth column is for nesting, that is, putting bracketed comments within bracketed comments, that look like this:
SELECT * FROM t; /* OUTER /* INNER */ COMMENT */
I’ve often been irritated that I can’t nest in C, so I approve of the DBMSs that support this standard requirement. But I never saw it as important in my MySQL-architect days. There were a few what I guess could be categorized
as “feature requests” (here and here and here) and I approved of my colleagues’ clear responses, it’s low priority.
The final column is for hints. A hint is a bit of syntax that the server might ignore, signalled by an extra character or two in a bracketed comment, like this:
SELECT /*+ HINT COMMENT */ * FROM t;
Typically a hint is a suggestion for an optimizer, like “use index X instead of the default”. It’s found in Oracle; it’s not found in PostgreSQL and some PostgreSQL folks don’t like it; but it’s found in EnterpriseDB’s “advanced PostgreSQL”; and of course it’s found in MySQL and MariaDB. A newish point is that MariaDB has an extra signal “/*M!###### MariaDB-specific code */” that MySQL won’t recognize, which is a good thing since the optimizers have diverged somewhat.
Passing comments to the server
In the MySQL 5.7 manual we see the client has an interesting option:
–comments, -c
Whether to preserve comments in statements sent to the server. The default is –skip-comments (discard comments), enable with –comments (preserve comments).
and a good question is: huh? Surely we should preserve comments, especially in stored procedures, no? Well, the obvious answer is that the parser has to spend time skipping over them, but I doubt that the effect is significant nowadays. The better answer is merely that behaviour changes are serious so let’s leave this up to the users. Our GUI client supports –comments too, which is no surprise since we support all mysql-client options that make sense in a GUI.
But what happens if it’s hard to tell where comments belong? Buried in the source download is a file named mysql-test/t/mysql_comments.sql which is checking these questions:
* Ignore comments outside statements, on separate lines?
* Ignore comments at the end of statements, on the same line but after the semicolon?
* Ignore comments inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT, but not in the body?
The test should be updated now that compound statements in MariaDB don’t have to be inside CREATE PROCEDURE/FUNCTION/TRIGGER/EVENT.
Therefore
Steve McConnell’s “Code Complete” book advises: “A common guideline for Java and C++ that arises from a similar motivation is to use // synax for single-line comments and /* … */ syntax for larger comments.”
I guess that the equivalent for SQL purposes would be to say: use — for single-line comments and /* … */ for longer ones. But don’t use #, and be wary with standalone or endline comments, and turn –comments on.
Update
In an earlier blog post I predicted that ocelotgui, our GUI client for MySQL and MariaDB, would be beta in February. Now it’s February 29, so I have to modify that to: “any day now (watch this blog for updates or click Watch on the github project page)”. The latest feature additions are in the downloadable source code, by the way, but not in the binary release.
SQL qualified names
Bewilderedly behold this SQL statement:
SELECT * FROM a.b.c;
Nobody can know the meaning of “a.b.c” without knowing the terminology, the context, and the varying intents of various DBMS implementors.
The terminology
It’s pretty clear that a.b.c is a name, that is, a unique reference to an SQL object, which in this case is a table.
The name happens to be qualified — it has three parts separated by periods. A generalist would say that each part is a container, with the first part referring to the outermost container a, which contains b, which contains c. Analogies would be: a directory with a subdirectory and a sub-subdirectory, or an element within a struct within a struct.
That is true but incomplete. Now we fight about what kind of container each
identifier refers to, and what is the maximum number of levels.
What kind of container
The standard suggests that the levels are
[catalog.] [schema.] objectAnd here are the possible ways to do it:
1. Ignore catalog and schema, the only legal statement is “SELECT * FROM c;”, so c is a table name and there is no qualification. This is what happens in Firebird.
2. Ignore catalog, the legal statements are “SELECT * FROM b.c;” or “SELECT * FROM c;”, so b is a schema name, or the schema name is some default value (in MySQL/MariaDB this default value is specified by the USE statement, in standard SQL by the SET SCHEMA statement). In this case the schema identifier is the same as the database identifier. This is what happens in MySQL/MariaDB, and in Oracle. I am ignoring the fact that MySQL/MariaDB has a single catalog named def, since that has no practical use.
3. Ignore nothing, the legal statements are “SELECT * FROM a.b.c;” or “SELECT * FROM b.c;” or “SELECT * FROM c;”. The outermost (catalog) container is for a server. This is what happens in DB2.
4. There is a fourth level. This is what happens in SQL Server.
Naturally the variety causes trouble for JDBC or ODBC applications, which have to connect to any sort of DBMS despite the contradictory meanings. But when you’re connecting to the same DBMS every time, it can be okay.
The standard meaning of catalog
In SQL-99 Complete, Really — which is reproduced on mariadb.org — the idea of a catalog is expressed as a named container in an “SQL-environment”. Okay, but that leaves some uncertainty. We know that an SQL-environment can mean “the server and the client” or “the server as seen by the client”. And beyond that, we see the words “implementation-defined” because different vendors have different ideas.
The standard is neutral. Optional Feature F651 “Catalog name qualifiers” says simply that there can be a catalog identifier, there can be a “SET CATALOG ‘identifier’;” statement which has “no effect other than to set up default information”, there is no defined way to create a catalog (that is, there is no official analogue for CREATE SCHEMA), and the rest is up to the implementor.
The PostgreSQL idea is that the catalog is the cluster. The word “cluster” appears in database literature but it’s vague, it doesn’t have to mean “a group of servers connected to each other and known to each other which co-operate”. But that’s how PostgreSQL interprets, so “SELECT * FROM a.b.c;” implies “in cluster a, in which there is a schema b which should be uniquely defined within the cluster, there is a table c”.
The DB2 idea is that the catalog is the server, or an instance of the server. Presumably, if there’s only one server in a cluster, this would be the same as the PostgreSQL idea. So “SELECT * FROM a.b.c;” implies “in server a, in which there is a schema b, there is a table c”. This might be what C.J.Date was talking about when he wrote, in A Guide To The SQL Standard: “Or different catalogs might correspond to databases at different sites, if the SQL-environment involved some kind of distributed processing.” This also might be what the Hitachi manual is implying when it says a table can be qualified as node_name . authorization_identifier . table_name.
The Microsoft idea is pretty well the same thing, except that SQL Server considers “server” to be at the outermost (fourth) level.
Oracle, also, can specify a server in a table name; however, Oracle does it by appending rather than prefixing, for example “schema.table@database_link”.
In all cases the levels are separated by dots or at-signs, so it’s clear what the parts are. Astonishingly, there is a NoSQL DBMS that uses dot separators
but allows unquoted names to include dots(!); mercifully I’ve only seen this once.
Speaking of NoSQL, Apache Drill’s levels for a pseudo-table-name are plugin . workspace . location. That is an excellent way to specify what plugin to use, but I don’t see how it would work if there are two instances of a plugin.
Default schema name
The default schema name is typically implementation-defined when “the schema” is synonymous with “the database”. For example, MySQL and MariaDB say it’s null, but it’s common to start off by saying –database=test or “USE test”.
The default schema name can be the user name when the qualification is “table-qualifier . table-owner . table-name”. For example, if you log in as joe, then “SELECT * FROM t;” will be interpreted as “SELECT * FROM joe.t;”. This is becoming uncommon, but you’ll still see hints about it in old guides to ODBC, and in the Hitachi manual that I mentioned earlier.
The folks at Microsoft have an interesting BNF:
server . [catalog] . [schema] . table
| catalog . [schema] . table
| schema . table
| table
… which is not the same as the standard’s:
[catalog .] [schema .] table>
… See the difference? It means that one can leave catalog-name and schema-name blank if they’re default. So this is legal:
SELECT * FROM RemoteServer…t;
Alas, it’s easy to misread and think “[schema].table” is legal too. The MySQL manual is apparently alluding to that, but without trying to explain it, when it says: “The syntax .tbl_name means the table tbl_name in the default database. This syntax is accepted for ODBC compatibility because some ODBC programs prefix table names with a “.” character.”
Below the bottom level
What happens if an object has sub-objects? I don’t mean columns — it’s obvious that “SELECT x.y FROM t AS x;” assumes there’s a column y in table t — but I do mean partitions. As far as I know, nobody has partition identifiers within table names, although sometimes it’s okay to put them as hints after table names.
I also should mean sub-parts of columns, as one could find when (for example) the column is XML or JSON. But that’s a big enough subject for separate blog posts.
What is the use?
I was thinking of qualifiers when considering an enhancement to ocelotgui, our GUI client for MySQL and MariaDB. Suppose that one could have more than one DBMS connection. This isn’t possible with the regular mysql client, but we can go beyond it. So suppose we connect to two different DBMSs, or suppose we connect to the same DBMS twice. The first hurdle is that the usual parameters (–host, –port, –user, –password) are scalar, so we have to supplement them with new options, such as –connection2_host, –connection2_port, –connection2_user, –connection2_password. That’s easy, but now, if the user enters
SELECT * FROM b.c;
how do we know which connection the user wants to use, the one specified by –host or the one specified by –server2_host?
This could be done by saying “following statement is to be passed to connection X”, in a separate command or a menu choice. However, I rather like the idea of making catalog = server, so that “select * FROM b.c;” means send to the default server, “select * from server2.b.c;” means send to second server, and “USE server2.b” would change the default catalog as well as the default schema. This is easy and is all done by the client, so there’s no question it would work, the only thing to resolve is whether it’s a good idea.
Whatever happens, it will be in the next version of ocelotgui, along with a few bug fixes and other features. That next version will be 0.9, probably our first beta, in February 2016. But I do hope that people won’t wait — version 0.8 alpha is safe and good-looking and easy to download from github.
Standard SQL/JSON and MySQL 5.7 JSON
Support for storing and querying JSON within SQL is progressing for the ANSI/ISO SQL Standard, and for MySQL 5.7. I’ll look at what’s new, and do some comparisons.
The big picture
The standard document says
The SQL/JSON path language is a query language used by certain SQL operators (JSON_VALUE, JSON_QUERY, JSON_TABLE, and JSON_EXISTS, collectively known as the SQL/JSON query operators) to query JSON text.The SQL/JSON path language is not, strictly speaking, SQL, though it is embedded in these operators within SQL. Lexically and syntactically, the SQL/JSON path language adopts many features of ECMAScript, though it is neither a subset nor a superset of ECMAScript.The semantics of the SQL/JSON path language are primarily SQL semantics.
Here is a chart that shows the JSON-related data types and functions in the standard, and whether a particular DBMS has something with the same name and a similar functionality.
Standard Oracle SQL Server MySQL -------- ------ ---------- ----- Conventional data type YES YES NO JSON_VALUE function YES YES NO JSON_EXISTS function YES NO NO JSON_QUERY function YES YES NO JSON_TABLE function YES NO NO
My source re the standard is a draft copy of ISO/IEC 9075-2 SQL/Foundation. For Oracle 12c read Oracle’s whitepaper. For SQL Server 2016 read MSDN’s blog. My source re MySQL 5.7 is the MySQL manual and the latest source-code download of version 5.7.9.
Now, what is the significance of the lines in the chart?
Conventional data type
By “conventional”, I mean that in standard SQL JSON strings should be stored in one of the old familiar data types: VARCHAR, CLOB, etc. It didn’t have to be this way, and any DBMS that supports user-defined types can let users be more specific, but that’s what Oracle and Micosoft accept.
MySQL 5.7, on the other hand, has decided that JSON shall be a new data type. It’s closely related to LONGTEXT: if you say
CREATE TABLE j1 AS SELECT UPPER(CAST('{}' AS JSON));
SHOW CREATE TABLE j1;
then you get LONGTEXT. But if you use the C API to ask the data type, you get MYSQL_TYPE_JSON=245 (aside: this is not documented). And it differs because, if you try to put in non-JSON data, you get an error message.
At least, that’s the theory. It didn’t take me long to find a way to put non-JSON data in:
CREATE TABLE j2a (s1 INT, s2 JSON);
INSERT INTO j2a VALUES (1,'{"a": "VALID STUFF"}');
CREATE TABLE j2b AS SELECT s1, UPPER(s2) AS s2 FROM j2a;
INSERT INTO j2b VALUES (NULL, 'INVALID STUFF');
ALTER TABLE j2b MODIFY COLUMN s2 JSON;
… That unfortunately works, and now if I say “SELECT * FROM j2b;” I get an error message “The JSON binary value contains invalid data”. Probably bugs like this will disappear soon, though.
By making a new data type, MySQL has thrown away some of the advantages that come with VARCHAR or TEXT. One cannot specify a maximum size — everything is like LONGTEXT. One cannot specify a preferred character set and collation — everything is utf8mb4 and utf8mb4_bin. One cannot take advantage of all the string functions — BIN() gives meaningless results, for example. And the advantage of automatic validity checking could have been delivered with efficient constraints or triggers instead. So why have a new data type?
Well, PostgreSQL has a JSON data type. As I’ve noticed before, PostgreSQL can be a poor model if one wants to follow the standard. And it will not surprise me if the MariaDB folks also decide to make a JSON data type, because I know that they are following similar logic for an “IP address” data type.
By the way, the validity checking is fairly strict. For example, ‘{x:3}’ is considered invalid because quote marks are missing, and ‘{“x”:.2} is considered invalid because the value has no leading digit.
JSON_VALUE function
For an illustration and example it’s enough to describe the standard’s JSON_VALUE and MySQL’s JSON_EXTRACT.
The standard idea is: pass a JSON string and a JavaScript-like expression, get back an SQL value, which will generally be a scalar value. For example,
SELECT JSON_VALUE(@json, @path_string) FROM t; SELECT JSON_VALUE(json_column_name, 'lax $.c') AS c FROM t;
There are optional clauses for deciding what to do if the JSON string is invalid, or contains missing and null components. Again, the standard’s JSON_VALUE is what Oracle and Microsoft accept. There’s some similarity to what has gone before with SQL/XML.
MySQL, on the other hand, accomplishes some similar things with JSON_EXTRACT. For example,
SELECT JSON_EXTRACT(@json, @path_string); SELECT JSON_VALUE(json_column_name, '$.c') AS c FROM t;
And the result is not an ordinary MySQL scalar, it has type = JSON. In the words of physicist I.I.Rabi when confronted with a new particle, “Who ordered that?”
Well, JSON_EXTRACT and some of the other MySQL functions have fairly close analogues, in both name and functionality, with Google’s BigQuery and with SQLite. In other words, instead of the SQL standard, MySQL has ended up with something like the NoSQL No-standard.
I should stress here that MySQL is not “violating” the SQL standard with JSON_EXTRACT. It is always okay to use non-standard syntax. What’s not okay is to use standard syntax for a non-standard purpose. And here’s where I bring in the slightly dubious case of the “->” operator. In standard SQL “->”, which is called the “right arrow” operator, has only one purpose: dereferencing. In MySQL “->” has a different purpose: a shorthand for JSON_EXTRACT. Since MySQL will never support dereferencing, there will never be a conflict in practice. Nevertheless, technically, it’s a violation.
Observed Behaviour
When I tried out the JSON data type with MySQL 5.7.9, I ran into no exciting bugs, but a few features.
Consistency doesn’t apply for INSERT IGNORE and UPDATE IGNORE. For example:
CREATE TABLE t1 (date DATE, json JSON);
INSERT IGNORE INTO t1 (date) VALUES ('invalid date');
INSERT IGNORE INTO t1 (json) VALUES ('{invalid json}');
The INSERT IGNORE into the date column inserts null with a warning, the INSERT IGNORE into the json column returns an error.
Some error messages might still need adjustment. For example:
CREATE TABLE ti (id INT, json JSON) PARTITION BY HASH(json);
Result: an error message = “A BLOB field is not allowed in partition function”.
Comparisons of JSON_EXTRACT results don’t work. For example:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
JSON_EXTRACT(@json,'$.a'),
JSON_EXTRACT(@json,'$.b'));
The result is a warning “This version of MySQL doesn’t yet support ‘comparison of JSON in the LEAST and GREATEST operators'”, which is a symptom of the true problem, that JSON_EXTRACT returns a JSON value instead of a string value. The workaround is:
SET @json = '{"a":"A","b":"B"}';
SELECT GREATEST(
CAST(JSON_EXTRACT(@json,'$.a') AS CHAR),
CAST(JSON_EXTRACT(@json,'$.b') AS CHAR));
… which returns “B” — a three-character string, including the quote marks.
Not The End
The standard might change, and MySQL certainly will change anything that’s deemed wrong. Speaking of wrong, I might have erred too. And I certainly didn’t give justice to all the other details of MySQL 5.7 JSON.
Meanwhile
The Ocelot GUI client for MySQL and MariaDB is still version 0.8 alpha, but since the last report there have been bug fixes and improvements to the Help option. Have a look at the new manual by going to https://github.com/ocelot-inc/ocelotgui and scrolling down till you see the screenshots and the words “User Manual”.
What is a data type?
I’d suppose that these statements are generally accepted:
A data type is a set of values.
So any value that belongs to that set is said to “have” or “belong to” that data type.
And any column which is defined as “of” that data type is going to contain values which have that data type, only.
For example a column C may be defined as of type INTEGER and will only contain values which belong to the set of integers.
And now for the exceptions, details, caveats, and errors.
What is synonymous with data type?
There are no synonyms; no other term should ever be used.
Not datatype. Oracle’s manual has “datatype” but IBM’s doesn’t and Microsoft’s doesn’t, and it’s not in the standard.
Not domain. C.J.Date (Date on Database, Writings 2000-2006) says
I observe that some people don’t understand even yet that domains and types are the same thing. The SQL standard muddies the water, too, because it used the term DOMAIN to mean something else …”
From your perspective the implication should be: you can’t use domain as a synonym because users of SQL products will think you mean something else.
Not class. Although some people uses class and type interchangeably, class can also mean a set of objects (rather than just a set of values), so it’s a less precise term.
What does the standard say
Move now to what’s in the SQL:2011 standard document. We find:
A data type is a set of representable values. Every representable value belongs to at least one data type and some belong to several data types.
This is restating the common definition — “a data type is a set of values” — without significant limitations. By saying “representable”, the standard seems to be merely accepting that a DBMS shouldn’t include what it can’t store or display. By saying “several data types”, it’s acknowledging that the value denoted by the literal 9999 could fit in either INTEGER or SMALLINT.
Does a data type include length, character set, etc.?
Suppose the definition of a column is
COLUMN_NAME CHARACTER(32)
Is the data type CHARACTER, or is the data type CHARACTER(32)?
This is a difficult question. The best answer I can give, which I’ll claim is what the SQL:2011 standard would say if it could, is: “CHARACTER(32)”.
Yes the name of the data type is CHARACTER. The standard only defines a small set of data type names — CHARACTER, CHARACTER VARYING, CHARACTER LARGE OBJECT, BINARY, BINARY VARYING, BINARY LARGE OBJECT, NUMERIC, DECIMAL, SMALLINT, INTEGER, BIGINT, FLOAT, REAL, DOUBLE PRECISION, BOOLEAN, DATE, TIME, TIMESTAMP, INTERVAL — and of course “CHARACTER” is on that list but “CHARACTER(32)” is not, it is not a name.
On the other hand — and I think the standard’s vocabulary choice is unfortunate — the data type’s name does not identify the data type! The data type is actually identified by a “data type descriptor” which is defined with the entire <data type> clause, and which, as well as name, includes precision, character set, etc.
That is not explicitly stated, so I’ll support the interpretation with several quotes which show that it’s implicit.
“A data type is predefined even though the user is required (or allowed) to provide certain parameters when specifying it (for example the precision of a number).”
“Two data types,T1 and T2, are said to be compatible if T1 is assignable to T2,T2 is assignable to T1, and their descriptors include the same data type name.”
“The data types “CHARACTER(n) CHARACTER SET CS1” and “CHARACTER(m) CHARACTER SET CS2”,where CS1 ≠ CS2, have descriptors that include the same data type name (CHARACTER), but are not mutually assignable”
“If a <data type> is specified, then let [the data type of a domain] be the data type identified by <data type>.”
“If <data type> is specified, then [the declared type of the column] is that data type.”
“If the maximum length of the subject data type is fixed [then default literals shall not be too long].”
“All data types in [destination strings] shall be character string, and all of them shall have the same character repertoire.”
“[If the result of an operation is] not exactly representable with the precision and scale of the result data type [then it’s an error].”
“A site declared with a character string type may be specified as having a collation, which is treated as part of its data type.”
… I quote them merely for the sake of showing that length and character set and repertoire are all part of data type, and that the <data type> clause is what specifies or identifies the data type, and that two different data types can both have the same data type name.
This does not mean that CHARACTER(32) is a subtype of CHARACTER, because the standard is clear that predefined data types cannot have subtypes or supertypes. (User-defined types can have subtypes or supertypes; however, for user-defined types questions like “is the data type character(32)?” don’t arise.)
This does not mean that saying “the data type is CHARACTER” is wrong, because, whenever we’re talking abstractly or generally, that’s appropriate.
It does mean that “data type is CHARACTER(32)” is much more correct when the definition is known.
What about funny-looking values?
If a data type is supposed to be a set of values, but NULLs are allowed, then what is the set?
Taking the line that NULL represents UNKNOWN, and using MySQL/MariaDB limits for SMALLINT, we could say that the set is {-32768, -32767, -32766, … 0, …, +32767} — NULL is somewhere in that enumeration, we just don’t happen to know where. But NULL could mean other things besides UNKNOWN, and sometimes it definitely does — think of ROLLUP. The standard just says “Every data type has a special value, called the
If the limits of the floating-point sets are supposed to be “based on the IEEE standard”, as the MySQL manual says they are, then where are NaN (not a number) and INF (pseudo-infinity)?
This has been the subject of feature requests like Bug#57519 Documentation for IEEE 754 compliance is missing from Daniël van Eeden, and Bug#41442 Support ieee754 by supporting INF and NaN from Mark Callaghan.
Bug#41442, incidentally, says “the SQL spec doesn’t allow [INF and NaN]”. I’d put it less severely — the standard effectively disallows them for all the standard predefined numeric data types including FLOAT or DOUBLE PRECISION (for example it says that an approximate-numeric literal must have the form <mantissa>E<exponent>). The standard does not forbid new implementation-defined data types.
Other specific effects on our favourite DBMSs
As for “what is a data type in MySQL (or by extension in MariaDB)?”, the
correct answer is: whatever the MySQL or MariaDB documentation says. There used to be arguments about this, but I think they’re all in the past now.
Equally, there’s no point arguing about how TINYBLOB etc. should have been specified in terms of maximum length or precision, or about how ENUM should have been a [VAR]CHAR plus a constraint. The more feasible feature request would be along the lines of: more complete support for the standard types.