Month: September 2013
Sometimes MySQL is more standards-compliant than PostgreSQL
Here are examples comparing MySQL 5.6 against PostgreSQL 9.3 Core Distribution, where MySQL seems to comply with “standard SQL” more closely than PostgreSQL does. The examples are also true for MariaDB 10.0 so whenever I say “MySQL” I mean “MySQL and/or MariaDB”. When I say “more closely” I do not mean that MySQL is completely compliant, or that PostgreSQL is completely non-compliant.
Identifiers
Example:
CREATE TABLE ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ (s1 INT); /* 32-character name */
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name = 'ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ';
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name LIKE LOWER('Ž%');
Result:
PostgreSQL says count(*) is 0. MySQL says it’s 1.
Reason:
(1) PostgreSQL maximum identifier length is 63 bytes; MySQL maximum identifier length is 64 characters. The standard requirement is 128 characters.
(2) With PostgreSQL, if you insert an invalid value, PostgreSQL truncates — it “tries to make do” rather than failing. (If the name had been too long for MySQL, it would have thrown an error.)
(3) PostgreSQL does not convert to lower case during CREATE, and does a case-sensitive search during SELECT.
Character Sets And Collations
Example:
CREATE TABLE t (s1 CHAR(1) CHARACTER SET utf16);
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support named character sets; it can only handle one character set per database.
Example:
CREATE TABLE t (s1 CHAR(2), s2 VARCHAR(2));
INSERT INTO t VALUES ('y ','y ');
SELECT * FROM t WHERE s1 = 'y';
SELECT * FROM t WHERE s2 = 'y';
Result:
PostgreSQL finds one row for the first SELECT but zero rows for the second SELECT. MySQL finds one row both times.
Reason:
PostgreSQL does not always add spaces to the shorter comparand, or remove spaces from the longer comparand. MySQL is consistent. The behaviour is optional, but it is not supposed to depend on the data type.
Example:
CREATE TABLE t (s1 CHAR(1), uca CHAR(4),utf32 CHAR(6),utf8 CHAR(8),name VARCHAR(50)); INSERT INTO t VALUES (U&'\+003044','3197',' 3044',' E38184','HIRAGANA LETTER I'); INSERT INTO t VALUES (U&'\+003046','3198',' 3046',' E38186','HIRAGANA LETTER U'); INSERT INTO t VALUES (U&'\+0030A4','3197',' 30A4',' E382A4','KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+0030A5','3198',' 30a5',' E382A5','KATAKANA LETTER SMALL U'); INSERT INTO t VALUES (U&'\+00FF72','3197',' FF72',' EFBDB2','HALFWIDTH KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+00042B','1AF1',' 042B',' D0AB','CYRILLIC CAPITAL LETTER YERU'); INSERT INTO t VALUES (U&'\+0004F9','1AF5',' 04F9',' D3B9','CYRILLIC SMALL LETTER YERU WITH DIAERESIS'); INSERT INTO t VALUES (U&'\+0004CF','1B4A',' 04CF',' D38F','CYRILLIC SMALL LETTER PALOCHKA'); INSERT INTO t VALUES (U&'\+002C13','1B61',' 2C13',' E2B093','GLAGOLITIC CAPITAL LETTER RITSI'); INSERT INTO t VALUES (U&'\+0100CC','3872',' 100CC','F090838C','LINEAR B IDEOGRAM B240 WHEELED CHARIOT'); SELECT * FROM t ORDER BY s1 COLLATE "C",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "POSIX",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "C.UTF-8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "en_CA.utf8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "default",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "ucs_basic",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "zh_CN",uca DESC,name;
Result:
With PostgreSQL, no matter which collation one chooses, one does not get a linguistic standard ordering. Here is a typical result:
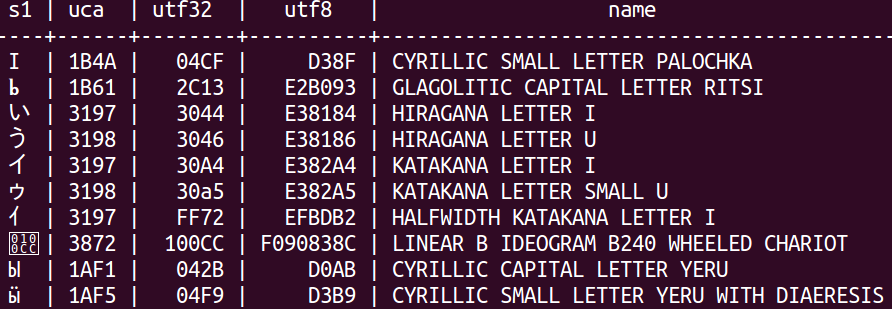
With MySQL, if one enters the same data (albeit in a different way), and chooses collation utf8mb4_unicode_520_ci, one gets a standard result.
Reason:
PostgreSQL depends on the operating system for its collations. In this case my Linux operating system offered me only 5 collations which were really distinct. I did not attempt to customize or add more. I tried all the ones that were supplied, and failed to get a result which would match the Unicode Collation Algorithm order (indicated by the ‘uca’ column in the example). This matters because the standard does ask for a UNICODE collation “in which the ordering is determined by applying the Unicode Collation Algorithm with the Default Unicode Collation Element Table [DUCET]”. MySQL is a cross-platform DBMS and does not depend on the operating system for its collations. So, out of the box and for all platform versions, it has about 25 distinct collations for 4-byte UTF8. One of them is based on the DUCET for Unicode 5.2.
MySQL’s character set and collation support is excellent in some other respects, but I’ll put off the paeans for another post. Here I’ve just addressed a standard matter.
Views
Example:
CREATE TABLE t (s1 INT); CREATE VIEW v AS SELECT * FROM t WHERE s1 < 5 WITH CHECK OPTION;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
MySQL has some support for core standard feature F311-04 “Create view: with check option”. PostgreSQL does not.
Transactions
Example:
START TRANSACTION; CREATE TABLE t (s1 SMALLINT); INSERT INTO t VALUES (1); INSERT INTO t VALUES (32768); /* This causes an error. */ COMMIT; SELECT * FROM t;
Result:
MySQL finds a row containing 1. PostgreSQL finds nothing.
Reason:
PostgreSQL rolls back the entire transaction when it encounters a syntax error. MySQL only cancels the statement.
Now, PostgreSQL is within its rights — the standard says that an implementor may do an “implicit rollback” for an error. But that is a provision for what a DBMS implementor MAY do. From other passages in the standard, it’s apparent that the makers didn’t anticipate that a DBMS would ALWAYS do it, even for syntax errors. (For example it says: “exception conditions for transaction rollback have precedence over exception conditions for statement failure”.) Even Microsoft SQL Server, in its optional “abort-transaction-on-error” mode, doesn’t abort for syntax errors. So MySQL appears to be nearer the spirit of the standard as generally understood.
Example:
CREATE TABLE t (s1 INT); INSERT INTO t VALUES (1); COMMIT; START TRANSACTION; SELECT CURRENT_TIMESTAMP FROM t; /* Pause 1 second. */ SELECT CURRENT_TIMESTAMP FROM t;
Result: PostgreSQL shows the same timestamp twice. MySQL shows two different timestamps.
Reason:
PostgreSQL keeps the same time throughout a transaction; MySQL keeps the same time throughout a statement.
The key sentences in the standard say that the result of a datetime value function should be the time when the function is evaluated, and “The time of evaluation of a datetime value function during the execution of S and its activated triggers is implementation-dependent.” In other words, it’s supposed to occur during the execution of S, which stands for Statement. Of course, this leads to arguable matters, for example what if the statement is in a function that’s invoked from another statement, or what if the statement is within a compound statement (BEGIN/END block)? But we don’t have to answer those questions here. We just have to observe that, for the example given here, the DBMS should show two different timestamps. For documentation of how DB2 follows this, see ibm.com.
Stored Procedures, Functions, Triggers, Prepared Statements
Example:
CREATE FUNCTION f () RETURNS INT RETURN 1;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support any functions, stored procedures, or triggers with standard syntax.
Instead PostgreSQL supports Oracle syntax. This is not as bad it sounds — the Oracle syntax is so popular that even DB2 also has decided to support it, optionally.
Example:
PREPARE stmt1 FROM 'SELECT 5 FROM t';
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL doesn’t support the standard syntax for PREPARE.
Data Types
Example:
CREATE TABLE t (s1 CHAR(1)); INSERT INTO t VALUES (U&'\+000000');
Result:
PostgreSQL returns an error. MySQL succeeds, although MySQL has to use a different non-standard syntax.
Reason:
PostgreSQL has an aversion to CHR(0) the NUL character.(“The character with the code zero cannot be in a string constant.”). Other DBMSs allow all characters in the chosen character set. In this case, the default character set is in use, so all Unicode characters should be okay.
Example:
CREATE TABLE t (s1 BINARY(1), s2 VARBINARY(2), s3 BLOB);
Result: PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support BINARY or VARBINARY or BLOB. It has equivalent non-standard data types.
The Devil Can Cite Scripture For His Purpose
I could easily find examples going the other way, if I wrote a blog post titled “Sometimes PostgreSQL is more standards-compliant than MySQL”. But can one generalize from such examples?
The PostgreSQL folks boldly go to conclusion mode:
As a quick summary, MySQL is the “easy-to-use, web developer” database, and PostgreSQL is the “feature-rich, standards-compliant” database.
Follow I do not dare.
How to pronounce SQL
In the thirty-second minute of a YouTube video featuring Oracle CEO Larry Ellison you can hear him say clearly “we compete against Microsoft SQL Server … we never compete against MySQL”.
The important thing is that he says “Microsoft SEQUEL Server” the way Microsoft people say it, but he says “My-ESS-CUE-ELL” the way the MySQL Reference Manual says is “official” pronunciation (for English). That is, for product names Mr Ellison respects the way the product makers say it. That settles that, but what about the word SQL in general?
Although SEQUEL was the earlier name, there are no English words where the letter Q alone is pronounced KW. So this can’t be settled with logic. Let’s try appealing to authority.
I looked for the way that other prominent database people said it, or the way they wrote it — if they wrote “an SQL” then the pronunciation must be “Ess-Cue-Ell”; if they wrote “a SQL” then the pronunciation must be “Sequel”.
The results were:
| Authority | Prefers | Source |
|---|---|---|
| Joe Celko | Both | YouTube |
| Don Chamberlin | Ess-Cue-Ell | Book Excerpt |
| C.J.Date | Sequel | “A guide to the SQL Standard” (1987), p. 10, p. 32 |
| David DeWitt | Sequel | YouTube |
| Steven Feuerstein | both | YouTube |
| Bill Gates | Both | YouTube |
| Jim Gray | Sequel | Podcast |
| Joseph M. Hellerstein | Both | Podcast |
| Jim Melton | Ess-Cue-Ell | Podcast |
| Curt Monash | Sequel | Article |
| Shamkant Navathe | Ess-Cue-Ell | “Fundamentals of Database Systems” with Ramez Elmasri (3rd edition) p. 207 |
| Patricia Selinger | Sequel | YouTube |
| Jim Starkey | Sequel | Blog comment |
| Michael Stonebraker | Sequel | YouTube |
| Jennifer Widom | Sequel | YouTube |
… Then I checked vendor documentation. All manuals are inconsistent so this is based on which choice is most frequent.
| Authority | Prefers | Source |
|---|---|---|
| Firebird | Ess-Cue-Ell | firebirdsql.org |
| IBM | Ess-Cue-Ell | publib.boulder.ibm.com |
| MariaDB | Ess-Cue-Ell | askmonty.org/v |
| Microsoft | Sequel | technet.microsoft.com |
| MySQL | Ess-Cue-Ell | mysql.com/doc |
| Oracle | Sequel | docs.oracle.com |
| PostgreSQL | Ess-Cue-Ell | www.postgresql.org/about/press/faq |
As for NoSQL: Dwight Merriman (the chairman of MongoDB Inc.) says No-Sequel, and Martin Fowler (the co-author of NoSQL Distilled) says No-Sequel, but there’s an IBM tutorial that says No-Ess-Cue-Ell.
… Finally I looked again at my beloved “Standard” document.
| Authority | Prefers | Source |
|---|---|---|
| The Standard | Ess-Cue-Ell | jtc1sc32.org |
… And what I did not do is count Google hits. I know “Sequel” would win big if it was a hoi polloi decision, but this is a technical term. Many people pronounce Uranus in a way that astronomers dislike; many people say Brontosaurus although paleontologists say Apatosaurus — but if you were in astronomy or paleontology you’d have to go with what the experts say. Majority opinion is only decisive for ordinary language.
In the end, then, it’s “when in Rome do as the Romans do”. In Microsoft or Oracle contexts one should, like Mr Ellison, respect Microsoft’s or Oracle’s way of speaking. But here in open-source-DBMS-land the preference is to follow the standard.
So the name of this blog is Ess-cue-ell and its Sequels.
Representing Sex In Databases
The MySQL Reference Manual advises:
Use a CREATE TABLE statement to specify the layout of your table:
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
-> species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
…
Several types of values can be chosen to represent sex in animal records, such as ‘m’ and ‘f’, or perhaps ‘male’ and ‘female’. It is simplest to use the single characters ‘m’ and ‘f’.
I will supplement that with this post about representing sex (gender) in people records. I have to consider the name, the possible values, the data type, and the constraints. It won’t be simplest.
Should the column name be ‘sex’?
First consider Naming Conventions. The word ‘sex’ is not too long, its characters are all Latin, there is no need to “delimit”, using lower case is okay, making it plural (‘sexes’) would be a mistake, and it’s not a reserved word. So far so good.
Next consider the alternative term ‘gender’. Some people make a distinction between gender and sex. In that case, ‘sex’ is better if only a physical characteristic matters, but ‘gender’ is better if you’re also taking into account the behaviour, self-identification, and washroom preference. However, gender’s primary dictionary meaning is as a grammatical category, and it is a far less popular word.
Conclusion: yes, the column name should be ‘sex’.
Should the possible values be ‘m’ and ‘f’?
Now consider interoperability. If there are application programs that use the database, what checkboxes are they likely to display? If the data must go to some other body (the government, say), do they tell you what the choices are? This is where standards come in. For pretty well anything that’s commonly used to describe a person (age, occupation, income, and of course sex) there will be a standard code list.
The German Wikipedia article about “Data standards for description of sex” describes many of them. It’s worth a look even if your German is weak, because most of the charts include English translations. I’ll try to use primary sources and then generalize:
- ISO 5218.
ISO/IEC 5218 Information technology — Codes for the representation of human sexes has single-digit numeric codes: 0 = not known, 1 = male, 2 = female, 9 = not applicable.
- Three-Way.
The CDC (Centers for Disease Control) prescription is ‘M’ = male, ‘F’ = female, ‘O’ = other.
On German birth certificates, starting in November the choices will be ‘M’, ‘F’, ‘ ‘.
For Australian passports the choices are ‘M’, ‘F’, ‘X’.
- European.
The Eurostat statistics group of the European Commission, and SDMX (Statistical Data and Metadata eXchange) which is sponsored by Eurostat and OECD, have produced a hodgepodge of incompatible recommendations. But the most recent list seems to be: T = Total, F = Females, M = Males, NAP = Not applicable, UNK = Unknown.
- Biological.
HL7 (Health Level 7), a standard for interoperability of health information adds a hermaphrodite category. CID 7455, a directive for physicians goes furthest of all with: M = Male, F = Female, U = Unknown Sex, MP = Male pseudohermaphrodite (see the Wikipedia article on Pseudohermaphroditism), FP = Female pseudohermaphrodite, H = Hermaphrodite, MC = Male changed to female, FC = Female changed to male, 121104 = Ambiguous, 121032 = Subject sex (for clinical purposes), 121102 = Other, 121103 = Temporarily undetermined (see the BBC article on determining sex or see “Everything you ever wanted to know about determining sex”).
ISO 5218 is the international standard, and gets a recommendation in a chapter about sex in “Joe Celko’s Data, Measurement and Standards in SQL”. The problem is it only uses digits. This eliminates the worry that it will look biased towards West European languages, but then it looks biased towards males (because ‘1’ comes before ‘2’), and on that basis has been called “offensive”.
More seriously, a digit has no mnemonic value and that means inputters and readers would have to learn more, or developers would have to write more.
Let’s look instead for something that the other “standards” can agree on.
They all say ‘M’ = male and ‘F’ = female, so that’s indisputable.
Most of them say there’s at least one other category, and although it is disputable it is prudent to add ‘O’ = other, forestalling complaints like the lack of ‘fluidity’ objection from the Gay, Lesbian, Bisexual, and Transgender Round Table of the American Library Association.
Most of them say there are codes for “unknown” and “not applicable”, and this should be disputed. Such codes are necessary for simple lists, but for SQL databases they are unnecessary because NULLs exist. If we said that the ‘sex’ column has special values for “unknown” or “not applicable”, but ‘owner’ and ‘species’ do not, we would need inconsistent rules. Therefore “unknown” and “not applicable” are to be handled with NULL.
They all say that ‘M’ and ‘F’ are upper case. Of course it might not matter in MySQL or MariaDB, where the default collation is case insensitive. But other DBMSs are stricter, and we’re thinking about interoperability here, so lower case codes like ‘m’ and ‘f’ are not acceptable equivalents.
Conclusion: allow ‘M’, ‘F’, ‘O’, and NULL.
Should the data type be CHAR(1)?
Now consider what best fits for the range of values, without totally forgetting efficient storage.
- ENUM(‘M’,’F’,’O’)
This has the advantage that input errors, like a sex value of ‘!’, won’t be allowed — the closest that MySQL can come to a CHECK clause. And it’s handy that ENUMs can be searched as numerics, which for this definition would be 1 = M and 2 = F, the same as the ISO/IEC requirement. But ENUM is not standard.
- SMALLINT or TINYINT
Well, any numeric type would be okay for storing an ISO-5218-style digit. However, saying it’s SMALLINT is telling the world “it’s a number”. Just because a digit can appear in a numeric column doesn’t mean that any of the things that are meaningful for numbers (averaging, multiplying, etc.) should be applicable to ‘sex’.
- BOOLEAN
MySQL’s BOOLEAN is just a synonym for TINYINT(1) so is of no use. If we were talking about the real idea of a Boolean — a binary TRUE/FALSE — we’d better change the column name to reflect that the answers are true or false — instead of ‘sex’, the column name should be ‘is_male’.
- VARCHAR(5)
This is a bit more flexible than CHAR(1) if one fears that someday there will be a mandate to store as CID 7455 which has 5-character codes, but VARCHAR might need more space.
- BIT(1) and CHAR(0)
Speaking of needing space, a bunch of BIT columns might be more economical for storage than a bunch of CHAR(1) columns, with MyISAM. And for the CHAR(0) trick, see a 2008 post from Percona. BIT(1) and CHAR(0) would only be for people desperate to save bytes; in other respects they are the worst choice.
Conclusion: yes, the data type should be CHAR(1).
Should there be constraints to prevent bad input?
Since we won’t use ENUM, and we can’t use a CHECK clause, how can we stop people from putting in something other than ‘M’, ‘F’, ‘O’, or NULL?
With old versions we’d have to make views with CHECK OPTION clauses, or perhaps foreign-key references. Nowadays we can make triggers. For example:
DELIMITER //
CREATE TRIGGER check_sex AFTER INSERT ON pet FOR EACH ROW BEGIN
IF new.sex COLLATE latin1_bin NOT IN ('M','F','O') AND new.sex IS NOT NULL THEN
SIGNAL SQLSTATE '22222' SET MESSAGE_TEXT='sex must be ''M'' or ''F'' or ''O'' or NULL';
END IF;
END//
For historical reasons that’s not a MySQLish practice, though. Ordinarily I’d expect that people will hope that application code will keep the input clean, and will do periodic cleanups when they find that application code does not keep the input clean.
The Real Point
The MySQL manual is correct about the way to design a “My Pets” database. But if a database description will consistently map to items in the real big wide world, there are going to be multiple things to consider.
NULL and UNIQUE
When I worked for MySQL I saw frequent complaints that the UNIQUE constraint didn’t stop users from inserting NULLs, multiple times. For example:
CREATE TABLE t (s1 INT, UNIQUE (s1));
INSERT INTO t VALUES (NULL);
INSERT INTO t VALUES (NULL); /* This does not cause a “unique constraint violation” error */
There are now eleven generously-commented bugs.mysql.com reports:
#5685, #6829, #7479, #8173, #9844, #17825, #19377, #25544, #27019, #27376, #66512. The essential points (along with observations about how we were stupid or deaf or lazy) are:
- the ANSI/ISO SQL standard said we should throw an error,
- all the other major DBMSs would throw an error,
- and throwing an error would be more sensible and convenient.
The first point is false; the second point depends what “major” means; the third point is a valid opinion.
I will now attempt to beat this subject to death with enough thoroughness that it will become dead.
Exactly what the ANSI/ISO standard says, and how it applies
Our example will be a table named t created thus:
CREATE TABLE t (s1 INT, UNIQUE (s1));
INSERT INTO t VALUES (NULL),(NULL);
So t looks like this:
+------------+ | s1 | +------------+ | NULL | | NULL | +------------+
Our question will be: is the constraint “UNIQUE (s1)” violated according to the SQL standard?
I’ll use a recent draft of SQL:2011 because it’s current and it’s available for all to see, at:
jtc1sc32.org/doc/N1951-2000/32N1964T-text_for_ballot-FCD_9075-2.pdf.
The wording is about the same in all earlier versions of the standard since SQL-89, which didn’t allow NULLs at all for UNIQUE constraints.
Section 11.7 says:
[Syntax Rules]
4) … let SC be the <search condition>:
UNIQUE ( SELECT UCL FROM TNN )
where UCL means “Unique Column List” and TNN means “Table Name”.
So for our example, search condition SC is “UNIQUE (SELECT s1 FROM t)”.
3) The unique constraint is not satisfied if and only if
EXISTS ( SELECT * FROM TNN WHERE NOT ( SC ) )
is True.
… Plugging in our values, that means
3) The unique constraint is not satisfied if and only if
EXISTS ( SELECT * FROM t WHERE NOT ( UNIQUE (SELECT s1 FROM t) ) )
is True.
So now we have to know how “UNIQUE(…)” is supposed to work.
Section 8.11 says:
If there are no two rows in T such that the value of each column in one row is non-null and is not distinct from the value of the corresponding column in the other row, then the result of the <unique predicate> is True; otherwise, the result of the <unique predicate> is False.
… where T is the table.
Now, apply the predicate “UNIQUE (s1)” to table t.
For either Row#1 or Row#2: Is the value of column s1 non-null?
Answer: NO. It is NULL.
Therefore the requirement “that the value of each column in one row is non-null” is met for zero rows in t.
But the <unique predicate> is only False if the requirement is met for two rows in t. Therefore the result of the <unique predicate> is True.
In other words,
UNIQUE (s1) is True.
Therefore
NOT (UNIQUE (s1)) is False.
Therefore
SELECT * FROM TNN WHERE NOT (UNIQUE (t)) returns zero rows.
Therefore
EXISTS ( SELECT * FROM TNN WHERE NOT ( UNIQUE (t) ) ) is false.
But Rule 3) says that the unique constraint is not satisfied if and only if that EXISTS clause is True.
Therefore the constraint is satisfied.
And when a constraint is satisfied, it is not violated.
Thus, according to the rules for <unique constraint definition>, our example table violates no constraint.
It’s tedious to work through this because there are multiple negatives, but it is not ambiguous.
Why, then, do some people have trouble? Partly because they look at a different statement in the introductory sections. Section 4.17 Integrity constraints says:
A unique constraint is satisfied if and only if no two rows in a table have the same non-null values in the unique columns.
And I have to admit that it’s not at all obvious what that’s supposed to mean. But, since you have now seen what is in the later and more detailed sections, you should read it as “no two rows have unique-column values which are the same (an undefined word which probably means equal) and which are also non-null”.
What other DBMSs do
Trudy Pelzer and I wrote this on page 260 of our book, SQL Performance Tuning:
| DBMS | Maximum number of NULLs when there is a UNIQUE constraint |
| IBM (DB2) | One |
| Informix | One |
| Ingres | Zero |
| InterBase | Zero |
| Microsoft (SQL Server) | One |
| MySQL | Many [although the BDB storage engine was an exception] |
| Oracle | Many |
| Sybase | One |
DB2 has an optional clause which can force standard behaviour.
Oracle is only allowing multiple NULLs because it doesn’t put NULLs in indexes; if we were talking about a multiple-column constraint, Oracle would be non-standard.
The book didn’t cover PostgreSQL and Access and Firebird, which all allow “Many” NULLs. A newer entrant, NuoDB, allows only one NULL (I told them that’s non-standard but they didn’t believe me).
Most of the complainers were apparently thinking of Microsoft SQL Server. So it’s interesting that on Microsoft’s discussion boards the complaints are (spoiler alert!) that SQL Server doesn’t follow the standard and should be more like other DBMSs. See, for example, NULL in unique index (where SQL Server gets it wrong) and Change UNIQUE constraint to allow multiple NULL values.
According to SQL Server Magazine, in 2008,
ANSI SQL supports two kinds of UNIQUE constraints — one that enforces uniqueness of NULLs just like with known values, and another that enforces uniqueness of known values but allows multiple NULLs. Microsoft SQL Server implemented only the former.
As we’ve seen, that’s false, and so is another claim, that “Informix and Microsoft SQL Server follow the other interpretation of the standard.” But perhaps Microsoft’s stories help explain people’s beliefs.
What is more sensible
An unfortunate defence of the allow-many-NULLs behaviour is that “Null values are not considered equal”. That’s what’s happening in effect in this particular case, but it’s not a general or useful rule.
- (a) if we were doing a NULL/NULL comparison, or a NULL/not-NULL comparison, the result would be UNKNOWN. For other constraints an UNKNOWN result is considered a violation.
- (b) “equality” is the wrong concept to consider here, it is more important to consider whether the values are “not distinct” — and in fact two NULL values are not distinct.
- (c) NULLs sort together for purposes of GROUP BY, ORDER BY, or duplicate elimination.
Therefore, the UNIQUE rules do not follow automatically from how NULLs behave elsewhere in SQL. That is why the standard had to add wording to specify that the uniqueness predicate applies only for “non-null” values.
So, regarding what looks more sensible, it seems that the complainers have a point.
What is more convenient?
It is better, now, to carry on as before. The current behaviour is the de facto and the de jure standard. It is neither a bug nor undesirable.
But would it be even better if MySQL or MariaDB allowed an option? The DB2 syntax to allow UNIQUE with many NULLs is:
CREATE TABLE t (s1 INT UNIQUE WHERE NOT NULL)
so presumably the way to specify UNIQUE with one NULL would be:
CREATE TABLE t (s1 INT UNIQUE WHERE NULL OR NOT NULL)
but it would be easier to understand if we said
CREATE TABLE t (s1 INT UNIQUE AND MAXIMUM NUMBER OF NULLS = 1).
Anyway, it would be possible. But a nice first step would be to acknowledge that it is a feature request rather than a bug.
Copyright (c) 2013 by Ocelot Computer Services Inc. All rights reserved.
Back From Blogging Break
Most “SQL And Its Sequels” blog posts will be from me, Peter Gulutzan, formerly Software Architect for MySQL then Sun then Oracle. Most posts will be about MySQL / MariaDB and SQL standards — my expertises. But I learned about other products during my recent stint at HP, and I like to look at other open-source DBMSs as well.
The RSS feed is http://ocelot.ca/blog/feed/ and posts will occur once or twice a month.
Copyright (c) 2013 by Ocelot Computer Services Inc. All rights reserved.