Category: NoSQL
What’s in the SQL of NoSQL
In a previous post I said it’s bogus that NoSQL stands for Not Only SQL, but NoSQL products can have “some” SQL. How much?
To get past the SQL-for-Hadoop stuff I’ll just mine a few quotes: “Hive was the first SQL on Hadoop engine and is still the most mature engine.” “Apache Phoenix is a project which aims to provide OLTP style SQL on top of Apache HBase.” “Cloudera Impala and Apache Drill are the two most prominent Dremel clones.” “Oracle, IBM, and Greenplum have all retrofit their database engines to integrate with Hadoop in various ways.” There, that’s the history out of the way. With thanks to a comprehensive article series: The Truth about SQL on Hadoop”.
Of course I could add that it’s possible to take an SQL front and add a NoSQL back as an “engine”, as MariaDB did with Cassandra plus LevelDB, as PostgreSQL did with MongoDB.
Here’s what I see as the documented capabilities provided by NoSQL vendors themselves, or via the Dremel clones.
| thing | CQL | Drill | Impala | OrientDB |
|---|---|---|---|---|
| DELETE,INSERT,UPDATE | 1/2 | no | yes | yes |
| SELECT + WHERE | 1/2 | yes | yes | yes |
| SELECT + GROUP BY | no | yes | yes | yes |
| SELECT + functions | 1/2 | yes | 1/2 | yes |
| SELECT + IS NULL | no | yes | yes | yes |
| Subqueries or Joins | no | 1/2 | yes | no |
| GRANT + REVOKE | yes | no | yes | yes |
| Stored SQL Routines | no | no | no | no |
| Collations | no | no | 1/10 | |
CQL (Cassandra Query Language) does what I expect: I can do the regular DML statements, but UPDATE can only handle one row at a time. There are no subqueries or joins or views or SQL functions, and the WHERE is restricted because I have to use a query that includes information that tells Cassandra what cluster to go to. All strings are ASCII or UTF-8.
Apache Drill has all the options I respect for SELECT, even windowing. But ithe updating is done outside SQL. There are lots of built-in functions that CQL lacks.
Impala, from Cloudera, is regarded as a good option for analytic queries.
OrientDB handles graph databases, which the OrientDB founder says is defined as “index-free adjacency” (that’s my first joke, I’m making sure you don’t miss them).
For my chart, I deliberately added criteria that I thought might make the DBMSs choke. Specifically I thought IS [NOT] NULL would cause trouble because in a flexible schema the data might be either “missing” = not stored at all or “unknown” = stored explicitly as null value … but usually this caused no problem. Specifically I thought collations would cause trouble because they must affect either storage or performance … and they certainly did, CQL and Impala are byte-value-comparison-only and OrientDB has a grand total of two collations (case sensitive or insensitive). Most of the limitations are understandable for a DBMS that does clustering and searching quickly, but that’s not mom-and-pop stuff. I will end this paragraph with my second joke. NoSQL doesn’t scale … down.
Sometimes the vendors get it that when you use SQL you should use ANSI SQL, for example it’s typical that identifiers can be enclosed within double quotes — far better than MySQL/MariaDB’s ANSI_QUOTES requirement. On the other hand I see that Impala has SHOW statements — just as bad as MySQL/MariaD. And I’ve no idea where OrientDB came up with the syntax “ORDER BY … SKIP”.
On the other hand, NoSQL can be expected to be better at flexible schemas. And it is, because some of the SQL vendors (I’m especially thinking of the work-in-progress “dynamic column” stuff in MariaDB and the JSON functions in MySQL) are still catching up. But they will catch up eventually. That’s why I like the Gartner Report on DBMSs predicting
By 2017, the “NoSQL” label will cease to distinguish DBMSs, which will result in it falling out of use.
Only 5 months left to go, eh?
Another NoSQL DBMS, Tarantool, is also going to have SQL real soon now. Anti-disclosure: I do some work for the vendor but I had nothing to do with the SQL planning.
The idea behind Tarantool/SQL is: instead of struggling to add a piece at a time to a home-grown parser, just fork the one in SQLite. Poof, there’s SQL syntax which, as I discussed in an earlier post, is more than an insignificant subset of the standard core features. The actual data maintenance job is done by Tarantool’s multi-user server.
Here is an ocelotgui screenshot of a Tarantool/SQL query showing the usual advantages that one gets when the language is SQL: syntax highlighting, predicting, and columnar output.
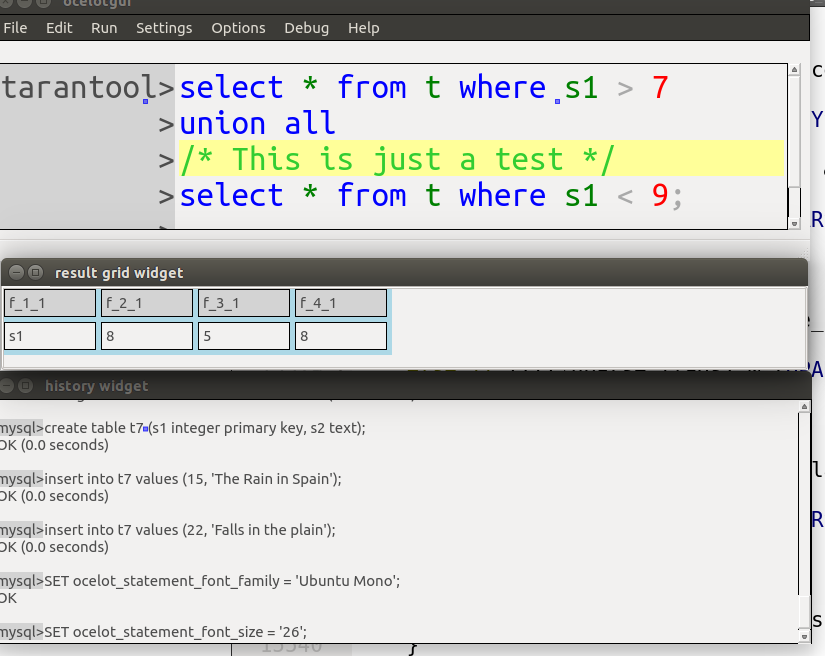
What part of NoSQL don’t you understand?
In the word “NoSQL”, the letters “No” are an acronym so the meaning is “Not Only SQL” rather than “No SQL”. True or false?
Historically, it’s false
The first NoSQL product was a classic DBMS which didn’t happen to use SQL for a query language, featured in Linux Journal in 1999. Its current web page has a traffic-sign symbol of the word SQL with a bar through it, and a title “NoSQL: a non-SQL RDBMS”.
For a meetup in June 2009 about “open source, distributed, non-relational databases” the question came up “What’s a good name?” Eric Evans of Rackspace suggested NoSQL, a suggestion which he later regretted.
In October 2009 Emil Eifrem of NeoTechnology tweeted “I for one have tried REALLY HARD to emphasize that #nosql = Not Only SQL”. This appears to be the earliest recorded occurrence of the suggestion. In November 2009 Mr Eifrem declared with satisfaction that the suggestion was “finally catching on”.
In other words saying “No = Not Only” is an example of a backronym, and specifically it’s a class of backronym known as False Acronyms. There are lots of these around — like the idea that “cabal” stands for seventeenth-century English ministers named Clifford Arlington Buckingham Ashley and Lauderdale, or the myth that “posh” means “port out starboard home”. False acronyms might go back at least 1600 years, if the earliest example is the “Jesus Fish”. Anyway, backronyms are popular and fun, but this one’s false.
Currently it’s unaccepted
Regardless of etymology, NoSQL could currently mean Not Only SQL, if everyone accepted that. So, getting the new interpretation going is a matter of evangelism — tell everyone that’s what it means, and hope that they’ll tell their friends. Is that working?
I think it has worked among NoSQL insiders, but it’s tenuous. If it were generally believed, then the common spelling would be NOSQL rather than NoSQL, and the common pronunciation would be “En O Ess Cue Ell” rather than “No Sequel”. Although my sample size is small, I can say that I’ve rarely seen that spelling and I’ve rarely heard that pronunciation.
And the general public knows that “no-starch” products don’t contain more than starch, or that “no-goodniks” are in a class beyond goodness, and that the slogan “No means no!” is a response to proponents of sexual assaults. So, when confronted with the claim that no doesn’t mean no, there’s inevitable resistance or disgust.
But is it true?
It would still be okay to promote the idea that “NoSQL” equals “not only SQL” if the term described a group of products that are (a) SQL and (b) something other than SQL. This is where, in a rephrasing of the Wendy’s “Where’s The Beef?” commercial, the first question is: “Where’s the SQL?”
Back in 2009 the answers would have been pathetic, but nowadays there are “SQL” query languages that come from NoSQL vendors. CQL would qualify as an SQL product if the bar was low, like saying “If it MOVEs, it’s COBOL”. Impala would qualify in a more serious way, in fact most of the core-SQL tick-box items are tickable. (I’m believing the manual, I didn’t do vicious testing as I did with MySQL.) So, although they’re a minority, there seem to be NoSQL vendors who supply SQL.
But the second question is: what can these products do that can’t be done in SQL? Well, they can supply language extensions, and they can allow the SQL layer to be bypassed. However, so can MySQL or MariaDB — think of the navigation with HANDLER or direct access with HandlerSocket. In that case MySQL would be a NoSQL DBMS, and if that were true then the term NoSQL wouldn’t distinguish the traditional from the non-traditional products, and so it would be a useless word.
Therefore pretending that NoSQL means Not Only SQL is wrong in several ways, but insisting it still means No SQL is merciless. Perhaps an honest solution is to stop saying that the word’s parts mean anything. It’s just a name now, in the same way that “PostgreSQL” is just a name and you’ve forgotten what’s it’s a post of.
The USA’s healthcare.gov site and LAMP
The USA’s health care exchange site, healthcare.gov, has had well-publicized initial woes.
The New York Times has said one of the problems was the government’s choice of DBMS, namely MarkLogic. A MarkLogic employee has said that “If the exact same processes and analysis were applied to a LAMP stack or an Oracle Exa-stack, the results would have likely been the same.”
I don’t know why he picked Exastack for comparison, but I too have wondered whether things would have been different if the American government had chosen a LAMP component (MySQL or MariaDB) as a DBMS, instead of MarkLogic.
What is MarkLogic?
The company is a software firm founded in 2001 based in San Carlos California. It has 250 employees. The Gartner Magic Quadrant classes it as a “niche player” in the Operational DBMS Category.
The product is a closed-source XML DBMS. The minimum price for a perpetual enterprise license is $32,000 but presumably one would also pay for support, just as one does with MySQL or MariaDB.
There are 250 customers. According to the Wall Street Journal “most of its sales come from dislodging Oracle Corp.”
One of the customers, since 2012 or before, is CMS (the Centers for Medicare and Medicaid), which is a branch of the United States Department of Health and Human Services. CMS is the agency that built the healthcare.gov online portal.
Is MarkLogic responsible for the woes?
Probably MarkLogic is not the bottleneck.
It’s not even the only DBMS that the application queries. There is certainly some contact with other repositories during a get-acquainted process, including Oracle Enterprise Identity management — so one could just as easily blame Oracle.
There are multiple other vendors. USA Today mentions Equifax, Serco, Optum/QSSI, and the main contractor
CGI Federal.
A particular focus for critics has been a web-hosting provider, Verizon Terremark. They have been blamed for some of the difficulties and will eventually be replaced by an HP solution. HP also has a fairly new contract for handling the replication.
Doubtless all the parties would like to blame the other parties, but “the Obama administration has requested that all government officials and contractors involved keep their work confidential”.
It’s clear, though, that the site was launched with insufficient hardware. Originally it was sharing machines with other government services. That’s changed. Now it has dedicated machines.
But the site cost $630 million so one has to suppose they had money to buy hardware in the first place. That suggests that something must have gone awry with the planning, and so it’s credible what a Forbes article is saying, that the government broke every rule of project management.
So we can’t be sure because of the government confidentiality requirement, but it seems unlikely that MarkLogic will get the blame when the dust settles.
Is MarkLogic actually fast?
One way to show that MarkLogic isn’t responsible for slowness, would be to look for independent confirmations of its fastness. The problem with that is MarkLogic’s evaluator-license agreement, from which I quote:
…
MarkLogic grants to You a limited, non-transferable, non-exclusive, internal use license in the United States of America
…
[You must not] disclose, without MarkLogic’s prior written consent, performance or capacity statistics or the results of any benchmark test performed on Software
…
[You must not] use the Product for production activity,
…
You acknowledge that the Software may electronically transmit to MarkLogic summary data relating to use of the Software
— http://developer.marklogic.com/products
These conditions aren’t unheard of in the EULA world, but they do have the effect that I can’t look at the product at all (I’m not in the United States), and others can look at the product but can’t say what they find wrong with it.
So it doesn’t really matter that Facebook got 13 million transactions/second in 2011, or that the HandlerSocket extension for MySQL got 750,000 transactions/second with a lot less hardware. Possibly MarkLogic could do better. And I think we can dismiss the newspaper account that MarkLogic “continued to perform below expectations, according to one person who works in the command center.” Anonymous accounts don’t count.
So we can’t be sure because of the MarkLogic confidentiality requirements, but it seems possible that MarkLogic could outperform its SQL competitors.
Is MarkLogic responsible for absence of High Availability?
High Availability shouldn’t be an issue.
At first glance the reported uptime of the site — 43% initially, 90% now — looks bad. After all, Yves Trudeau surveyed MySQL High Availability solutions years ago and found even the laggards were doing 98%. Later the OpenQuery folks reported that some customers find “five nines” (99.999%) is too fussily precise so let’s just round it to a hundred.
At second glance, though, the reported uptime of the site is okay.
First: The product only has to work in 36 American states and Hawaii is not one of them. That’s only five time zones, then. So it can go down a few hours per night for scheduled maintenance. And uptime “exclusive of scheduled maintenance” is actually 95%.
Second: It’s okay to have debugging code and extra monitoring going on during the first few months. I’m not saying that’s what’s happening — indeed the fact that they didn’t do a 500-simulated-sites test until late September suggests they aren’t worry warts — but it is what others would have done, and therefore others would also be below 99% at this stage of the game.
So, without saying that 90 is the new 99, I think we can admit that it wouldn’t really be fair to make a big deal about some LAMP installation that has higher availability than healthcare.gov.
Is it hard to use?
MarkLogic is an XML DBMS. So its principal query language is XQuery, although there’s a section in the manual about how you could use SQL in a limited way.
Well, of course, to me and to most readers of this blog, XQuery is murky gibberish and SQL is kindergartenly obvious. But we have to suppose that there are XML experts who would find the opposite.
What, then, can we make out of the New York Times’s principal finding about the DBMS? It says:
“Another sore point was the Medicare agency’s decision to use database software, from a company called MarkLogic, that managed the data differently from systems by companies like IBM, Microsoft and Oracle. CGI officials argued that it would slow work because it was too unfamiliar. Government officials disagreed, and its configuration remains a serious problem.”
— New York Times November 23 2013
Well, of course, to me and to most readers of this blog, the CGI officials were right because it really is unfamiliar — they obviously had people with experience in IBM DB2, Microsoft SQL Server, or Oracle (either Oracle 12c or Oracle MySQL). But we have to suppose that there are XML experts who would find the opposite.
And, though I think it’s a bit extreme, we have to allow that it’s possible the problems were due to sabotage by Oracle DBAs.
Yet again, it’s impossible to prove that MarkLogic is at fault, because we’re all starting off with biases.
Did the problem have something to do with IDs?
I suspect there was an issue with IDs (identifications).
It starts off with this observation of a MarkLogic feature: “Instead of storing strings as sequences of characters, each string gets stored as a sequence of numeric token IDs. The original string can be reconstructed using the dictionary as a lookup table.”
It ends with this observation from an email written on September 27 2013 by a healthcare.gov worker: “The generation of identifiers within MarkLogic was inefficient. This was fixed and verified as part of the 500 user test.”
Of course that’s nice to see it was fixed, but isn’t it disturbing that a major structural piece was inefficient as late as September?
Hard to say. Too little detail. So the search for a smoking gun has so far led nowhere.
Is it less reliable?
Various stories — though none from the principals — suggest that MarkLogic was chosen because of its flexibility. Uh-oh.
The reported quality problems are “one in 10 enrollments through HealthCare.gov aren’t accurately being transmitted” and “duplicate files, lack of a file or a file with mistaken data, such as a child being listed as a spouse.”
I don’t see how the spousal problem could have been technical, but the duplications and the gone-missings point to: uh-oh, lack of strong rules about what can go in. And of course strong rules are something that the “relational” fuddy-duddies have worried about for decades. If the selling point of MarkLogic is in fact leading to a situation which is less than acceptable, then we have found a flaw at last. In fact it would suggest that the main complaints so far have been trivia.
This is the only matter that I think looks significant at this stage.
How’s that hopey-changey stuff working out for your Database?
The expectation of an Obama aide was: “a consumer experience unmatched by anything in government, but also in the private sector.”
The result is: so far not a failure, and nothing that shows that MarkLogic will be primarily responsible if it is a failure.
However: most of the defence is along the lines of “we can’t be sure”. That cuts both ways — nobody can say it’s “likely” that LAMP would have been just as bad.
The Third Most Popular Open Source DBMS
We all know that MySQL says it is “the world’s most popular open-source database”. And PostgreSQL has a firm hold on second place while claiming to be, instead, “the world’s most advanced open source database”. But the horse that comes in third can return some money to gamblers who bet “to show”. And the horse that shows momentum or gets close is worth watching for next time.
So I’ll just ignore the dolphin and the elephant in the room, and go on to a harder question: who’s number three?
According to Wikipedia
To find out how many times someone has expressed interest in a topic, I can go to stats.grok.se and ask how many times someone has looked at that topic’s page in Wikipedia. Evil-thinking people could manipulate these numbers with ease, but until now they have had no reason to do so.
So here is the count of accesses on the Wikipedia pages of the nine contending SQL DBMSs, for September last year (blue) and September this year (red).
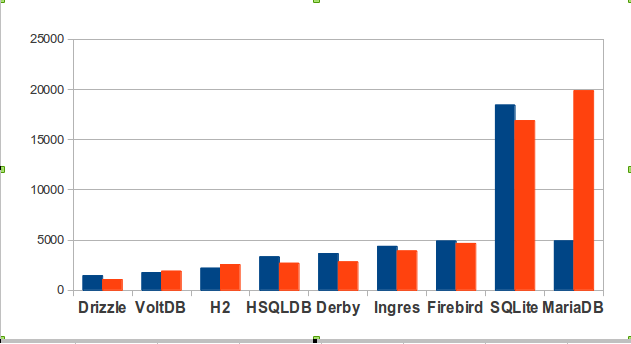
In absolute terms, MariaDB is only slightly ahead. But if you look at momentum (what direction the hit counts have gone between September 2012 and September 2013), interest in MariaDB has risen a great deal while interest in most other DBMSs has declined.
Now here is the chart for open-source NoSQL DBMSs, made the same way. This time I can’t be comprehensive — there are 150 NoSQL products! I’ll show only the ten with the most hits.
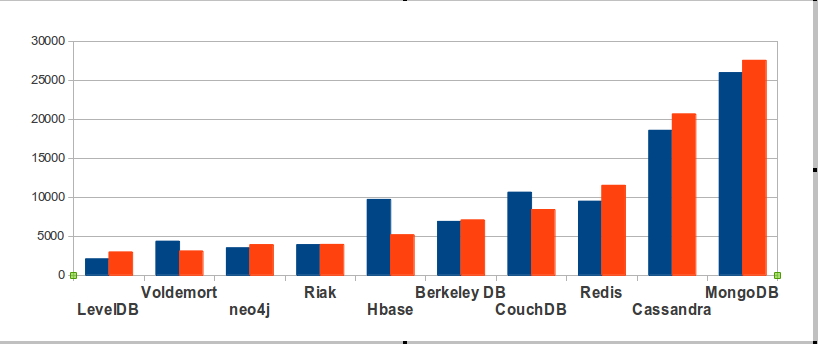
Of course MongoDB is in front. The surprise is that MongoDB’s in-frontness isn’t glaring.
According to The Register
To find out how many times the mass media mentioned a DBMS, I can go to google.com and enter site:theregister.co.uk [DBMS name] -mozilla. Simply googling the DBMS name would fail because Google seems to become more inexact as numbers get bigger, and because “Ingres” and “Firebird” and “Drizzle” and “Cassandra” have alternative meanings that have nothing to do with databases.
So this term is more specific, it’s asking: how many times does search-term appear in The Register (in a non-Mozilla context)? For this purpose I’m positing that “the mass media” and the well-known medium “The Register” are synonymous terms.
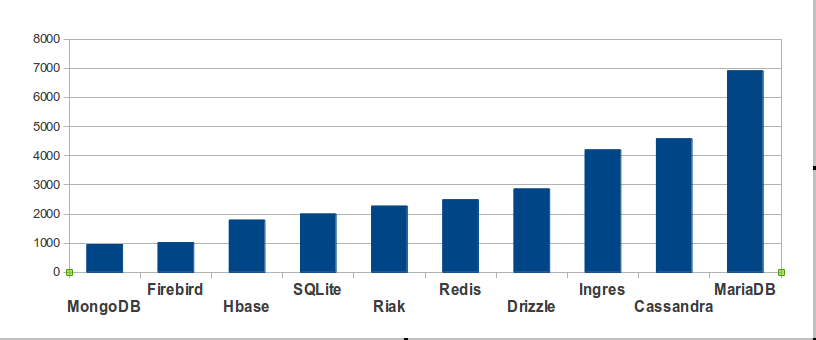
According to Ohloh
To find out how much activity an open-source project has, I can go to ohloh.net and look up the count of commits in the last year. (Ohloh “provides a single aggregate source of information about the world’s open source projects from over 5,000 repositories and forges including GitHub, SourceForge and Google Code, as well as open source foundation repositories including the Eclipse, Mozilla, Apache, and Linux.”) This method has been justly criticized, but is an indicator for developer enthusiasm. Again I am only showing the top ten, other than MySQL or PostgreSQL, for any kind of open-source DBMS.
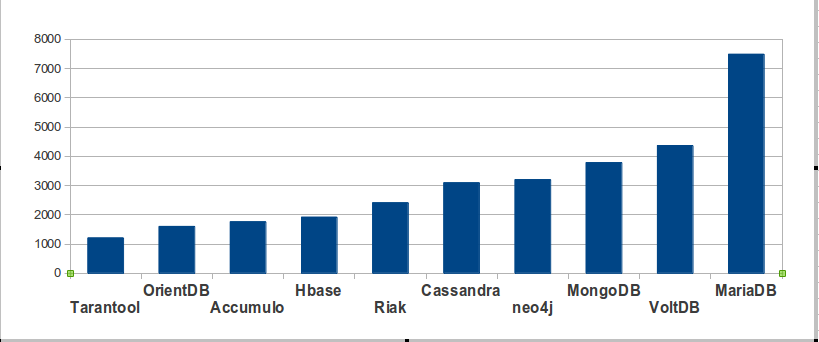
According to db-engines
An Austrian company named solid IT maintains a site named db-engines.com. On it there is “a list of DBMS ranked by their current popularity … updated monthly.” Their ranking is based on (a) Google and Bing hits, (b) Google Trends, (c) Stack Overflow and DBA Stack Exchange (counting the number of technical discussions), (d) indeed.com and simplyhired.com (counting the number of job offers), (e) LinkedIn (counting the number of people who mention the product in their profiles). In other words, none of their criteria match the criteria that I prefer. If one excludes closed-source and MySQL and PostgreSQL from their list, their top 10 hits are:
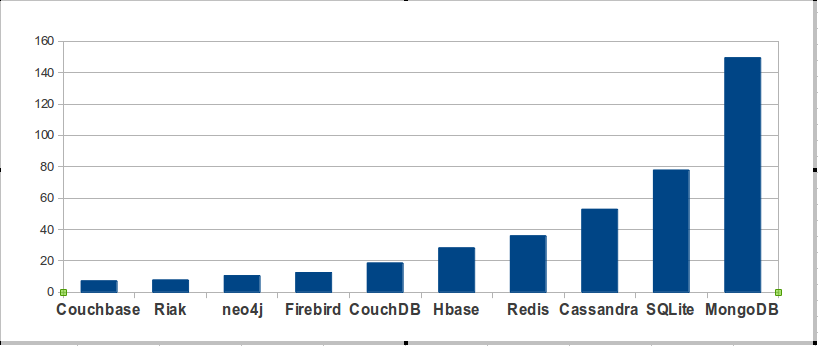
Woe and alas. If their results had been similar to mine, despite their different criteria, then that might have validated both our methods. But they’re very different. I think that’s because my criteria are the only valid ones, but obviously I’m not the only evaluator.
According to the makers
“We believe that there are more copies of SQLite in use around the world than any other SQL database engine, and possibly all other SQL database engines combined.”
— sqlite.org
“Mountain View, Calif. – February 8, 2012 – Couchbase, Inc. [is] the NoSQL market share leader …”
— couchbase.com
“Firebird® is the universal open source database used by approximately 1 million of software developers worldwide.”
— facebook.com/FirebirdSQL
“MongoDB is the leading NoSQL database, with significant adoption among the Fortune 500 and Global 500.”
— mongodb.com
Announcing the finishers
MariaDB is in third place among the open-source SQL DBMSs, and would be third overall if we gave more weight to the numbers “according to Ohloh” and “according to The Register”. But MongoDB and Cassandra nose past it “according to Wikipedia”, and MongoDB is definitely the third-place finisher “according to db-engines”. The claim of SQLite is strongest “according to the makers”.
We have a photo finish, with a blurry camera.