Category: MariaDB
Work around a MariaDB behaviour change
CREATE PROCEDURE p() BEGIN DECLARE v CHAR CHARACTER SET utf8 DEFAULT ''; SELECT * FROM information_schema.routines WHERE routine_name > v; END; CALL p();
Result: with current MariaDB 11.4 or MySQL 8.3: a result set.
Result: with new or future MariaDB: an error message mentioning collations.
The error appears with MariaDB 11.5.1 and later, except for Debian-based distros such as Ubuntu where it appears with MariaDB 11.5.2 and later. It is not a bug, it is a behaviour change.
I’ll describe the error’s cause, the rare situations where the change breaks existing applications, the ways to check, and a workaround.
Assume routine’s character set is Unicode
Let’s say I installed a DBMS and created a UTF8 database. Then I can look at the database’s defaults with
SELECT * FROM information_schema.schemata;
If the server is MySQL 8.3:
The database that I created has default_character_set_name=utf8mb4, default_collation_name = utf8mb4_0900_ai_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
If the server is MariaDB 11.4:
The database that I created has default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
If the server is MariaDB 11.6:
The database that I created has default_character_set_name=utf8mb3, default_collation_name = utf8mb3_uca1400_ai_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
(A system database is sys, performance_schema, information_schema, or mysql.)
The difference between utf8mb3 and utf8mb4 is usually not important. Maybe bigger is better, but I looked at an admittedly-old stack overflow question which established that the extra characters are mostly Gothic, emoji, new Chinese personal names, and some mathematical symbols. At the moment you can’t create routines which require 4-byte UTF8 anyway which means the effect for system tables is nothing.
The difference between uca_0900 and uca_1400 collations is usually not important. The former refers to Unicode Collation Algorithm Version 9 (2016) the latter refers to Collation Algorithm Version 14 (2021). UCA’s version number is “synchronized with the version of the Unicode Standard which specifies the repertoire covered”, which means the order of new emojis or rarely-used scripts will differ. For example the Unicode-14 release notes mention the bronze-age Cypro-Minoan script, so if you use that, you should care.
However, the difference between latin1 and utf8 is usually so important that — I hope — many people will explicitly declare CHARACTER SET UTF8 or some variant, when creating the database or creating the routine. As the manual says: “If CHARACTER SET and COLLATE are not present, the database character set and collation in effect at routine creation time are used.”
Therefore, “DECLARE v CHAR;” will often mean “DECLARE v CHAR DEFAULT CHARACTER SET utf8;”. I’ll assume that’s the case. That’s what causes the error, since with a latin1 default it won’t happen.
The cause
The error message is due to the enhancement request Change default Unicode collation to uca1400_ai_ci which has explanations from the requester and the MariaDB collation expert about some of the things to watch out for, other than this error message. As well, you can find a condemnation of the non-UCA collations such as utf8mb3_general_ci.
The general collation is not awful, for example it knows that “B with dot above” is equal to B.
However, it sees differences where a Unicode _ai_ci collation does not. For example,
SELECT 'お' COLLATE utf8mb4_general_ci =
'オ' COLLATE utf8mb4_general_ci;
is false.
SELECT 'お' COLLATE uca1400_ai_ci =
'オ' COLLATE utf8mb4_uca1400_ai_ci;
is true.
But this makes it dangerous to change a system table. If the server manufacturer simply declared that the default collation of information_schema is henceforth UCA, then suddenly the indexes are no good and primary keys contain duplicates for people who happen to have created routines or tables with similar names.
Everybody learned their lesson about that from a long-ago fiasco. As I commented about it in a heated bug report in 2011: “Why don’t we just change the rules for utf8_general_ci, instead of introducing new collations with new rules? Well, as a matter of fact, that happened for another rule affecting German Sharp S in our version 5.1. The results were catastrophic, because collation affects order of keys in an index, and when index keys are out of the expected order then searches fail (Bug#37046 etc.). The only solution is to rebuild the index and when we have customers with multiple billion rows that’s hugely inconvenient. This change was a stupid error, we have sworn not to repeat it.”
Check routine for upgrade
This isn’t the same as CHECK TABLE … FOR UPGRADE and I don’t think it can be automated, it depends on humans and their particular situations.
Probably most straightforward upgrades will not cause a change of the default so there will be no immediate effect — until you create a routine which has the same expression as what worked before, which won’t work now.
Watch out for comparisons of variables with any columns in system tables.
Watch out for DECLARE HANDLER statements which could hide the error.
Watch out for CREATE TABLE statements which use the variable as a source because you don’t want to change their collation inadvertently.
Watch out for parameters too, as the passer’s character set might differ from the catcher’s.
Workaround: explicit collation
Add a COLLATE clause.
This will indicate the approved collation, so now the comparison will not cause an error.
That is, change
DECLARE v CHAR; /* assuming UTF8 database or explicit UTF8 at some higher level */
to
DECLARE v CHAR CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci;
But not change
WHERE routine_name > v;
to
WHERE routine_name > v COLLATE utf8mb3_general_ci;
This is a minimal change. It insists on the general collation, rather than a Unicode collation, so it’s compatible with the comparand and is less likely to cause an error and is more likely to cause an indexed search.
The COLLATE in the DECLARE clause usually will not interfere with later statements that contain COLLATE. For example, here is a procedure where there might seem to be a conflict:
CREATE PROCEDURE ae()
BEGIN
DECLARE v CHAR CHARACTER SET utf8mb3
COLLATE utf8mb3_general_ci;
SET v = 'ä';
SELECT coercibility(v);
SELECT coercibility((SELECT max(routine_name
COLLATE utf8mb3_german2_ci)
FROM information_schema.routines));
SELECT * FROM information_schema.routines
WHERE routine_name COLLATE utf8mb3_german2_ci = v;
END;
CALL ae();
The nifty coercibility function will say that v is 2 (implicit) while the routine_name is 0 (explicit),
therefore the WHERE’s COLLATE clause trumps the variable’s COLLATE clause,
therefore there is no error,
therefore ‘ä’ = ‘ae’ is true,
therefore there will be one row in the result set.
The workaround has two flaws.
1. For MariaDB 11.6 there’s a feature request Change default charset from latin1 to utf8mb4 So far I haven’t seen that this has happened. But when it does, CHARACTER SET utf8 COLLATE utf8mb3_general_ci could cause trouble because utf8 won’t mean utf8mb3.
Thus COLLATE utf8mb3_general_ci may not be good for the long term, I actually prefer CAST(operand AS CHAR(n) CHARACTER SET utf8mb4) COLLATE utf8mb4_general_ci as something that can work today and can probably work tomorrow.
2. For MySQL 8.3 (which is obsolete) and a similar procedure that looked at tables, I saw the bizarre error message “Error 1267 (HY000) Illegal mix of collations (utf8mb3_tolower_ci,EXPLICIT) and (utf8mb4_0900_ai_ci,EXPLICIT) for operation ‘='” which must have been a bug since there’s no such thing as utf8mb3_tolower_ci, and it doesn’t happen for MySQL 8.4.
3. It’s extra trouble for something that you don’t need in legacy MariaDB versions. To which you might be saying, “Duh, Peter, just use MariaDB’s Executable Comment Syntax to suppress the unneeded stuff when the server isn’t the latest. Well, yes, but I don’t use non-standard syntax if I don’t have to.
Thanks to Alexander Barkov for a suggestion.
How this affected me
The ocelotgui (GUI for MySQL and MariaDB) contains a debugger for stored procedures and functions. It contains DECLARE … CHAR CHARACTER SET utf8; many times. This behaviour change broke it. This commit on GitHub shows my own workaround for it. It did not go through testing with the 11.6 preview. Yesterday I included it in the latest release.
But should the GUI warn about this when parsing CREATE PROCEDURE statements? If anyone thinks so, they can submit a bug report / feature request.
Short note re Progress and NuSphere
Progress Software on 2024-04-19 said more about “considering” an offer for MariaDB plc (the company not the foundation).
They own NuSphere which had a dispute with MySQL AB which was settled in 2002. My happy history as a MySQL employee biases me but I thought that NuSphere was not acting angelically.
I think it won’t happen.
Update: Apparently it didn’t. The 2024-04-26 K1 recommended offer differed.
Packages in MariaDB default mode
MariaDB 11.4 has a new feature: CREATE PACKAGE with routine syntax for the default mode as opposed to sql_mode=’Oracle’. It’s a well-written and long-desired feature but, since it’s alpha, a few things might still need change. I’ll say how it works, with details that aren’t in the manual and probably never will be.
The point
A package is a group of routines (procedures or functions) for which I can CREATE and GRANT and DROP as a unit, all at once.
Roland Bouman wrote a feature request for it in 2005 for MySQL, but MySQL hasn’t got it yet, the workaround is to create whole databases. MariaDB has had CREATE PACKAGE since version 10.3 but only when sql_mode=’oracle’, and only with Oracle syntax (“PL/SQL”) for defining the routines.
Now MariaDB has CREATE PACKAGE with the default sql_mode, i.e. anything except sql_mode=’oracle’, and with ordinary standard-like syntax (“SQL/PSM”) for defining the routines. But it’s a bit of a hybrid because, although the routine definitions within the package are SQL/PSM, the CREATE PACKAGE statements themselves are not.
Package versus Module
CREATE PACKAGE is a PL/SQL statement. CREATE MODULE is the SQL/PSM statement for something functionally very similar.
Here I compare the way MariaDB creates packages versus the way the standard prescribes for modules. I ignore trivial clauses that appear in most CREATE statements.
The MariaDB way
+------------------------------------------------------------+ | CREATE PACKAGE package_name | | [ COMMENT or SQL SECURITY clause ... ] | | [ FUNCTION | PROCEDURE name + COMMENT or SQL clauses ... ] | | END | +------------------------------------------------------------+ +-------------------------------+ | CREATE PACKAGE BODY | | [ variable declaration ... ] | | | routine definition ... ] | | END | +-------------------------------+
The standard way
+-------------------------------------+ | CREATE MODULE module_name | | [ NAMES ARE character_set_name ] | [ [ SCHEMA default_schema_name ] | [ [ path specification ] | | [ temporary table declaration ... ] | | [DECLARE] routine-definition; ... ] | END MODULE | +-------------------------------------+
The most prominent vendor with CREATE PACKAGE is of course Oracle, but others, for example PostgreSQL and IBM, have it too.
The most prominent vendor with CREATE MODULE is IBM but Mimer has it too.
The basic example
So the absolute smallest example of statements that have all the relevant features is:
CREATE PACKAGE pkg1 PROCEDURE p1(); FUNCTION f1() RETURNS INT; END; CREATE PACKAGE BODY pkg1 DECLARE var1 INT; FUNCTION f1() RETURNS INT RETURN var1; PROCEDURE p1() SELECT f1(); SET var1=1; END; SELECT pkg1.f1(); CALL pkg1.p1(); SHOW CREATE PACKAGE pkg1; SHOW CREATE PACKAGE BODY pkg1; GRANT EXECUTE ON PACKAGE db.pkg TO PUBLIC; DROP PACKAGE pkg1;
Documentation and Terminology
In the Canadian Football League there used to be an official term “non-import” for a player who, essentially, wasn’t from the States or Europe or Samoa etc. This caused some complaint because there were simpler terms, like, um, “Canadian” or “national” i.e. native.
Eventually the League realized that adding “non-” was being negative about the default player situation.
I was reminded of that when reading the MariaDB manual, which now has split up the sections for CREATE PACKAGE and CREATE PACKAGE BODY to put “Oracle mode” and “non-Oracle mode”. I am hopeful that someday MariaDB, like the Canadian Football League, will come up with a less negative term such as “default”, or “when sql_mode is the default”. Also I am hopeful — here I speak as the former head of documentation for MySQL — that there will be rearrangement so that the default is shown first, as it will be more important than sql_mode=’oracle’, won’t it?
Another change will happen soon — perhaps by the time you read this — to the BNF. Currently it is
CREATE
[ OR REPLACE]
[DEFINER = { user | CURRENT_USER | role | CURRENT_ROLE }]
PACKAGE [ IF NOT EXISTS ]
[ db_name . ] package_name
[ package_characteristic ... ]
[ package_specification_element ... ]
END [ package_name ]
… which is wrong, adding [ package_name ] after END will just cause an error.
And later
package_specification_function:
func_name [ ( func_param [, func_param]... ) ]
RETURN func_return_type
[ package_routine_characteristic... ]
… which is wrong, it should be RETURNS not RETURN.
Also, since CREATE FUNCTION documentation says “RETURNS type” not “RETURNS func_return_type”, there’s no need to introduce a new term here.
As for CREATE PACKAGE BODY the default mode BNF is undocumented, only Oracle mode BNF is documented. So my description above might be missing some detail, for example maybe it’s possible somehow to declare package-wide cursors and handlers as well as variables.
Error messages
I see two package-related error messages in sql/share/errmsg-utf8.txt
"Subroutine '%-.192s' is declared in the package specification but is not defined in the package body"
and
"Subroutine '%-.192s' has a forward declaration but is not defined"
… which is wrong, there is no such thing as a subroutine, the term is “routine”. (Oracle has a thing called “subprogram” but it too would be a wrong term.)
After I create a package named pkg6 with a procedure p1, if I say
DROP PROCEDURE pkg6.p1;
I get told “PROCEDURE pkg6.p1 does not exist”.
… which is wrong, pkg6.p1 does exist, I can CALL it. It would be better to re-use the message “The used command is not allowed with this MariaDB version”. (Yes, it’s a statement not a command, but I can’t ask for the moon.)
If I say
GRANT EXECUTE ON PACKAGE no_such_package TO PUBLIC;
I get told “FUNCTION or PROCEDURE no_such_package does not exist”
which is wrong, I’m trying to grant on a nonexistent package not a nonexistent routine.
Qualifiers
Suppose we have a package named pkg containing a procedure p1. “CALL p1();” is legal inside another routine in the same package, but outside the package we have to add a qualifier: “CALL pkg.p1();”.
Here is an example that shows why this is dangerous. (Delimiters added so mysql client understands.)
DROP DATABASE pkg; DROP PACKAGE pkg; CREATE DATABASE pkg; CREATE PROCEDURE pkg.p1() SELECT 'database'; CALL pkg.p1(); DELIMITER $ CREATE PACKAGE pkg PROCEDURE p1(); END; $ DELIMITER ; DELIMITER $ CREATE PACKAGE BODY PKG PROCEDURE p1() SELECT 'package'; END; $ DELIMITER ; CALL pkg.p1();
…
The first “CALL pkg.p1();” will display “database”, the second “CALL pkg.p1();” will display “package”. The package has shadowed the database!
People can avoid the danger by adopting a naming convention that database names and package names will always have different prefixes, but they won’t.
Or people can “fully” qualify the package’s P1 by saying “CALL [database_name.].[package_name.].p1();”. But they cannot “fully” qualify the database’s P1 by saying “CALL [catalog_name.][database_name.]p1();” — you’ll see a CATALOG_NAME column in INFORMATION_SCHEMA tables, but it is useless.
Therefore MariaDB should emit a warning message when there’s ambiguity, or support a different qualifier syntax. I’m hopeful that will happen in some future version.
By the way, Mimer “solves” this by disallowing: “The module name is never used to qualify the name of a routine.” It’s unstated, but I suppose this would mean that no two procedures can have the same name in the same schema, even if they are in different packages of the schema.
Also the standard allows SCHEMA and PATH which might be another way to evade the ambiguity, but it’s not necessary.
Metadata
The obvious question after creation is: how can I see what’s in a package?
SHOW CREATE PACKAGE works. SHOW CREATE PACKAGE BODY works.
SHOW PACKAGE STATUS works. SHOW PACKAGE BODY STATUS works.
But they’re SHOW statements and therefore they’re no good.
In INFORMATION_SCHEMA.ROUTINES the package will appear with routine_type = ‘PACKAGE’ and routine_definition = ‘procedure pkg(); end’.
This is odd because
(a) a package is not a routine
(b) there is no procedure named pkg
(c) the actual routine is not a row in information_schema!
I can dig the routine out of another row that has routine_type = ‘PACKAGE BODY’ but I can do it because I have an SQL parser available, other people would be stalled because the body is a mishmash of routines and contents.
Similar cluttering occurs for mysql.proc, although at least there I see PROCEDURE and FUNCTION entries. Remember that the the ‘body’ field might be blank unless you have appropriate privileges.
The obvious answer, similar to what the standard has, is: put routines in INFORMATION_SCHEMA.ROUTINES, and add a PACKAGE_NAME column. Probably something needs to be added to mysql.proc too. Until that happens, since SHOW is not useful, getting metadata for package routines is awkward.
The answer hasn’t appeared in code yet but I’ll assume that what’s obvious will happen.
Variables
I can declare variables that are accessible from all routines in the package. This is possible in CREATE PACKAGE BODY and alas might soon be in CREATE PACKAGE too, if this is done.
Here is an illustration.
DELIMITER $
CREATE OR REPLACE PACKAGE BODY pkg
-- variable declarations
DECLARE a INT DEFAULT 11;
DECLARE b INT DEFAULT 10;
FUNCTION f1() RETURNS INT
BEGIN
SET a=a-1;
RETURN a;
END;
-- routine declarations
PROCEDURE p1()
BEGIN
SELECT a,f1(),a;
END;
-- package initialization section
SET a=a-b;
END;
$
DELIMITER ;
And the question is: what should “CALL pkg.p1();” display?
If you guessed 1, 0, 0 then good for you, but notice what’s unpleasant here. First: we have a procedure’s variable’s value being changed in a way that the procedure doesn’t see. Second: the value changes between the first time it’s selected and the second time it’s selected, in the same statement.
Now, This won’t startle any experienced person, since MariaDB user variables (the ones whose names start with ‘@’) have always worked that way. But I can’t think of any case where that can happen with a DECLAREd variable, so it might startle people who have only worked with standard-like syntax.
I like globals, but I am just expecting that some people will consider it should be noted in a style guide. One of the suggestions I’ve seen (for Oracle) is that package variables are a way to do “constants”. I must emphasize, though, that I’m only talking about what some people might like in style guides, and I’m recognizing that many more people will see an advantage to sharing dynamic variables.
Private routines
Suppose I say
CREATE PACKAGE pkg12 PROCEDURE p1(); END; CREATE PACKAGE BODY pkg12 PROCEDURE p0() SELECT 5; PROCEDURE p1() CALL p0(); END; CALL pkg12.p1() /* This succeeds */; CALL pkg12.p0() /* This fails */;
Thus p0 is not in CREATE PACKAGE but p0 is in CREATE PACKAGE BODY. That is legal provided p0 comes before p1 (no forward references please). In this case p1 is a “public” routine — I can CALL pkg12.p1() from outside the package. However, p0 is a “private” routine — I cannot CALL pkg12.p0() from outside the package. I will see “Error 1305 (42000) PROCEDURE pkg12.p0 does not exist”.
Nothing against private, but since pkg12.p0 does exist, I think a message that’s more explicit would help somebody in ages to come. Otherwise, it should be made obvious. Probably a naming convention would be a good way to do that. A comment would not be a good way because many clients, including mysql and ocelotgui, have –skip-comments as a default.
Privileges
To allow CREATE PACKAGE (example);
GRANT CREATE ROUTINE ON w2.* TO k@localhost;
To allow EXECUTE of a package (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost;
This is a good thing, the usual privileges affecting routines will affect packages, as a whole. It’s a bit odd that a qualifier is necessary for GRANT but not for CALL; however.
To allow SHOW CREATE PACKAGE (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost; GRANT ALTER ROUTINE ON PACKAGE w2.pkg TO k@localhost;
This is a strange thing, currently one way to make SHOW CREATE possible is to grant ALTER ROUTINE.
ALTER
MariaDB has eleven ALTER statements, but ALTER PACKAGE is not one of them. Given that Oracle has one, and DB2 has ALTER MODULE, and it’s mentioned in a MariaDB document, I expect this will eventually be added with an excuse of “orthogonality”.
Debugger
The debugger in the Ocelot GUI does not yet work with routines inside packages. However, in a version which will be released soon, the “recognizer” will see MariaDB 11.4 syntax and be able to alert typists about what syntax is expected as they type, the same experience that they get for other statements.
This enhancement is already in the source code, in this patch.
Update
2024-02-15: MariaDB has done some fixes for the documentation matters that I mentioned, and there are plans for others in their bugs database, including: MDEV-33382 Documentation fixes for CREATE PACKAGE and CREATE PACKAGE BODY, MDEV-33384 ALTER PACKAGE [ BODY ] statement, MDEV-33385 Support package routines in metadata view, MDEV-33386 Wrong error message on `GRANT .. ON PACKAGE no_such_package ..`, MDEV-33395 I_S views to list stored packages, MDEV-33399 Package variables return a wrong result when changed inside a function, MDEV-33403 Document stored packages overview, MDEV-33428 Error messages ER_PACKAGE_ROUTINE_* are not good enough. For further developments follow MariaDB’s announcements. Meanwhile ocelotgui 2.2 has appeared which recognizes the new syntax.
SQL:2023 and how well MySQL and MariaDB comply
SQL:2023 is now the official SQL standard. I’ll compare some of the new optional features with what MySQL and MariaDB support already, and say whether I judge they are compliant.
At the moment I don’t have draft documents (my membership on the standard committee ended long ago), so I gratefully get my news from Oracle and Peter Eisentraut. It’s early days, I may be making mistakes and may be guessing wrong about what new features are important.
LPAD and RPAD
MySQL and MariaDB examples:
SELECT LPAD('hi',3,'?'); causes '?hi'.
SELECT RPAD('hi',3,'?'); causes 'hi?'.
Judgment: compliant with SQL:2023 optional feature T055.
The third argument is optional and default is the space character. For some reason I’m not seeing the documentation in the manuals, but it is standard behaviour.
LTRIM and RTRIM and BTRIM
MySQL and MariaDB examples:
SELECT LTRIM(' *'); -- causes '*'.
SELECT RTRIM('* '); -- causes '*'.
Judgment: not compliant with SQL:2023 optional feature T056.
Although SQL:2023 now has LTRIM and RTRIM, they are two-argument,
perhaps a bit like Oracle.
Also SQL:2023 has BTRIM for trimming from both ends. Although MySQL and MariaDB have TRIM(BOTH …), it’s not quite the same thing.
VARCHAR instead of VARCHAR(length)
MySQL and MariaDB example:
CREATE TABLE t(s1 VARCHAR(1)); -- (length) is mandatory
Judgment: not compliant with SQL:2023 optional feature T081
A DBMS that supports feature T081 doesn’t have to include a maximum length, it’s up to the implementation, which in this situation could be 65535 bytes. This is unfortunate and it might be my fault, I think I used to insist that length should be mandatory in MySQL.
Although I can use the TEXT data type instead for indefinite-length strings, it has different characteristics.
ANY_VALUE, emphasizing use with GROUP BY
MySQL and MariaDB example:
SELECT s1, s2 FROM t GROUP BY s1;
Judgment: compliant with SQL:2023 optional feature T626, almost, alas
Probably you noticed that s2 is not in the GROUP BY clause, and yet the syntax is legal — any of the original t values could appear.
The standard would yield something similar with different syntax: SELECT s1, ANY_VALUE(s2) FROM t GROUP BY s1;
Or, as Oracle describes it, “[ANY_VALUE] eliminates the necessity to specify every column as part of the GROUP BY clause”.
That means it’s non-deterministic. Usually I’ve cared more about non-standardness. But now that argument is weaker.
ORDER BY, emphasizing use with GROUP BY
MySQL and MariaDB example:
CREATE TABLE t (s1 int, s2 int, UNIQUE (s2)); INSERT INTO t VALUES (1,1),(7,2),(5,3); SELECT s1 FROM t GROUP BY s1 ORDER BY s2;
Judgment: not compliant with SQL:2023 optional feature F868.
I’m probably misunderstanding something here about the intent, but the effect is that something that’s not in the GROUP BY clause can determine the ordering. In this case, because column s3 is unique, it’s maybe not utterly absurd. But in MySQL and MariaDB, the result is not guaranteed to be in order by column s3.
GREATEST and LEAST
MySQL and MariaDB syntax:
SELECT GREATEST(2,1,3); -- result = 3 SELECT LEAST(2,1,3); -- result = 1
Judgment: compliant with SQL:2023 optional feature T054
UNIQUE NULLS DISTINCT
MySQL and MariaDB example:
CREATE TABLE t (s1 INT, UNIQUE(s1)); INSERT INTO t VALUES (NULL),(NULL);
Judgment: partly compliant with SQL:2023 feature F292 unique null treatment
To understand this, your required reading is my old blog post
NULL and UNIQUE.
You have to read the whole thing to understand that the
standard document was not contradictory, and that MySQL
and MariaDB have always been compliant, because …
In a UNIQUE column, you can insert NULLs multiple times.
However, because lots of people never understood, there are implementations where you cannot do so. Therefore feature F292 allows new syntax:
CREATE TABLE t (s1 INT, UNIQUE NULLS DISTINCT (s1)); or CREATE TABLE t (s1 INT, UNIQUE NULLS NOT DISTINCT (s1));
MySQL and MariaDB could easily half-comply by allowing the first option and saying it is the default. (The standard now says the default is implementation-defined.) (A backward step.)
Hexadecimal and octal and binary integer literals
MySQL and MariaDB example:
SELECT 0x4141;
Judgment: not compliant with SQL:2023 optional feature T661
Did you notice that I said “integer literals”? That’s what’s wrong, 0x4141 in standard SQL is now supposed to be an integer, decimal 16705. But MySQL and MariaDB will treat it as a string, ‘AA’.
It is always legal for an implementation to have “non-conforming” syntax that causes “implementation-dependent” results. That’s what happened with 0x4141, in the mists of time. But now, if one decides to “conform” with the syntax of this optional feature, one must change the behaviour drastically: not merely a different value but a different data type.
I suppose that the road to compliance would involve deprecations, warnings, sql_mode changes, etc., lasting years.
Underscore digit separators
MySQL and MariaDB example:
CREATE TABLE t (10_000_000 INT); INSERT INTO t VALUES (1); SELECT 10_000_000;
Judgment: not compliant with SQL:2023 optional feature T662 Underscores in numeric literals
Big numbers like 10,000,000 cannot be expressed in SQL using commas because that looks like three separate values. The solution, which I see was implemented a few years ago in Python, is to express 10,000,000 as 10_000_000 — that is, underscores instead of commas.
In standard SQL, an identifier cannot begin with a digit. But in MySQL and MariaDB, it can, so 10_000_000 is a legal regular identifier. This is another example of an extension that causes trouble in a long term.
There is an idiom about this, usually about chickens: “come home to roost”. As Cambridge Dictionary puts it: “If a past action, mistake, etc. comes home to roost, it causes problems at a later date, especially when this is expected or seems deserved …”
JSON
MariaDB example:
CREATE TABLE t (s1 JSON);
Judgment: partial compliance with SQL:2023 feature T801 JSON data type etc.
I’m not going to try to analyze all the new JSON options because it’s a big subject. Also there’s a CYCLE clause and a new section of the standard, part 16 Property Graph Queries (SQL/PGQ), which I don’t think is appropriate to get into during this comparison of features in the foundation. Maybe some other time.
Score
Actually, despite pointing to some non-compliance, I have to give credit to the people who decided to implement some features long before they became standard. (And I don’t credit myself at all because they appeared before I was a MySQL architect, and in fact I objected to some of them while I was with MySQL AB.)
Well done.
ocelotgui news
The new version of the Ocelot GUI application, ocelotgui, is 2.0. As always the source and executable files are on github. The biggest new feature is charts. I’ll say more in a later blog post.
Update added 2023-06-12: Re ANY_VALUE: see comment by Øystein Grøvlen. As for the question from Federico Razzoli, I cannot give an authoritative answer. Also I’ve been reminded that MariaDB request MDEV-10426 regarding ANY_VALUE is marked as part of MariaDB 11.2 flow, but until then I guess MySQL is a bit ahead.
Offset and fetch clauses in MariaDB
A new feature in MariaDB 10.6 is “Implement SQL-standard SELECT … OFFSET … FETCH”.
I’ll say what’s not in the manual: mention other vendors, add details, talk style, show how to get the wrong answer, describe WITH TIES, mention alternatives, experiment with locks, and list 11 minor flaws.
Other vendors
Products with support for OFFSET … FETCH:
Oracle, DB2, SQL Server.
Products with support for LIMIT … OFFSET:
Tarantool, MySQL, Vertica, PostgreSQL.
Products with support for neither:
Firebird, ScyllaDB, Actian.
This isn’t a complete list — there are lots of SQL products nowadays — but it does include the “Big Three”. All of them support SELECT … OFFSET … FETCH.
Syntax details
The BNF actually is:
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES } ]
The “start” and count” must be unsigned integers if they’re literals, but if they’re declared variables then they can be NULL (in which case they’re treated as zeros), or can be negative (in which case they’re treated as -infinity for “start” and +infinity for “count”) (but depending on undefined behaviour isn’t always fun).
The lowest offset is zero which is the first row, and the lowest count is zero, that is, it is possible to select zero rows. If count is omitted, then 1 is assumed.
Style
If you haven’t read the descriptive SQL style guide and clicked like, then you won’t understand this section, skip it.
OFFSET and FETCH are both either “clause starts” or “sub-clause starts” so if the choice is to put separate clauses on separate lines, then they are.
Deciding whether to use ROW rather than ROWS, or FIRST rather than NEXT, (neither of which make a difference for server behaviour), one could base a rule on English grammar:
(1) If there was an OFFSET clause with a non-zero number-of-rows, then NEXT, else FIRST. If number-of-rows is greater than one, or unknown, then ROWS, else ROW.
or one could base a rule on what comes first in the MariaDB manual BNF:
(2) The BNF has {FIRST|NEXT} and {ROW|ROWS} so FIRST and ROW.
or one could base a rule on what the examples in the manual use most often:
(3) FIRST and ROWS
or one could base a rule on whatever is shortest:
(4) NEXT and ROW.
I like (3), for example
OFFSET 5 ROWS FETCH FIRST 1 ROWS ONLY;
but there’s no established rule yet so I’ll vary the format in what follows.
How to get the wrong answer
Try this:
CREATE TABLE td (char_1_column CHAR(1) DEFAULT '1',
null_column INT,
char_2_column CHAR(2));
CREATE INDEX int_char_1_column_plus_char_2_column
ON td (char_1_column, char_2_column);
INSERT INTO td (char_2_column)
VALUES ('a'),('b'),('c'),('d'),('e'),('ab');
SELECT char_2_column, null_column
FROM td
WHERE char_1_column > '0'
OFFSET 0 ROWS
FETCH FIRST 4 ROWS ONLY;
SELECT char_2_column, null_column
FROM td WHERE char_1_column > '0'
OFFSET 4 ROWS
FETCH FIRST 4 ROWS ONLY;
Result of first SELECT:
(‘a’,NULL),(‘ab’,NULL),(‘b’,NULL),(‘c’,NULL)
Result of second SELECT:
(‘e’,NULL),(‘ab’,NULL)
So there’s no (‘d’,NULL) and there’s a duplicate (‘ab’,NULL). Wrong answer.
I don’t think it’s a bug because, in the absence of an ORDER BY statement, there is no guarantee which rows will be skipped in the second SELECT. But luckily it’s due to an exotic situation which is easy to avoid: the combined index on a non-unique column and a multi-character string column. Just don’t use the index, and all is well.
WITH TIES
The effects of the new syntax are mostly the same as with LIMIT … OFFSET, but WITH TIES is new.
Suppose there are 6 rows, selected in order (there must be an ORDER BY clause):
(NULL),(NULL),(1),(1),(2),(2).
Then OFFSET 0 ROWS FETCH NEXT 1 ROWS WITH TIES will gives us (NULL),(NULL).
Thus WITH TIES doesn’t mean that the two values are technically “equal”, they merely must be peers, so NULLS tie. The interesting thing is that when you ask for “NEXT 1 ROW” you get the next 2 rows. But that only applies to FETCH, it doesn’t apply to OFFSET, therefore this could be a mistake:
SELECT * FROM t ORDER BY pk OFFSET 0 ROWS FETCH NEXT 1 ROWS WITH TIES; SELECT * FROM t ORDER BY pk OFFSET 1 ROWS FETCH NEXT 1 ROWS WITH TIES;
With the example 6 rows, the second SELECT will return a row that was already returned for the first SELECT. It would be better to say, instead of “OFFSET 1 ROWS”, “OFFSET (number of rows returned by the previous SELECT) ROWS”.
Alternatives
A standard way to fetch only one row:
BEGIN NOT ATOMIC DECLARE v INT; DECLARE c CURSOR FOR SELECT * FROM t; OPEN c; FETCH NEXT FROM c INTO v; END;
A non-standard way to fetch only one row: (remember to restore @@sql_select_limit later):
SET sql_select_limit = 1; SELECT * FROM t;
A way to offset by 10 and fetch 10 (this assumes that pk has all the integers in this range i.e. it depends on user knowing about contents and indexes, and assumes that user only wants to go forward without skipping)
SELECT * FROM t WHERE pk > 10 AND pk <= 10 + 10;
A way to let the user do the offsets and fetches (this depends on the client being a GUI and the user knowing how to click on a scroll bar)
SELECT * FROM t;
… although users often only look at the first few pages (think of how often you use Google and only click Next a few dozen times).
Locking
Will locking, or SET TRANSACTION ISOLATION LEVEL, guarantee consistency?
For a test, I started two clients. On the first, I said:
CREATE TABLE pks (pk INT PRIMARY KEY);
BEGIN NOT ATOMIC
DECLARE v INT DEFAULT 0;
WHILE v <= 10000 DO
INSERT INTO pks VALUES (v);
SET v = v + 1;
END WHILE;
END;
SET @@autocommit=0;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION;
SELECT * FROM pks
WHERE pk > 400
OFFSET 10 ROWS
FETCH FIRST 2 ROWS ONLY FOR UPDATE;
On the second, I said:
SET @@autocommit=0; SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; START TRANSACTION; DELETE FROM pks WHERE pk = 7227; DELETE FROM pks WHERE pk = 405; DELETE FROM pks WHERE pk = 411;
Result: The first DELETE succeeds, the second DELETE hangs until I say ROLLBACK; on the first client. The third DELETE would also have hung if I had said it first.
In other words: the rows between 401 and 410 (the rows skipped due to OFFSET) are locked, and the rows between 411 and 412 (the rows picked up by FETCH) are locked, but the rows after 412 (the rest of the rows matching WHERE) are not locked.
What this means, of course, is that ordinarily you can’t be certain that you’re paging through a consistent set. If this is a concern (it shouldn’t always be), make a copy on either the server or the client.
Minor Flaws
A few incompatibilities with standard SQL or another DBMS or another bit of MariaDB 10.10 syntax.
Table t has 4 rows created thus:
CREATE TABLE t (s1 INT, s2 INT); INSERT INTO t VALUES (1,2),(2,1),(3,2),(4,1);
1.
WITH x AS (SELECT * FROM t OFFSET 5 ROWS) SELECT * FROM x;
Result: Success, all 4 rows in table t are returned. It appears that the OFFSET clause is ignored.
2.
BEGIN NOT ATOMIC DECLARE var1 DECIMAL(0); SELECT * FROM t OFFSET var1 ROWS; END;
Result: Error 1691 (HY000) A variable of a non-integer based type in LIMIT clause
Never mind whether var1 should be accepted. The error message is obsolete, I was not using a LIMIT clause.
3.
BEGIN NOT ATOMIC DECLARE var1 BIT DEFAULT NULL; SELECT * FROM t OFFSET var1 ROWS; END;
Result: Success, all rows are returned.
Sometimes non-integer variables are illegal, but here a BIT variable is legal.
MariaDB calls BIT a numeric data type but SELECT * FROM t OFFSET b’1′ ROWS wouldn’t work.
4.
SET sql_mode='oracle';
CREATE PROCEDURE p2 AS
var1 NUMBER := 1;
BEGIN
SELECT * FROM t OFFSET var1 rows;
END;
(Don’t forget to restore sql_mode later.)
Result: Error 1691 (HY000) A variable of a non-integer based type in LIMIT clause
That’s right for standard SQL (“The declared type … shall be an exact numeric with scale 0”) but Oracle says it might be more forgiving (“If rowcount includes a fraction, then the fractional portion is truncated.”)
5.
SELECT * FROM t OFFSET 1 ROWS FETCH FIRST 0 ROWS ONLY;
Result: Success, zero rows are returned.
That’s wrong for standard SQL, which would return “data exception — invalid row count in fetch first clause”.
6.
SELECT * FROM t FETCH FIRST 1 ROWS ONLY;
Result: Success.
But the manual’s BNF is
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }
which might suggest to newbies that the OFFSET clause is compulsory before FETCH.
7.
SET @x = 1; SELECT * FROM t OFFSET @x ROWS;
Result: Syntax error.
I can find, by saying CREATE TABLE .. AS SELECT @x; and then saying SHOW CREATE TABLE or SELECT … FROM INFORMATION_SCHEMA, that @x is BIGINT. BIGINT declared variables are legal, and I can use variables that start with @ in some other situations. This is how things go when variables have variable types.
8.
SHOW WARNINGS OFFSET 1 ROW;
Result: Success. I believe this is reasonable, and of course any non-standard syntax can be handled in an implementor-defined way. But it’s not documented on the documentation page for SHOW WARNINGS.
9.
BEGIN NOT ATOMIC DECLARE only INT DEFAULT 2e2; DECLARE row INT DEFAULT (SELECT 5); SELECT * FROM t OFFSET ROW ROW FETCH FIRST ONLY ROW ONLY; END;
Result: Success.
In standard SQL:2016 ROW and ONLY are reserved words.
MariaDB tends to accept goofiness since it’s not your nanny, but I believe in egregious cases the standard strictness is preferable after reasonable notice.
10.
SELECT * FROM t FETCH FIRST 1 ROWS ONLY ROWS EXAMINED 1;
Result: Error.
Another inconsistency, since LIMIT 1 ROWS EXAMINED 1 is legal.
11.
VALUES (1),(2),(3) OFFSET 1 ROW FETCH FIRST ROW ONLY;
Result: Success.
This is fine, but once again undocumented.
ocelotgui support
The Ocelot GUI client recognizes MariaDB syntax when connected to a MariaDB server, so if you need features like autocomplete after OFFSET to be correct then download it from github.
FOR … END FOR
Let’s start by combining one new MariaDB feature — VALUES (5) which is the standard equivalent of the old non-standard “SELECT 5” — with another new feature in MariaDB 10.3.5, the FOR … END FOR statement.
mariadb>BEGIN NOT ATOMIC > DECLARE v INT DEFAULT 0; > FOR a IN (VALUES (7)) DO SET v = v + 1; END FOR; > SELECT v; >END; Error 2013 (HY000) Lost connection to MySQL server during query
Oops. However, the MariaDB folks now know about this, it’s bug MDEV-15940″ and they know about the other bugs that I’ll mention in this post, so there’s no problem provided you wait for the next version.
FOR … END FOR works prettily so I decided to describe it. The official documentation isn’t out yet so this could change.
FOR x IN (subquery) DO … END FOR
Example:
BEGIN NOT ATOMIC DECLARE v INT DEFAULT 0; FOR a IN (SELECT 5) DO SET v = v + 1; END FOR; SELECT v; END;
The SELECT will return ‘1’ because the SET statement happened once, because SELECT 5 returns 1 row. We must put (SELECT 5) inside parentheses because there must be a way to find where it ends — the word DO is not reserved and therefore is useless as a marker for the parser.
FOR x IN cursor DO … END FOR
Example:
CREATE TABLE t (s1 INT);
INSERT INTO t VALUES (1),(2),(3);
BEGIN NOT ATOMIC
DECLARE v2, v3 INT DEFAULT 0;
BEGIN
DECLARE cn CURSOR FOR SELECT * FROM t;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET v3 = 1;
FOR cn_record IN cn
DO
SET v2 = v2 + cn_record.s1;
END FOR;
END;
SELECT v2, v3;
END;
FOR cn_record IN cn means “loop with cursor cn, which was declared earlier”. And cn_record according to MariaDB is a row variable that can be used within the loop, so cn_record.s1 is the value of s1 within a given row of table t.
Given that table t has 3 rows containing (1),(2),(3), and given that the obvious intent is that v2 will end up with the sum, you might think the SELECT will return v2 = 6, eh? Well, you’re thinking right, it does. This is a way to go through a cursor, with each iteration doing an automatic FETCH.
And, since there’s a CONTINUE HANDLER that says we’ll set v3 = 1 when there are no more rows to fetch, you might think the SELECT will return v3 = 1, eh? Well, you’re thinking reasonably (I think), but it doesn’t. The handler isn’t brought into play, the NOT FOUND condition is automatically cleared when the loop ends.
Summary: this kind of FOR does automatic cursor-open and cursor-fetch, but not automatic cursor-close. To me that looked like a bug, the way I interpret the standard document, “CLOSE cn;” is supposed to happen. And MariaDB agrees, it’s bug MDEV-15941.
FOR x IN low-number .. high-number DO … END FOR
Example:
SET @v = 0; CREATE PROCEDURE p() BEGIN FOR a IN 1 .. 3 DO SET @v = @v + a; END FOR; SELECT @v; END;
MariaDB 10.3 comes with a boatload of Oracle/PostgreSQL syntax, often known as “PL/SQL” (their deviation from the standard “SQL/PSM” syntax which MySQL/MariaDB have followed in the past). But all the PL/SQL stuff is supplied if and only if you say
SET @@sql_mode='oracle';
The FOR … END FOR statement is an exception, it works in the default mode too. That’s deliberate. And it’s equivalent to
SET a = 1; WHILE a <= 3 DO ... SET a = a + 1; END WHILE;
So the SELECT in the above example displays '6'.
The ".." is a new operator, vaguely similar to the "range operators" in languages like Ruby and Perl. But SQL already has a range operator, it's called BETWEEN. And now MariaDB won't be able to accept the SQL Server syntax where ".." is for qualifiers ("a..b" means "schema a + default table + column b").
I encountered a problem during the test, with:
FOR a IN (SELECT 1) .. 3 DO SET @v = @v + a; END FOR;
Technically this should be legal because “low-number” can be any expression, including a subquery. In this case, though, subqueries mean something else, so it is not legal. This is now bug MDEV-15944″.
I enthusiastically recommend: don’t use this, use WHILE.
Differences from the standard
My first example looked like this:
FOR a IN (SELECT 5) DO SET v = v + 1; END FOR;
In standard SQL it would have looked like this:
FOR (VALUES (5)) DO SET v = v + 1; END FOR;
… The standard doesn’t require mentioning “a” when there is no need to refer to “a” inside the loop. The fact that the standard would use “VALUES (5)” is, as we’ve seen, something that MariaDB will soon support too.
My second example looked like this:
FOR cn_record IN cn
DO
SET v2 = v2 + cn_record.s1;
END FOR;
In standard SQL it would have looked like this:
FOR cn_record AS cn
DO
SET v2 = v2 + s1;
END FOR;
So it’s a difference between “IN” and “AS”, and between “cn_record.s1” and “s1”. However, I could have said “cn_record.s1” in standard SQL too, it’s optional when there’s no ambiguity.
There are serious matters that underlie that innocent-looking difference with “cn_record.”, about which I now digress.
Shadowing, a Digression
In the following, should “SELECT v FROM t;” display 1, or 2, or 3?
BEGIN NOT ATOMIC
a: DECLARE v INT DEFAULT 1;
BEGIN
b: DECLARE v INT DEFAULT 2;
CREATE TABLE t (v INT);
INSERT INTO t VALUES (3);
SELECT v FROM t;
END;
END;
Answer: in MariaDB it’s 2. Inner scope beats outer scope, and variable declaration beats table definition. This is an old MySQL flaw that MariaDB has inherited (Bug #5967 Stored procedure declared variable used instead of column). The workaround, if you actually want “column v of table t”, is to use a qualifier, as in “SELECT t.v FROM t;”.
But what if you wanted to refer to the first declared variable? That would be easy too, in standard SQL you would qualify with the label, as in “SELECT a.v FROM t;”. Unfortunately — another old MySQL flaw that MariaDB has inherited — you can’t use [label.]variable_name for qualification.
As a result of these two flaws, we could have trouble in our FOR … END FOR loop if we used unqualified names like “s1”. Therefore in MariaDB you have to say “cn_record.s1” if you want the FOR variable, that is, qualification is compulsory. That’s a solution.
But the solution depends on a third flaw.
In standard SQL in this FOR loop “cn_record” becomes a label, and that’s why “cn_record.s1” would be legal — cn_record is a label qualifier. That’s not the case with Oracle/MariaDB, where “cn_record” is a variable with type = ROW — cn_record is a row-variable qualifier. The effect is the same for the particular example that I used, but that’s just luck.
The flaws do not mean that the implementor did something wrong for FOR … END FOR, rather it means that the blame lies in MySQL’s history. It would be grossly wrong to blame the standard, which has no flaws.
Differences from the Standard, continued
My third example looked like this:
FOR a IN 1 .. 3 DO SET @v = @v + a; END FOR;
In standard SQL it would have looked like this:
[empty prairie with crickets chirping in the darkness]
For more about the original plan for adding FOR … END FOR to MySQL in a standard way, go to “WL#3309: Stored Procedures: FOR statement” and click “High-level architecture”.
ocelotgui
Of course we’ve changed Ocelot’s GUI client for MySQL/MariaDB so that it recognizes most of the new syntax in MariaDB 10.3. We haven’t changed the debugger, though, so it won’t handle statements containing FOR … END FOR.
The simultaneous_assignment mode in MariaDB 10.3.5
Starting with MariaDB 10.3.5, if you say sql_mode = ‘simultaneous_assignment’, then
UPDATE t SET a = b, b = a;
will swap b and a because a gets what’s originally in b, while b gets what’s originally in a (as of the start of the SET for a given row), instead of what was going on before, which was “Assignments are evaluated in left-to-right order”.
I will list things that I like or don’t like, and behaviour-change cases to watch for.
I like it that this is standard SQL at last
I don’t know any other vendor who ever did left-to-right assignments, and they had a good reason.
Way back in SQL-86, section 8.11
SET <object column> = <value expression> | NULL [, <object column> = <value expression> | NULL …
“If the <value expression> contains a reference to a column of T, the reference is to the value of that column in the object row before any value of the object row is updated.”
In case anyone still didn’t get it, SQL-92 added the sentence:
“The <value expression>s are effectively evaluated before updating the object row.”
Unfortunately later versions of the standard were slightly denser, such as:
“11) Each <update source> contained in SCL is effectively evaluated for the current row before any of the current row’s object rows is updated.”
The abbreviation “SCL” is the set clause list. The word “rows” is not a typo, but it’s for a special situation, we can still interpret as “before the object row is updated”.
Thus what we’re talking about is optionally following the standard.
So hurrah, let’s put equestrian statues of the MariaDB seal in main squares of our cities.
I don’t like the name
I’ll admit that the effect can be the same, and I’ll admit that some SQL Server commenters like to refer to this as doing things “all at once”. (See here and here.) But the standard description isn’t really demanding that all the assignments be simultaneous.
And the term “simultaneous assignment” can make some programmers
think of “parallel assignment”, as in this example (from Wikipedia)
a, b := 0, 1
A name like “evaluate_sources_first_during_updates” would have been better.
I don’t like that it’s a mode
We all know the problems of setting a global variable that people don’t see or think about when they create SQL statements.
So perhaps it would have been better to make a change to the UPDATE syntax, e.g.
UPDATE /*! new-style-update */ NEW STYLE t SET …;
It doesn’t solve the problem cleanly — now every statement has non-standard syntax in order to perform in a standard way — but it means you don’t get the behaviour change in every statement, only in the ones where you ask.
Or perhaps it would have been better to produce a warning: “You are using an sql_mode value that changes the behaviour of this particular UPDATE statement because evaluation is no longer left to right.” I don’t know if it would be hard. I don’t know if it’s too late.
Setup for examples
Following examples are done with a one-row table, made thus:
CREATE TABLE t (col1 INT, col2 INT, PRIMARY KEY (col1, col2)); INSERT INTO t VALUES (1, 2);
The MariaDB version is 10.3.5 downloaded on 2018-03-20.
Assigning with swaps and variables
SET @@sql_mode='simultaneous_assignment'; UPDATE t SET col1 = 1, col2 = 2; UPDATE t SET col1 = col2, col2 = col1; SELECT * FROM t; -- Result: col1 is 2, col2 is 1.
This is different from what happens with @@sql_mode=”. This is the best example that shows the new mode works.
SET @@sql_mode='simultaneous_assignment'; SET @x = 100; UPDATE t SET col1 = @x, col2 = @x := 200; SELECT * FROM t; -- Result: col1 is 100, col2 is 200.
This is not different from what happens with @@sql_mode=”. Conclusion: if you use the non-standard variable-assignment trick, the value is not updated in advance.
What about the SET statement?
DROP PROCEDURE p; SET @@sql_mode='simultaneous_assignment'; CREATE PROCEDURE p() BEGIN DECLARE v1 INT DEFAULT 1; DECLARE v2 INT DEFAULT 2; SET v1 = v2, v2 = v1; SELECT v1, v2; END; CALL p(); -- Result: v1 is 2, v2 is 2.
This is not different from what happens with @@sql_mode=”. Conclusion ‘simultaneous_assignment’ does not affect assignments with the SET statement.
Perhaps people will expect otherwise because SET statements look so similar to SET clauses, but this is actually correct. The way the standard defines things, for syntax that is similar to (though not exactly the same as) “SET v1 = v2, v2 = v1;”, is: the statement should be treated as equivalent to
SET v1 = v2; SET v2 = v1;
Good. But come to think of it, this is another reason to dislike the misleading mode name ‘simultaneous_assignment’. SET statements are assignments but @@sql_mode won’t affect them.
What about the INSERT statement?
SET @@sql_mode='simultaneous_assignment'; TRUNCATE TABLE t; INSERT INTO t SET col1 = col2, col2 = 99; SELECT * FROM t; -- Result: col1 is 0, col2 is 99.
Conclusion: ‘simultaneous_assignment’ does not affect INSERT … SET statements, processing is left to right. This looks inconsistent to me, but it’s not wrong.
What about the INSERT ON DUPLICATE KEY UPDATE statement?
SET @@sql_mode='simultaneous_assignment'; UPDATE t SET col1 = 0, col2 = 1; INSERT INTO t VALUES (0, 1) ON DUPLICATE KEY UPDATE col1 = col2, col2 = col1; SELECT * FROM t; -- Result: col1 is 1, col2 is 0.
Conclusion: ‘simultaneous_assignment does affect INSERT ON DUPLICATE KEY UPDATE. Nobody said that it has to (this syntax is a MySQL/MariaDB extension), but surely this is what everyone would expect. Good.
Triggers and constraints
I could not come up with a case where ‘simultaneous_assignment’ affected the order in which triggers or constraints are processed. Good.
Assigning twice to the same column
SET @@sql_mode='simultaneous_assignment'; UPDATE t SET col1 = 3, col2 = 4, col1 = col2; -- Result: error.
Good. There’s supposed to be an error, because (quoting the standard document again) “Equivalent <object column>s shall not appear more than once in a <set clause list>.”
Actually this doesn’t tell us something new about ‘simultaneous_assignment’, I only tried it because I thought that MariaDB would not return an error. Probably I was remembering some old version before this was fixed.
Multiple-table updates
From the bugs.mysql.com site quoting the MySQL manual:
“Single-table UPDATE assignments are generally evaluated from left to right. For multiple-table updates, there is no guarantee that assignments are carried out in any particular order.”
I don’t see an equivalent statement in the MariaDB manual. So I conclude that even for multiple-table updates the assignments will be done in a standard way, but couldn’t think of a good way to test.
There are other things
The really big things in MariaDB 10.3.5 are PL/SQL and the myrocks engine. So, just because I’ve looked at a small thing, don’t get the impression that 10.3.5 is going to be a minor enhancement.
ocelotgui
There have been no significant updates to ocelotgui since my last blog post.
PL/SQL in MariaDB
The Oracle 12c manual says “Oracle PL/SQL provides functionality equivalent to SQL/PSM:2011, with minor syntactic differences, such as the spelling or arrangement of keywords.” Yes, and English provides functionality equivalent to Russian, except all the words are spelled differently and in different order. Seriously, since Oracle has PL/SQL and MariaDB has SQL/PSM, their stored procedures and functions and triggers and anonymous blocks — hereinafter “code blocks” — look different.
But that’s changing.
There’s a boatload of Oracle compatibility sauce in MariaDB 10.3, and part of it is PL/SQL code blocks, which is what I’ll look at here. MariaDB 10.3 is not released and might not be released for a long time, but the source code is public. I downloaded it with
git clone -b bb-10.2-compatibility https://github.com/MariaDB/server.git
and followed the usual instructions for building from source. I had a bit of trouble building, and I’ll make a few quibbles when I describe details. But to get to the bottom line here at the top: the feature is complete and works about as well as some betas that I’ve seen.
Here’s a short example.
CREATE PROCEDURE p AS
var1 NUMBER(6) := 1;
BEGIN
WHILE var1 < 5 LOOP
DELETE FROM t WHERE s1 = var1;
var1 := var1 + 1;
END LOOP;
END;
Notice some obvious differences from SQL/PSM:
there are no parentheses after p, they're optional
var1 is defined outside the BEGIN END block
WHILE ... LOOP ... END LOOP not WHILE ... DO ... END WHILE
assignment is done without SET, this too is sometimes optional.
In terms of "Oracle 12c compatibility", MariaDB is now pulling ahead of MySQL, which is bemusing when one considers that Oracle owns MySQL. MariaDB will still not be as compatible as PostgreSQL with EnterpriseDB, I suppose, but this is a boost for migrants.
First complaint: Ocelot's stored-procedure debugger, which is part of our open-source GUI (ocelotgui) for MySQL and MariaDB, can't handle the new PL/SQL. It doesn't even detect where statements end, so I've got work to do.
Second complaint: obviously Monty Widenius makes the MariaDB programmers work too hard. What happened to the halcyon days of yore when making DBMSs was one long party?
For the rest of this blog post, I will describe what the differences are between MariaDB's current PSM and MariaDB 10.3's PL/SQL.
sql_mode='oracle'
In order to enable creation of PL/SQL code blocks, say
SET sql_mode='oracle';
Before saying "this is a bad idea", I will admit that:
I don't have a better idea at the moment.
Now, with that out of the way, I can say that:
this is a bad idea.
(1) There's already a "SET sql_mode='oracle';" statement, so this is a significant behaviour change.
(2) The setting changes what statements are legal. That means that, faced with a code-block statement, it's impossible to know whether it's syntactically correct unless you know what the earlier statements were.
(3) Inevitably some things will be SQL/PSM and some things will be PL/SQL, at least in some installations. Therefore there will be lots of jumping back and forth with sql_mode settings, with special extra fun if someone makes the change to @@sql_mode globally.
In other words, this is such a bad idea that it cannot possibly survive. Therefore don't worry about it. (UPDATE: 2017-02-12: since I have no better idea, and since few current users would be affected, I backtrack -- MariaDB may as well stay on course.)
CREATE PROCEDURE
SQL/PSM PL/SQL
------- ------
CREATE CREATE
[OR REPLACE] [OR REPLACE]
[DEFINER = {user|CURRENT_USER }] [DEFINER = {user|CURRENT_USER}]
PROCEDURE sp_name PROCEDURE sp_name
([proc_parameter[,...]]) [([proc_parameter[,...]])]
[characteristic ...] [characteristic ...]
{IS|AS}
body body
proc_parameter:
[IN|OUT|INOUT] name type name [IN|OUT|INOUT] type
type:
Any MariaDB data type any MariaDB or Oracle data type
characteristic:
LANGUAGE SQL LANGUAGE SQL
| [NOT] DETERMINISTIC | [NOT] DETERMINISTIC
| contains|reads|modifies SQL clause | contains|reads|modifies SQL clause
| SQL SECURITY {DEFINER|INVOKER} | SQL SECURITY {DEFINER|INVOKER}
| COMMENT 'string' | COMMENT 'string'
The only differences between the left column and the right column are:
* {IS|AS} clause -- if you see IS OR AS here, then you know it's PL/SQL.
* parentheses around the parameter list are optional.
* types can be Oracle data types, which I'll discuss later.
If Mr Spock saw this he would say "It's PL/SQL captain, but not as we know it." The DEFINER clause and the INOUT option and all the characteristics are not in Oracle 12c. But they are good additions -- if they weren't allowed, some functionality would be lost. So my only quibble would be: the Oracle characteristics clause AUTHID {DEFINER|CURRENT_USER} should have been allowed as well.
After I created with
CREATE PROCEDURE p IS BEGIN DELETE FROM t; END;
I looked at information_schema with
SELECT routine_definition, routine_body, sql_data_access, sql_mode
FROM information_schema.routines
WHERE routine_name='p';
and saw
ROUTINE_DEFINITION: 'IS BEGIN DELETE FROM t; END'
ROUTINE_BODY = 'SQL'
SQL_DATA_ACCESS = 'CONTAINS SQL'
SQL_MODE: 'PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ORACLE, ...' (etc.)
So how do I know this is a PL/SQL routine?
I can't depend on SQL_MODE, for the reasons I stated before. I don't like to depend on ROUTINE_DEFINITION, because really the definition doesn't start with IS, it starts with BEGIN.
So my second quibble is: I wish the value in ROUTINE_BODY was 'PLSQL' rather than 'SQL'.
Approximately the same syntax enhancements exist for functions and triggers.
Body
When a body of a routine is a compound statement ...
SQL/PSM PL/SQL
------- ------
[DECLARE section]
BEGIN [[NOT] ATOMIC] BEGIN
[variable declarations]
[exception-handler declarations]
[Executable statements] Executable statements
[EXCEPTION section]
END END
In SQL/PSM the variables are declared within BEGIN/END, in PL/SQL they're declared before BEGIN/END. In SQL/PSM the exceptions are declared within BEGIN/END, in PL/SQL they're declared after BEGIN/END.
Therefore the SQL/PSM body...
CREATE OR REPLACE PROCEDURE a() BEGIN DECLARE v VARCHAR(100) DEFAULT 'Default'; SET v = NULL; END;
... does look different in PL/SQL ...
CREATE PROCEDURE a IS v VARCHAR2(100) := 'Default'; BEGIN v := NULL; END;
but the differences are in the syntax and order of non-executable statements. That is, the existing MariaDB-10.2 SQL executable statements (DELETE, DROP, etc.) will work in a PL/SQL body.
Control statements
SQL/PSM PL/SQL
------- ------
label: <<label>>
IF ... THEN ... [ELSE ...] END IF IF ... THEN ... [ELSE ...] END IF
LOOP ... END LOOP LOOP ... END LOOP
WHILE ... DO ...; END WHILE WHILE LOOP ...; END LOOP
CASE ... WHEN ... THEN ... END CASE CASE ... WHEN ... THEN ... END CASE
REPEAT ... UNTIL ...
ELSIF
FOR
GOTO
NULL
LEAVE EXIT [WHEN ...]
ITERATE CONTINUE [WHEN ...]
For controlling the flow of execution, there's a lot of similarity.
The only major "enhancement" in PL/SQL is GOTO, which is considered beneficial when one wishes to get out of a loop that's within a loop that's within a loop. Seeing how that works out in practice will be interesting (a euphemism for: there will be bugs).
The only minor "enhancement" in PL/SQL is NULL, which does nothing. That is, where in SQL/PSM you'd say "BEGIN END", in SQL/PSM you'd say "BEGIN NULL; END".
Third quibble: For some reason, BEGIN <<label>> NULL; END is illegal.
Fourth quibble: The NULL statement is not visible in INFORMATION_SCHEMA.
(Update 2017-01-17: The third quibble has been taken care of, and the fourth quibble was my mistake, the NULL statement is visible.)
Variables
This is a PL/SQL procedure with a mishmash of declarations and assignments.
CREATE PROCEDURE p() IS a VARCHAR2(500); b CHAR(7) CHARACTER SET sjis; c NUMBER(6) := 1; d TINYINT DEFAULT 1; BEGIN SET @c = c; d := @d; END;
Variables a and c are declared with Oracle syntax, but variables b and d are declared with MySQL syntax. The first assignment is MariaDB syntax, but the second assignment is Oracle syntax.
Fifth quibble: "SET d := @d" wouldn't work, which shows that Oracle and MariaDB variable and assignment statements aren't always interchangeable, but they usually are.
Mishmash is good -- once again, the MariaDB folks didn't see a need to limit functionality just because Oracle doesn't do something, and didn't see a need to be strict about Oracle syntax because of course MariaDB syntax works. However, routines like this can't be migrated to Oracle 12c. Compatibility only works one way.
The worklog
MariaDB is open -- the early source code is available, and so are the worklog tasks on JIRA. The information in the worklog tasks is sparse, far inferior to what we used to do for MySQL. But these items are worth following to see when they change.
[MDEV-10137] Providing compatibility to other databases
[MDEV-10142] PL/SQL parser
[MDEV-10343] Providing compatibility for basic SQL data types
[MDEV-10411] Providing compatibility for basic PL/SQL constructs
[MDEV-10580] sql_mode=ORACLE: FOR loop statement
[MDEV-10697] GOTO statement
[MDEV-10764] PL/SQL parser - Phase 2
There are many other tasks associated with "Oracle compatibility", if I had tried to describe them all this post would be too long.
MariaDB 10.2 Window Functions
Today the first MariaDB 10.2 alpha popped up and for the first time there is support for window functions.
I’ll describe what’s been announced, what’s been expected, comparisons to other DBMSs, problems (including crashes and wrong answers), how to prepare, what you can use as a substitute while you wait.
I assume some knowledge of what window functions are. If you’d prefer an introductory tutorial, I’d suggest reading articles like this one by Joe Celko before you continue reading this post.
What’s been announced
The MariaDB sources are:
The release notes
The source code trees — the feature tree up till now has been github.com/MariaDB/server/commits/bb-10.2-mdev9543 but the version-10.2 download page has more choices and is probably more stable.
Sergei Petrunia and Vicentiu Ciorbaru, two developers who I think deserve the credit, made a set of slides for a conference in Berlin earlier this month. It seems to have some typos but is the best description I’ve seen so far.
On Wednesday April 20 Mr Petrunia will give a talk at the Percona conference. Alas, it coincides with Konstantin Osipov’s talk about Tarantool — which I’ve done some work for — which, if you somehow haven’t heard, is a NoSQL DBMS that’s stable and faster than others according to independent benchmarks like the one from Coimbra. What a shame that two such important talks are scheduled for the same time.
Anyway, it’s clear that I’ll have to update this post as more things happen.
What’s been expected
There have been several wishes / feature requests for window functions over the years.
Typical feature requests or forum queries are “Oracle-like Analytic Function RANK() / DENSE_RANK() [in 2004]”, “analytical function like RANK etc to be implemented [in 2008]”, “Is MySQL planning to implement CTE and Window functions? [in 2010]”.
Typical blog posts are Shlomi Noach’s “Three wishes for a new year [in 2012]” and Baron Schwartz’s “Features I’d like in MySQL: windowing functions [in 2013]”..
Typical articles mentioning the MySQL/MariaDB lack of window functions are “What PostgreSQL has over other open source SQL databases” and “Window Functions Comparison …”.
So it’s clear that there has been steady demand, or reason for demand, over the years.
My first applause moment is: Mr Petrunia and Mr Ciorbaru have addressed something that’s been asked for, rather than what they wished had been asked for.
Comparisons to other DBMSs
I know twelve DBMSs that support window functions. No screen is wide enough for a chart showing them all, so I’ll just list their windows-function documents here so that you can click on the names to get the details:
APACHE DRILL,
CUBRID,
DB2 LUW,
DB2 z/OS 10,
DERBY,
FIREBIRD,
INFORMIX,
ORACLE,
POSTGRESQL,
SQL SERVER,
SYBASE,
TERADATA. I’ll show MariaDB against The Big Three.
These functions are mentioned in the standard document as required by optional feature T611 ELementary OLAP operations:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| DENSE_RANK | yes | yes | yes | yes |
| RANK | yes | yes | yes | yes |
| ROW_NUMBER | yes | yes | yes | yes |
These functions are mentioned in the standard document as required by optional feature T612 Advanced OLAP operations:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| CUME_DIST | yes | yes | no | yes |
| PERCENT_RANK | yes | yes | no | yes |
These functions are mentioned in the standard document as required by optional features T614 through T617:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| FIRST_VALUE | no | yes | yes | yes |
| LAG | no | yes | yes | yes |
| LAST_VALUE | no | yes | yes | yes |
| LEAD | no | yes | yes | yes |
| NTH_VALUE | no | yes | no | no |
| NTILE | yes | yes | no | yes |
These are common functions which are in the standard and which can be window functions:
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| AVG | yes | yes | yes | yes |
| COUNT | yes | yes | yes | yes |
| COVAR_POP/SAMP | no | yes | yes | yes |
| MAX | no | yes | yes | yes |
| MIN | no | yes | yes | no |
| SUM | yes | yes | yes | yes |
| VAR_POP/SAMP | no | yes | yes | yes |
Yes MariaDB also supports non-standard functions like BIT_XOR, but they’re worthless for comparison purposes. What’s more important is that the MariaDB functions cannot be DISTINCT.
As for the options in OVER clause … just the important ones …
| Function | MariaDB | Oracle | DB2 | SQL Server |
|---|---|---|---|---|
| ORDER BY | yes | yes | yes | yes |
| NULLS FIRST|LAST | no | “yes” | yes | no |
| PARTITION BY | yes | yes | yes | yes |
| PRECEDING|FOLLOWING | sometimes | yes | yes | yes |
Those are the options that matter. The NULLS clause is important only because it shows how far an implementor will go to support the standard, rather than because most people care. MariaDB in effect supports NULLS HIGH|LOW, which is as good as Oracle — The Oracle manual puts it this way: “NULLS LAST is the default for ascending order, and NULLS FIRST is the default for descending order.” People who think that’s not cheating can add a comment at the end of this post.
From the above I suppose this second applause moment is justifiable: MariaDB has all the basics, and half of the advanced features that other DBMSs have.
Problems (including crashes and wrong answers)
The MariaDB announcement says:
“Do not use alpha releases on production systems! … Thanks, and enjoy MariaDB!”
Indeed anyone who used 10.2.0 in production would discover that enjoyable things can be bad for you.
I started with this database: …
create table t1 (s1 int, s2 char(5)); insert into t1 values (1,'a'); insert into t1 values (null,null); insert into t1 values (1,null); insert into t1 values (null,'a'); insert into t1 values (2,'b'); insert into t1 values (-1,'');
The following statements all cause the server to crash:
select row_number() over (); select 1 as a, row_number() over (order by a) from dual; select *, abs(row_number() over (order by s1)) - row_number() over (order by s1) as X from t1; select rank() over (order by avg(s1)) from t1;
The following statements all give the wrong answers:
select count(*) over (order by s2) from t1 where s2 is null; select *,dense_rank() over (order by s2 desc), dense_rank() over (order by s2) from t1; select *, sum(s1) over (order by s1) from t1 order by s1; select avg(s1), rank() over (order by s1) from t1;
The following statement causes the client to hang (it loops in mysql_store_result, I think this is the first time I’ve seen this type of error)
select *, avg(s1) over () from t1;
And now for the third applause line … to which you might be saying: huh? Aren’t those, er, less-than-desirable results? To which I would reply: yes, but two weeks ago there were far more and far bigger problems. We should be clapping for how quickly progress has been made, and guessing that this section of my post will be obsolete soon.
How to prepare
You have lots of time to get ready for 10.2, but may as well start now by getting rid of words that have special meaning for window functions.
The word OVER is reserved.
The newly supported function names — DENSE_RANK RANK ROW_NUMBER CUME_DIST PERCENT_RANK NTILE — are not reserved, and the names of functions which will probably be supported soon — FIRST_VALUE LAG LEAD LAST_VALUE NTH_VALUE — will probably not be reserved. But they might as well be, because you won’t be able to use those names for your own functions. Besides, they’re reserved in standard SQL.
What you can use as a substitute
Suppose you don’t want to wait till MariaDB is perfect, or you’d like to stay with MySQL (which as far as I know has made less progress than MariaDB toward this feature). Well, in short: gee that’s too bad. But I have seen three claims about getting a slight subset.
One: Shlomi Noach claimss you can use a trick with GROUP_CONCAT:
Two: Adrian Corston claims you can make delta functions with assignments.
Three: I claim that in ocelotgui you can put ‘row_number() over ()’ in a SELECT and get a row-number column even with older versions of MySQL or MariaDB (this is a recent change, it’s in the source not the binary).
In fact all the “window_function_name() OVER ()” functions could be done easily in the client, if they’re in the select list and not part of an expression,
and the result set is ordered. But I’m not sure whether that’s something to excite the populace.
There might be a “Four:”. I have not surveyed the various applications that can do cumulations. I suspect that mondrian is one, and open OLAP might be another, but haven’t looked at them.
Our own progress
For ocelotgui (Ocelot’s GUI client for MySQL and MariaDB) we had to adjust the syntax checker to highlight the new syntax in 10.2, as this screenshot shows 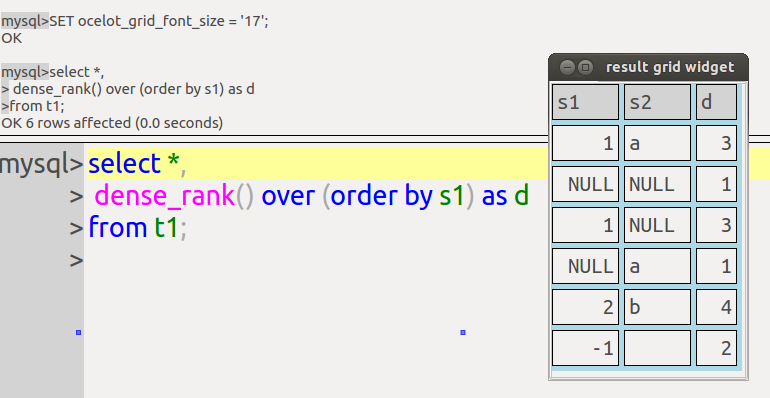
So we now can claim to have “the only native-Linux GUI that correctly recognizes MariaDB 10.2 window functions”. Catchy slogan, eh? The beta download is at https://github.com/ocelot-inc/ocelotgui. I still expect that it will be out of beta in a few weeks.
MariaDB 10.1 Release Candidate
I installed the MariaDB 10.1 Release Candidate. Nothing interesting happened, which from MariaDB’s point of view is good. But here’s how I tried to make it interesting. Some of this applies to late releases of MariaDB 10.0 as well.
Loop with MAKE INSTALL
My habit is to download the source to directory X and then say “cmake -DCMAKE_INSTALL_PREFIX=/X” (the same directory), then “make”, then “make install”. That doesn’t work any more. Now I can’t install in the same directory that I downloaded in. Not a big deal; perhaps I’m the only person who had this habit.
Crash with ALTER
In an earlier blog post General Purpose Storage Engines in MariaDB I mentioned a crash, which I’m happy to say is fixed now. Here’s another way to crash, once again involving different storage engines.
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 2 Server version: 10.1.8-MariaDB Source distribution Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> INSTALL SONAME 'ha_tokudb'; Query OK, 0 rows affected (0.57 sec) MariaDB [(none)]> USE test Database changed MariaDB [test]> CREATE TABLE t (id INT UNIQUE, s2 VARCHAR(10)) ENGINE=tokudb; Query OK, 0 rows affected (0.56 sec) MariaDB [test]> INSERT INTO t VALUES (1,'ABCDEFGHIJ'); Query OK, 1 row affected (0.04 sec) MariaDB [test]> INSERT INTO t VALUES (2,'1234567890'); Query OK, 1 row affected (0.05 sec) MariaDB [test]> CREATE INDEX i ON t (s2); Query OK, 0 rows affected (0.64 sec) Records: 0 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=innodb; Query OK, 2 rows affected (0.53 sec) Records: 2 Duplicates: 0 Warnings: 0 MariaDB [test]> ALTER TABLE t engine=tokudb; ERROR 2013 (HY000): Lost connection to MySQL server during query
… Do not do this on a production system, as it will disable all your databases.
[ UPDATE 2015-09-29: This is apparently due to a problem with jemalloc which should only happen if one builds from source on Ubuntu 12.04. MariaDB was aware and had supplied extra information in its Knowledge Base, which I missed. Thanks to Elena Stepanova. ]
PREPARE within PREPARE
No doubt everyone encounters this situation at least once:
MariaDB [test]> prepare stmt1 from 'prepare stmt2 from @x'; ERROR 1295 (HY000): This command is not supported in the prepared statement protocol yet
… and then everyone else gets on with their lives, because preparing a prepare statement isn’t top-of-agenda. Not me. So I welcome the fact that I can now say:
MariaDB [test]> prepare stmt1 from 'begin not atomic prepare stmt2 from @x; end'; Query OK, 0 rows affected (0.00 sec) Statement prepared
So now if I execute stmt1, stmt2 is prepared. This is part of the “compound statement” feature.
Evade the MAX QUERIES PER HOUR limit
Suppose some administrator has said
GRANT ALL ON customer.* TO 'peter'@'localhost' WITH MAX_QUERIES_PER_HOUR 20;
Well, now, thanks again to the “compound statement” feature, I can evade that and do 1000 queries. Here’s the test I used:
SET @a = 0; DELIMITER // WHILE @a < 1000 DO INSERT INTO t VALUES (@a); SET @a = @a + 1; END WHILE;// DELIMITER ;
No error. So with a little advance planning, I could put 1000 different statements in a user variable, pick off one at a time from within the loop, and execute. One way of looking at this is: the WHILE ... END WHILE is a single statement. Another way to look at this is: new features introduce new hassles for administrators. Such, however, is progress. I clapped for the compound-statement feature in an earlier blog post and ended with: "But MariaDB 10.1.1 is an early alpha, and nothing is guaranteed in an alpha, so it's too early to say that MariaDB is ahead in this respect." I'm glad to say that statement is obsolete now, because this is MariaDB 10.1.8, not early alpha but release candidate.
The true meaning of the OR REPLACE clause
MariaDB has decided to try to be consistent with CREATE and DROP statements, because frankly nobody could ever remember: which CREATE statements allow CREATE IF NOT EXISTS, which CREATE statements allow CREATE OR REPLACE, which DROP statements allow DROP IF EXISTS? I wrote a handy chart in MySQL Worklog#3129 Consistent Clauses in CREATE and DROP. Now it's obsolete. The MariaDB version of the chart will have a boring bunch of "yes"es in every row.
But OR REPLACE behaviour is just a tad un-Oracle-ish. The Oracle 12c manual's description is "Specify OR REPLACE to re-create the [object] if it already exists. You can use this clause to change the definition of an existing [object] without dropping, re-creating, and regranting object privileges previously granted on it." That's not what MariaDB is doing. MariaDB drops the object and then creates it again, in effect. You can see that because you need to have DROP privilege on the object in order to say CREATE OR REPLACE.
And here's where it gets a tad un-MySQL-ish too. If you say "CREATE OR REPLACE x ...,", causing the dropping of an existing x, and then say SHOW STATUS LIKE 'Com%', you'll see that the Com_drop_* counter is zero. That is: according to the privilege requirements, x is being dropped. But according to the SHOW statement, x is not being dropped. Decent folk wouldn't use SHOW anyway, so this won't matter.
An effect on us
One of the little features of ocelotgui (the Ocelot GUI application for MySQL and MariaDB) is that one can avoid using DELIMITER when typing in a statement. The program counts the number of BEGINs (or WHILEs or LOOPs etc.) and matches them against the number of ENDs, so it doesn't prematurely ship off a statement to the server until the user presses Enter after the final END. However, this feature is currently working only for compound statements within CREATE statements. Now that compound statements are stand-alone, this needs adjusting.
Now that I've mentioned ocelotgui again, I'll add that if you go to the https://github.com/ocelot-inc/ocelotgui download page and scroll past the install instructions, you'll find more pictures, and a URL of the debugger reference, for version 0.7 alpha.