Month: October 2013
The UTF-8 world is not enough
In English there are very few words of Japanese origin but I think this one has a great future: mojibake. Mojibake is the garbage you see when MySQL or MariaDB has a column definition saying character set A, stores into it a string that’s actually in character set B, then ships it to a client which expects everything to be in character set C.
For some DBMSs (Drizzle and NuoDB spring to mind) it’s apparent that the developers decided that users could avoid mojibake, and developers could avoid a lot of extra trouble, if everybody had the same character set: UTF-8. Well, MySQL and MariaDB have web users and UTF-8 is popular on the web. According to Web Technology Surveys, 80% of web sites use UTF-8. There’s a Google study that came to a vaguely similar conclusion.
And yet, and yet, the arguments are devastating for why should MySQL or MariaDB continue to support character sets other than UTF-8, and even add one or two more.
Space
With a Greek character set like 8859-7, it takes one (1) byte to store one ordinary Greek character. With UTF-8 it takes two (2) bytes to store one ordinary Greek character. So 8859-7 is 50% cheaper for Greek words, and the same ratio holds for other 8-bit non-Latin language-specific character sets like Bulgarian.
With a multi-byte character set like euckr (for Korean) things get more complicated and results will vary. I took the lead paragraph for the Korean Wikipedia article on Seoul, dumped the contents into columns with different character set definitions, and compared the sizes with the octet_length() function:
utf8 1260 /* worst */ utf16 1138 /* middle */ euckr 916 /* best */
Unsurprisingly, it takes fewer bytes to store Korean text with a “made-in-Korea” character set. Also it’s a bit cheaper to use utf16 (which always requires two bytes per character for ordinary Korean words), which is doubtless one reason that the SQL Server folks prefer UTF-16 over UTF-8. I of course will ignore any objections that space doesn’t matter, or that compression algorithms exist.
Conversion trouble
It is true that Unicode’s repertoire is a superset of what’s in Japanese character sets like sjis or ujis. But that does not mean that you can start with sjis text, convert to Unicode, then convert back to sjis. On some rare occasions such a “round trip” will fail. This happens because the mapping is not always one-to-one. But it also happens because there are slight differences between various versions of sjis — that’s a fact which causes no difficulty if there’s no conversion, but causes some difficulty if something comes in from the client as sjis, gets converted to Unicode for storage, then gets converted back to sjis when the server retrieves something for the client.
Legacy
At the start of this post I mentioned that 80% of web sites use UTF-8. However, that is the world-wide figure. For a language-specific look, here are two sobering statistics:
* Only 54% of Chinese-language web sites predominantly use UTF-8 * Only 60% of Japanese-language web sites predominantly use UTF-8 Source: Web Technology Surveys
Hunting for examples, I went to the alexa.com page for “Top Sites in China”, then on my Firefox browser I clicked Tools > Page Info: Encoding. Five of the top ten said their encoding was UTF-8, but the other five said their encoding was GBK. This is not a reliable test because the site owner could be fibbing. But even if only a few are telling the truth, it’s clear there are many holdouts in the Non-UTF-8 crannies.
Of course for all of these arguments there are counter-arguments or even possible refutations. But they wouldn’t matter to the DBMS vendor. The vendor is supposed to help the customer with the customer’s plan, rather than explain that they should do something which, with suspicious convenience, would make the vendor’s life easier.
I had a look at the open-source SQL DBMSs, and as far as I could tell only five support both storage and input with a variety of encodings: MySQL and MariaDB of course, but also PostgreSQL, Ingres, and Firebird.
VoltDB definitely cannot. The Java-based ones apparently cannot, but I didn’t make certain.
Regular (RLIKE and REGEXP) expressions: Good News
Ten years ago, MySQL got a “bug report” about trouble with RLIKE. It got marked “won’t fix” because MySQL used a regular-expression library that couldn’t handle non-ASCII characters reliably. Over time there were multiple similar or duplicate bug reports but the only result was a note in the MySQL manual saying, in effect, “tough luck”. Until now.
Actually the fix is in a pre-release of the bzr branch for MariaDB 10.0.5, and I can’t predict that the MySQL folks will copy it, but it looks good to me, and I clap for the original coders who made the “Perl Compatible Regular Expressions” library, the “Google Summer of Code” folks who pay students to help with open source projects, the student coder in question — Sudheera Palihakkara from a Sri Lanka university — and finally Alexander Barkov from the MariaDB foundation.
So what were the problems and what’s been solved — or not solved?
Solved: Handling any characters
Most of the complaints about REGEXP have been about handling of accented Latin characters, Cyrillic characters, or, in short: regardless of character set or collation, if any character in the pattern was outside the ASCII range or was NUL, then there would be false hits, no hits, miscalculated lengths, or failed case conversions. I took examples from the “how to repeat” section of those bug reports, and tried them with MariaDB 10.0.5. Results:
/* Bug#34473 */
MariaDB [test]> SELECT 'Ørneborgen' RLIKE '^[Ö]';
+-----------------------------+
| 'Ørneborgen' RLIKE '^[Ö]' |
+-----------------------------+
| 0 |
+-----------------------------+
1 row in set (0.03 sec)
/* Bug#54576 */
MariaDB [test]> SELECT 'č' REGEXP '^.$';
+-------------------+
| 'č' REGEXP '^.$' |
+-------------------+
| 1 |
+-------------------+
1 row in set (0.00 sec)
/* Bug#52080 */
MariaDB [test]> SELECT 'Я' regexp 'я';
+------------------+
| 'Я' regexp 'я' |
+------------------+
| 1 |
+------------------+
1 row in set (0.02 sec)
/* Bug#63439 */
MariaDB [test]> SELECT 'ääliö' REGEXP '^[aä]{1}[aä]{1}li[oö]{1}$';
+--------------------------------------------------+
| 'ääliö' REGEXP '^[aä]{1}[aä]{1}li[oö]{1}$' |
+--------------------------------------------------+
| 1 |
+--------------------------------------------------+
1 row in set (0.03 sec)
/* Bug#70470 */
MariaDB [test]> SELECT 'abc\0def' REGEXP 'def';
+-------------------------+
| 'abc\0def' REGEXP 'def' |
+-------------------------+
| 1 |
+-------------------------+
1 row in set (0.00 sec)
All the above answers are correct, for the first time ever.
In fact one could say that the new REGEXP handles too many characters. It’s adjusted for Unicode 6.2, a version that neither MySQL nor MariaDB support yet. This will of course be of concern to those who use the Meroitic alphabet, but they’re a fading minority.
Not solved: incompatibilities
I guess it was inevitable that, since there’s a different underlying library, the text of some error messages would change. For example I get this:
MariaDB [test]> select '1' rlike rpad('1',100,'(');
ERROR 1139 (42000): Got error 'missing ) at offset 100' from regexp
and that’s okay, but in MySQL 5.6.14 the error message is:
“ERROR 1139 (42000): Got error ‘parentheses not balanced’ from regexp”.
A bit more interesting is this query:
/* Bug#68153 */ MariaDB [test]> SELECT CHAR(126) REGEXP '[[.tilde.]]'; ERROR 1139 (42000): Got error 'POSIX collating elements are not supported at offset 1' from regexp
and that looks a little less okay. In MySQL 5.6.14 the same search condition doesn’t cause an error, it’s considered to be “true”.
Solved: Handling more Posix
The MariaDB folks have proudly announced that version 10.0.5 supports “recursive patterns, named capture, look-ahead and look-behind assertions, non-capturing groups, non-greedy quantifiers”. To which I’m sure that the response will be: What? How shocking that non-greedy quantifiers weren’t added ten years ago!
Well, maybe not. But when looking at new features, it’s wrong to ask merely whether there’s some advantage for the non-greedy man on the Clapham omnibus. The point is it’s supposed to be more compatible with modern Perl programs, with Posix, and with all the box-tickers who will ask: do you really support regular expressions? And if someday I reach that pinnacle of ambition, to figure out grep, then I’ll doubtless appreciate look-behind assertions in the way they deserve to be appreciated.
Unsolved: handling more standard SQL
In the operetta Die Fledermaus there’s a refrain: “Happy is the one who forgets what isn’t going to be changed”. But I, alas, can’t forget the comment that I wrote on Bug#746 ten years ago, showing there are at least six behavioural differences between REGEXP and the optional-SQL-standard operator, SIMILAR TO. The incompatibilities arise because SIMILAR TO works like LIKE, so it’s more SQL-ish, and less Posix-ish. Thus, improvements in REGEXP alone are not an advance towards more standard SQL. This would matter more if there were many other SQL implementations supporting SIMILAR TO. The only ones I know of are PostgreSQL and Firebird.
The Third Most Popular Open Source DBMS
We all know that MySQL says it is “the world’s most popular open-source database”. And PostgreSQL has a firm hold on second place while claiming to be, instead, “the world’s most advanced open source database”. But the horse that comes in third can return some money to gamblers who bet “to show”. And the horse that shows momentum or gets close is worth watching for next time.
So I’ll just ignore the dolphin and the elephant in the room, and go on to a harder question: who’s number three?
According to Wikipedia
To find out how many times someone has expressed interest in a topic, I can go to stats.grok.se and ask how many times someone has looked at that topic’s page in Wikipedia. Evil-thinking people could manipulate these numbers with ease, but until now they have had no reason to do so.
So here is the count of accesses on the Wikipedia pages of the nine contending SQL DBMSs, for September last year (blue) and September this year (red).
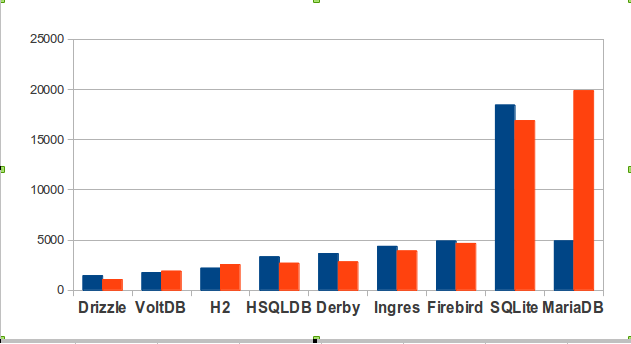
In absolute terms, MariaDB is only slightly ahead. But if you look at momentum (what direction the hit counts have gone between September 2012 and September 2013), interest in MariaDB has risen a great deal while interest in most other DBMSs has declined.
Now here is the chart for open-source NoSQL DBMSs, made the same way. This time I can’t be comprehensive — there are 150 NoSQL products! I’ll show only the ten with the most hits.
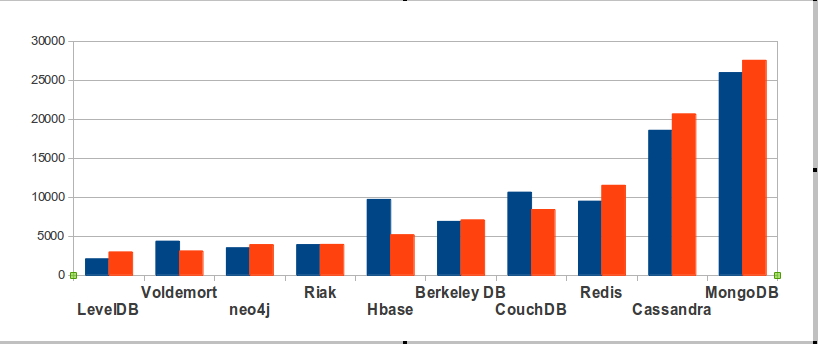
Of course MongoDB is in front. The surprise is that MongoDB’s in-frontness isn’t glaring.
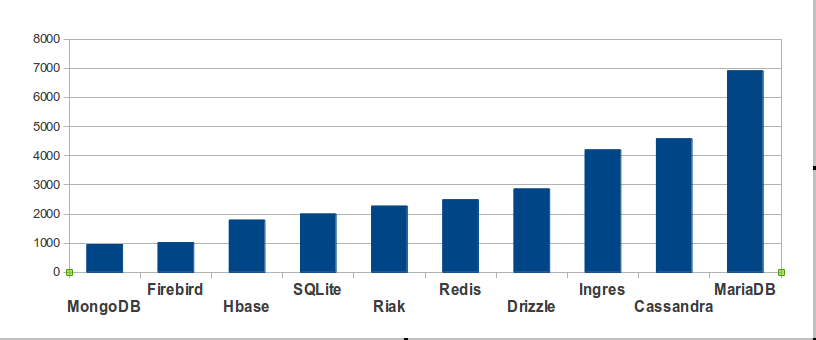
According to The Register
To find out how many times the mass media mentioned a DBMS, I can go to google.com and enter site:theregister.co.uk [DBMS name] -mozilla. Simply googling the DBMS name would fail because Google seems to become more inexact as numbers get bigger, and because “Ingres” and “Firebird” and “Drizzle” and “Cassandra” have alternative meanings that have nothing to do with databases.
So this term is more specific, it’s asking: how many times does search-term appear in The Register (in a non-Mozilla context)? For this purpose I’m positing that “the mass media” and the well-known medium “The Register” are synonymous terms.
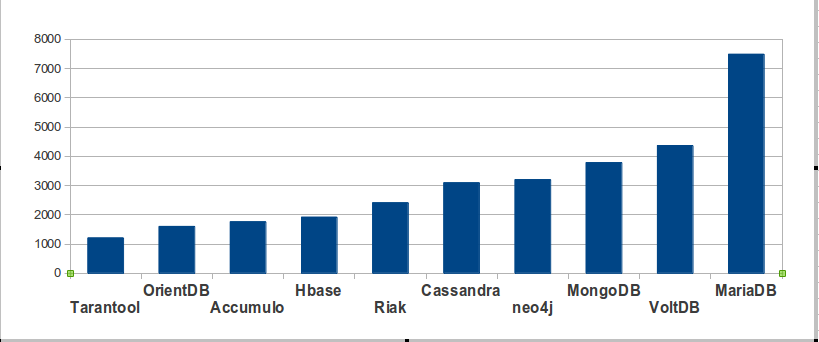
According to Ohloh
To find out how much activity an open-source project has, I can go to ohloh.net and look up the count of commits in the last year. (Ohloh “provides a single aggregate source of information about the world’s open source projects from over 5,000 repositories and forges including GitHub, SourceForge and Google Code, as well as open source foundation repositories including the Eclipse, Mozilla, Apache, and Linux.”) This method has been justly criticized, but is an indicator for developer enthusiasm. Again I am only showing the top ten, other than MySQL or PostgreSQL, for any kind of open-source DBMS.
According to db-engines
An Austrian company named solid IT maintains a site named db-engines.com. On it there is “a list of DBMS ranked by their current popularity … updated monthly.” Their ranking is based on (a) Google and Bing hits, (b) Google Trends, (c) Stack Overflow and DBA Stack Exchange (counting the number of technical discussions), (d) indeed.com and simplyhired.com (counting the number of job offers), (e) LinkedIn (counting the number of people who mention the product in their profiles). In other words, none of their criteria match the criteria that I prefer. If one excludes closed-source and MySQL and PostgreSQL from their list, their top 10 hits are:
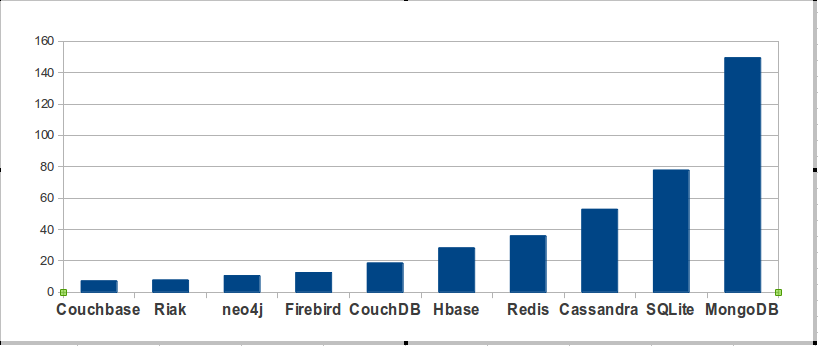
Woe and alas. If their results had been similar to mine, despite their different criteria, then that might have validated both our methods. But they’re very different. I think that’s because my criteria are the only valid ones, but obviously I’m not the only evaluator.
According to the makers
“We believe that there are more copies of SQLite in use around the world than any other SQL database engine, and possibly all other SQL database engines combined.”
— sqlite.org
“Mountain View, Calif. – February 8, 2012 – Couchbase, Inc. [is] the NoSQL market share leader …”
— couchbase.com
“Firebird® is the universal open source database used by approximately 1 million of software developers worldwide.”
— facebook.com/FirebirdSQL
“MongoDB is the leading NoSQL database, with significant adoption among the Fortune 500 and Global 500.”
— mongodb.com
Announcing the finishers
MariaDB is in third place among the open-source SQL DBMSs, and would be third overall if we gave more weight to the numbers “according to Ohloh” and “according to The Register”. But MongoDB and Cassandra nose past it “according to Wikipedia”, and MongoDB is definitely the third-place finisher “according to db-engines”. The claim of SQLite is strongest “according to the makers”.
We have a photo finish, with a blurry camera.
Triggers: Comparisons, New Features, and a Trick
I’ll show a chart which indicates the level of support for trigger features in major open-source DBMSs.
I’ll comment on new features in MySQL 5.7.
I’ll show how triggers can be used to abort statements which are taking too long.
Trigger features in major open-source DBMSs
| Feature | Firebird | Ingres | MySQL+MariaDB | PostgreSQL |
|---|---|---|---|---|
| Any compound statement | YES | – | YES | – |
| Alter | YES | – | – | – |
| Disable | YES | – | – | YES |
| For each statement | – | YES | – | YES |
| For each row | YES | YES | YES | YES |
| One trigger, multiple trigger events | YES | YES | – | YES |
| Multiple triggers for same situation | YES | – | YES | |
| Views’ “instead of” clause | – | – | – | YES |
| Deferrable | – | – | – | YES |
| Normally standardish syntax | YES | – | YES | YES |
| “New” and “Old” variables | YES | YES | YES | YES |
| “When” clause or equivalent | – | YES | – | YES |
Explanation of each column:
“Any compound statement”:
“YES” if trigger body can be something like BEGIN statement1;statement2; … END.
“-” if trigger body an only be something like a single CALL statement.
“Alter”:
“YES” if ALTER TRIGGER is legal and can do something significant (more than renaming). Non-standard.
“-” if the normal way to change a trigger is to drop and create again.
“Disable”:
“YES” if there is a persistent way to make a trigger inactive or disabled. Non-standard.
“-” if the normal way to disable a trigger is to drop it or add an IF clause.
“For each statement”:
“YES” if checking happens before/after rest of statement processing
“-” if checking is only for each row
“For each row”:
“YES” if checking happens before/after rest of row processing
“-” if checking is only for each statement
“One trigger, multiple trigger events”:
“YES” if clauses like “BEFORE INSERT OR UPDATE OR DELETE” are possible. Non-standard.
“-” if clause can only contain one verb (no OR allowed)
“Multiple triggers for same situation”:
“YES” if there can be (for example) two BEFORE UPDATE triggers on table t.
“-” if only one trigger is possible for the same action at the same time.
Views’ “instead of” clause:
“YES” if INSTEAD OF triggers are possible (usually for views only)
“-” if the only trigger action times are BEFORE and AFTER
“Deferrable”:
“YES” if it’s possible to defer “after” checking until end of transaction. Non-standard.
“-” if all checking is during statement execution
“Normally standardish syntax”:
“YES” if normal CREATE TRIGGER syntax is reminiscent of standard syntax
“-” if normal/recommended syntax is CREATE RULE, or normal body is EXECUTE clause.
“New” and “Old” variables:
“YES” if a trigger can use NEW.column_name and/or OLD.column_name
“-” if column values are invisible during trigger execution
“When” clause or equivalent:
“YES” if syntax is CREATE TRIGGER … [WHEN condition] …;
“-” if condition has to be in an IF statement in the trigger body
Information for this chart comes from the documentation for Firebird 1.5, Ingres 10.0, MySQL 5.6, and PostgreSQL 9.3.
Two New Features In MySQL 5.7
The first enhancement is that it is possible to say
CREATE TABLE t (s1 INT NOT NULL)//
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
IF new.s1 IS NULL THEN SET new.s1=0; END IF;
END//
INSERT INTO t VALUES (NULL)//
That is, NOT NULL no longer stops the INSERT if the trigger was going to change the value to non-null anyway. This was a long-standing feature request, and I doubt that anyone will complain.
The second enhancement is WL#3253: Triggers: multiple triggers per table.
In 5.6, if there are two actions to trigger, one must put them both in one trigger:
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement1
statement2
END
In 5.7 one can put them in two triggers:
CREATE TRIGGER t1 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement1
END
CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW
BEGIN
statement2
END
This is unnecessary for a DBMS like MySQL that supports compound statements for triggers, but it’s in the standard, and there was at least one feature request for it. The problem with multiple triggers is that there has to be some way to decide which one is activated first, and the standard isn’t helpful here — it says to follow the order of creation, but that’s rigid, and also
unreliable if one depends on CURRENT_TIMESTAMP. PostgreSQL “solved” this by saying the order is the alphabetical order of the trigger names, but then Oracle 11g came along with a syntax that MySQL 5.7 copies:
CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW FOLLOWS t1 ... or CREATE TRIGGER t2 BEFORE INSERT ON t FOR EACH ROW PRECEDES t1 ...
“FOLLOWS t1” means “is activated immediately after t1”, and in INFORMATION_SCHEMA.TRIGGERS there is an integer column ACTION_ORDER which reflects this (this column is not new, but in earlier MySQL versions it is always zero).
The feature works, and the worklog task for it has good high-level architecture description. But, once you’ve made trigger t2 follow t1, you’re stuck — there’s still no ALTER TRIGGER. And I think that, even if you know what ACTION_ORDER is, you’ll still get confused. To test that, here is a quiz. After
CREATE TABLE t (s1 CHAR(3));
CREATE TRIGGER t1 BEFORE UPDATE ON t FOR EACH ROW
SET new.s1 = CONCAT(old.s1,'c');
CREATE TRIGGER t2 BEFORE UPDATE ON t FOR EACH ROW PRECEDES t1
SET new.s1 = CONCAT(new.s1,'b');
INSERT INTO t VALUES ('a');
UPDATE t SET s1 = '';
Does s1 contain ‘ab’ or ‘abc’ or ‘acb’ or ‘ac’? Answer at end of post. If you get it wrong, you should continue with the old way and put all actions in a single trigger; however, the coder (apparently Mr Dmitry Shulga) deserves congratulation.
Stopping an update after 10 seconds
Of course the legitimate uses of triggers are (a) to make up for MySQL’s lack of CHECK clauses by producing an error when a NEW value is wrong; (b) to add to a summary in table b whenever there’s a change to table a.
A less tame use — because it is non-deterministic — is aborting a statement if some external condition occurs. The example here is saying, in effect, “If 10 seconds have elapsed since the update began, stop and return an error”. Since the ordinary timers like CURRENT_TIMESTAMP don’t change during a statement, I use SYSDATE.
[ UPDATE: In an earlier version of this article, I used a low-level
counter from PERFORMANCE_SCHEMA. Thanks to Justin Swanhart for suggesting a simpler way. It won’t work if the server was started with –sysdate-is-now, but my original method could also have failed in some circumstances. ]
/* Make a test table with 25 rows. */
CREATE TABLE t (s1 INT);
INSERT INTO t VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),
(11),(12),(13),(14),(15),(16),(17),(18),(19),(20),
(21),(22),(23),(24),(25);
/* Make a trigger so (current time - start time) is checked after
each row update, and SIGNAL if the result is more than 10. */
delimiter //
CREATE TRIGGER abort_after_elapsed_time BEFORE UPDATE ON t FOR EACH ROW
IF TO_SECONDS(SYSDATE()) - @start_time > 10 THEN
SIGNAL SQLSTATE '57005' SET message_text='Timeout';
END IF;//
delimiter ;
/* Set a variable which will contain the current time. */
/* This should be done just before doing the UPDATE. */
SET @start_time = TO_SECONDS(SYSDATE());
/* Do a very slow UPDATE which would take
(25 rows * 1 second per row) if no timeout. */
select current_timestamp;
UPDATE t SET s1 = SLEEP(1);
select current_timestamp;
Example result showing “Timeout” error occurs after about 10 seconds:
MariaDB [test]> select current_timestamp; +---------------------+ | current_timestamp | +---------------------+ | 2013-10-07 12:54:39 | +---------------------+ 1 row in set (0.00 sec) MariaDB [test]> UPDATE t SET s1 = SLEEP(1); ERROR 1644 (57005): Timeout MariaDB [test]> select current_timestamp; +---------------------+ | current_timestamp | +---------------------+ | 2013-10-07 12:54:50 | +---------------------+ 1 row in set (0.00 sec)
Your mileage may vary but by luck it worked this way on my machine. Probably a progress bar would be more interesting, eh? I’ll get back to that theme if I ever finish one.
Answer to quiz question
‘ac’.