I know of seven DBMSs that support GET DIAGNOSTICS: DB2, Oracle Rdb, MySQL, MariaDB, PostgreSQL, Teradata, Mimer.
I regret that its clauses don’t resemble SELECT’s clauses and that the result isn’t a table, but it’s always good to see standard compliance.
Now GET DIAGNOSTICS is getting better due to two new features, one in MySQL and the other in MariaDB.
STACKED
The problem: suppose a condition (an error or warning) happens. Execution goes to a condition handler (a series of statements that are preceded by DECLARE … CONDITION HANDLER FOR condition-value). Now, within those statements, how do we know what was the condition that caused the execution to go to the handler?
For example:
CREATE PROCEDURE p ()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLWARNING
BEGIN
statement-1;
statement-2;
statement-3;
END;
SIGNAL SQLSTATE '01000';
END
Well, the answer looks easy: if you say GET DIAGNOSTICS before statement-1, you’ll get ‘01000’. But there are no guarantees after that, so you’d have to store the results of GET DIAGNOSTICS somewhere, in case you need to see them later.
The solution: GET STACKED DIAGNOSTICS, a new feature in MySQL 5.7. There are now two diagnostics areas: diagnostics area #1 = the “current” one, and diagnostics area #2 = the “stacked” one. The stacked diagnostics area always has the results as they were upon entry. Here’s an illustration:
delimiter //
CREATE PROCEDURE p ()
BEGIN
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION BEGIN
SIGNAL SQLSTATE '01000';
GET CURRENT DIAGNOSTICS CONDITION 1 @current = RETURNED_SQLSTATE;
GET STACKED DIAGNOSTICS CONDITION 1 @stacked = RETURNED_SQLSTATE;
END;
SIGNAL SQLSTATE '03000';
END//
CALL p()//
SELECT @current, @stacked//
The result: @current = ‘01000’ but @stacked =’03000′. There’s been a known bug since February, but that’s okay in an unreleased version.
Multiple warnings
The problem: if there are two warnings, you want to see both of them with GET DIAGNOSTICS. This is especially desirable because SHOW WARNINGS has no trouble returning a set of warnings, and it would be great if we could eliminate SHOW WARNINGS usage (for reasons unrelated to this problem). However, we don’t know in advance that there will be two warnings, and we don’t have a direct way to check. If we put the check for warnings in a procedure, then that works with MariaDB but requires a privilege. If we ask for conditions that don’t exist, then a curious error/warning hybrid happens, which is workaroundable but confusing.
The solution: dynamic compound statements, a new feature in MariaDB 10.1. I mentioned it last week but didn’t think: hmm, if there’s no reason that the diagnostics area would be cleared by a simple comparison. So can I put GET DIAGNOSTICS statements inside an IF … THEN … ELSE so that I get zero, or one, or two results just by typing in appropriately on the mysql client?
I’ll start by creating a table and doing an INSERT, with default SQL mode, in MariaDB only, will cause two “Division by 0” warnings. Then I’ll see what the new feature does.
DELIMITER //
CREATE TABLE test (s1 INT)//
INSERT INTO test VALUES ('a'),('a')//
GET DIAGNOSTICS @condition_count = number//
IF @condition_count = 1 THEN
GET DIAGNOSTICS CONDITION 1 @message_1 = message_text;
SELECT @message_1;
ELSEIF @condition_count = 2 THEN
GET DIAGNOSTICS CONDITION 1 @message_1 = message_text;
GET DIAGNOSTICS CONDITION 2 @message_2 = message_text;
SELECT @message_1, @message_2;
END IF//
The result: both warnings are displayed. Whoopee.
By the way
The worklog task for GET DIAGNOSTICS was WL#2111 Stored Procedures: Implement GET DIAGNOSTICS. Since it got implemented long ago, it’s obsolete. But if you’re interested “what happens if GET DIAGNOSTICS itself causes an error?” and the reasons behind our decisions at that time, go over there and click the high level architecture box.
A long-ago-discussed and much-requested feature, “dynamic compound statements”, is working at last.
It’s been eleven years since the original discussion of dynamic compound statements for MySQL, as you can see by looking at the worklog task on the wayback machine. (As usual, you have to click the “high level architecture” box to see the meat of the specification.) The essential idea is that one can directly enter compound statements like BEGIN … END and conditional statements like “IF … END IF” and looping statements like “WHILE … END WHILE” without needing a CREATE PROCEDURE or CREATE FUNCTION statement.
The advantages are that one can run conditional or complex sequences of statements without needing an EXECUTE privilege, or affecting the database metadata. This has been a popular feature request, as one can see from bug#15037, bug#48777, bug#54000, and bug#61895. and bug#62679.
In 2013 Antony Curtis submitted a patch named “Compound / Anonymous statement blocks for MySQL”. (Anonymous blocks is the Oracle terminology.) Apparently he offered it to Oracle but they couldn’t agree about the licence terms. The MariaDB people were gladder to get the offer, so it’s now in the MariaDB 10.1.1 alpha.
I downloaded it from source. There’s a problem with “make install” but it’s easy to work around and has nothing to do with Mr Curtis’s patch. I had no trouble checking that the feature works as advertised. So, next, I compared the spec with Mr Curtis’s implementation.
Spec: Allow BEGIN … END “compound statements”, CASE, IF, LOOP, WHILE, and REPEAT. Implementation: all done. The only significant defect is that BEGIN has to be stated as BEGIN NOT ATOMIC, to avoid confusion with an old non-standard meaning of BEGIN. So “BEGIN DELETE FROM t; END” is illegal. And “label_x: BEGIN DELETE FROM t; END” is illegal. Only “BEGIN NOT ATOMIC DELETE FROM t; END” is legal. It’s a slight disappointment that no way was found to handle these little difficulties in the parser.
Spec: internally there will be a temporary anonymous procedure created for every compound statement. Implementation: This didn’t happen, at least not in a user-visible way. That’s a low-level detail so it doesn’t matter.
Spec: there should be no new privilege requirement. Implementation: there is no new privilege requirement.
Spec: the implied routine will have characteristics like MODIFIES SQL DATA and NOT DETERMINISTIC. Implementation: characteristics are irrelevant.
Spec: even if there is an anonymous procedure, it should not be visible to the user in information_schema.routines. Implementation: nothing is visible in information_schema.routines.
Spec: perhaps the statement should be in performance_schema.statements. Implementation: no.
Spec: some statements that are client-specific and are not allowed in stored procedures should not be in dynamic compound statements. Implementation: right. For example “USE database_name” is not allowed.
Spec: it’s uncertain whether a dynamic compound statement (which after all is a “statement”) should appear as a single statement in the slow log. Implementation: I didn’t test this because I don’t believe in the slow log; I assumed it doesn’t work.
Spec: if @@sql_mode is set within a dynamic compound statement, then it gets restored to its original value when the statement ends. Implementation: yes, it’s restored.
Spec: A dynamic compound statement may not contain statements that create or drop or alter routines. Implementation: right, statements like DROP PROCEDURE are illegal.
Spec: a dynamic compound statement cannot be used for a PREPARE statement, and therefore there is no fix for BUG#14115 “Prepare() with compound statements breaks”. Supposedly there could be parser-related pitfalls with such syntax. Implementation: PREPARE is allowed. Statements like PREPARE stmt1 FROM ‘BEGIN NOT ATOMIC DECLARE v INT; END’// are just fine. This is worrisome, but probably the supposed pitfalls were cleared up long ago.
Spec: SHOW STATUS could have new counters: Com_compound_statement, Com_if, Com_loop, Com_repeat, Com_while. Implementation: No, that’s not implemented.
Spec: SHOW PROCESSLIST will show the whole compound statement. Implementation: No, that’s not implemented. When I first started the performance_schema design I realized that SHOW PROCESSLIST would eventually become obsolete, so nowadays I think this part of the spec is obsolete.
The future
Given that dynamic compound statements are in DB2 and Oracle 12c and PostgreSQL and now in MariaDB alpha, Oracle/MySQL will look a bit slow if it waits another eleven years to implement them.
But MariaDB 10.1.1 is an early alpha, and nothing is guaranteed in an alpha, so it’s too early to say that MariaDB is ahead in this respect.
The PostgreSQL manual says:
“The standard’s definition of the behavior of temporary tables is widely ignored. PostgreSQL’s behavior on this point is similar to that of several other SQL databases.”
The first sentence is false. The second sentence could be rephrased as “MySQL copied us”, although nobody else did, as far as I know.
The standard’s definition is widely followed
I base this claim on the documentation of DB2, Oracle Rdb, Oracle 12c, and Firebird.
I don’t say the standard is “universally followed” — for example SQL Server is out of step. I don’t say the whole standard is followed — only the subset related to global temporary tables. I don’t say the standard is the only thing that’s followed. But all these DBMSs support at least four, and sometimes all six, of these characteristics:
1. There is a syntax CREATE GLOBAL TEMPORARY TABLE <table-name> … The word GLOBAL means “the scope of the name is global”, that is, it’s recognized by all modules. Since most DBMSs don’t have multiple modules, the word GLOBAL is compulsory and the standard’s other type of temporary table, LOCAL, is usually not there. (I will mention, though, parenthetically, that LOCAL could optionally mean a temporary table is local to a stored procedure if it’s created in a stored procedure.)
2. If there is a non-temporary table already existing with the same name, then CREATE GLOBAL TEMPORARY TABLE fails.
3. There’s a distinction between the metadata — the definition of the table — and the data — the contents of the table.
4. The metadata is persistent; the data disappears when the session ends, or earlier.
5. The metadata is visible to all sessions in INFORMATION_SCHEMA or equivalent. The data is not visible to all sessions, and one sometimes calls the temporary table’s contents “session-specific data”.
6. There is an optional clause ON COMMIT {PRESERVE|DELETE} ROWS. When ON COMMIT DELETE ROWS is specified or is default, then the data disappears when COMMIT happens.
PostgreSQL’s behaviour is copied by MySQL
For PostgreSQL, the CREATE TEMPORARY TABLE statement arrived in PostgreSQL 6.5 which was released in June 1999. For MySQL, CREATE TEMPORARY TABLE arrived in MySQL 3.23 in August 1999.
That was before my time, but I’m a post-hoc-ergo-propter-hoc kind of guy, and I suspect that somebody was seduced by the logical fallacy that PostgreSQL has some standard SQL, therefore copy it. So the thing that’s presently in MySQL and MariaDB is CREATE TEMPORARY TABLE table_name …;
But these DBMSs support zero (0) of the six characteristics that I described for the standard-compliant DBMSs.
1. The specification of scope is missing.
2. If there is a non-temporary table already existing with the same name, then CREATE TEMPORARY TABLE succeeds, and the existing table is hidden.
3. There’s no distinction between the metadata — the definition of the table — and the data — the contents of the table.
4. The metadata is not persistent; the data disappears when the session ends, or earlier.
5. The metadata is not visible to all sessions in INFORMATION_SCHEMA or equivalent … Yes, I’m refusing to acknowledge the existence of the new table INNODB_TEMP_TABLE_INFO, for quality reasons.
6. There is no optional clause ON COMMIT {PRESERVE|DELETE} ROWS.
One funny result of this is that simple statements like SELECT * FROM table_name; can’t be fully checked or optimized at the time they’re checked within a stored procedure, because there’s no way to know what table_name is — maybe at execution time it will be the table that’s defined and visible in information_schema, but maybe it will be a temporary table which is only temporarily visible.
A less serious but irritating result is that, if you want to use a temporary table repeatedly, you have to re-create everything — find the original table definition somewhere, then add whatever indexes or views or triggers applied originally.
Is there any good news?
I wrote a worklog task about this long ago. It was WL#934 “Temporary tables in the standard way”. But it is a private Oracle spec, and is not in the Internet archive, so the general public can’t see it. There’s been no action on it that I know of. Some attention has been paid to feature request #58392 “Prevent TEMPORARY tables from shadowing regular tables” and feature request #20001 “Support for temp-tables in INFORMATION_SCHEMA”, but those are mere distractions.
However, it remains possible to implement standard global temporary tables without disrupting existing applications. The key is the syntax difference between
CREATE TEMPORARY TABLE ...; /* MySQL or MariaDB */
and
CREATE GLOBAL TEMPORARY TABLE ...; /* standard */
They’re two different statements. So one could just say that “if and only if GLOBAL is specified, then the table has to have the standard rules”.
This isn’t due to luck. It happened because in olden days MySQL’s architects paid attention to the official ANSI/ISO framework requirements:
“In the Syntax Rules, the word shall defines conditions that are required to be true of syntactically-conforming SQL language … The treatment of language that does not conform to the SQL Formats and Syntax Rules is implementation-dependent.”
In other words, by allowing only the non-standard syntax CREATE TEMPORARY TABLE, MySQL is not violating the standard. On the other hand, the latest PostgreSQL release allows CREATE GLOBAL TEMPORARY TABLE, so PostgreSQL is violating the standard. To people who read my earlier blog post “Sometimes MySQL is more standards-compliant than PostgreSQL”, that won’t come as a shock.
In the word “NoSQL”, the letters “No” are an acronym so the meaning is “Not Only SQL” rather than “No SQL”. True or false?
Historically, it’s false
The first NoSQL product was a classic DBMS which didn’t happen to use SQL for a query language, featured in Linux Journal in 1999. Its current web page has a traffic-sign symbol of the word SQL with a bar through it, and a title “NoSQL: a non-SQL RDBMS”.
For a meetup in June 2009 about “open source, distributed, non-relational databases” the question came up “What’s a good name?” Eric Evans of Rackspace suggested NoSQL, a suggestion which he later regretted.
In October 2009 Emil Eifrem of NeoTechnology tweeted “I for one have tried REALLY HARD to emphasize that #nosql = Not Only SQL”. This appears to be the earliest recorded occurrence of the suggestion. In November 2009 Mr Eifrem declared with satisfaction that the suggestion was “finally catching on”.
In other words saying “No = Not Only” is an example of a backronym, and specifically it’s a class of backronym known as False Acronyms. There are lots of these around — like the idea that “cabal” stands for seventeenth-century English ministers named Clifford Arlington Buckingham Ashley and Lauderdale, or the myth that “posh” means “port out starboard home”. False acronyms might go back at least 1600 years, if the earliest example is the “Jesus Fish”. Anyway, backronyms are popular and fun, but this one’s false.
Currently it’s unaccepted
Regardless of etymology, NoSQL could currently mean Not Only SQL, if everyone accepted that. So, getting the new interpretation going is a matter of evangelism — tell everyone that’s what it means, and hope that they’ll tell their friends. Is that working?
I think it has worked among NoSQL insiders, but it’s tenuous. If it were generally believed, then the common spelling would be NOSQL rather than NoSQL, and the common pronunciation would be “En O Ess Cue Ell” rather than “No Sequel”. Although my sample size is small, I can say that I’ve rarely seen that spelling and I’ve rarely heard that pronunciation.
And the general public knows that “no-starch” products don’t contain more than starch, or that “no-goodniks” are in a class beyond goodness, and that the slogan “No means no!” is a response to proponents of sexual assaults. So, when confronted with the claim that no doesn’t mean no, there’s inevitable resistance or disgust.
But is it true?
It would still be okay to promote the idea that “NoSQL” equals “not only SQL” if the term described a group of products that are (a) SQL and (b) something other than SQL. This is where, in a rephrasing of the Wendy’s “Where’s The Beef?” commercial, the first question is: “Where’s the SQL?”
Back in 2009 the answers would have been pathetic, but nowadays there are “SQL” query languages that come from NoSQL vendors. CQL would qualify as an SQL product if the bar was low, like saying “If it MOVEs, it’s COBOL”. Impala would qualify in a more serious way, in fact most of the core-SQL tick-box items are tickable. (I’m believing the manual, I didn’t do vicious testing as I did with MySQL.) So, although they’re a minority, there seem to be NoSQL vendors who supply SQL.
But the second question is: what can these products do that can’t be done in SQL? Well, they can supply language extensions, and they can allow the SQL layer to be bypassed. However, so can MySQL or MariaDB — think of the navigation with HANDLER or direct access with HandlerSocket. In that case MySQL would be a NoSQL DBMS, and if that were true then the term NoSQL wouldn’t distinguish the traditional from the non-traditional products, and so it would be a useless word.
Therefore pretending that NoSQL means Not Only SQL is wrong in several ways, but insisting it still means No SQL is merciless. Perhaps an honest solution is to stop saying that the word’s parts mean anything. It’s just a name now, in the same way that “PostgreSQL” is just a name and you’ve forgotten what’s it’s a post of.
We’ve written a GUI application. Its command-line options are like those in the mysql client. Its graphic features are an SQL-statement text editor and a scrollable SQL result set. It runs on Linux now and we believe it could be ported to other platforms.
Here are four screenshots.

The startup is as non-GUI as can be — in fact it gets options from the command line, or from my.cnf, the same way that the mysql client does. Wherever it seemed reasonable, we asked: What would mysql do?
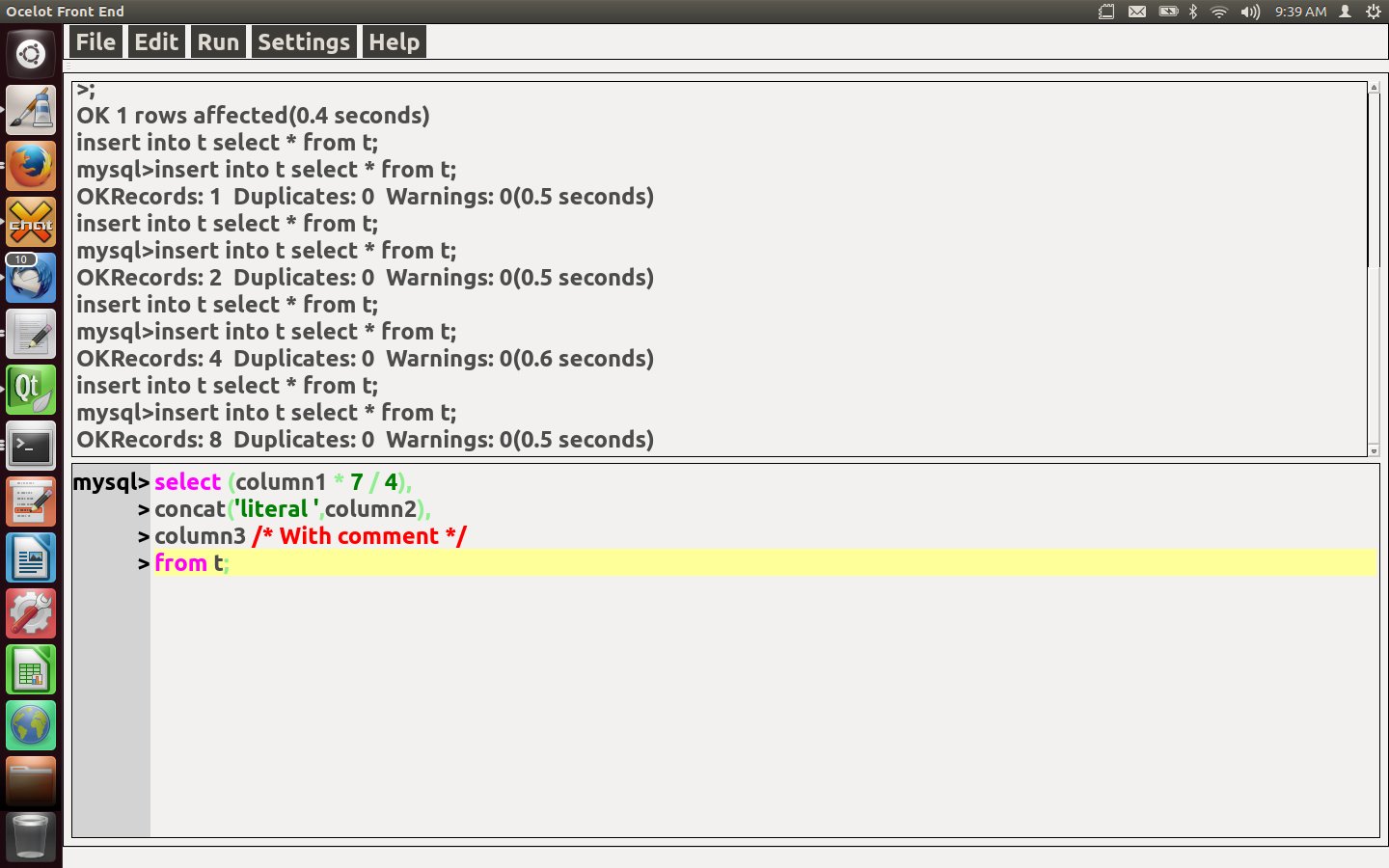
The statement (at the bottom of the screenshot) has the usual GUI features for editing, and has syntax highlighting — comments are green, reserved words are magenta, and so on.
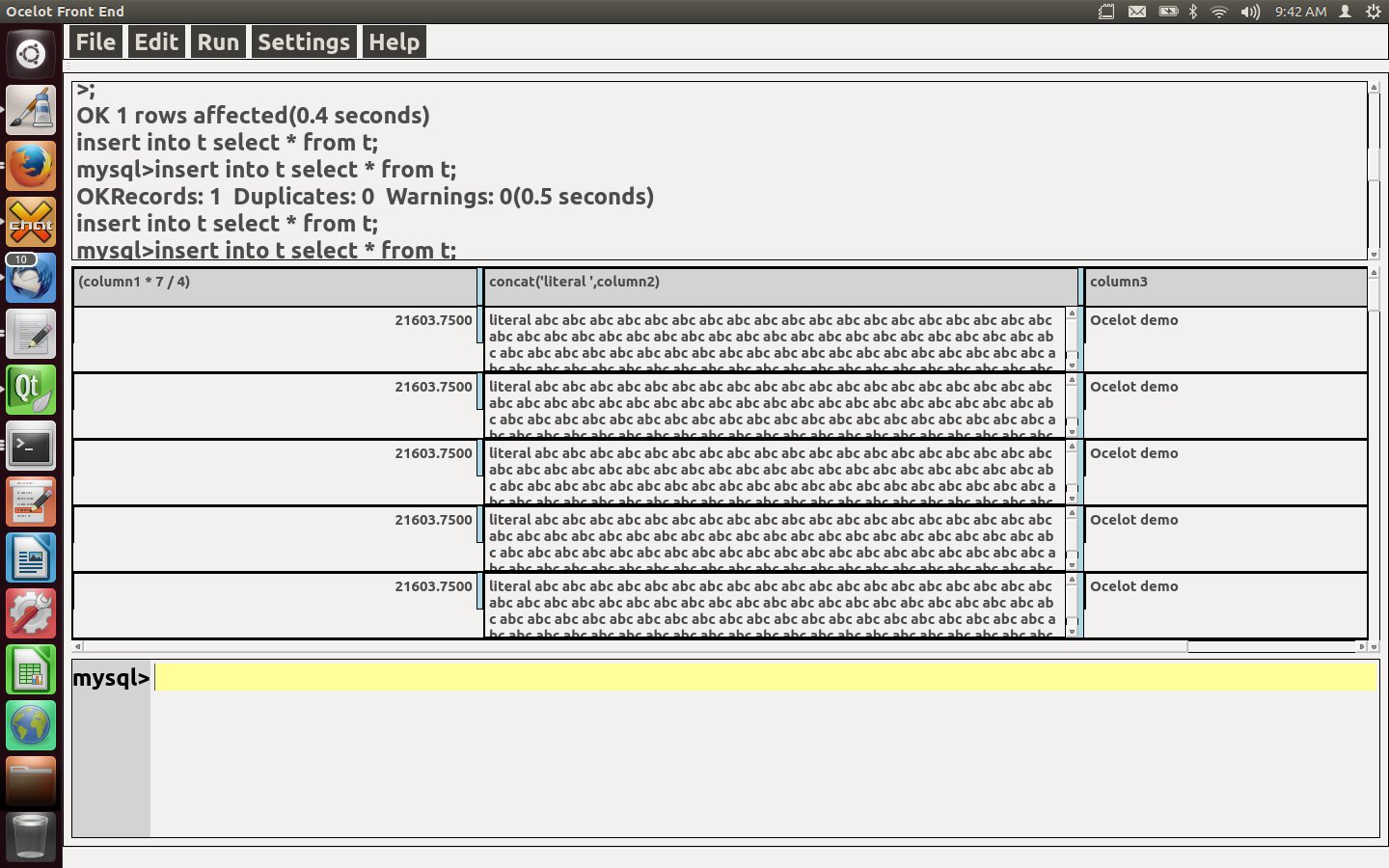
Here the result is appearing in a grid. The second column is long so it’s on multiple lines with its own scroll bars.
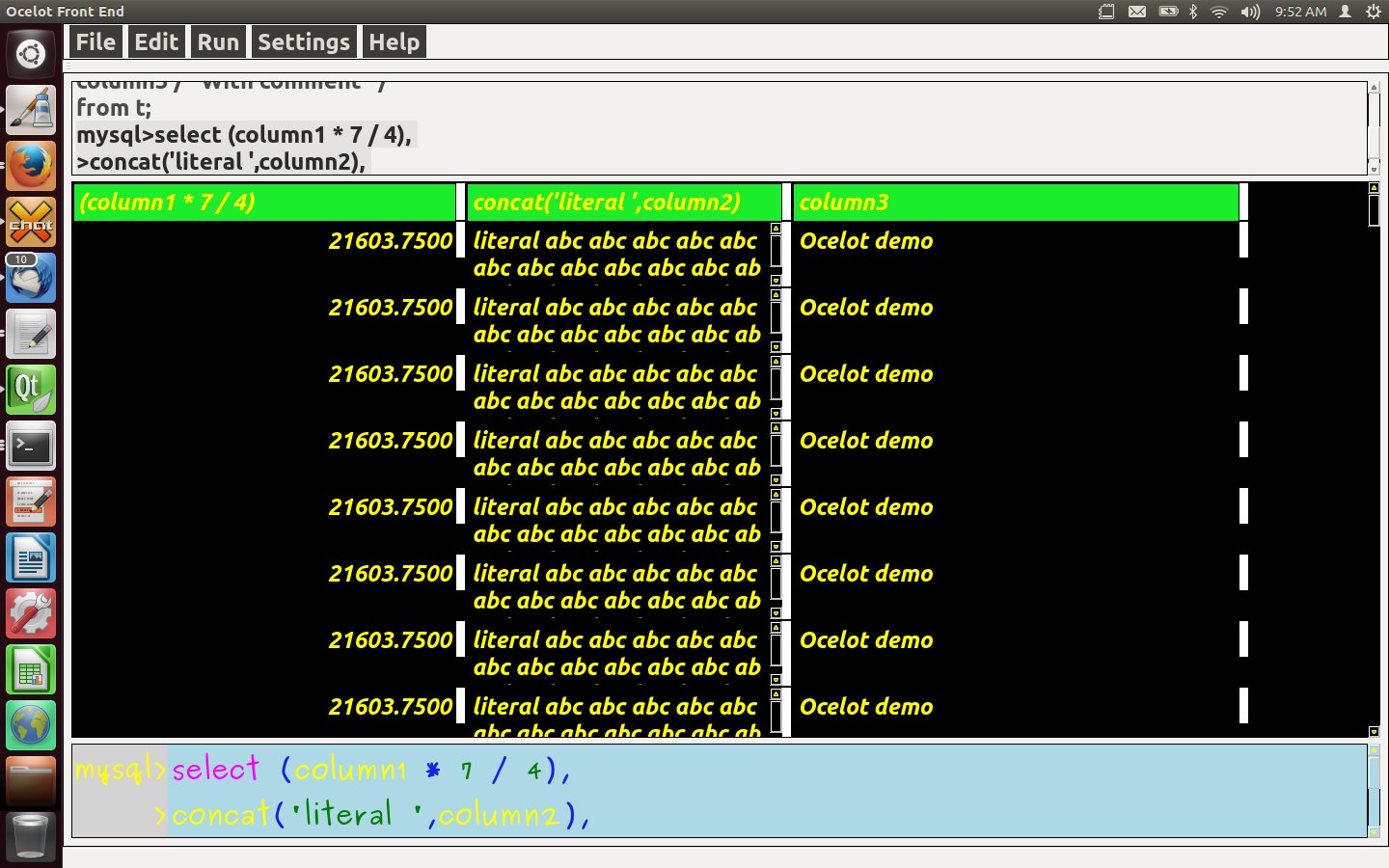
Finally, here’s the same result after fooling around with cosmetics — the colours and fonts for each section of the screen are resettable via menu items, and the column widths can be changed by dragging.
The program is written in C++ and uses Qt. Qt is available on many operating systems including Mac and Windows but we only tried Linux. The license is GPL version 2. The status is alpha — there are bugs. Source and executable files can be downloaded from https://github.com/ocelot-inc/ocelotgui.
MySQL’s support of the BINARY and VARBINARY data type is good, and the BINARY and VARBINARY data types are good things. And now the details. What applies here for MySQL applies for MariaDB as well.
Who supports VARBINARY
There’s an SQL:2008 standard optional feature T021 “BINARY and VARBINARY data types”. Our book has a bigger description, but here is one that is more up to date:
| DBMS |
Standard-ish? |
Maximum length
|
| DB2 for LUW |
No. Try CHAR FOR BIT DATA. |
254 for fixed-length, 32672 for variable-length |
| DB2 for z/OS |
Yes. |
255 for fixed-length, 32704 for variable-length |
| Informix |
No. Try CHAR. |
32767 |
| MySQL |
Yes. |
constrained by maximum row length = 65535 |
| Oracle |
No. Try RAW. |
2000 sometimes; 32767 sometimes |
| PostgreSQL |
No. Try BYTEA. |
theoretically 2**32 – 1 |
| SQL Server |
Yes. |
8000 for fixed-length. 2**31 -1 for variable length |
Standard Conformance
Provided that sql_mode=strict_all_tables, MySQL does the right (standard) thing most of the time, with two slight exceptions and one exception that isn’t there.
The first exception:
CREATE TABLE t1 (s1 VARBINARY(2));
INSERT INTO t1 VALUES (X'010200');
… This causes an error. MySQL is non-conformant. If one tries to store three bytes into a two-byte target, but the third byte is X’00’, there should be no error.
The second exception:
SET sql_mode='traditional,pipes_as_concat';
CREATE TABLE t2 (s1 VARBINARY(50000));
CREATE TABLE t3 AS SELECT s1 || s1 FROM t2;
… This does not cause an error. MySQL is non-conformant. If a concatenation results in a value that’s longer than the maximum length of VARBINARY, which is less than 65535, then there should be an error.
The exception that isn’t there:
The MySQL manual makes an odd claim that, for certain cases when there’s a UNIQUE index, “For example, if a table contains ‘a’, an attempt to store ‘a\0’ causes a duplicate-key error.” Ignore the manual. Attempting to insert ‘a\0’ will only cause a duplicate-key error if the table’s unique-key column contains ‘a\0’.
The poem Antigonish desccribed a similar case:
Yesterday, upon the stair,
I met a man who wasn’t there.
He wasn’t there again today,
I wish, I wish he’d go away…”
The BINARY trap
Since BINARY columns are fixed-length, there has to be a padding rule. For example, suppose somebody enters zero bytes into a BINARY(2) target:
CREATE TABLE t4 (s1 BINARY(2));
INSERT INTO t4 VALUES (X'');
SELECT HEX(s1) FROM t4;
… The result is ‘0000’ — the padding byte for BINARY is X’00’ (0x00), not X’20’ (space).
There also has to be a rule about what to do for comparisons if comparands end with padding bytes.
CREATE TABLE t5 (s1 VARBINARY(2));
INSERT INTO t5 VALUES (X'0102');
SELECT * FROM t5 WHERE s1 = X'010200';
… This returns zero rows. It’s implementation-defined whether MySQL should
ignore trailing X’00’ during comparisons, so there was no chance of getting
it wrong.
The behaviour difference between BINARY and VARBINARY can cause fun:
CREATE TABLE t7 (s1 VARBINARY(2) PRIMARY KEY);
CREATE TABLE t8 (s1 BINARY(2), FOREIGN KEY (s1) REFERENCES t7 (s1));
INSERT INTO t7 VALUES (0x01);
INSERT INTO t8 SELECT s1 FROM t7;
… which fails on a foreign-key constraint error! It looks bizarre
that a value which is coming from the primary-key row can’t be put
in the foreign-key row, doesn’t it? But the zero-padding rule, combined
with the no-ignore-zero rule, means this is inevitable.
BINARY(x) is a fine data type whenever it’s certain that all the values
will be exactly x bytes long, and otherwise it’s a troublemaker.
When to use VARBINARY
VARBINARY is better than TINYBLOB or MEDIUMBLOB because it has a definite
maximum size, and that makes life easier for client programs that want to
know: how wide can the display be? In most DBMSs it’s more important that BLOBs can be stored separately from the rest of the row.
VARBINARY is better than VARCHAR if there should be no validity checking.
For example, if the default character set is UTF8 then this is illegal:
CREATE TABLE t9 (s1 VARCHAR(5));
INSERT INTO t9 VALUES (0xF4808283);
… but this is legal because character set doesn’t matter:
CREATE TABLE t10 (s1 VARBINARY(5));
INSERT INTO t10 VALUES (0xF4808283);
(I ran into this example on a SQL Server forum where the participants display woeful ignorance of Unicode).
And finally converting everything to VARBINARY is one way to avoid the annoying message “Invalid mix of collations”. In fact the wikimedia folks appear to have changed all VARCHARs to VARBINARYs back in 2011 just to avoid that error. I opine that the less drastic solution is to use collations consistently, but I wasn’t there.
My former boss at MySQL sent out a notice that MySQL 5.7.4 now supports the GB18030 character set, thus responding to requests that have been appearing since 2005. This is a big deal because the Chinese government demands GB18030 support, and because the older simplified-Chinese character sets (gbk and gb2312) have a much smaller repertoire (that is, they have too few characters). And this is real GB18030 support — I can define columns and variables with CHARACTER SET GB18030. That’s rare — Oracle 12c and SQL Server 2012 and PostsgreSQL 9.3 can’t do it. (They allow input from GB18030 clients but they convert it immediately to Unicode.) Among big-time DBMSs, until now, only DB2 has treated GB18030 as a first-class character set.
Standard Adherence
We’re talking about the current version of the standard, GB18030-2005 “IT Chinese coded character set”, especially its description of 70,244 Chinese characters. I couldn’t puzzle out the Chinese wording in the official document, all I could do was use translate.google.com on some excerpts. But I’ve been told that the MySQL person who coded this feature is Chinese, so they’ll have had better luck. What I could understand was what are the difficult characters, what are the requirements for a claim of support, and what the encoding should look like. From the coder’s comments, it’s clear that part was understood. I did not check whether there was adherence for non-mandatory parts, such as Tibetan script.
Conversions
The repertoire of GB18030 ought to be the same as the Unicode repertoire. So I took a list of every Unicode character, converted to GB18030, and converted back to Unicode. The result in every case was the same Unicode character that I’d started with. That’s called “perfect round tripping”. As I explained in an earlier blog post “The UTF-8 World Is Not Enough”, storing Chinese characters with a Chinese character set has certain advantages. Well, now the biggest disadvantage has disappeared.
Hold on — how is perfect round tripping possible, given that MySQL frequently refers to Unicode 4.0, and some of the characters in GB18030-2005 are only in Unicode 4.1? Certainly that ought to be a problem according to the Unicode FAQ and this extract from Ken Lunde’s book. But it turns out to be okay because MySQL doesn’t actually disallow those characters — it accepts encodings which are not assigned to characters. Of course I believe that MySQL should have upgraded the Unicode support first, and added GB18030 support later. But the best must not be an enemy of the good.
Also the conversions to and from gb2312 work fine, so I expect that eventually gb2312 will become obsolete. It’s time for mainland Chinese users to consider switching over to gb18030 once MySQL 5.7 is GA.
Collations
The new character set comes with three collations: one trivial, one tremendous, one tsk, tsk.
The trivial collation is gb18030_bin. As always the bin stands for binary. I expect that as always this will be the most performant collation, and the only one that guarantees that no two characters will ever have the same weight.
The tremendous collation is gb18030_unicode_520_ci. The “unicode_520” part of the name really does mean that the collation table comes from “Unicode 5.2” and this is the first time that MySQL has taken to heart the maxim: what applies to the superset can apply to the subset. In fact all MySQL character sets should have Unicode collations, because all their characters are in Unicode. So to test this, I went through all the Unicode characters and their GB18030 equivalents, and compared their weights with WEIGHT_STRING:
WEIGHT_STRING(utf32_char COLLATE utf32_unicode_520_ci) to
WEIGHT_STRING(gb18030_char COLLATE gb18030_unicode_520_ci).
Every utf32 weight was exactly the same as the gb18030 weight.
The tsk, tsk collation is gb18030_chinese_ci.
The first bad thing is the suffix chinese_ci, which will make some people think that this collation is like gb2312_chinese_ci. (Such confusion has happened before for the general_ci suffix.) In fact there are thousands of differences between gb2312_chinese_ci and gb18030_chinese_ci. Here’s an example.
mysql> CREATE TABLE t5
-> (gb2312 CHAR CHARACTER SET gb2312 COLLATE gb2312_chinese_ci,
-> gb18030 CHAR CHARACTER SET gb18030 COLLATE gb18030_chinese_ci);
Query OK, 0 rows affected (0.22 sec)
mysql> INSERT INTO t5 VALUES ('[','['),(']',']');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT DISTINCT gb2312 from t5 ORDER BY gb2312;
+--------+
| gb2312 |
+--------+
| ] |
| [ |
+--------+
2 rows in set (0.00 sec)
mysql> SELECT DISTINCT gb18030 from t5 ORDER BY gb18030;
+---------+
| gb18030 |
+---------+
| [ |
| ] |
+---------+
2 rows in set (0.00 sec)
See the difference? The gb18030 order is obviously better — ‘]’ should be greater than ‘[‘ — but when two collations are wildly different they shouldn’t both be called “chinese_ci”.
The second bad thing is the algorithm. The new chinese_ci collation is based on pinyin for Chinese characters, and binary comparisons of the UPPER() values for non-Chinese characters. This is pretty well useless for non-Chinese. I can bet that somebody will observe “well, duh, it’s a Chinese character set” — but I can’t see why one would use an algorithm for Latin/Greek/Cyrillic/etc. characters that’s so poor. There’s a Common Locale Data Repository for tailoring for Chinese, there are MySQL worklog tasks that explain the brave new world, there’s no need to invent an idiolect when there’s a received dialect.
Documentation
The documentation isn’t up to date yet — there’s no attempt to explain what the new character set and its collations are about, and no mention at all in the FAQ.
But the worklog task WL#4024: gb18030 Chinese character set gives a rough idea of what the coder had in mind before starting. It looks as if WL#4024 was partly copied from http://icu-project.org/docs/papers/unicode-gb18030-faq.html so that’s also worth a look.
For developers who just need to know what’s going on now, just re-read this blog post. What I’ve described should be enough for people who care about Chinese.
I didn’t look for bugs with full-text or LIKE searches, and I didn’t look at speed. But I did look hard for problems with the essentials, and found none. Congratulations are due.
Update on July 17 2014: A source at MariaDB tells me that they’ve worked on GB18030 too. And the MySQL folks have closed a GB18030 bug that ‘Y’ = tilde” in the Chinese collation — not realizing that it’s a duplicate of a bug that I reported seven years ago.
Firebird is an open-source DBMS with a long history and good SQL support. Although I measured Firebird’s importance as smaller than MySQL’s or MariaDB’s, it exists, and might grow a bit when Firebird becomes the default LibreOffice DBMS.
I decided to compare the current versions of MySQL 5.6 and Firebird SQL 2.5. I only looked at features that end users can see, without benchmarking. Preparing for the comparison was easy. I looked at the instructions for downloading Firebird with Ubuntu and within 15 minutes I was entering SQL statements. The documentation is disorganized but when in doubt I could guess what to do, since the Firebird folks care about standards.
I’ll organize the discussion according to the ANSI/ISO feature list. I’ll skip the features which both products support equally, which means I’ll skip the great majority, because both products are very similar. Then: For every feature where MySQL is better, MySQL gets a point. For every feature where Firebird is better, Firebird gets a point. The only way to be objective is to be arbitrary.


Mandatory Features
|
| Feature |
Firebird Point |
MySQL Point |
Explanation |
| E011-03 DECIMAL and NUMERIC types |
|
1 |
Firebird maximum number of digits = 18. MySQL maximum = 65. |
| E021-02 CHARACTER VARYING data type |
|
1 |
Firebird maximum VARCHAR length = 32767. MySQL maximum = 65535. |
| E021-07 Character concatenation |
1 |
|
Firebird concatenation operator is ||. MySQL has CONCAT() by default. |
| E031-01 Delimited identifiers |
1 |
|
Firebird delimiter “” means case-sensitive. MySQL has no viable equivalent. |
| E041-04 Basic foreign key |
1 |
|
In Firebird one can use syntax variants that MySQL/InnoDB ignores. |
| E101-03 Searched UPDATE statement |
1 |
|
Firebird has fixed a small flaw. MySQL still has the flaw. |
| E141-08 CHECK clause |
1 |
|
MySQL doesn’t have this. |
| F031-03 GRANT statement |
1 |
1 |
Only Firebird can grant to PUBLIC. But only MySQL can grant TRIGGER. One point each. |
| F051-03 TIMESTAMP data type |
|
1 |
Firebird can have 4 digits for seconds precision, MySQL can have 6. |
| T321-01 User-defined SQL functions |
|
1 |
Firebird only has procedures, and they’re PLSQL syntax. MySQL has standard syntax. |
| 9075-11 information_schema |
|
1 |
Firebird doesn’t have this. |
Optional Features
|
| Feature |
Firebird Point |
MySQL Point |
Explanation |
| F121-01 GET DIAGNOSTICS |
|
1 |
Firebird doesn’t have this. |
| F200 TRUNCATE |
|
1 |
Firebird doesn’t have this. |
| F201 CAST function |
1 |
|
In Firebird I can cast to (among other data types) VARCHAR, SMALLINT, INT, BIGINT, NUMERIC, TIMESTAMP. In MySQL, I can’t. |
| F221 Explicit defaults |
|
1 |
Both products allow DEFAULT in CREATE statements, but only MySQL allows DEFAULT in UPDATE or INSERT statements. |
| F251 Domain support |
1 |
|
MySQL doesn’t have this. |
| F312 Merge statement |
1 |
|
MySQL doesn’t have a MERGE statement, although it does have near equivalents. |
| F391 Long identifiers |
|
1 |
Firebird maximum length = 31. MySQL maximum length = 64. Both are sub-standard. |
| F401-02 Full outer join |
1 |
|
MySQL doesn’t have this. |
| F461 Named character sets |
|
1 |
See Note #1. |
| F531 Temporary tables |
1 |
|
Firebird allows CREATE GLOBAL TEMPORARY. MySQL has temporary tables in a non-standard way. |
| F690 Collation support |
|
1 |
See Note #2. |
| T021 BINARY and VARBINARY data types |
|
1 |
Firebird doesn’t have this, although it does allow specifying a character set as OCTETS,which is comparable to MySQL’s “binary”. |
| T121 WITH (excluding RECURSIVE) in query |
1 |
|
Firebird recently added WITH support. MySQL doesn’t have it. Incidental note: misinformation has been spread about MySQL’s history for this feature, for example the first comment on this blog post. The fact is that in 2004 MySQL decided to support CONNECT BY, not WITH. Then it didn’t implement it. |
| T131 Recursive query |
1 |
|
MySQL doesn’t have this. |
| T141 SIMILAR predicate |
1 |
|
MySQL doesn’t have this. |
| T171 LIKE clause in table definition |
|
1 |
Firebird doesn’t have this. |
| T172 AS clause in table definition |
|
1 |
Firebird doesn’t have this. |
T176 Sequence generator support |
1 |
|
Firebird only supports a “CREATE SEQUENCE sequence-name” statement, but that’s enough for a point. |
| T211 Basic trigger capability |
|
|
See the table in an earlier post but MySQL has more standard CREATE TRIGGER syntax. Can’t decide. |
| T281 SELECT privilege with column granularity |
|
1 |
Firebird doesn’t have this. |
| T331 Basic roles |
1 |
|
Firebird has 50% support. MySQL has nothing. MariaDB roles are beta. |
Note #1: Re character sets: Ignoring duplicates, alias names, and slight variations: Firebird multi-byte character sets are gbk, sjis, utf-8, big5, gb2312, eucjp, ksc 5601, gb18030. MySQL multi-byte character sets are gbk, sjis, utf-8, big5, gb2312, eucjp, euckr, utf-16, utf-32. As I put it in an earlier blog post, “The UTF-8 world is not enough”. MySQL has more, so it gets the point.
Note #2: Re collations: Although Firebird deserves special mention for supporting a slightly later version of the Unicode Collation Algorithm, the only multi-byte character set for which Firebird has many collations is UTF-8. Firebird has only four collations for UTF-8: ucs_basic (code point order), and unicode / unicode_ci / unicode_ci_ai (variations of UCA order with and without case sensitivity or accent sensitivity). MySQL has additionally: Croatian, Czech, Danish, Estonian, German, Hungarian, Iceland, Latvian, Lithuanian, Persian, Polish, Romanian, Sinhala, Slovak, Slovenian, Spanish, Swedish, Turkish, Vietnamese. Incidental side note: guess whom the Firebird manual points to for extra documentation about its character sets? None other than the guy who coded MySQL’s collations, a certain A. Barkov, formerly of MySQL, now of MariaDB.
Total points for Firebird: 16. Total points for MySQL: 16.
Update: in an earlier edition of this post, I broke the tie by giving Firebird a delay-of-game penalty on the basis that the makers started talking about version 3.0 in 2011, and version 3.0 is still alpha, and I concluded “MySQL wins by a score of 16 to 16”. That wasn’t serious. The fair way to break the tie is to decide which features should have more weight.
If you haven’t read the Wikipedia article on deprecation, you might not know it’s from the Latin word deprecare, meaning “to ward off (a disaster) by prayer.” That pretty well describes the quandary for any software product that has a big established user base. Is it better to keep junk features, in case removing them will cause disasters for the old users? Or is it better to remove junk features, to avoid ridicule and to make the manual slimmer for the new users?
Historically MySQL has deprecated with caution, and usually MySQL has followed these steps:
(1) In version X, for any SQL statement that appears to use the feature, return a warning that the feature “has been deprecated and may be removed in a future release”.
(2) Also in version X, put a notification in the manual. Notifications have a regular pattern so they’re easy to find by looking in the “What’s new” section, such as http://dev.mysql.com/doc/relnotes/mysql/5.7/en/news-5-7-4.html, and http://dev.mysql.com/doc/relnotes/mysql/5.7/en/news-5-7-4.html.
Alternatively, one can look for the “nutshell” pages, such as https://dev.mysql.com/doc/refman/5.6/en/mysql-nutshell.html and https://dev.mysql.com/doc/refman/5.5/en/mysql-nutshell.html. Or, in googlespeak, site:dev.mysql.com/doc “what’s new” “deprecated”. Notice that I am pointing only to the MySQL manual, because MariaDB does not appear to have an equivalent (the MariaDB “deprecation policy” page only talks about supported platforms).
(3) In version X+1 or X+2, actually remove the feature and start throwing syntax errors.
My all-time favourite deprecation was of the TIMESTAMP(M) data type before version 4.1. The M stood for “display width”, for example, with TIMESTAMP(6) you’d only see the first few digits. We realized that was in conflict with the ANSI/ISO standard, so it became deprecated in 4.x, became a syntax error in 5.x, and then — years after the original warning — the syntax became legal again with a different meaning, so now the 6 in TIMESTAMP(6) means “fractional seconds”. Because there was a period when the syntax was simply illegal, it was practically impossible to move an old application to the new format without noticing anything.
These are my nominations for favourite deprecations in 5.6 and 5.7.
SHOW AUTHORS.
SHOW AUTHORS was an “Easter egg”. Naturally I reported it as such at the time because Easter eggs are more than bugs, they are vandalism. Eventually the feature got documented, but the smell of rotten eggs was in my nose for years afterward, so I’m relieved it’s gone.
INFORMATION_SCHEMA.PROFILING
Faithful readers of my blog posts will of course recall me saying in 2008
A bit of a caveat: I was totally against adding this feature, and some of my bias might show. But I’m not trying to argue about it. I do believe that once we add a feature we should explain it, and all I’m trying to do is explain here.
… which had nothing to do with the quality of the user contribution. People who know me as the original crusader for PERFORMANCE_SCHEMA might guess that I saw this feature as out of step.
INSERT DELAYED
INSERT DELAYED wasn’t junk per se. The problem with little non-standard performance-enhancing niblets is that they’re always non-orthogonal. People sense that. So the bug report / feature request for — why not? — “UPDATE DELAYED” got about 15 votes. Adding the EVENTS feature didn’t quell the protesters, because any rational person could see that, if INSERT DELAYED was okay syntax, UPDATED DELAYED should also be. (This makes two posts in a row where I’m railing about lack of orthogonality — I brought it up in my blog post last week about MariaDB’s DELETE … RETURNING feature. By the way, I updated that post to show what decent standard-fearing folk would do instead of copying PostgreSQL.) So, to stop the protests that there’s a precedent, get rid of the precedent. Well done.
What these deprecations are telling me is that somebody at MySQL at last has the authority and determination to clean the garage. The product is not just getting new good features, it’s losing old bad ones.
Today I looked at the MariaDB Release Candidate wondering how my earlier predictions came out.
I predicted, for “roles”:
For all of the bugs, and for some of the flaws, there’s no worry — they’ll probably disappear.
In fact all the bugs are gone, and I belatedly realized (after some gentle nudges from a MariaDB employee) that some of the flaws weren’t flaws.
The inability to grant to PUBLIC still troubles me, but it looks like roles are ready to roll.
I predicted for “mroonga”:
At the time I’m writing this, MariaDB 10.0.8 doesn’t have mroonga yet.
In other words, I thought it would be in 10.0.8. It was not to be, as another MariaDB employee told me:
Unfortunately, mroonga appeared to have some portability problems. Most likely it won’t be in 10.0.8. There is a good chance it will be 10.0.9 though.
While I was looking, I tried out a new clause for the DELETE statement:
DELETE FROM t RETURNING select-list;
which returns the rows that just got deleted. It’s a new non-standard clause which increases MariaDB’s divergence from MySQL, so decent people should demand an explanation.
Oracle 12c looks similar but does something different:
DELETE FROM t RETURN|RETURNING expr [,expr...] INTO data-item [,data-item...];
SQL Server 2012 has a clause which looks different but does something similar:
DELETE FROM t OUTPUT select-list;
PostgreSQL has a clause which looks similar and does something similar:
DELETE FROM t RETURNING select-list;
So we’re seeing, yet again, the belief that PostgreSQL is a better model for MariaDB than the big boys are. By the way, the big boys are a bit more orthogonal — I’ve seen extensions similar to this one in UPDATE or MERGE statements. But the bigger orthogonality woe is that here we have a statement that returns a result set, but can’t be used in all the places where a result-set-returning sub-statement could work, like DECLARE CURSOR FOR DELETE, or INSERT … DELETE. Of course, I’m glad they don’t work. My point is only that now-it-works-now-it-doesn’t additions make the product look haphazard.
Update: How it’s done in standard SQL
This section was added on 2014-03-01, one week after the original post.
SQL:2011 has a non-core (optional) feature T495 “Combined data change and retrieval”. Ignoring a lot, the syntax is SELECT … FROM NEW|OLD|FINAL TABLE (INSERT|UPDATE|DELETE …) …. For example
SELECT column1+5 FROM OLD TABLE (DELETE FROM t) AS t WHERE f = 77;
In this example table t is a “delta table”.
There’s an example with DECLARE CURSOR and FETCH in the DB2 10 for z/OS manual.
