Category: Standard SQL
The BINARY and VARBINARY data types
MySQL’s support of the BINARY and VARBINARY data type is good, and the BINARY and VARBINARY data types are good things. And now the details. What applies here for MySQL applies for MariaDB as well.
Who supports VARBINARY
There’s an SQL:2008 standard optional feature T021 “BINARY and VARBINARY data types”. Our book has a bigger description, but here is one that is more up to date:
| DBMS | Standard-ish? | Maximum length |
|---|---|---|
| DB2 for LUW | No. Try CHAR FOR BIT DATA. | 254 for fixed-length, 32672 for variable-length |
| DB2 for z/OS | Yes. | 255 for fixed-length, 32704 for variable-length |
| Informix | No. Try CHAR. | 32767 |
| MySQL | Yes. | constrained by maximum row length = 65535 |
| Oracle | No. Try RAW. | 2000 sometimes; 32767 sometimes |
| PostgreSQL | No. Try BYTEA. | theoretically 2**32 – 1 |
| SQL Server | Yes. | 8000 for fixed-length. 2**31 -1 for variable length |
Standard Conformance
Provided that sql_mode=strict_all_tables, MySQL does the right (standard) thing most of the time, with two slight exceptions and one exception that isn’t there.
The first exception:
CREATE TABLE t1 (s1 VARBINARY(2)); INSERT INTO t1 VALUES (X'010200');
… This causes an error. MySQL is non-conformant. If one tries to store three bytes into a two-byte target, but the third byte is X’00’, there should be no error.
The second exception:
SET sql_mode='traditional,pipes_as_concat'; CREATE TABLE t2 (s1 VARBINARY(50000)); CREATE TABLE t3 AS SELECT s1 || s1 FROM t2;
… This does not cause an error. MySQL is non-conformant. If a concatenation results in a value that’s longer than the maximum length of VARBINARY, which is less than 65535, then there should be an error.
The exception that isn’t there:
The MySQL manual makes an odd claim that, for certain cases when there’s a UNIQUE index, “For example, if a table contains ‘a’, an attempt to store ‘a\0’ causes a duplicate-key error.” Ignore the manual. Attempting to insert ‘a\0’ will only cause a duplicate-key error if the table’s unique-key column contains ‘a\0’.
The poem Antigonish desccribed a similar case:
Yesterday, upon the stair,
I met a man who wasn’t there.
He wasn’t there again today,
I wish, I wish he’d go away…”
The BINARY trap
Since BINARY columns are fixed-length, there has to be a padding rule. For example, suppose somebody enters zero bytes into a BINARY(2) target:
CREATE TABLE t4 (s1 BINARY(2)); INSERT INTO t4 VALUES (X''); SELECT HEX(s1) FROM t4;
… The result is ‘0000’ — the padding byte for BINARY is X’00’ (0x00), not X’20’ (space).
There also has to be a rule about what to do for comparisons if comparands end with padding bytes.
CREATE TABLE t5 (s1 VARBINARY(2)); INSERT INTO t5 VALUES (X'0102'); SELECT * FROM t5 WHERE s1 = X'010200';
… This returns zero rows. It’s implementation-defined whether MySQL should
ignore trailing X’00’ during comparisons, so there was no chance of getting
it wrong.
The behaviour difference between BINARY and VARBINARY can cause fun:
CREATE TABLE t7 (s1 VARBINARY(2) PRIMARY KEY); CREATE TABLE t8 (s1 BINARY(2), FOREIGN KEY (s1) REFERENCES t7 (s1)); INSERT INTO t7 VALUES (0x01); INSERT INTO t8 SELECT s1 FROM t7;
… which fails on a foreign-key constraint error! It looks bizarre
that a value which is coming from the primary-key row can’t be put
in the foreign-key row, doesn’t it? But the zero-padding rule, combined
with the no-ignore-zero rule, means this is inevitable.
BINARY(x) is a fine data type whenever it’s certain that all the values
will be exactly x bytes long, and otherwise it’s a troublemaker.
When to use VARBINARY
VARBINARY is better than TINYBLOB or MEDIUMBLOB because it has a definite
maximum size, and that makes life easier for client programs that want to
know: how wide can the display be? In most DBMSs it’s more important that BLOBs can be stored separately from the rest of the row.
VARBINARY is better than VARCHAR if there should be no validity checking.
For example, if the default character set is UTF8 then this is illegal:
CREATE TABLE t9 (s1 VARCHAR(5)); INSERT INTO t9 VALUES (0xF4808283);
… but this is legal because character set doesn’t matter:
CREATE TABLE t10 (s1 VARBINARY(5)); INSERT INTO t10 VALUES (0xF4808283);
(I ran into this example on a SQL Server forum where the participants display woeful ignorance of Unicode).
And finally converting everything to VARBINARY is one way to avoid the annoying message “Invalid mix of collations”. In fact the wikimedia folks appear to have changed all VARCHARs to VARBINARYs back in 2011 just to avoid that error. I opine that the less drastic solution is to use collations consistently, but I wasn’t there.
MySQL versus Firebird
Firebird is an open-source DBMS with a long history and good SQL support. Although I measured Firebird’s importance as smaller than MySQL’s or MariaDB’s, it exists, and might grow a bit when Firebird becomes the default LibreOffice DBMS.
I decided to compare the current versions of MySQL 5.6 and Firebird SQL 2.5. I only looked at features that end users can see, without benchmarking. Preparing for the comparison was easy. I looked at the instructions for downloading Firebird with Ubuntu and within 15 minutes I was entering SQL statements. The documentation is disorganized but when in doubt I could guess what to do, since the Firebird folks care about standards.
I’ll organize the discussion according to the ANSI/ISO feature list. I’ll skip the features which both products support equally, which means I’ll skip the great majority, because both products are very similar. Then: For every feature where MySQL is better, MySQL gets a point. For every feature where Firebird is better, Firebird gets a point. The only way to be objective is to be arbitrary.


Mandatory Features |
|||
|---|---|---|---|
| Feature | Firebird Point | MySQL Point | Explanation |
| E011-03 DECIMAL and NUMERIC types | 1 | Firebird maximum number of digits = 18. MySQL maximum = 65. | |
| E021-02 CHARACTER VARYING data type | 1 | Firebird maximum VARCHAR length = 32767. MySQL maximum = 65535. | |
| E021-07 Character concatenation | 1 | Firebird concatenation operator is ||. MySQL has CONCAT() by default. | |
| E031-01 Delimited identifiers | 1 | Firebird delimiter “” means case-sensitive. MySQL has no viable equivalent. | |
| E041-04 Basic foreign key | 1 | In Firebird one can use syntax variants that MySQL/InnoDB ignores. | |
| E101-03 Searched UPDATE statement | 1 | Firebird has fixed a small flaw. MySQL still has the flaw. | |
| E141-08 CHECK clause | 1 | MySQL doesn’t have this. | |
| F031-03 GRANT statement | 1 | 1 | Only Firebird can grant to PUBLIC. But only MySQL can grant TRIGGER. One point each. |
| F051-03 TIMESTAMP data type | 1 | Firebird can have 4 digits for seconds precision, MySQL can have 6. | |
| T321-01 User-defined SQL functions | 1 | Firebird only has procedures, and they’re PLSQL syntax. MySQL has standard syntax. | |
| 9075-11 information_schema | 1 | Firebird doesn’t have this. | |
Optional Features |
|||
|---|---|---|---|
| Feature | Firebird Point | MySQL Point | Explanation |
| F121-01 GET DIAGNOSTICS | 1 | Firebird doesn’t have this. | |
| F200 TRUNCATE | 1 | Firebird doesn’t have this. | |
| F201 CAST function | 1 | In Firebird I can cast to (among other data types) VARCHAR, SMALLINT, INT, BIGINT, NUMERIC, TIMESTAMP. In MySQL, I can’t. | |
| F221 Explicit defaults | 1 | Both products allow DEFAULT in CREATE statements, but only MySQL allows DEFAULT in UPDATE or INSERT statements. | |
| F251 Domain support | 1 | MySQL doesn’t have this. | |
| F312 Merge statement | 1 | MySQL doesn’t have a MERGE statement, although it does have near equivalents. | |
| F391 Long identifiers | 1 | Firebird maximum length = 31. MySQL maximum length = 64. Both are sub-standard. | |
| F401-02 Full outer join | 1 | MySQL doesn’t have this. | |
| F461 Named character sets | 1 | See Note #1. | |
| F531 Temporary tables | 1 | Firebird allows CREATE GLOBAL TEMPORARY. MySQL has temporary tables in a non-standard way. | |
| F690 Collation support | 1 | See Note #2. | |
| T021 BINARY and VARBINARY data types | 1 | Firebird doesn’t have this, although it does allow specifying a character set as OCTETS,which is comparable to MySQL’s “binary”. | |
| T121 WITH (excluding RECURSIVE) in query | 1 | Firebird recently added WITH support. MySQL doesn’t have it. Incidental note: misinformation has been spread about MySQL’s history for this feature, for example the first comment on this blog post. The fact is that in 2004 MySQL decided to support CONNECT BY, not WITH. Then it didn’t implement it. | |
| T131 Recursive query | 1 | MySQL doesn’t have this. | |
| T141 SIMILAR predicate | 1 | MySQL doesn’t have this. | |
| T171 LIKE clause in table definition | 1 | Firebird doesn’t have this. | |
| T172 AS clause in table definition | 1 | Firebird doesn’t have this. | T176 Sequence generator support | 1 | Firebird only supports a “CREATE SEQUENCE sequence-name” statement, but that’s enough for a point. |
| T211 Basic trigger capability | See the table in an earlier post but MySQL has more standard CREATE TRIGGER syntax. Can’t decide. | ||
| T281 SELECT privilege with column granularity | 1 | Firebird doesn’t have this. | |
| T331 Basic roles | 1 | Firebird has 50% support. MySQL has nothing. MariaDB roles are beta. | |
Note #1: Re character sets: Ignoring duplicates, alias names, and slight variations: Firebird multi-byte character sets are gbk, sjis, utf-8, big5, gb2312, eucjp, ksc 5601, gb18030. MySQL multi-byte character sets are gbk, sjis, utf-8, big5, gb2312, eucjp, euckr, utf-16, utf-32. As I put it in an earlier blog post, “The UTF-8 world is not enough”. MySQL has more, so it gets the point.
Note #2: Re collations: Although Firebird deserves special mention for supporting a slightly later version of the Unicode Collation Algorithm, the only multi-byte character set for which Firebird has many collations is UTF-8. Firebird has only four collations for UTF-8: ucs_basic (code point order), and unicode / unicode_ci / unicode_ci_ai (variations of UCA order with and without case sensitivity or accent sensitivity). MySQL has additionally: Croatian, Czech, Danish, Estonian, German, Hungarian, Iceland, Latvian, Lithuanian, Persian, Polish, Romanian, Sinhala, Slovak, Slovenian, Spanish, Swedish, Turkish, Vietnamese. Incidental side note: guess whom the Firebird manual points to for extra documentation about its character sets? None other than the guy who coded MySQL’s collations, a certain A. Barkov, formerly of MySQL, now of MariaDB.
Total points for Firebird: 16. Total points for MySQL: 16.
Update: in an earlier edition of this post, I broke the tie by giving Firebird a delay-of-game penalty on the basis that the makers started talking about version 3.0 in 2011, and version 3.0 is still alpha, and I concluded “MySQL wins by a score of 16 to 16”. That wasn’t serious. The fair way to break the tie is to decide which features should have more weight.
Tuples
“It is better to keep silence and be thought a fool, than to say ‘tuple’ and remove all doubt.”
But recently people have been using the word “tuple” more frequently. Doubtless all those people know that in relational databases a tuple (or a tuple value) is a formal term for a row of a table. It’s possible to know a bit more than that.
Pronounced Tyoople, Toople, or Tuhple?
The Oxford Dictionaries site says Tyoople. Other dictionaries are neutral about the terms from which Tuple was derived (sextuple, octuple, etc.), for example Merriam-Webster says they usually end in Toople but Tuhple is an accepted alternate, and the Oxford Canadian Dictionary says it’s always Tuhple. So the question comes down to: what is the proper way in a database context?
I found one book that says Tuple rhymes with Scruple, that is, it’s Toople: Rod Stephens, Beginning Database Design Solutions. But Mr Stephens also tells us that tables are called relations because “the values of a row are related”, so I’m wary about him.
I found four books that say Tuple rhymes with Couple, that is, it’s Tuhple:
- David Kroenke, Database Processing: Fundamentals, Design and Implementation
- Kevin Loney, Oracle9i The Complete Reference
- Donald Burleson, Oracle High-Performance SQL Tuning
- Paul Nielsen, SQL Server 2005 Bible
Then I found the decisive one:
C.J.Date, An Introduction To Database Systems.
I quote:
The relational model therefore does not use the term “record” at all; instead it uses the term “tuple” (rhymes with “couple”).
Since C.J.Date had many conversations with the The Founder (E.F.Codd), and Mr Codd would have been certain to correct Mr Date if he had mispronounced, this is decisive. Most writers in the field, including the one who ought to know, are saying that it rhymes with couple.
Wait a minute — couple was originally a French word, and the French would use an oo sound, what about that? A good explanation, although it’s based on analogy, is that some Middle English words with oo (like blood and flood) changed in stages from the oo sound to the uh sound in the centuries following the Great English Vowel Shift. See the Wikipedia article about Phonological history of English high back vowels. So the reply to people who say “etymologically it was an oo sound” would be “yes, but oo changed to uh as part of a trend, get modern”.
But what if it’s a non-relational tuple?
Quoting C.J.Date again (from The Relational Database Dictionary):
NOTE: Tuples as defined in the relational model differ in certain respects from the mathematical construct of the same name. In particular, tuples in mathematics typically don’t have named attributes; instead, their attributes are identified by their ordinal position, left to right.
Aha. So if a sequence of values doesn’t have a corresponding header with a sequence of column names, it shouldn’t be called a row (that would be relational) but it could be called a tuple — provided it’s not in a relational database. In practice that’s seems to be a fairly common usage, but I’ll highlight the products where it seems to be the preferred usage.
- Tuple Spaces.
The modest idea of just filling a space with tuples, and calling it a
“tuple space”, started off in 1982 with a language named Linda. Since then the general concept has gotten into various Java implementations. - Python.
The tuple is a supported data type that’s part of the Python core.
Of course there are similar things in other languages but I believe
that Python is the most prominent language that actually calls it a
tuple. - Pig.
- FoundationDB.
- Tarantool.
Actually one of my current projects is enhancing Tarantool’s documentation, which is what led me to wonder about the word.
The MySQL manual usually avoids the term, although it’s more frequent with NDB.
Alas
Recently I saw a poll with a single question:
What is to be Done? (a) Nothing (b) Something
I think that (a) won, hurrah. And yet it would have been a finer world if everyone had agreed that “tuple” meant a sequence of values, “record” meant a sequence of values which had fixed types, and “row” meant a sequence of values which had both fixed types and fixed names. If only Mr Codd had left the vocabulary alone …
Sometimes MySQL is more standards-compliant than PostgreSQL
Here are examples comparing MySQL 5.6 against PostgreSQL 9.3 Core Distribution, where MySQL seems to comply with “standard SQL” more closely than PostgreSQL does. The examples are also true for MariaDB 10.0 so whenever I say “MySQL” I mean “MySQL and/or MariaDB”. When I say “more closely” I do not mean that MySQL is completely compliant, or that PostgreSQL is completely non-compliant.
Identifiers
Example:
CREATE TABLE ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ (s1 INT); /* 32-character name */
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name = 'ŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽŽ';
SELECT COUNT(*) FROM information_schema.tables
WHERE table_name LIKE LOWER('Ž%');
Result:
PostgreSQL says count(*) is 0. MySQL says it’s 1.
Reason:
(1) PostgreSQL maximum identifier length is 63 bytes; MySQL maximum identifier length is 64 characters. The standard requirement is 128 characters.
(2) With PostgreSQL, if you insert an invalid value, PostgreSQL truncates — it “tries to make do” rather than failing. (If the name had been too long for MySQL, it would have thrown an error.)
(3) PostgreSQL does not convert to lower case during CREATE, and does a case-sensitive search during SELECT.
Character Sets And Collations
Example:
CREATE TABLE t (s1 CHAR(1) CHARACTER SET utf16);
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support named character sets; it can only handle one character set per database.
Example:
CREATE TABLE t (s1 CHAR(2), s2 VARCHAR(2));
INSERT INTO t VALUES ('y ','y ');
SELECT * FROM t WHERE s1 = 'y';
SELECT * FROM t WHERE s2 = 'y';
Result:
PostgreSQL finds one row for the first SELECT but zero rows for the second SELECT. MySQL finds one row both times.
Reason:
PostgreSQL does not always add spaces to the shorter comparand, or remove spaces from the longer comparand. MySQL is consistent. The behaviour is optional, but it is not supposed to depend on the data type.
Example:
CREATE TABLE t (s1 CHAR(1), uca CHAR(4),utf32 CHAR(6),utf8 CHAR(8),name VARCHAR(50)); INSERT INTO t VALUES (U&'\+003044','3197',' 3044',' E38184','HIRAGANA LETTER I'); INSERT INTO t VALUES (U&'\+003046','3198',' 3046',' E38186','HIRAGANA LETTER U'); INSERT INTO t VALUES (U&'\+0030A4','3197',' 30A4',' E382A4','KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+0030A5','3198',' 30a5',' E382A5','KATAKANA LETTER SMALL U'); INSERT INTO t VALUES (U&'\+00FF72','3197',' FF72',' EFBDB2','HALFWIDTH KATAKANA LETTER I'); INSERT INTO t VALUES (U&'\+00042B','1AF1',' 042B',' D0AB','CYRILLIC CAPITAL LETTER YERU'); INSERT INTO t VALUES (U&'\+0004F9','1AF5',' 04F9',' D3B9','CYRILLIC SMALL LETTER YERU WITH DIAERESIS'); INSERT INTO t VALUES (U&'\+0004CF','1B4A',' 04CF',' D38F','CYRILLIC SMALL LETTER PALOCHKA'); INSERT INTO t VALUES (U&'\+002C13','1B61',' 2C13',' E2B093','GLAGOLITIC CAPITAL LETTER RITSI'); INSERT INTO t VALUES (U&'\+0100CC','3872',' 100CC','F090838C','LINEAR B IDEOGRAM B240 WHEELED CHARIOT'); SELECT * FROM t ORDER BY s1 COLLATE "C",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "POSIX",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "C.UTF-8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "en_CA.utf8",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "default",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "ucs_basic",uca DESC,name; SELECT * FROM t ORDER BY s1 COLLATE "zh_CN",uca DESC,name;
Result:
With PostgreSQL, no matter which collation one chooses, one does not get a linguistic standard ordering. Here is a typical result:
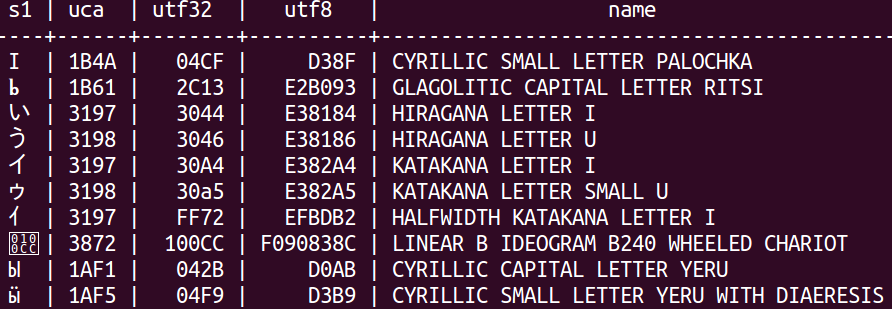
With MySQL, if one enters the same data (albeit in a different way), and chooses collation utf8mb4_unicode_520_ci, one gets a standard result.
Reason:
PostgreSQL depends on the operating system for its collations. In this case my Linux operating system offered me only 5 collations which were really distinct. I did not attempt to customize or add more. I tried all the ones that were supplied, and failed to get a result which would match the Unicode Collation Algorithm order (indicated by the ‘uca’ column in the example). This matters because the standard does ask for a UNICODE collation “in which the ordering is determined by applying the Unicode Collation Algorithm with the Default Unicode Collation Element Table [DUCET]”. MySQL is a cross-platform DBMS and does not depend on the operating system for its collations. So, out of the box and for all platform versions, it has about 25 distinct collations for 4-byte UTF8. One of them is based on the DUCET for Unicode 5.2.
MySQL’s character set and collation support is excellent in some other respects, but I’ll put off the paeans for another post. Here I’ve just addressed a standard matter.
Views
Example:
CREATE TABLE t (s1 INT); CREATE VIEW v AS SELECT * FROM t WHERE s1 < 5 WITH CHECK OPTION;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
MySQL has some support for core standard feature F311-04 “Create view: with check option”. PostgreSQL does not.
Transactions
Example:
START TRANSACTION; CREATE TABLE t (s1 SMALLINT); INSERT INTO t VALUES (1); INSERT INTO t VALUES (32768); /* This causes an error. */ COMMIT; SELECT * FROM t;
Result:
MySQL finds a row containing 1. PostgreSQL finds nothing.
Reason:
PostgreSQL rolls back the entire transaction when it encounters a syntax error. MySQL only cancels the statement.
Now, PostgreSQL is within its rights — the standard says that an implementor may do an “implicit rollback” for an error. But that is a provision for what a DBMS implementor MAY do. From other passages in the standard, it’s apparent that the makers didn’t anticipate that a DBMS would ALWAYS do it, even for syntax errors. (For example it says: “exception conditions for transaction rollback have precedence over exception conditions for statement failure”.) Even Microsoft SQL Server, in its optional “abort-transaction-on-error” mode, doesn’t abort for syntax errors. So MySQL appears to be nearer the spirit of the standard as generally understood.
Example:
CREATE TABLE t (s1 INT); INSERT INTO t VALUES (1); COMMIT; START TRANSACTION; SELECT CURRENT_TIMESTAMP FROM t; /* Pause 1 second. */ SELECT CURRENT_TIMESTAMP FROM t;
Result: PostgreSQL shows the same timestamp twice. MySQL shows two different timestamps.
Reason:
PostgreSQL keeps the same time throughout a transaction; MySQL keeps the same time throughout a statement.
The key sentences in the standard say that the result of a datetime value function should be the time when the function is evaluated, and “The time of evaluation of a datetime value function during the execution of S and its activated triggers is implementation-dependent.” In other words, it’s supposed to occur during the execution of S, which stands for Statement. Of course, this leads to arguable matters, for example what if the statement is in a function that’s invoked from another statement, or what if the statement is within a compound statement (BEGIN/END block)? But we don’t have to answer those questions here. We just have to observe that, for the example given here, the DBMS should show two different timestamps. For documentation of how DB2 follows this, see ibm.com.
Stored Procedures, Functions, Triggers, Prepared Statements
Example:
CREATE FUNCTION f () RETURNS INT RETURN 1;
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support any functions, stored procedures, or triggers with standard syntax.
Instead PostgreSQL supports Oracle syntax. This is not as bad it sounds — the Oracle syntax is so popular that even DB2 also has decided to support it, optionally.
Example:
PREPARE stmt1 FROM 'SELECT 5 FROM t';
Result:
PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL doesn’t support the standard syntax for PREPARE.
Data Types
Example:
CREATE TABLE t (s1 CHAR(1)); INSERT INTO t VALUES (U&'\+000000');
Result:
PostgreSQL returns an error. MySQL succeeds, although MySQL has to use a different non-standard syntax.
Reason:
PostgreSQL has an aversion to CHR(0) the NUL character.(“The character with the code zero cannot be in a string constant.”). Other DBMSs allow all characters in the chosen character set. In this case, the default character set is in use, so all Unicode characters should be okay.
Example:
CREATE TABLE t (s1 BINARY(1), s2 VARBINARY(2), s3 BLOB);
Result: PostgreSQL returns an error. MySQL succeeds.
Reason:
PostgreSQL does not support BINARY or VARBINARY or BLOB. It has equivalent non-standard data types.
The Devil Can Cite Scripture For His Purpose
I could easily find examples going the other way, if I wrote a blog post titled “Sometimes PostgreSQL is more standards-compliant than MySQL”. But can one generalize from such examples?
The PostgreSQL folks boldly go to conclusion mode:
As a quick summary, MySQL is the “easy-to-use, web developer” database, and PostgreSQL is the “feature-rich, standards-compliant” database.
Follow I do not dare.
How to pronounce SQL
In the thirty-second minute of a YouTube video featuring Oracle CEO Larry Ellison you can hear him say clearly “we compete against Microsoft SQL Server … we never compete against MySQL”.
The important thing is that he says “Microsoft SEQUEL Server” the way Microsoft people say it, but he says “My-ESS-CUE-ELL” the way the MySQL Reference Manual says is “official” pronunciation (for English). That is, for product names Mr Ellison respects the way the product makers say it. That settles that, but what about the word SQL in general?
Although SEQUEL was the earlier name, there are no English words where the letter Q alone is pronounced KW. So this can’t be settled with logic. Let’s try appealing to authority.
I looked for the way that other prominent database people said it, or the way they wrote it — if they wrote “an SQL” then the pronunciation must be “Ess-Cue-Ell”; if they wrote “a SQL” then the pronunciation must be “Sequel”.
The results were:
| Authority | Prefers | Source |
|---|---|---|
| Joe Celko | Both | YouTube |
| Don Chamberlin | Ess-Cue-Ell | Book Excerpt |
| C.J.Date | Sequel | “A guide to the SQL Standard” (1987), p. 10, p. 32 |
| David DeWitt | Sequel | YouTube |
| Steven Feuerstein | both | YouTube |
| Bill Gates | Both | YouTube |
| Jim Gray | Sequel | Podcast |
| Joseph M. Hellerstein | Both | Podcast |
| Jim Melton | Ess-Cue-Ell | Podcast |
| Curt Monash | Sequel | Article |
| Shamkant Navathe | Ess-Cue-Ell | “Fundamentals of Database Systems” with Ramez Elmasri (3rd edition) p. 207 |
| Patricia Selinger | Sequel | YouTube |
| Jim Starkey | Sequel | Blog comment |
| Michael Stonebraker | Sequel | YouTube |
| Jennifer Widom | Sequel | YouTube |
… Then I checked vendor documentation. All manuals are inconsistent so this is based on which choice is most frequent.
| Authority | Prefers | Source |
|---|---|---|
| Firebird | Ess-Cue-Ell | firebirdsql.org |
| IBM | Ess-Cue-Ell | publib.boulder.ibm.com |
| MariaDB | Ess-Cue-Ell | askmonty.org/v |
| Microsoft | Sequel | technet.microsoft.com |
| MySQL | Ess-Cue-Ell | mysql.com/doc |
| Oracle | Sequel | docs.oracle.com |
| PostgreSQL | Ess-Cue-Ell | www.postgresql.org/about/press/faq |
As for NoSQL: Dwight Merriman (the chairman of MongoDB Inc.) says No-Sequel, and Martin Fowler (the co-author of NoSQL Distilled) says No-Sequel, but there’s an IBM tutorial that says No-Ess-Cue-Ell.
… Finally I looked again at my beloved “Standard” document.
| Authority | Prefers | Source |
|---|---|---|
| The Standard | Ess-Cue-Ell | jtc1sc32.org |
… And what I did not do is count Google hits. I know “Sequel” would win big if it was a hoi polloi decision, but this is a technical term. Many people pronounce Uranus in a way that astronomers dislike; many people say Brontosaurus although paleontologists say Apatosaurus — but if you were in astronomy or paleontology you’d have to go with what the experts say. Majority opinion is only decisive for ordinary language.
In the end, then, it’s “when in Rome do as the Romans do”. In Microsoft or Oracle contexts one should, like Mr Ellison, respect Microsoft’s or Oracle’s way of speaking. But here in open-source-DBMS-land the preference is to follow the standard.
So the name of this blog is Ess-cue-ell and its Sequels.