SQL:2023 is now the official SQL standard. I’ll compare some of the new optional features with what MySQL and MariaDB support already, and say whether I judge they are compliant.
At the moment I don’t have draft documents (my membership on the standard committee ended long ago), so I gratefully get my news from Oracle and Peter Eisentraut. It’s early days, I may be making mistakes and may be guessing wrong about what new features are important.
Judgment: compliant with SQL:2023 optional feature T055.
The third argument is optional and default is the space character. For some reason I’m not seeing the documentation in the manuals, but it is standard behaviour.
Judgment: not compliant with SQL:2023 optional feature T056.
Although SQL:2023 now has LTRIM and RTRIM, they are two-argument, perhaps a bit like Oracle.
Also SQL:2023 has BTRIM for trimming from both ends. Although MySQL and MariaDB have TRIM(BOTH …), it’s not quite the same thing.
VARCHAR instead of VARCHAR(length)
MySQL and MariaDB example:
CREATE TABLE t(s1 VARCHAR(1)); -- (length) is mandatory
Judgment: not compliant with SQL:2023 optional feature T081
A DBMS that supports feature T081 doesn’t have to include a maximum length, it’s up to the implementation, which in this situation could be 65535 bytes. This is unfortunate and it might be my fault, I think I used to insist that length should be mandatory in MySQL.
Although I can use the TEXT data type instead for indefinite-length strings, it has different characteristics.
ANY_VALUE, emphasizing use with GROUP BY
MySQL and MariaDB example:
SELECT s1, s2 FROM t GROUP BY s1;
Judgment: compliant with SQL:2023 optional feature T626, almost, alas
Probably you noticed that s2 is not in the GROUP BY clause, and yet the syntax is legal — any of the original t values could appear.
The standard would yield something similar with different syntax: SELECT s1, ANY_VALUE(s2) FROM t GROUP BY s1;
Or, as Oracle describes it, “[ANY_VALUE] eliminates the necessity to specify every column as part of the GROUP BY clause”.
That means it’s non-deterministic. Usually I’ve cared more about non-standardness. But now that argument is weaker.
ORDER BY, emphasizing use with GROUP BY
MySQL and MariaDB example:
CREATE TABLE t (s1 int, s2 int, UNIQUE (s2));
INSERT INTO t VALUES (1,1),(7,2),(5,3);
SELECT s1 FROM t GROUP BY s1 ORDER BY s2;
Judgment: not compliant with SQL:2023 optional feature F868.
I’m probably misunderstanding something here about the intent, but the effect is that something that’s not in the GROUP BY clause can determine the ordering. In this case, because column s3 is unique, it’s maybe not utterly absurd. But in MySQL and MariaDB, the result is not guaranteed to be in order by column s3.
GREATEST and LEAST
MySQL and MariaDB syntax:
SELECT GREATEST(2,1,3); -- result = 3
SELECT LEAST(2,1,3); -- result = 1
Judgment: compliant with SQL:2023 optional feature T054
UNIQUE NULLS DISTINCT
MySQL and MariaDB example:
CREATE TABLE t (s1 INT, UNIQUE(s1));
INSERT INTO t VALUES (NULL),(NULL);
Judgment: partly compliant with SQL:2023 feature F292 unique null treatment
To understand this, your required reading is my old blog post NULL and UNIQUE. You have to read the whole thing to understand that the standard document was not contradictory, and that MySQL and MariaDB have always been compliant, because … In a UNIQUE column, you can insert NULLs multiple times.
However, because lots of people never understood, there are implementations where you cannot do so. Therefore feature F292 allows new syntax:
CREATE TABLE t (s1 INT, UNIQUE NULLS DISTINCT (s1));
or
CREATE TABLE t (s1 INT, UNIQUE NULLS NOT DISTINCT (s1));
MySQL and MariaDB could easily half-comply by allowing the first option and saying it is the default. (The standard now says the default is implementation-defined.) (A backward step.)
Hexadecimal and octal and binary integer literals
MySQL and MariaDB example:
SELECT 0x4141;
Judgment: not compliant with SQL:2023 optional feature T661
Did you notice that I said “integer literals”? That’s what’s wrong, 0x4141 in standard SQL is now supposed to be an integer, decimal 16705. But MySQL and MariaDB will treat it as a string, ‘AA’.
It is always legal for an implementation to have “non-conforming” syntax that causes “implementation-dependent” results. That’s what happened with 0x4141, in the mists of time. But now, if one decides to “conform” with the syntax of this optional feature, one must change the behaviour drastically: not merely a different value but a different data type.
I suppose that the road to compliance would involve deprecations, warnings, sql_mode changes, etc., lasting years.
Underscore digit separators
MySQL and MariaDB example:
CREATE TABLE t (10_000_000 INT);
INSERT INTO t VALUES (1);
SELECT 10_000_000;
Judgment: not compliant with SQL:2023 optional feature T662 Underscores in numeric literals
Big numbers like 10,000,000 cannot be expressed in SQL using commas because that looks like three separate values. The solution, which I see was implemented a few years ago in Python, is to express 10,000,000 as 10_000_000 — that is, underscores instead of commas.
In standard SQL, an identifier cannot begin with a digit. But in MySQL and MariaDB, it can, so 10_000_000 is a legal regular identifier. This is another example of an extension that causes trouble in a long term.
There is an idiom about this, usually about chickens: “come home to roost”. As Cambridge Dictionary puts it: “If a past action, mistake, etc. comes home to roost, it causes problems at a later date, especially when this is expected or seems deserved …”
JSON
MariaDB example:
CREATE TABLE t (s1 JSON);
Judgment: partial compliance with SQL:2023 feature T801 JSON data type etc.
I’m not going to try to analyze all the new JSON options because it’s a big subject. Also there’s a CYCLE clause and a new section of the standard, part 16 Property Graph Queries (SQL/PGQ), which I don’t think is appropriate to get into during this comparison of features in the foundation. Maybe some other time.
Score
Actually, despite pointing to some non-compliance, I have to give credit to the people who decided to implement some features long before they became standard. (And I don’t credit myself at all because they appeared before I was a MySQL architect, and in fact I objected to some of them while I was with MySQL AB.)
Well done.
ocelotgui news
The new version of the Ocelot GUI application, ocelotgui, is 2.0. As always the source and executable files are on github. The biggest new feature is charts. I’ll say more in a later blog post.
Update added 2023-06-12: Re ANY_VALUE: see comment by Øystein Grøvlen. As for the question from Federico Razzoli, I cannot give an authoritative answer. Also I’ve been reminded that MariaDB request MDEV-10426 regarding ANY_VALUE is marked as part of MariaDB 11.2 flow, but until then I guess MySQL is a bit ahead.
In the SQL standard delimiters are for separating tokens; in MySQL/MariaDB they’re for ending statements, particularly compound statements as in
CREATE PROCEDURE p()
BEGIN
VALUES (5);
END;
The problem is that a dumb client could stop at the first semicolon “;” in the statement (the one after VALUES (5)) instead of the one that truly ends (the one after END). The solution is to say that semicolon is no longer the default delimiter, and the way to specify a replacement is with a non-standard DELIMITER statement, such as
DELIMITER //
and after that the true statement end is //.
The idea isn’t unusual — in PostgreSQL’s psql client you can enclose compound statements with $$ which they call dollar quoting, with Microsoft you get used to saying “go” when you want something shipped to the server, with Oracle you might sometimes see SQLTERMINATOR. But it shouldn’t always be necessary — despite the fact that words like BEGIN are not reserved, a client with even a slight ability to recognize syntax can see where a compound statement ends without needing special tags.
Quirks
Some DELIMITER quirks are documented in either the MySQL manual or MariaDB manual, some are common to all mysql-client commands, but all are weird. They are: () DELIMITER itself is not delimited () After DELIMITER A B the delimiter is A () After DELIMITER A; the delimiter is A; () After DELIMITER 12345678901234567890 the delimiter is 123456789012345 () After DELIMITER ‘x’ or DELIMITER “x” or DELIMITER `x` the delimiter is x () After DELIMITER ;; the delimiter is ;; () Delimiters inside comments or character string literals or delimited identifiers are ignored () After \dA the delimiter is A (\d is a substitute for DELIMITER and no space is necessary) () After DELIMITER \ the effect can be odd, the MySQL manual recommends not to use \ () SELECT 5; DELIMITER ; will cause an error message () DELIMITER ;; followed by SELECT 5;;; has a different effect from DELIMITER // followed by SELECT 5;// () \G and \g will work whether or not there is a delimiter
It is not a gotcha that, when statements are in a .sql file and read by the SOURCE file-name statement, the rules are different: Compound statements will be recognized without special delimiters, and semicolons will always end non-compound statements even after a different delimiter has been specified.
It is not a quirk or a gotcha, it’s merely bad design, that DELIMITER forces the fundamental requirement of a parser — the tokenizer — to change what the tokenizing rules are while the tokenizing is going on.
Best practice
Both the MySQL and the MariaDB manual have example statements where the delimiter is // and that’s unlikely to cause confusion, since the only other uses of / are as a beginning of a bracketed comment or as a division operator, or in arguments to PROMPT or SOURCE or TEE. Less frequently there is a recommendation for $$ but that is bad because $$ can occur inside regular identifiers. DELIMITER !! is equally bad because !, unlike /, is a repeatable operator, for example SELECT !!5; returns 1. DELIMITER ;; is worse and has caused bugs in the past, but the mysqldump utility will generate it before CREATE TRIGGER statements.
Avoid non-printable or non-ASCII characters, some clients will support them but others won’t.
You could set a delimiter at the start of a session and let it persist. But I believe the more common practice is to put DELIMITER [something appropriate] immediately before any CREATE PROCEDURE or CREATE TRIGGER or CREATE FUNCTION or BEGIN NOT ATOMIC statement, and DELIMITER ; immediately after. This might help readability by humans since otherwise they’d look at statements that end with mere semicolons and assume they’d go to the server immediately, not realizing that long ago there was a DELIMITER statement.
The ocelotgui client doesn’t need DELIMITER statements because obviously a client that includes a stored-procedure debugger can recognize compound statements, but it will accept them because it tries to be compatible with the mysql client. It does not duplicate mysql client behaviour for the SOURCE statement but that should be fixed in the next version, and the fix is now in the source code which can be downloaded from github.
It’s pleasant to admire drawings of database tables and their foreign-key relationships, which are
“data structure diagrams”
or more grandiosely
“entity relationship (ER) diagrams”.
I’ll show what the esthetic considerations are i.e. “does this look nice”,
and what the engineering considerations are i.e. “what do I have to do to make it at all”.
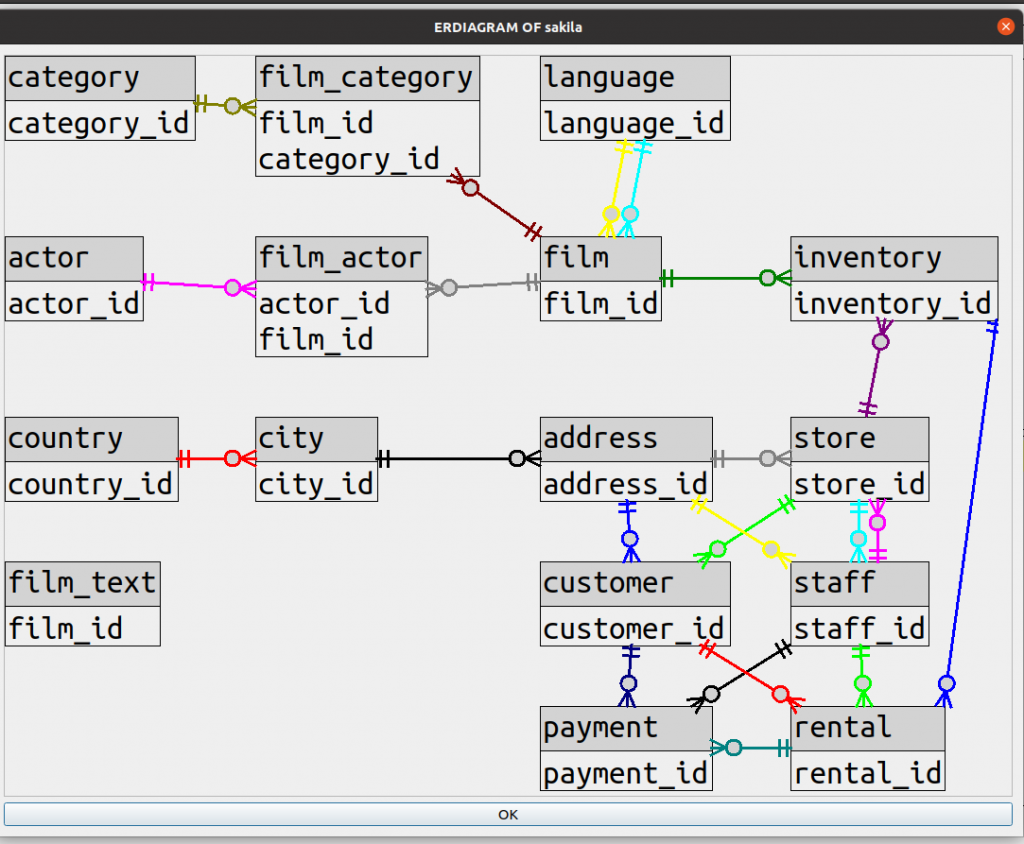
I’ll begin with the conclusion — here is a drawing of the well-known sakila database.
To find diagrams that other products draw for the same database, just google “sakila er diagram”.
You’ll see something like this:
and what I’m trying to address first is: who’s the fairest?
Crossings when two lines intersect or nearly intersect.
Edge non-orthogonality when lines are not all horizontal or vertical with right angles.
Node non-orthogonality when tables are not in a fixed rank-and-file grid.
Inconsistent line lengths when some of a table’s relationships are short and others are long.
Although a computer program may not be great as a beauty contest judge,
it can simply count bends and crossings, assign numeric weights to them,
and come up with a negative score. Then picking for display a drawing with the best score can be
achieved with brute-force comparisons or with functions that are slightly more sophisticated
but enormously harder to write.
Bends
Unlike what happens in most of the google-result diagrams I mentioned above, I just declare
“there are no bends”. All lines are straight, with many more angles than 90-degree up/down/left/right.
For example this is a table that had foreign-key relationships with 8 other tables.
Bend count: zero.
Let’s admit the downsides too:
(a) The original idea of structure diagrams was that lines could be done with as few as four ASCII characters
– | > <
and so were easy to reproduce. Drawing angles is perhaps technically possible with
ASCII art
but would need more screen space.
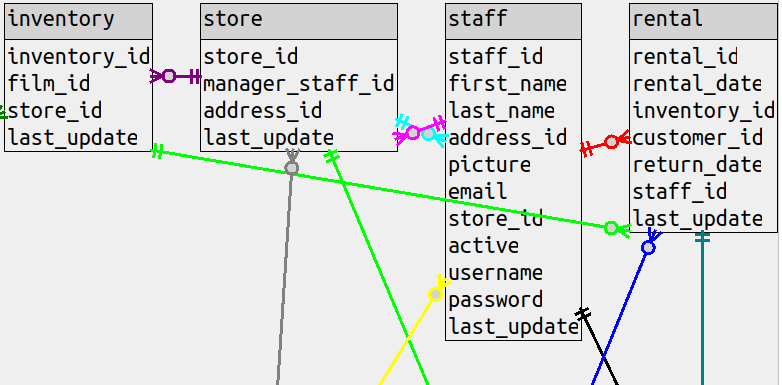
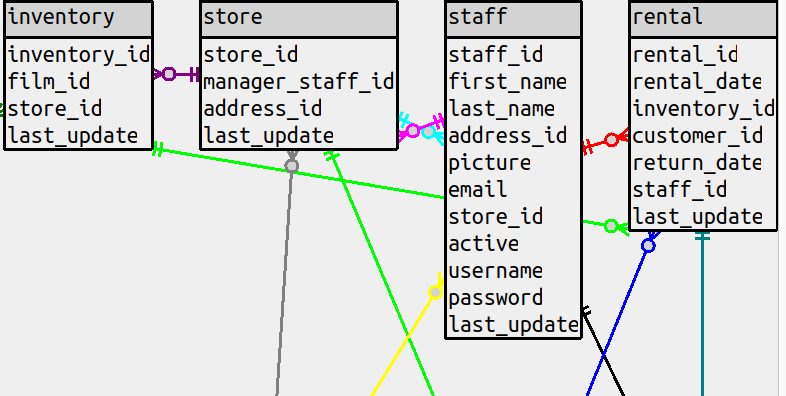
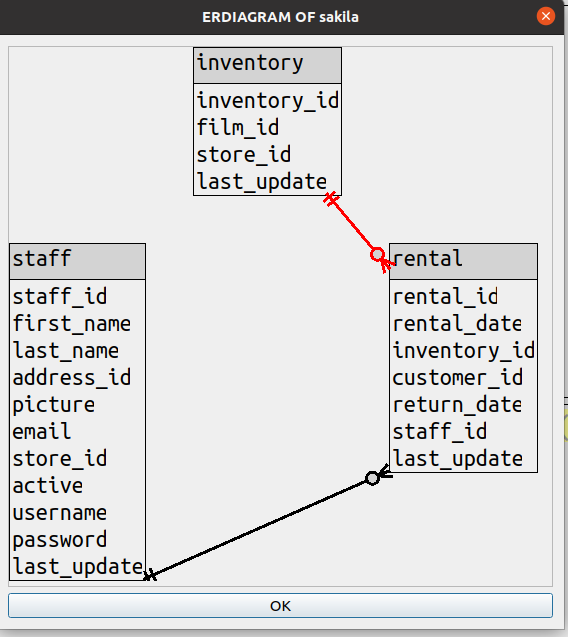
(b) In the situations where the classic style would bend around, the straight-line style will draw right through
a table. This can be illustrated with a sakila diagram that has all the columns, and the line between
rental and inventory goes right over the staff table.
There’s an option to put the line in the background instead
but either way, there’s an esthetic problem which should be weighted the same as a count of bends, or higher.
(c) we can’t put labels on any non-horizontal lines, so the only way to know the foreign-key constraint is to
hover over the line and wait for a tooltip to appear.
Crossings
Unlike the monochrome google-result diagrams I mentioned above, I just declare
“different lines have different colours”. This has limited possibilities since
the palette has to consist of only colours that are easily distinguishable and
are not similar to the background colour, which would have a camouflage effect.
So the practical limit is about a dozen colours.
However, usually, when two lines are close or intersecting it’s easy to distinguish them.
Let’s admit the downside here too:
(a) this doesn’t reduce the number of crossings, it just patches over the problem
(b) it’s a matter of chance whether a bunch of colours is esthetic or not.
Edge non-orthogonality
The algorithm produces straight lines and almost no right angles so it is
almost always edge non-orthogonal.
As the Radboud University thesis
says, edge non-orthogonality is considered a negative.
But the thesis also
admits that there are unnecessary bends otherwise.
I’m giving bends more weight.
I see in other products that edge orthogonality has more weight.
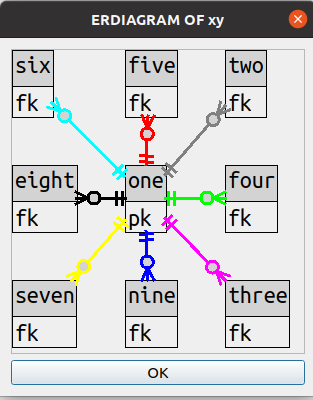
Node non-orthogonality
The algorithm places high weight on node orthogonality and one result is that
tables are in fixed ranks and files, always.
Again, this is unlike what I see in other products. I suppose that their criterion is compactness:
if there are fewer spaces between tables, then there is less scrolling necessary to see the whole
picture. So this is another case of a beautification with a downside, but I insist on it because
of another consideration: specifiability.
Users will sometimes want to specify, instead of “ERDIAGRAM OF whole_schema”,
“ERDIAGRAM OF schema TABLES (table-list)”. Once we allow that much, it’s reasonably simple
to allow for users to say which tables should go in which fixed positions. For example,
consider this specification
SHOW ERDIAGRAM OF sakila TABLES (staff 0 1, inventory 1 0, rental 2 1)
which results in this
Users can figure out graphic coordinates such as 0 1 “position 0 on the X axis position 1 on the Y axis”.
They would be , however, if the coordinates had to be pixel positions instead.
Having straight ranks and files makes it possible to specify with small integers.
By the way, the automatic production of drawings based on databases is sometimes called
“reverse engineering”. So I suppose the appropriate term for specifying a diagram like this
is “forward engineering”, but the real engineering job is of course the CREATE TABLE statements.
Positioning
Suppose we have three tables A B C, and A references C, well
then we wouldn’t want to draw B between A and C, we’d want the diagram to look like A C B.
In other words, if we could just get related tables to be drawn close to each other with no intervening tables,
we’d have no bends. For a tiny number of tables this is easy to see and to fix.
But as the number of tables grows the possible number of possible table positions in the drawing
grows geometrically, like a
travelling salesman problem.
So positioning is far more difficult than bend denialism or crossings anti-camouflage.
The Radboud University thesis mentions a tried-and-mathematically-solid way to get the fewest bends
with a large number of related tables. I saw it too late, though, so the method I implemented might
be inferior.
Also I might have saved time by bringing in the
Open Graph Drawing Algorithm
library, but didn’t.
The method is like crystal formation.
Start by drawing the table A that has the most relationships, either referencing-from or referenced-to.
Then, for each table that A is related to, draw nearby (as closely as possible without interfering
with other tables) the related tables … starting with the table B which is related to A which
has the most relationships, and so on until there are no more.
This involves a lot of recursion.
The initial result of a crystal formation is sometimes pretty good, and then there are last-microsecond patchups
that can enhance it. Look for pairs of tables that are not near each other and
see whether, if they were exchanged with each other or if one of them was moved close to the other,
the total bend count for the table would go down. This usually helps just a little bit and adds
more than a little bit to the computer time, so it can only go on for a limited number of looks.
Touchup
So much for the esthetics that are specifically for ER diagrams. I suppose I should add that there
have to be further esthetic features that apply to widgets in general.
The diagram must be changeable with respect to fonts, header and detail
background colours, and line widths.
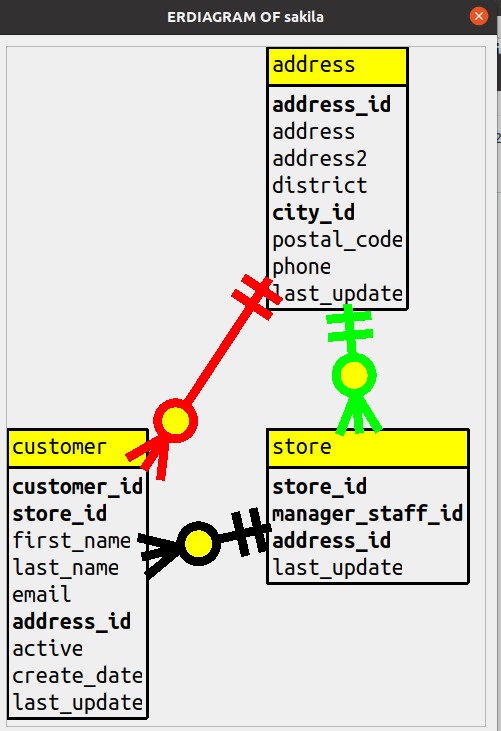
For example, for this diagram of a limited number of tables in sakila
I specified that column names ending with _id should be in bold, the lines should be extra wide,
and header background should be yellow.
(One thing users can’t change is the way that an arrow looks, the so-called
Crow’s foot.
At least one other product offers choices for this.)
I imagine that other high-class GUI clients can do such touchups so this is nothing special,
but in a post about esthetics I figure I ought to mention this final step.
But where’s the SQL?
In this case the SQL statements are the easy part, especially if the DBMS supports SQL-standard INFORMATION_SCHEMA access.
All the necessary information about foreign-key relationships can be picked up with
SELECT … FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE WHERE …
There’s a quirk that is non-standard: your favourite DBMS insists that primary-key constraints must be
named PRIMARY, so KEY_COLUMN_USAGE has all we need for deciding which columns are part of the a primary key,
as well as which columns are part of a foreign key.
And if the user specifies that the drawing should have all columns instead of just primary-key columns,
SELECT … FROM INFORMATION_SCHEMA.COLUMNS WHERE …
does the job.
However, I don’t think it’s a good idea for the program to do those SELECTS every time the user asks for
a drawing. They’re expensive on the server. (Rule: taking time on a client computer is trivial, taking
time on the server might not be.) So this is done as part of an “explorer”, which means the user can slowly slowly
pick up all the table and column and relationship information at once, so it’s stored in the local computer’s
memory, and subsequent requests to draw don’t affect the server at all unless the user decides to refresh
potentially-obsolete information.
ocelotgui
The feature I’ve just described comes with ocelotgui 1.9 which is available for download on
github.
That is, for table T2, I show the table name and foreign-key name and referenced-table name, then the columns of that table in the order they appear in the foreign key, then if there is another foreign key repeat after a blank line.
Here is a long but simple stored procedure that produces such a display.
DROP PROCEDURE show_fk;
CREATE PROCEDURE show_fk(ref_table_name VARCHAR(128))
BEGIN
DECLARE d_table_name VARCHAR(128);
DECLARE d_column_name VARCHAR(128);
DECLARE d_ordinal_position INT;
DECLARE d_constraint_name VARCHAR(128);
DECLARE d_referenced_table_name VARCHAR(128);
DECLARE d_referenced_column_name VARCHAR(128);
DECLARE counter INT DEFAULT 0;
DECLARE err INT DEFAULT 0;
DECLARE x CURSOR FOR
SELECT table_name, column_name, ordinal_position,
constraint_name,
referenced_table_name, referenced_column_name
FROM information_schema.key_column_usage
WHERE table_name = ref_table_name AND referenced_column_name IS NOT NULL
ORDER BY constraint_name, ordinal_position;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET err = 1;
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION set err = 1;
CREATE TEMPORARY TABLE fks (referencing VARCHAR(128),
constraint_name VARCHAR(128),
referenced VARCHAR(128));
OPEN x;
WHILE err = 0 DO
FETCH x INTO d_table_name,d_column_name, d_ordinal_position,
d_constraint_name,
d_referenced_table_name, d_referenced_column_name;
IF err = 0 THEN
IF counter <> 0 AND d_ordinal_position = 1 THEN
INSERT INTO fks VALUES ('', '', '');
END IF;
IF d_ordinal_position = 1 THEN
INSERT INTO fks VALUES (d_table_name, d_constraint_name, d_referenced_table_name);
END IF;
INSERT INTO fks VALUES (d_column_name, '', d_referenced_column_name);
SET counter = counter + 1;
END IF;
END WHILE;
CLOSE x;
SELECT * FROM fks;
DROP TABLE fks;
END;
CALL show_fk('t2');
This is vaguely like an entity-relationship diagram, but with tables rather than pictures.
The flaws are: (1) it needs extra privileges, (2) it mixes different object types. So let’s look at the simpler and more common type of display.
The usual
Everything necessary can come from information_schema.key_column_usage.
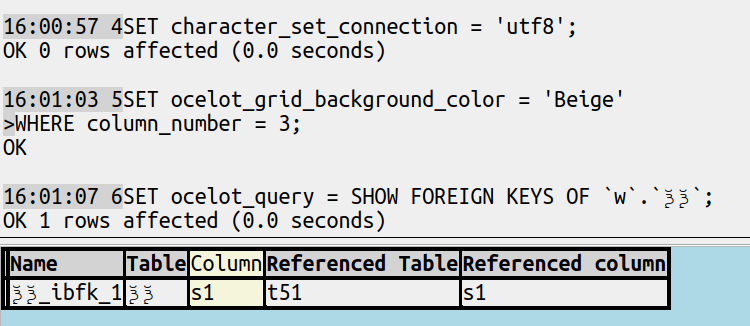
For example, there’s a GUI that displays with these columns:
SELECT constraint_name AS `Name`,
table_schema AS `Schema`,
table_name AS `Table`,
column_name AS `Column`,
referenced_table_schema AS `Referenced Schema`,
referenced_table_name AS `Referenced Table`,
referenced_column_name AS `Referenced Column`
FROM information_schema.key_column_usage
WHERE referenced_column_name IS NOT NULL
ORDER BY constraint_name, ordinal_position;
Or if that takes too long to type, make a view.
There’s another GUI that displays with these columns:
Key name | Columns | Reference Table | Foreign Columns | On UPDATE | On DELETE
(The “On UPDATE” and “On DELETE” values would have to come from information_schema.referential_constraints.)
The objection that I’d make is that such headers are not standard. So anybody who knows the actual column names has to do a double take, wondering whether the first column is the same as “constraint_name” or something exotic, and so on. Use of multiple different names for the same thing is poetry not programming.
The new
So I think this display, which admittedly makes cosmetic changes (replacing ‘_’ with ‘ ‘ and changing upper case to mixed case and emphasizing one column) is better:
I’ve made it so that can come from user statements or from the explorer. The source code is downloadable now and the released executables will come soon.
A new feature in MariaDB 10.6 is “Implement SQL-standard SELECT … OFFSET … FETCH”.
I’ll say what’s not in the manual: mention other vendors, add details, talk style, show how to get the wrong answer, describe WITH TIES, mention alternatives, experiment with locks, and list 11 minor flaws.
This isn’t a complete list — there are lots of SQL products nowadays — but it does include the “Big Three”. All of them support SELECT … OFFSET … FETCH.
Syntax details
The BNF actually is:
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES } ]
The “start” and count” must be unsigned integers if they’re literals, but if they’re declared variables then they can be NULL (in which case they’re treated as zeros), or can be negative (in which case they’re treated as -infinity for “start” and +infinity for “count”) (but depending on undefined behaviour isn’t always fun).
The lowest offset is zero which is the first row, and the lowest count is zero, that is, it is possible to select zero rows. If count is omitted, then 1 is assumed.
Style
If you haven’t read the descriptive SQL style guide and clicked like, then you won’t understand this section, skip it.
OFFSET and FETCH are both either “clause starts” or “sub-clause starts” so if the choice is to put separate clauses on separate lines, then they are.
Deciding whether to use ROW rather than ROWS, or FIRST rather than NEXT, (neither of which make a difference for server behaviour), one could base a rule on English grammar: (1) If there was an OFFSET clause with a non-zero number-of-rows, then NEXT, else FIRST. If number-of-rows is greater than one, or unknown, then ROWS, else ROW. or one could base a rule on what comes first in the MariaDB manual BNF: (2) The BNF has {FIRST|NEXT} and {ROW|ROWS} so FIRST and ROW. or one could base a rule on what the examples in the manual use most often: (3) FIRST and ROWS or one could base a rule on whatever is shortest: (4) NEXT and ROW.
I like (3), for example
OFFSET 5 ROWS
FETCH FIRST 1 ROWS ONLY;
but there’s no established rule yet so I’ll vary the format in what follows.
How to get the wrong answer
Try this:
CREATE TABLE td (char_1_column CHAR(1) DEFAULT '1',
null_column INT,
char_2_column CHAR(2));
CREATE INDEX int_char_1_column_plus_char_2_column
ON td (char_1_column, char_2_column);
INSERT INTO td (char_2_column)
VALUES ('a'),('b'),('c'),('d'),('e'),('ab');
SELECT char_2_column, null_column
FROM td
WHERE char_1_column > '0'
OFFSET 0 ROWS
FETCH FIRST 4 ROWS ONLY;
SELECT char_2_column, null_column
FROM td WHERE char_1_column > '0'
OFFSET 4 ROWS
FETCH FIRST 4 ROWS ONLY;
Result of first SELECT: (‘a’,NULL),(‘ab’,NULL),(‘b’,NULL),(‘c’,NULL)
Result of second SELECT: (‘e’,NULL),(‘ab’,NULL)
So there’s no (‘d’,NULL) and there’s a duplicate (‘ab’,NULL). Wrong answer.
I don’t think it’s a bug because, in the absence of an ORDER BY statement, there is no guarantee which rows will be skipped in the second SELECT. But luckily it’s due to an exotic situation which is easy to avoid: the combined index on a non-unique column and a multi-character string column. Just don’t use the index, and all is well.
WITH TIES
The effects of the new syntax are mostly the same as with LIMIT … OFFSET, but WITH TIES is new.
Suppose there are 6 rows, selected in order (there must be an ORDER BY clause): (NULL),(NULL),(1),(1),(2),(2). Then OFFSET 0 ROWS FETCH NEXT 1 ROWS WITH TIES will gives us (NULL),(NULL). Thus WITH TIES doesn’t mean that the two values are technically “equal”, they merely must be peers, so NULLS tie. The interesting thing is that when you ask for “NEXT 1 ROW” you get the next 2 rows. But that only applies to FETCH, it doesn’t apply to OFFSET, therefore this could be a mistake:
SELECT * FROM t
ORDER BY pk
OFFSET 0 ROWS
FETCH NEXT 1 ROWS WITH TIES;
SELECT * FROM t
ORDER BY pk
OFFSET 1 ROWS
FETCH NEXT 1 ROWS WITH TIES;
With the example 6 rows, the second SELECT will return a row that was already returned for the first SELECT. It would be better to say, instead of “OFFSET 1 ROWS”, “OFFSET (number of rows returned by the previous SELECT) ROWS”.
Alternatives
A standard way to fetch only one row:
BEGIN NOT ATOMIC
DECLARE v INT;
DECLARE c CURSOR FOR SELECT * FROM t;
OPEN c;
FETCH NEXT FROM c INTO v;
END;
A non-standard way to fetch only one row: (remember to restore @@sql_select_limit later):
SET sql_select_limit = 1;
SELECT * FROM t;
A way to offset by 10 and fetch 10 (this assumes that pk has all the integers in this range i.e. it depends on user knowing about contents and indexes, and assumes that user only wants to go forward without skipping)
SELECT * FROM t
WHERE pk > 10 AND pk <= 10 + 10;
A way to let the user do the offsets and fetches (this depends on the client being a GUI and the user knowing how to click on a scroll bar)
SELECT * FROM t;
… although users often only look at the first few pages (think of how often you use Google and only click Next a few dozen times).
Locking
Will locking, or SET TRANSACTION ISOLATION LEVEL, guarantee consistency?
For a test, I started two clients. On the first, I said:
CREATE TABLE pks (pk INT PRIMARY KEY);
BEGIN NOT ATOMIC
DECLARE v INT DEFAULT 0;
WHILE v <= 10000 DO
INSERT INTO pks VALUES (v);
SET v = v + 1;
END WHILE;
END;
SET @@autocommit=0;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION;
SELECT * FROM pks
WHERE pk > 400
OFFSET 10 ROWS
FETCH FIRST 2 ROWS ONLY FOR UPDATE;
On the second, I said:
SET @@autocommit=0;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
START TRANSACTION;
DELETE FROM pks WHERE pk = 7227;
DELETE FROM pks WHERE pk = 405;
DELETE FROM pks WHERE pk = 411;
Result: The first DELETE succeeds, the second DELETE hangs until I say ROLLBACK; on the first client. The third DELETE would also have hung if I had said it first.
In other words: the rows between 401 and 410 (the rows skipped due to OFFSET) are locked, and the rows between 411 and 412 (the rows picked up by FETCH) are locked, but the rows after 412 (the rest of the rows matching WHERE) are not locked.
What this means, of course, is that ordinarily you can’t be certain that you’re paging through a consistent set. If this is a concern (it shouldn’t always be), make a copy on either the server or the client.
Minor Flaws
A few incompatibilities with standard SQL or another DBMS or another bit of MariaDB 10.10 syntax.
Table t has 4 rows created thus:
CREATE TABLE t (s1 INT, s2 INT);
INSERT INTO t VALUES (1,2),(2,1),(3,2),(4,1);
1.
WITH x AS (SELECT * FROM t OFFSET 5 ROWS) SELECT * FROM x;
Result: Success, all 4 rows in table t are returned. It appears that the OFFSET clause is ignored.
2.
BEGIN NOT ATOMIC
DECLARE var1 DECIMAL(0);
SELECT * FROM t OFFSET var1 ROWS;
END;
Result: Error 1691 (HY000) A variable of a non-integer based type in LIMIT clause Never mind whether var1 should be accepted. The error message is obsolete, I was not using a LIMIT clause.
3.
BEGIN NOT ATOMIC
DECLARE var1 BIT DEFAULT NULL;
SELECT * FROM t OFFSET var1 ROWS;
END;
Result: Success, all rows are returned. Sometimes non-integer variables are illegal, but here a BIT variable is legal. MariaDB calls BIT a numeric data type but SELECT * FROM t OFFSET b’1′ ROWS wouldn’t work.
4.
SET sql_mode='oracle';
CREATE PROCEDURE p2 AS
var1 NUMBER := 1;
BEGIN
SELECT * FROM t OFFSET var1 rows;
END;
(Don’t forget to restore sql_mode later.) Result: Error 1691 (HY000) A variable of a non-integer based type in LIMIT clause That’s right for standard SQL (“The declared type … shall be an exact numeric with scale 0”) but Oracle says it might be more forgiving (“If rowcount includes a fraction, then the fractional portion is truncated.”)
5.
SELECT * FROM t
OFFSET 1 ROWS
FETCH FIRST 0 ROWS ONLY;
Result: Success, zero rows are returned. That’s wrong for standard SQL, which would return “data exception — invalid row count in fetch first clause”.
OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }
which might suggest to newbies that the OFFSET clause is compulsory before FETCH.
7.
SET @x = 1;
SELECT * FROM t OFFSET @x ROWS;
Result: Syntax error. I can find, by saying CREATE TABLE .. AS SELECT @x; and then saying SHOW CREATE TABLE or SELECT … FROM INFORMATION_SCHEMA, that @x is BIGINT. BIGINT declared variables are legal, and I can use variables that start with @ in some other situations. This is how things go when variables have variable types.
8.
SHOW WARNINGS OFFSET 1 ROW;
Result: Success. I believe this is reasonable, and of course any non-standard syntax can be handled in an implementor-defined way. But it’s not documented on the documentation page for SHOW WARNINGS.
9.
BEGIN NOT ATOMIC
DECLARE only INT DEFAULT 2e2;
DECLARE row INT DEFAULT (SELECT 5);
SELECT * FROM t OFFSET ROW ROW FETCH FIRST ONLY ROW ONLY;
END;
Result: Success. In standard SQL:2016 ROW and ONLY are reserved words. MariaDB tends to accept goofiness since it’s not your nanny, but I believe in egregious cases the standard strictness is preferable after reasonable notice.
10.
SELECT * FROM t
FETCH FIRST 1 ROWS ONLY ROWS EXAMINED 1;
Result: Error. Another inconsistency, since LIMIT 1 ROWS EXAMINED 1 is legal.
11.
VALUES (1),(2),(3) OFFSET 1 ROW FETCH FIRST ROW ONLY;
Result: Success. This is fine, but once again undocumented.
ocelotgui support
The Ocelot GUI client recognizes MariaDB syntax when connected to a MariaDB server, so if you need features like autocomplete after OFFSET to be correct then download it from github.
A former colleague from my MySQL AB days asked me about SELECT pk, SUM(amount) AS pk FROM t ORDER BY pk; should the duplicate use of the name PK be illegal?
My reply is: A relational-database expert deplores it in the select list; the SQL standard says it’s conceptually illegal in the order-by clause; MySQL and MariaDB handle it in an odd way; the Ocelot GUI for MySQL and MariaDB doesn’t flag it.
A relational-database expert deplores
CJ.Date, in Date On Databases, Writings 2000-2006, has a multi-page section about “Duplicate Column Names”. I’ll just quote the firmest negatives.
… we can avoid the duplicate names if we want to. The problem is, we don’t have to, and SQL does not have to deal with the possibility that a given table might have column names that aren’t unique. As an aside, I should explain that … we don’t have to use the “AS column name” construct is because it wasn’t part of the original standard (it was introduced with SQL:1992), and compatibility therefore dictates that its use has to be optional. (I should also note in passing that — believe it or not — names introduced by AS don’t have to be unique!
*Every SQL table has a left-to-right column ordering *Every column in every named SQL table (i.e. base table or view) has a user-known name, and that name is unique within the table in question. But neither of these properties holds, in general, for unnamed tables (i.e. intermediate and final result tables). … I’d like to point out that duplicate and missing column names both constitute a fairly egregious violation of The Naming Principle
So nothing’s ambiguous about Mr Date’s evaluation, but he is acknowledging that SQL won’t be changing due to compatibility with old standards, and at least it wouldn’t allow duplicate column names in the select list of a CREATE VIEW statement.
The SQL standard says it might be illegal
The standard says this about Concepts:
This Clause describes concepts that are, for the most part, specified precisely in other parts of ISO/IEC 9075. In any case of discrepancy, the specification in the other part is to be presumed correct.
So we usually expect a specific syntax rule, but if it’s missing, we maybe can look at Concepts.
And this is SQL:2016, Foundation, 4.13 Columns, fields, and attributes, in the Concepts section:
Sometimes the Syntax Rules forbid two elements at different ordinal positions from having equivalent names (particularly when created through an SQL schema statement). When two elements with equivalent names are permitted, then the element name is ambiguous and attempts to reference either element by name will raise a syntax error.
That suggests that if pk appears twice in select list then ORDER BY pk; should fail, but it’s not explicitly stated in the Syntax Rules. This in contrast with GROUP BY, which has a clear Syntax Rule, that is, “Each grouping column reference shall unambiguously reference a column of the table resulting from the from clause.” Perhaps when I was on the ANSI committee I should have asked why Syntax Rule for ORDER BY doesn’t also say “unambiguously”, but it’s too late now.
MySQL and MariaDB handle it in an odd way
I tried variations of the syntax with MySQL 8.0.31 and MariaDB 10.10.1, sql_mode=only_full_group_by is not true, sql_mode=ansi_quotes is true. They both return the same results.
CREATE TABLE t (pk INT, amount INT); INSERT INTO t VALUES (1,2), (2,1),(1,2),(2,1); SELECT pk, (amount) AS pk FROM t ORDER BY pk; Result: Error 1052 (23000) Column ‘pk’ in order clause is ambiguous SQLSTATE values starting with 23 are for “integrity constraint violation”, so it would be better to have something starting with 42 (syntax error or access violation), I described good old ’42’ in an earlier blog post. However, the error message is good and consistent with standard SQL.
SELECT pk, SUM(amount) AS pk FROM t ORDER BY pk; Result: 1,6. SELECT pk, 5 AS pk, amount FROM t ORDER BY pk,amount DESC; Result: (1,5,2),(1,5,2),(2,5,1),(2,5,1) SELECT pk, (SELECT SUM(amount) AS pk FROM t) AS "pk" FROM t ORDER BY pk; Result: (1,6),(2,6),(1,6),(2,6) These results are harmless — there’s either an implied grouping or a literal for the main sort, so they’re always the same value, so they can be optimized away. Nevertheless, they’re inconsistent — if “Column ‘pk’ in order clause is ambiguous” is detectable, and it’s a syntax error not a runtime error, it shouldn’t have been ignored.
SELECT pk * - 1 AS pk, pk FROM t ORDER by pk; Result: (-2,2),(-2,2),(-1,1),(-1,1) SELECT pk, pk * - 1 AS pk FROM t ORDER by pk; Result: (2,-2),(2,-2),(1,-1),(1,-1) These results are odd, they show that we’re ordering by the pk that has an AS clause, regardless of which column is first in the select list.
SELECT SUM(amount) AS pk, pk FROM t GROUP BY pk ORDER BY pk; Result: (2,2),(4,1) Also there is a warning: Column ‘pk’ in group statement is ambiguous. But it does succeed, and once again the item with the AS clause is preferred. This syntax is explicitly declared illegal in standard SQL.
SELECT * FROM (SELECT 1 AS a, 1 AS a) AS t1, (SELECT 1 AS a, 1 AS a) AS t2; Result: Error 1060 (42S21) Duplicate column name ‘a’ This is the right result, and the SQLSTATE is better because it starts with ’42’. The reason it’s correct is that Trudy Pelzer long ago reported a bug with duplicate names in subqueries, which are illegal due to a different item in the standard, and Oleksandr Byelkin fixed it.
The Ocelot GUI for MySQL and MariaDB doesn’t flag it
An obvious thought is: since ocelotgui recognizes MySQL/MariaDB syntax, and gives hints or autocompletions while the user is entering a statement, should I be adding code to catch this? After all, we stop most illegal syntax before it goes to the server.
But I’m wary. The behaviour that I describe here is undocumented, so it could change without warning, and besides who are we to reject what the server would accept? It won’t be at the top of the “To Do” pile.
Speaking of “To Do” piles, ocelotgui 1.8 has now been released, and is downloadable from github.
A while ago we got a question about data type conversion and SQLSTATE …
“ Suppose we have data types T1 and T2 (either built-in or user defined).
This pair is not explicitly listed in the Store Assignment rules.
There is no a CREATE CAST for this pair defined.
Reading the standard, I have an impression that these statements should fail:
UPDATE t1 SET T1_col=T2_col; INSERT INTO t1 (T1_col) SELECT T2_col FROM t1; SET T1_var=T2_var; — inside an SP
But I could not find which exactly error should be raised:
what should be SQLSTATE
what should be error message text
A related question: Is it possible to do CREATE CAST for a pair of two built-in data types? “
The answer was …
I will be quoting 9075-1:2011 Framework and 9075-2:2016 Foundation.
Framework says: “In the Syntax Rules, the term shall defines conditions that are required to be true of syntactically conforming SQL language. When such conditions depend on the contents of one or more schemas, they are required to be true just before the actions specified by the General Rules are performed. The treatment of language that does not conform to the SQL Formats and Syntax Rules is implementation-dependent. If any condition required by Syntax Rules is not satisfied when the evaluation of Access or General Rules is attempted and the implementation is neither processing non-conforming SQL language nor processing conforming SQL language in a non-conforming manner, then an exception condition is raised: syntax error or access rule violation.” … Therefore: if you see the word “shall” in a syntax rule, and the condition is not true, it is a syntax error or access violation.
Foundation says: re set clause list: “Otherwise, the Syntax Rules of Subclause 9.2, “Store assignment”, are applied with the column of T identified by the <object column> as TARGET and the <update source> of the <set clause> as VALUE.”
Foundation says: re store assignment: syntax rules: where SD = source data type and TD = target data type: “If TD is character string, binary string, numeric, boolean, datetime, interval, or a user-defined type, then either SD shall be assignable to TD or there shall exist an appropriate user-defined cast function UDCF from SD to TD.” … Therefore: since the word “shall” has been used and this is a syntax rule: if the condition is not true, it is a syntax error or access violation.
Foundation says: re definition of assignable: “A binary string is assignable only to sites of binary string type.” “A number is assignable only to sites of numeric type.” … And so on. That is, for each data type, there’s a note about what assignable means for that type. Now take this as an example: … SET binary_string_target = numeric_source … According to “A binary string is assignable only to sites of binary string type”, this SD is not assignable to this TD. Therefore, unless there is an appropriate user-defined cast function, the partial condition “SD shall be assignable to TD” has not been met.
For a moment ignore the other partial condition, “there shall exist an appropriate user-defined cast function”. In that case, now we know that the rule for store assignment, which is required by the rule for set clause list, has not been met. And that rule is a syntax rule that includes the word “shall”. So it is a syntax error or access rule violation. Table 38 “SQLSTATE class and subclass codes” says that the class for syntax error or access rule violation is 42. Thus it’s clear — at last, eh? — that the SQLSTATE class is 42. What about the subclass? Foundation says: “NOTE 767 — One consequence of this is that an SQL-implementation may, but is not required by ISO/IEC 9075 to, provide subclasses for exception condition syntax error or access rule violation that distinguish between the syntax error and access rule violation cases.” In other words, you can say SQLSTATE is 42000 but you can say other things too. Here I recommend that you look at what DB2 for z/OS has.
“42806 A value cannot be assigned to a variable, because the data types are not compatible.” or “42821 A data type for an assignment to a column or variable is not compatible with the data type.”
Conclusion: the SQLSTATE can be 42xxx, e.g. 42821, syntax error or access violation.
But there are two loopholes! Long ago, when my job was to say how MySQL was compatible with standard SQL, I used them both.
Loophole #1: See above: “The treatment of language that does not conform to the SQL Formats and Syntax Rules is implementation-dependent.” Well, whenever MySQL/MariaDB has a type that is not mentioned in the official rules, such as TEXT rather than CHARACTER VARYING, that means you can declare there is no error.
Loophole #2: See above: “or there shall exist an appropriate user-defined cast function”. Well, there is a cast function whenever MySQL/MariaDB says there is. That is, if Monty declares that you can assign a number to a varchar, while smiling, I would explain: the meaning of the word “user” is implementation-dependent. In this case, the user who created the function is Monty. That means you can declare there is no error.
But, if you declare that you are using the loopholes, then CREATE CAST will be illegal because Foundation requires: “There shall be no user-defined cast for SDT and TDT.” and, alas, where user = Monty, there is a user-defined cast.
Thanks to Alexander Barkov for the question.
ocelotgui explorer
On an unrelated note, the Ocelot Graphical User Interface has an explorer.
Sometimes called a navigator, and vaguely like what people are used to with Windows Explorer, this is a widget that appears (usually on the left but detachable) showing objects in all schemas that the user can access. If the user right-clicks on an object, an in-context menu appears with SQL statements or client actions that can be performed by clicking. Customizable.
Currently it’s only in source code which you can download from github, as always.
It and its documentation will be in the next release and/or in the next post of this blog.
Bug fix: due to a recent MariaDB change, our stored-procedure debugger could not be installed when connecting to a MariaDB server (MySQL debugging was not affected). Now all is well again.
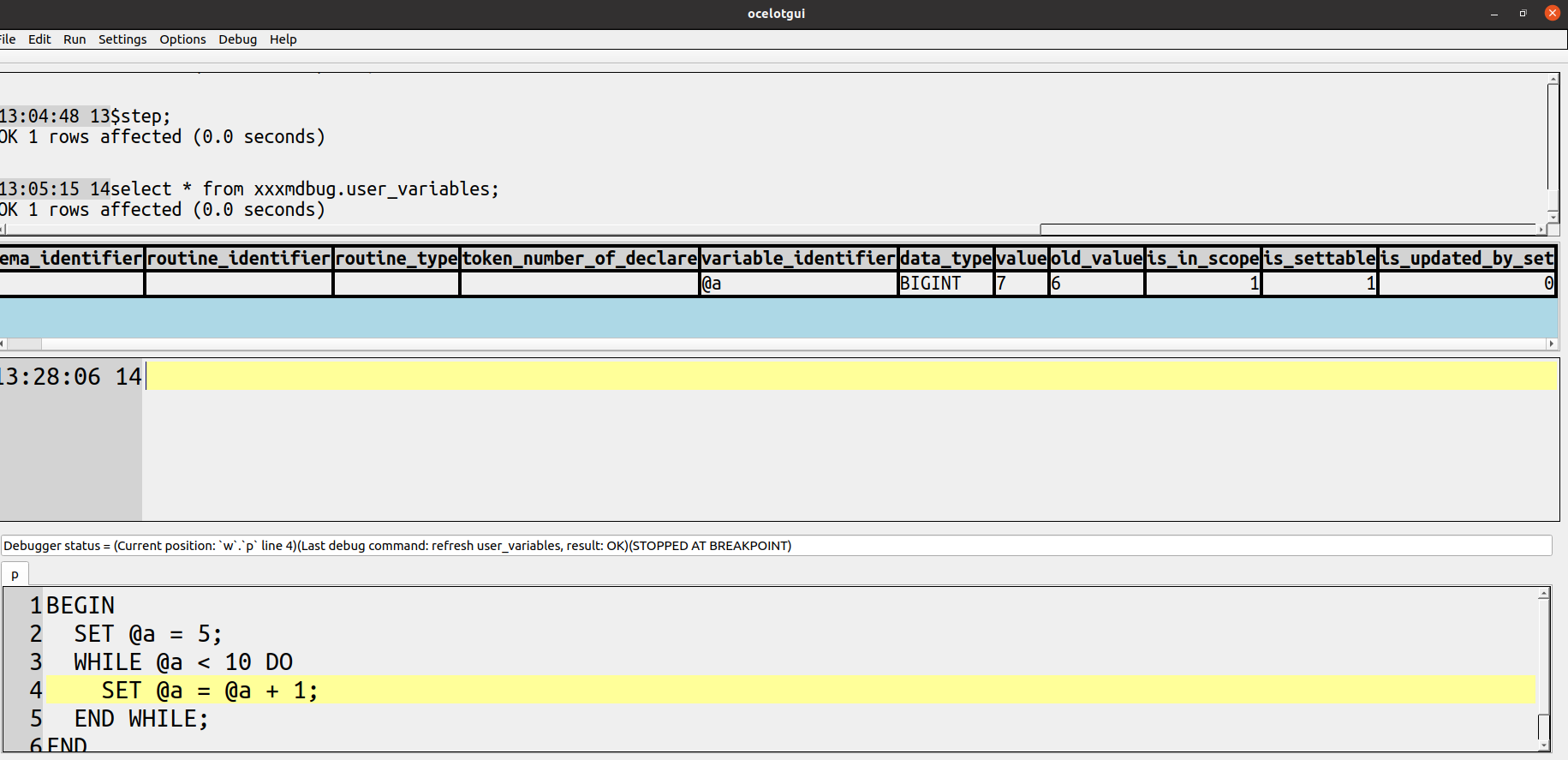
Here, for example, is a screenshot of ocelotgui after connecting to MariaDB 10.8, saying $debug P; and then Alt+5 (“Step”) 4 times, then clicking menu item “Refresh user variables” to see the previous and current values of @a:
/
Incidentally I’ve just noticed some old comments about ocelotgui on https://stackoverflow.com/questions/3007625/mysql-stored-procedure-debugging with one user saying “… helped me a lot!” and another saying “I connected, debugged their tutorial, and am amazed. it’s a GREAT step debugger with variable data view on demand. lots to learn, but the #1 choice so far for free.” Don’t get the wrong idea though — debugging is a unique feature but not the major one.
New platform: Actually ocelotgui runs on any Linux distro (and Windows of course); however, the only specific instructions for creating packages were ones for .deb (Debian-based) and .rpm (Red-Hat-based). Now there is a script file for creating packages on Arch-Linux-based distros too, for example Manjaro or EndeavourOS. It’s PKGBUILD.
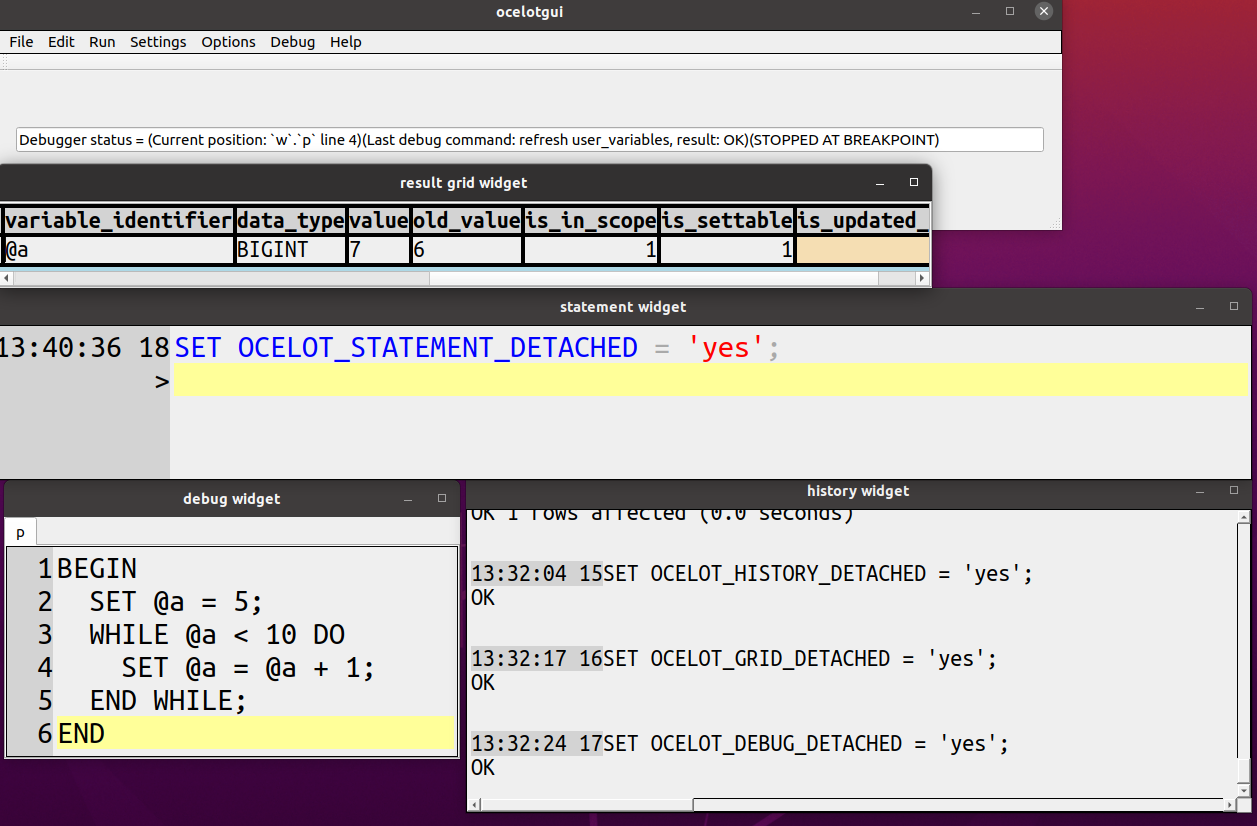
Enhancement: Detaching wasn’t quite as spiffy as it should be because our size calculations were slightly wrong. Here’s a screenshot showing the same widgets as before, after detaching them all and doing some manual fiddling:
I’ll cover SUBSTRING’s variants, its behaviour in odd cases, and what can go wrong. I’ll add a C program that emulates what the SQL:2016 standard requires.
Ordinary case
SUBSTRING(value-expression FROM start-position [FOR string-length])
I expect that everyone knows the ordinary case: value-expression should be either a character string or a binary string, start-position and string-length should be integers, and SUBSTRING(‘abc’ FROM 2 FOR 2) will return ‘bc’.
Abbreviating SUBSTRING to SUBSTR, with commas instead of words to separate arguments, is Oracle and SQLite syntax. MySQL cheerily accepts both syntaxes and treats them as synonyms.
Informix accepts both but does not treat them as synonyms. DB2 has something similar.
So when you have a choice, you just have to decide: do you want to be compatible with Oracle, or with almost everybody else?
Variation: passing a non-string and non-integers
In MySQL/MariaDB I can say SUBSTRING(123, 1.5, 1.1) and get ‘2’. The standard requirement is: the first argument must be a string and the others must be exact with scale 0. So rather than accepting decimals and rounding, others will call this an error.
What we’re seeing here is the typical MySQL/MariaDB idea that, if it’s possible to do something with the input, do it. And in this case it’s possible by converting the first argument to a string and rounding the next arguments.
But it’s not a strictly MySQL thing, Oracle and DB2 will also accept non-integers and do implicit conversions.
Variation: negative start-position
This is probably the most frequent variation.
What is SUBSTRING(‘abc’, -2, 2)?
The standard is 100% clear (well, as clear as it ever gets): start-position is 2 characters before the start of the string, and string start is 1, so SUBSTRING(‘abc’ FROM -2 FOR 2) is a zero-length string but SUBSTRING(‘abc’ FROM -2 FOR 4) is ‘a’. SQL Server follows this though I don’t know whether it always does so.
However — perhaps because programmers are used to seeing such stuff in php and perl and Lua — the alternative is to say that negative start-positions are counted backwards from the end of the string, so -1 is the last character, -2 is the second-last, and so on.
So in MySQL SUBSTRING(‘abc’ FROM -2 FOR 2) is ‘bc’ and SUBSTRING(‘abc’ FROM -2 FOR 4) is also ‘bc’. But don’t hope for consistency: SUBSTRING(‘abc’ FROM -4 FOR 5) is just a zero-length string.
I’ll admit that the count-backwards variation is popular, since it’s in Oracle and SQLite and MySQL/MariaDB (and in Informix SUBSTR, which is the difference I mentioned earlier). But it’s awfully easy to avoid: use a different function if your DBMS supports RIGHT() or INSTR(), or say SUBSTRING(‘abc’ FROM LENGTH(‘abc’) – 2 FOR 2).
For that last suggestion, I wondered: won’t that take longer? So I filled a table with long strings.
CREATE TABLE j (s1 TEXT(1000000));
CREATE PROCEDURE p()
BEGIN
DECLARE i INTEGER DEFAULT 0;
WHILE i < 737 DO
INSERT INTO j VALUES (REPEAT('abc',1000000));
SET i = i + 1;
END WHILE;
END;
CALL p();
SELECT SUBSTRING(s1 FROM -2 FOR 2) FROM j;
SELECT SUBSTRING(s1 FROM LENGTH(s1)-2 FOR 2) FROM j;
The SELECT with “FROM -2” takes on average about 12 seconds on my laptop. The SELECT with “FROM LENGTH(s1)-2” takes on average about 7 seconds. Your mileage will vary but if you get anything vaguely similar you’ll have to conclude that non-standard negative start positions are unnecessary.
Variation: going past the end
Of course SUBSTRING(‘abc’ FROM 3 FOR 5) is ‘c’ and the nonexistent characters past the end don’t matter. That’s standard, and it’s why I found it inconsistent when I saw different behaviour for nonexistent characters before the start.
But there’s another possible answer: the DB2 incomprehensible result. The documentation for SUBSTR() says that the result is an error, and simultaneously that the string is padded on the right with spaces or zero bytes.
Variation: CHAR in, VARCHAR out
If the input is CHAR, is the result supposed to be CHAR?
The standard is once again clear about this: “If the declared type of <character value expression> is fixed-length character string or variable-length character string, then DTCSF is a variable-length character string type with maximum length equal to the fixed length or maximum length of DTCVE.”
For Oracle the result is VARCHAR if the input is CHAR.
For SQL Server the result is VARCHAR if the input is CHAR.
For DB2 the result is VARCHAR if the input is CHAR.
For MySQL the result is undocumented so I used my usual way of finding out what the data type of a result is …
CREATE TABLE j (s1 CHAR(5));
CREATE TABLE j2 AS SELECT SUBSTRING(s1 FROM 2 FOR 2) FROM j;
SELECT table_name, data_type FROM information_Schema.columns WHERE column_name = 's1';
Result: ‘char’. Yes, I know, SHOW CREATE TABLE j2; would say ‘varchar’, but I don’t rely on it here. If you set sql_mode=’pad_char_to_full_length’; and then select length(column_name) from all rows in the table, you’ll see it’s always the defined length.
Variation: octets
SUBSTRING(… FROM … FOR … [USING CHARACTERS|OCTETS])
By now you’ve gathered that my main concern is SUBSTRING for characters more than SUBSTRING for binaries, but the standard says I can specify the position and length in bytes rather than characters.
So, if you’ve got a multi-byte character, and you use OCTETS, you can split it so that the result is not valid characters. For example: starting with ‘Д’ in UTF-8 (which is encoded as 0D94): SUBSTRING(‘Д’ FROM 2 FOR 1 USING OCTETS) is X’94’ which is not a UTF-8 character that was in the input.
DB2 covers this up by replacing invalid character fragments with spaces.
For the standard, for the newer substring function added in SQL:2016, I read: “If [character length units] is OCTETS and the [relevant] octet of STR is not the first octet of a character, then the result of [this function] is implementation-dependent.” That certainly seems like the appropriate thing to say about all substring functions.
Variation: added in SQL:2016
These SUBSTRING syntaxes which are part of SQL:2016 might someday be interesting:
<regular expression substring function> ::=
SUBSTRING <left paren> <character value expression> SIMILAR <character value expression>
ESCAPE <escape character> <right paren>
<regex substring function> ::=
SUBSTRING_REGEX <left paren>
<XQuery pattern> [ FLAG <XQuery option flag> ]
IN <regex subject string>
[ FROM <start position> ]
[ USING <char length units> ]
[ OCCURRENCE <regex occurrence> ]
[ GROUP <regex capture group> ]
<right paren>
… but as of today they seem to have not caught fire in popular imagination.
Variation: zero-length strings can be errors
The obsolete manual for Oracle 10g says “When you specify a value that is less than 1, the function returns NA.” which I guess means it was an error long ago. Now the return is null because Oracle doesn’t distinguish it from a zero-length string.
In a draft of an earlier SQL standard, one might read: “16) If the result of <string value expression> is a zero-length character string, then it is implementation-defined whether an exception condition is raised: data exception — zero-length character string”
But that, in the section about <string value function>, didn’t fit well. It was replaced by “16) If the result of <string value function> is the zero-length character string or the zero-length binary string, then it is implementation-defined whether an exception condition is raised: data exception – zero-length character string or data exception – zero-length binary string, respectively.”
So: if the result of SUBSTRING() is ”, then it’s not a violation of the standard to return an error. However, I don’t expect that anybody would say that unless they did the same for everything, not just SUBSTRING().
C program that does what the standard says
I said the standard document is clear, but it is also intimidating. The main clause about SUBSTRING for characters looks like this:
3)If <character substring function> is specified, then:
a) If the character encoding form of <character value expression> is UTF8, UTF16, or UTF32, then, in
the remainder of this General Rule, the term "character" shall be taken to mean "unit specified by
<char length units>".
b) Let C be the value of the <character value expression>, let LC be the length in characters of C, and
let S be the value of the <start position>.
c) If <string length> is specified, then let L be the value of <string length> and let E be S+L. Otherwise,
let E be the larger of LC + 1 and S.
d) If at least one of C, S, and L is the null value, then the result of the <character substring function> is
the null value.
e) If E is less than S, then an exception condition is raised: data exception - substring error.
f) Case:
i) If S is greater than LC or if E is less than 1 (one), then the result of the <character substring
function> is the zero-length character string.
ii) Otherwise,
1) Let S1 be the larger of S and 1 (one). Let E1 be the smaller of E and LC+1. Let L1 be
E1-S1.
2) The result of the <character substring function> is a character string containing the L1
characters of C starting at character number S1 in the same order that the characters appear
in C.
It’s not something that humans can grasp immediately. But notice that, in English, it’s declaring variables and conditional-execution statements. So for testing purposes it’s straightforward to convert the English into C. That’s what I’ve done for this section. Here is a stand-alone program that replicates all the important parts of the clause so that anyone can see what SUBSTRING() would produce for any combination of SUBSTRING(value-expression FROM start-position [FOR string-length])
/*
Simulate ISO 9075-2:2016 description of substring
By Peter Gulutzan 2021-08-30
Copyright (c) 2021 by Peter Gulutzan. All rights reserved.
To compile: gcc -o substring substring.c
To run, with 2 or 3 args: substring character_value_expression start_position [string_length]
Assumption: start_position and string_length are integers, there is no validity check.
Convention: if character_value_expression is - then we treat it as an empty string.
Example:
pgulutzan@pgulutzan-VirtualBox:~/tarantool_sandbox$ ./substring 'abc' -1 1
character_value_expression: abc.
start_position: -1
string_length: 1
LC: 3
S: -1
L: 1
E: 0
S > LC or E < 1. Return zero-length string
*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
int main( int argc, char *argv[] )
{
if ((argc < 3) || (argc > 4))
{
printf("We want: character_value_expression start_position string_length\n");
exit(0);
}
bool is_length_specified;
char *character_value_expression= argv[1];
int start_position= atoi(argv[2]); /* no validity check */
int string_length;
if (argc == 3)
{
is_length_specified= false;
}
else
{
is_length_specified= true;
string_length= atoi(argv[3]); /* no validity check */
}
printf("character_value_expression: %s.\n", character_value_expression);
printf("start_position: %d\n", start_position);
if (is_length_specified == false)
{
printf("string_length: not specified\n");
}
else
{
printf("string_length: %d\n", string_length);
}
char *C= character_value_expression;
int LC= -99, S= -99, E= -99, L= -99, S1= -99, E1= -99, L1= -99;
if (strcmp(character_value_expression, "-") == 0) LC= 0;
else LC= strlen(C);
printf("LC: %d\n", LC);
S= start_position;
/* c) If <string length> is specified, then let L be the value of <string length> and let E be S+L. Otherwise,
let E be the larger of LC + 1 and S. */
if (is_length_specified == true)
{
L = string_length;
E= S + L;
}
else
{
if ((LC + 1) > S) E= LC + 1;
else E= S;
}
printf("S: %d\n", S);
printf("L: %d\n", L);
printf("E: %d\n", E);
/* e) If E is less than S, then an exception condition is raised: data exception -- substring error. */
if (E < S)
{
printf("E < S. data exception -- substring error.\n");
exit(0);
}
/* f) i) If S is greater than LC or if E is less than 1 (one), then the result of the <character substring
function> is the zero-length character string. */
if ((S > LC) || (E < 1))
{
printf("S > LC or E < 1. Return zero-length string\n");
exit(0);
}
/* f) ii) 1) Let S1 be the larger of S and 1 (one). Let E1 be the smaller of E and LC+1. Let L1 be
E1-S1. */
if (S > 1) S1= S;
else S1= 1;
if (E < (LC + 1)) E1= E;
else E1= LC + 1;
L1= E1 - S1;
printf("S1: %d\n", S1);
printf("E1: %d\n", E1);
printf("L1: %d\n", L1);
/* f) ii) 2 The result of the <character substring function> is a character string containing the L1
characters of C starting at character number S1 in the same order that the characters appear
in C. */
for (int i= S1 - 1; i < (S1 - 1) + L1; ++i)
{
printf("%c\n", *(C + i));
}
}
ocelotgui progress
The open-source GUI client program is getting constantly better. The next big feature will be “Export” to a variety of formats including delimited, boxed, html, and default. The preliminary code has been uploaded to our github repository.
The README for the current version (1.5) is here for MySQL/MariaDB. Or, here for Tarantool.
A while ago I noticed a forum with tips for changing the colour of some results of the mysql utility. They’re nifty but tricky and don’t look appropriate for ordinary users. So I’ll concentrate on what a GUI can do instead. I illustrate with ocelotgui but any good product should be similar.
My example table is
CREATE TABLE elements (atomic_number INTEGER PRIMARY KEY, name VARCHAR(20));
INSERT INTO elements VALUES
(48,'Cadmium'),(20,'Calcium'),(98,'Californium'),(6,'Carbon'),(58,'Cerium'),
(55,'Cesium'),(17,'Chlorine'),(24,'Chromium'),
(27,'Cobalt'),(112,'Copernicium'),(29,'Copper'),(96,'Curium');
Obvious and simple things with a Settings menu
Of course there will be a menu item for Settings that puts up a dialog box.
The important items on it will be for changing background colour and font. For example these three displays show what happens after the settings menu has changed background colours and fonts.
I prefer to use the dialog box initially and then make the changes
permanent with client statements or startup options.
HTML in the select list
HTML is designed for people who want to customize colours and fonts, and many SQL users are familiar with it, so it’s natural to want it for changing colours and fonts in an SQL result set.
For example, with a WHEN trick, here we display a column as bold, or as italic, depending on the value:
SELECT CASE
WHEN name LIKE '%ium' THEN '<b>' || name || '</i>'
ELSE '<i>' || name || '</i>'
END
AS name,
atomic_number
FROM elements;
For example, with a UNION trick, here we display in red or in blue, depending on the value:
SELECT
'<p style="color:red">' ||
CAST(atomic_number AS VARCHAR(20)) AS atomic_number,
'<p style="color:red">' || name AS name
FROM elements
WHERE atomic_number < 90
UNION ALL
SELECT atomic_number,
'<p style="color:blue">' || name AS name
FROM elements
WHERE atomic_number >= 90;
You could accomplish the same effects with REPLACE() or with stored procedures. An obvious usage is for emphasizing NULLs which otherwise are hard to distinguish from blanks. The advantage of this technique is that, even if your GUI isn’t this sophisticated, you can still get the effect by piping the result set to a file where a browser can read it. The distadvantages of this technique are: (a) it’s forcing the server to do a client job, (b) the column might contain ‘<‘ or ‘>’ or other entities, (c) some data types won’t work with the || concatenate operator (or the CONCAT function). So it’s best to have it as a non-default option (and that’s what the “HTML effects” option is for, on the first screenshot that I showed for Settings menu).
Conditional settings
The more general technique is to use a separate instruction for the setting, that will apply for all result sets, for cells that have certain characteristics. This is a bit like using cascading style sheets rather than inline HTML, but the best syntax is SQL-like, since that’s the language that users are bound to know. For example here is an instruction that changes a cell’s background colour and height if certain conditions are met (REGEXP means “regular expression”) (“SET ocelot_…” is a client-side statement that won’t get passed to the server):
SET ocelot_grid_background_color='yellow',
ocelot_grid_cell_height=40
WHERE column_name REGEXP 'number'
AND row_number <> 4 ;
SELECT * FROM elements LIMIT 6;
Images
Here is a cheap bar graph:
SELECT atomic_number,
SUBSTR('------------',1, atomic_number / 10) AS bar,
name
FROM elements;
MySQL/MariaDB users might prefer REPEAT(‘a’,atomic_number / 10) AS bar instead of SUBSTR. Unicode-character-set users might prefer Unicode 2588 █ (full block) instead of ‘-‘, to get a solid bar,
or might prefer a series of emojis.
Every good GUI can display .png of .jpg images too, so it’s not particularly hard to store them in the database and add them to the result via joins or subqueries. For example, with thanks to Wikipedia for the original picture,
SELECT atomic_number,
name,
(SELECT png
FROM "timages"
WHERE caption = 'copper')
AS png
FROM elements
WHERE name = 'copper';
but I hesitate to say that .png and .jpg images make good decoration, because they are never small.
ocelotgui 1.5.0
To be specific: the examples were all done with ocelotgui 1.5.0 and I used the options|detach menu choices so I could show only the select and grid widgets in a left-to-right order. Some of the functionality, particularly the new layout of the settings menu, is new. As always, the release is available on github.