Some Connector/C options can have better explanations than what’s in the MySQL or MariaDB manuals. Here they are.
Files
Putting together the MySQL and MariaDB Connector/C manuals’ words, Connector/C reads these files in this order:
/etc/my.cnf MYSQL always. MariaDB only if DEFAULT_SYSCONFDIR not defined
/etc/mysql/my.cnf MySQL always. MariaDB only if DEFAULT_SYSCONFDIR not defined
SYSCONFDIR/my.cnf MYSQL if SYSCONFDIR defined. + MariaDB if DEFAULT_SYSCONFDIR defined
$MYSQL_HOME/my.cnf MySQL always. MariaDB always.
defaults-extra-file MySQL always. MariaDB never (but they say maybe soon)
~/.my.cnf MySQL always. MariaDB always
~/.mylogin.cnf MySQL always. MariaDB never
What they don’t say is …
If $MYSQL_HOME is null, then they won’t look in $MYSQL_HOME/my.cnf.
If $MYSQL_HOME is non-null but also $MARIADB_HOME is non-null, then MariaDB will look only in $MARIADB_HOME/my.cnf.
What really happens with environment variables is in this snippet from MariaDB’s source file ma_default.c:
/* CONC-537: Read configuration files from MYSQL_HOME directory only if
MARIADB_HOME was not set */
if (!(env= getenv("MARIADB_HOME")))
env= getenv("MYSQL_HOME");
if (env && add_cfg_dir(configuration_dirs, env))
goto error;
Similarly, you can cause a working mysql client to fail thus:
#undefine the $HOME environment variable
unset HOME
#look for ~/.my.cnf -- this will work
ls ~/.my.cnf
#connect -- this will fail iff ~/.my.cnf has special options
mysql
In other words, what decides matters may be ~/.my.cnf, but may be $HOME.
And they don’t really tell you how to know if SYSCONFDIR is defined. Sure, it’s “usually” e.g. /etc if the connector was built on Red Hat, and you can see what their own statically-linked programs do by saying –help or –print-defaults, but those aren’t guarantees that the library you’re loading was built with the same cmake.
And beware, my.cnf might be symlinked. For example, I see this on Ubuntu 20:
$ ls -l /etc/mysql/my.cnf
lrwxrwxrwx 1 root root 11 May 26 2024 /etc/mysql/my.cnf -> mariadb.cnf
So, rather than believe the manuals, believe the strace utility. For example, I see this when I run a program optiontest that dynamically loads a connector and connects:
$ strace 2>&1 ./optiontest | grep my.cnf
stat("/etc/my.cnf", 0x7fff913b7bb0) = -1 ENOENT (No such file or directory)
stat("/etc/mysql/my.cnf", {st_mode=S_IFREG|0644, st_size=1146, ...}) = 0
openat(AT_FDCWD, "/etc/mysql/my.cnf", O_RDONLY|O_CLOEXEC) = 3
stat("/home/pgulutzan/.my.cnf", {st_mode=S_IFREG|0644, st_size=749, ...}) = 0
openat(AT_FDCWD, "/home/pgulutzan/.my.cnf", O_RDONLY|O_CLOEXEC) = 3
Value quirks
The MySQL manual will tell you “When you use a startup option to set a variable that takes a numeric value, the value can be given with a suffix of K, M, G, T, P, or E (either uppercase or lowercase) to indicate a multiplier of 1024, 10242, 10243, 10244, 10245, or 10246; that is, units of kilobytes, megabytes, gigabytes, terabytes, petabytes, or ettabytes, respectively.” (They mean “exabytes”.)
That doesn’t apply to options in an options file. If I say option=1K, the connector sees 1 and stops evaluating when it encounters a non-numeric.
The MariaDB manual even contains an example that contains “–max_allowed_packet=1GB”, though I can’t see where “GB” is documented.
And a connector even accepts this in a my.cnf file:
max-allowed-packet = "+1111111111"
It will change the hyphens to underscores and strip the quotes (single or double quotes both work) and ignore the sign.
This is all okay, therefore it is bad. Don’t be lax re syntax of a max.
Incompatible ABI
In MySQL 5.7 and MariaDB current, the value of option MYSQL_REPORT_DATA_TRUNCATION is 19. In MySQL current, it is 14. This happens because MySQL skipped some values when upgrading to version 8.0, which you can see by comparing mysql.h before-and-after. MariaDB did not make this change. Here’s part of MySQL 8.3 mysql.h on the left, part of MariaDB 12.0 mysql.h on the right:
enum mysql_option { enum mysql_option {
MYSQL_OPT_CONNECT_TIMEOUT, MYSQL_OPT_CONNECT_TIMEOUT,
MYSQL_OPT_COMPRESS, MYSQL_OPT_COMPRESS,
MYSQL_OPT_NAMED_PIPE, MYSQL_OPT_NAMED_PIPE,
MYSQL_INIT_COMMAND, MYSQL_INIT_COMMAND,
MYSQL_READ_DEFAULT_FILE, MYSQL_READ_DEFAULT_FILE,
MYSQL_READ_DEFAULT_GROUP, MYSQL_READ_DEFAULT_GROUP,
MYSQL_SET_CHARSET_DIR, MYSQL_SET_CHARSET_DIR,
MYSQL_SET_CHARSET_NAME, MYSQL_SET_CHARSET_NAME,
MYSQL_OPT_LOCAL_INFILE, MYSQL_OPT_LOCAL_INFILE,
MYSQL_OPT_PROTOCOL, MYSQL_OPT_PROTOCOL,
MYSQL_SHARED_MEMORY_BASE_NAME, MYSQL_SHARED_MEMORY_BASE_NAME,
MYSQL_OPT_READ_TIMEOUT, MYSQL_OPT_READ_TIMEOUT,
MYSQL_OPT_WRITE_TIMEOUT, MYSQL_OPT_WRITE_TIMEOUT,
MYSQL_OPT_USE_RESULT, MYSQL_OPT_USE_RESULT,
MYSQL_REPORT_DATA_TRUNCATION, MYSQL_OPT_USE_REMOTE_CONNECTION,
MYSQL_OPT_RECONNECT, MYSQL_OPT_USE_EMBEDDED_CONNECTION,
MYSQL_PLUGIN_DIR, MYSQL_OPT_GUESS_CONNECTION,
MYSQL_DEFAULT_AUTH, MYSQL_SET_CLIENT_IP,
MYSQL_OPT_BIND, MYSQL_SECURE_AUTH,
MYSQL_OPT_SSL_KEY, MYSQL_REPORT_DATA_TRUNCATION,
MYSQL_OPT_SSL_CERT, MYSQL_OPT_RECONNECT,
MYSQL_OPT_SSL_CA, MYSQL_OPT_SSL_VERIFY_SERVER_CERT,
MYSQL_OPT_SSL_CAPATH, MYSQL_PLUGIN_DIR,
MYSQL_OPT_SSL_CIPHER, MYSQL_DEFAULT_AUTH,
MYSQL_OPT_SSL_CRL, MYSQL_OPT_BIND,
... ...
The skipped values were MYSQL_OPT_USE_REMOTE_CONNECTION, MYSQL_OPT_USE_EMBEDDED_CONNECTION, MYSQL_OPT_GUESS_CONNECTION, MYSQL_SET_CLIENT_IP, MYSQL_SECURE_AUTH, and later MYSQL_OPT_SSL_VERIFY_SERVER_CERT. In “Changes in MySQL 8.0” the wording is “not binary compatible”. MariaDB deserves thanks for doing nothing.
This means life would be easier if mysql.h and Connector/C and the server all had the same version and vendor. Possibly somebody can do some subtracting of the skipped values either within the connector or before calling it, thus: call mysql_get_client_info() to determine whether it returns a MySQL version such as “9.x” or a MariaDB-Connector-C version such as “3.x” (unfortunately it won’t say “MariaDB” but you can tell from the number) (mysql_get_client_info is legal immediately after mysql_init so you don’t need to set options or connect); check #ifdef MYSQL_REPORT_DATA_TRUNCATION and if it’s 14 to determine whether mysql.h came from MySQL or MariaDB; if mysql.h and the connector are from different vendors then call mysql_options(…, option_value+-offset, …) instead of mysql_options(…, option_value, …).
However, a fewer-surprises solution is to get the connector to process the option files directly, so you don’t have to call mysql_options() for all possible numeric values. You can persuade the connector to do that with MYSQL_READ_DEFAULT_FILE (option value 4 in both connectors) or MYSQL_READ_DEFAULT_GROUP (option value 5 in both connectors).
MYSQL_READ_DEFAULT_FILE
The MySQL manual says this is a directive to “Read options from the named option file instead of from my.cnf.” (They mean “instead of any other file”.)
This would be useful, except that it’s exclusive — if you call it twice then the effects of one of the calls are erased.
With MariaDB only, if you pass mysql_options(…MYSQL_READ_DEFAULT_FILE, “”) then the connector reads all option files as if blanks are wildcards. This is not useful, though, because you can get the same effect with either MySQL or MariaDB by passing MYSQL_READ_DEFAULT_GROUP instead.
MYSQL_READ_DEFAULT_GROUP
This too is exclusive but at least you can hope that the connector reads all the default files.
And it’s not exclusive about groups, that is, if you ask for group “x” you get not only group “x” but also the default groups. (Alas, this may not be true for included files.) Or you can ask for group “” and get nothing but the default groups.
MariaDB handles the default groups [client] [client-server] [client-mariadb]. MySQL handles the default group [client] — [mysql] is supposed to be for the mysql client only. It follows then that, if you want your .cnf to work with either MySQL or MariaDB, you have to say
[client]
#options that apply for MySQL
[client-mariadb]
#options that apply for MariaDB
… a MySQL connector will ignore [client-mariadb]. A MariaDB connector will not ignore [client] but will override [client] options with the [client-mariadb] options because they come later.
Since the effects of one of the calls are erased if you call with MYSQL_READ_DEFAULT_GROUP twice, you’re limited to a maximum of one non-default group. Unless you can add one more with –defaults-group-suffix. This is something that MySQL has now and MariaDB might have soon.
Combining file options with command-line options
Suppose you want to let MYSQL_READ_DEFAULT_GROUP handle what’s in the option files, but you also want to process a command line that says –connect_timeout=100.
Seems easy enough, eh? You determine that “connect_timeout” is associated with MYSQL_OPT_CONNECT_TIMEOUT, you put the value after the “=” in an unsigned int, and call:
int mysql_option_result;
mysql_option_result= mysql_options(mysql, MYSQL_READ_DEFAULT_GROUP, "client");
printf("d after MYSQL_READ_DEFAULT_GROUP %d\n", mysql_option_result);
mysql_option_result= mysql_options(mysql, MYSQL_OPT_CONNECT_TIMEOUT, &connect_timeout);
printf("**** d2 after mysql_options MYSQL_OPT_CONNECT_TIMEOUT %d\n", mysql_option_result);
(The option numbers in these two cases are the same for all connectors.)
You see mysql_option_result is 0 both times, you check later with mysql_get_option() and find that the value is 100, and all seems well. But it’s not. Because: the order of option execution is not necessarily the order that you call mysql_options(). In my tests, if a my.cnf file just happens to contain “connect_timeout=200”, that overrides. Even if that’s okay (to me it doesn’t look okay), it’s still undocumented behaviour.
(Aside: if the only command-line options are host|user|password|database|port|socket, these control mysql_real_connect() arguments so you don’t need to worry about an inability to use mysql_options() for them.)
A decent solution is: explain that command-line options might not take effect, and print warnings if mysql_get_option(…MYSQL_OPT_CONNECT_TIMEOUT… ) result is not 100. And yet that’s not a great solution — people might expect that command-line options are trumps. Any way to force that?
Well, I can think of two ways:
1. Open ~/.my.cnf for appending, strip the –s from the arguments and put them in, call mysql_options with MYSQL_READ_DEFAULT_FILE, call mysql_real_connect, then remove what you appended.
2. Create a temporary file, make the first line something like this (replacing “$HOME” with your full path) !include $HOME/.my.cnf, then strip the –s from the arguments and put them in, call mysql_options with MYSQL_READ_DEFAULT_FILE, call mysql_real_connect, then remove what you appended.
But: you might not have write privileges (even if you do, there might be a sticky bit as if you’re in a sandbox).Or: you might conflict with some other program that wants the same files Or: you’d be missing the rest of the default option files besides ~/.my.cnf.
More option files
MySQL’s ability to handle defaults-extra-file is an advantage over MariaDB. But it might not last forever: Add option that corresponds to –defaults-extra-file MariaDB command-line option is marked as something that might happen in version 3.5 (as I write this, the latest version is 3.4.3).
MySQL’s ability to handle ~/.mylogin.cnf is an advantage over MariaDB. But read my earlier post and you’ll see that I supply a decrypter as part of the ocelotgui package.
MYSQL_OPT_INIT_COMMAND
Assuming you have a client that works with default option files for either MariaDB or MySQL, you can run a quick test.
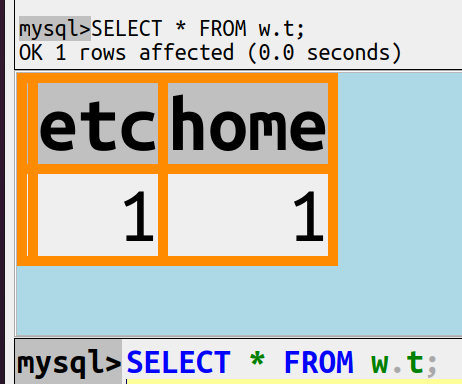
Start the client. Make this simple sample table:
CREATE DATABASE w;
CREATE TABLE w.t (etc INT, home INT);
INSERT INTO w.t VALUES (0, 0);
Exit.
Add these two lines at the end of ~/.my.cnf:
init_command = "UPDATE w.t SET etc = etc + 1;"
init_command = "UPDATE w.t SET home = home + 1;"
Start the client again and say
SELECT * FROM w.t;
The result will look like this:
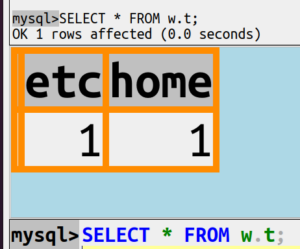
Now realize: this result proves that both UPDATE statements happened. The init_command option is an undocumented example of what one could call “multi-element” options. An ordinary option overwrites (cancels) any earlier occurrence. A multi-element option, if you say it twice, there are two things to execute (and the order of execution isn’t guaranteed).
This could be unpleasant if the first occurrence is hidden in /etc/my.cnf and you only see the second occurrence in ~/.my.cnf and think it’s all there is. Add that to the fact that the updates might not appear in the client’s log.
So if your client supports anything like “SOURCE file-with-statements”, and the statements are for the initial connect (not auto-reconnect), it’s probably better to use SOURCE instead of init_command.
MYSQL_OPT_CONNECT_ATTR_ADD
With MySQL’s mysql_options4 this looks like:
mysql_options4(mysql, MYSQL_OPT_CONNECT_ATTR_ADD, "program-name", "my_wonderful_client");
The MariaDB connector will translate mysql_options4() to mysql_optionsv().
There are other programs that will add “program-name” here, so you might as well too. It will appear in a performance_schema table, so you might as well have performance_schema on. It’s a way to put a comment in a my.cnf file that will be visible with SELECT.
Like init_command, MYSQL_OPT_CONNECT_ATTR_ADD is a multi-element option. So to avoid duplication you might want to say MYSQL_OPT_CONNECT_ATTR_DELETE first.
mysql_get_option
MariaDB is recommending mysql_get_optionv() but mysql_get_option() still works.
Or rather, it works after mysql_real_connect(). It’s useless to call mysql_get_option() until you’re connected, and it’s undefined-results-time if the option wasn’t set earlier.
I thought that the manuals’ examples for strings looked odd, so I supply this example instead (notice the &):
const char *set_charset_name= NULL;
int option_result= mysql_get_option(mysql, MYSQL_SET_CHARSET_NAME, &set_charset_name);
if (set_charset_name == NULL) printf("(null)\n");
else printf("**** %d, MYSQL_SET_CHARSET_NAME=%s\n", option_result, set_charset_name);
Some mysql_get_option() variations might fail even though the option is set correctly and the call is in the right place. This might tempt people to look at session variables instead, but they’re tricky too. For example, mysql_get_option(…MYSQL_OPT_MAX_ALLOWED_PACKET…) does not return the same thing as SELECT @@session.max_allowed_packet.
socket
Suppose, given some of what I’ve described, you decide it’s better to use MariaDB Connector/C when connecting to a MariaDB server, and use MySQL Connector/C when connecting to a MySQL server. So how do you know what you’re connecting to, before you connect?
Well, on my local network I have instances of both servers. For one of them I can use telnet localhost port-3309
~$ telnet 192.168.1.68 3309
Trying 192.168.1.68...
Connected to 192.168.1.68.
Escape character is '^]'.
I
9.3.0$xPUPGNw
�99PRRRp!caching_sha2_password2#08S01Got timeout reading communication packetsConnection closed by foreign host.
For the other I can use telnet localhost port-3310
$ telnet 192.168.1.68 3310
Trying 192.168.1.68...
Connected to 192.168.1.68.
Escape character is '^]'.
R
12.0.1-MariaDB&J%xPd*@�=Dr5Ng?ExQh<.mysql_native_passwordConnection closed by foreign host.
The important value on port-3309 is “9.3.0” so I know it’s MySQL 9.3.0. The important value on port-3310 is “12.0.1-MariaDB” so I know it’s MariaDB 12.0.1.
I can read these things within a program via the socket() utility, and discard. Then with pgfindlib I can pick the connector on my machine that’s best for that port.
But I don’t.
For now, I find it simpler to just suggest in the manual that one of the options on the the command line or in an option file should say what the expected server is.
documentation bugs
In June 2025 I submitted a bug report with 15 complaints about MariaDB documentation. I don’t mean to suggest that the MySQL documentation is better.
ocelotgui
If you’re wondering “Will Peter Gulutzan follow his own advice?” — oh yes, I intend to implement the suggestions I’ve made here, in ocelotgui. I’m just going to wait a week or two in case somebody finds a flaw. Meantime, ocelotgui version 2.5 is not doing a wonderful job of connecting, which I acknowledge. As always, source and executables are downloadable from github.
Errors?
I might be mistaking or omitting things, so read this blog post again after a while, in case I’ve had to make corrections. If you find a particular mistake or omission, comment on this post or send email, my name is pgulutzan and my domain is ocelot.ca.
The MySQL library is libmysqlclient.so, the MariaDB library is libmariadbclient.so or libmariadb.so. I’ll list some quirks that I think are relatively unknown but good to know. I’ll end with a pointer to a function that’s good to have.
mysql and mariadb clients don’t themselves use .so libraries
To illustrate, here’s the file mysql.dir/link.txt that I got when building MySQL’s source with -DWITHOUT_SERVER=ON.
/usr/bin/c++ -std=c++20 -fno-omit-frame-pointer -ftls-model=initial-exec -g -O2
-ffile-prefix-map=/home/pgulutzan/Downloads/mysql-9.2.0=.
-flto=auto -ffat-lto-objects -flto=auto -ffat-lto-objects -fstack-protector-strong
-Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2
-Wall -Wextra -Wformat-security -Wvla -Wundef -Wmissing-format-attribute -Woverloaded-virtual
-Wcast-qual -Wimplicit-fallthrough=5 -Wstringop-truncation -Wsuggest-override
-Wmissing-include-dirs -Wextra-semi -Wlogical-op
-ffunction-sections -fdata-sections -O2 -g -DNDEBUG -g1 -Wl,-Bsymbolic-functions
-flto=auto -ffat-lto-objects -flto=auto -Wl,-z,relro -Wl,--build-id=sha1
CMakeFiles/mysql.dir/__/sql-common/net_ns.cc.o
CMakeFiles/mysql.dir/completion_hash.cc.o CMakeFiles/mysql.dir/mysql.cc.o
CMakeFiles/mysql.dir/pattern_matcher.cc.o CMakeFiles/mysql.dir/readline.cc.o
CMakeFiles/mysql.dir/client_query_attributes.cc.o
CMakeFiles/mysql.dir/multi_factor_passwordopt-vars.cc.o
CMakeFiles/mysql.dir/multi_option.cc.o
CMakeFiles/mysql.dir/common/user_registration.cc.o
CMakeFiles/mysql.dir/__/sql-common/sql_string.cc.o
-o ../runtime_output_directory/mysql ../archive_output_directory/libmysqlclient.a
../extra/libedit/libedit-20240808-3.1/src/libedit.a
/usr/lib/x86_64-linux-gnu/libssl.so
/usr/lib/x86_64-linux-gnu/libcrypto.so
/usr/lib/x86_64-linux-gnu/libresolv.so -lm -lcurses
As you can see if you squint, it’s bringing in libmysqlclient.a, the static library.
This affects not only mysql but other executables that MySQL provides. And effects are similar with MariaDB’s source.
MySQL manual says LD_RUN_PATH decides the client .so library
Specifically the Environment Variables” section says in a chart beside LD_RUN_PATH: “Used to specify the location of libmysqlclient.so.” and the “Problems Using the Perl DBI/DBD Interface” section says “Add the path name of the directory where libmysqlclient.so is located to the LD_RUN_PATH environment variable. Some systems use LD_LIBRARY_PATH instead.”
These are not falsehoods but I think they could mislead Linux users.
First, as I mentioned earlier, it doesn’t necessarily apply for what they supply.
Second, as I’ll mention later, on “some systems” — e.g. Linux, eh? — LD_RUN_PATH only has an effect at build time (as when you run gcc) and Linux package developers deprecate it.
Third, as I’ll also mention later, there are several other factors that the dynamic loader will examine though the MySQL manual doesn’t mention them all.
As a client developer I have to pay attention to this advice and look at LD_RUN_PATH when calling dlopen, but it’s not my favourite advice.
MariaDB library isn’t always the same
I said at the start that “the MariaDB library is libmariadbclient.so or libmariadb.so” but it’s not so simple.
There’s a chance that symlinks will exist between libmysqlclient.so and a MariaDB .so.
There’s also a chance that both libmariadbclient.so and libmariadb.so will be available, and libmariadbclient.so will have a symlink to libmariadb.so which is the real target. However, this is not always the case.
Illustration #1: This is what the latest Debian distro says in the sid libmaria-dev list of x32 files:
/usr/lib/x86_64-linux-gnux32/libmariadb.so
/usr/lib/x86_64-linux-gnux32/libmariadbclient.so
I’ve left out the irrelevant stuff. The point is, both .so names are there.
Illustration #2: This is what the MariaDB Connector/C contains after a recent download:
~/connector-c/usr/local/lib/mariadb$ ls
libmariadb.a libmariadbclient.a libmariadb.so libmariadb.so.3 plugin
I’ve left out the irrelevant stuff. The point is, only one .so name is there. So usually you’ll have no trouble linking to libmariadbclient.so but it’s not guaranteed any more.
The server can display the .so
To see this you’ll have to run the server with performance_schema on, which is the default for MySQL but not for MariaDB, you’ll have to ask for it.
Example pasted from an ocelotgui session:

Notice the name and the version number. But if the library was statically linked, and not an .so, this won’t tell you.
mysql_config can display the .so path
For example,
$ bin/mysql_config --libs
-L/home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/lib
-Wl,-R,/home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/lib
-L/home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/lib/private
-Wl,-R,/home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/lib/private
-lmysqlclient -lpthread -ldl -lssl -lcrypto -lresolv -lm -lrt
And mariadb_config would do something similar. It is correct on my machine that the first specified directory indeed contains libmysqlclient.so.
If you follow MySQL’s instructions exactly in section “Building C API Client Programs” this is what you can expect.
But if the client program chooses a different path, this won’t tell you.
Linux utilities can display the .so and the .so path
As well as the programs that come with MySQL or MariaDB that show .so files, there are programs that come with Linux that show .so files. They work with any MySQL or MariaDB executable, but in this section I’ll show examples with common utilities instead because they’re shorter.
I admit that I’m depending on common Linux and ELF format for the examples, if it had to be general I’d perhaps think that libbfd would help me, but I’ve never seen the need.
FIND!
Of course one of the programs is the simple
sudo find / -name “libmy*.so*”
or
sudo find / -name “libmaria*.so*”
but it takes too long and it doesn’t show the files in the context of the caller. So the value is small.
LD!
For example
ld –verbose | grep SEARCH_DIR
SEARCH_DIR("=/usr/local/lib/x86_64-linux-gnu"); SEARCH_DIR("=/lib/x86_64-linux-gnu");
SEARCH_DIR("=/usr/lib/x86_64-linux-gnu"); SEARCH_DIR("=/usr/lib/x86_64-linux-gnu64");
SEARCH_DIR("=/usr/local/lib64"); SEARCH_DIR("=/lib64"); SEARCH_DIR("=/usr/lib64");
SEARCH_DIR("=/usr/local/lib"); SEARCH_DIR("=/lib"); SEARCH_DIR("=/usr/lib");
SEARCH_DIR("=/usr/x86_64-linux-gnu/lib64"); SEARCH_DIR("=/usr/x86_64-linux-gnu/lib");
… These are some standard system paths that ld the GNU linker will look at on a multiarch machine. But they are not necessarily what the dynamic loader will look at so the value is small.
LDD!
For example
$ ldd ./mysql
linux-vdso.so.1 (0x00007fffd2772000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f23b3b8b000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f23b3b85000)
libssl.so.3 => /home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/bin/./../lib/private/libssl.so.3 (0x00007f23b38dd000)
libcrypto.so.3 => /home/pgulutzan/mysql-8.3.0-linux-glibc2.28-x86_64/bin/./../lib/private/libcrypto.so.3 (0x00007f23b32a5000)
libresolv.so.2 => /lib/x86_64-linux-gnu/libresolv.so.2 (0x00007f23b3289000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f23b327f000)
libncurses.so.6 => /lib/x86_64-linux-gnu/libncurses.so.6 (0x00007f23b3254000)
libtinfo.so.6 => /lib/x86_64-linux-gnu/libtinfo.so.6 (0x00007f23b3224000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007f23b3042000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f23b2ef3000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f23b2ed8000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f23b2ce6000)
/lib64/ld-linux-x86-64.so.2 (0x00007f23b3bcc000)
Most utilities have a man page like this one.
STRACE!
For example, if you have ocelotgui,
strace ocelotgui 2>/dev/stdout| grep openat
will display
openat(AT_FDCWD, "/usr/mysql/lib/tls/x86_64/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/tls/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/tls/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/tls/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/x86_64/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/mysql/lib/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/lib/tls/x86_64/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/usr/lib/tls/x86_64/libdl.so.2", O_RDONLY|O_CLOEXEC) = -1 ENOENT (No such file or directory)
… And so on, for failed attempts to open .so files. The failures are expected, by the way. Subdirectory tls (thread local storage) tends to be absent.
LTRACE!
Example:
$ ltrace cp
strrchr("cp", '/') = nil
setlocale(LC_ALL, "") = "/usr/share/locale"
textdomain("coreutils") = "coreutils"
__cxa_atexit(0x560a7dde6ce0, 0, 0x560a7ddfe008, 0x736c6974756572) = 0
is_selinux_enabled(0x478e4b21b3007f54, 0x7fd612321ca0, 32, 0) 0
geteuid() = 1000
getenv("POSIXLY_CORRECT") = nil
… and so on for all the system calls that cp makes till it’s done. This could find calls that open libraries but the value is small.
READELF!
For example:
$ readelf -a /usr/bin/mariadb | grep NEEDED
0x0000000000000001 (NEEDED) Shared library: [libreadline.so.5]
0x0000000000000001 (NEEDED) Shared library: [libncurses.so.6]
0x0000000000000001 (NEEDED) Shared library: [libtinfo.so.6]
0x0000000000000001 (NEEDED) Shared library: [libpthread.so.0]
0x0000000000000001 (NEEDED) Shared library: [libssl.so.1.1]
0x0000000000000001 (NEEDED) Shared library: [libcrypto.so.1.1]
0x0000000000000001 (NEEDED) Shared library: [libz.so.1]
0x0000000000000001 (NEEDED) Shared library: [libdl.so.2]
0x0000000000000001 (NEEDED) Shared library: [libstdc++.so.6]
0x0000000000000001 (NEEDED) Shared library: [libc.so.6]
(Remember the MariaDB library is statically linked so it doesn’t appear here.)
OBJDUMP!
For example:
$ objdump -p /usr/bin/mariadb | grep NEEDED
NEEDED libreadline.so.5
NEEDED libncurses.so.6
NEEDED libtinfo.so.6
NEEDED libpthread.so.0
NEEDED libssl.so.1.1
NEEDED libcrypto.so.1.1
NEEDED libz.so.1
NEEDED libdl.so.2
NEEDED libstdc++.so.6
NEEDED libc.so.6
This objdump list is the same as the readelf list. You can read stories like readelf vs. objdump: why are both needed to know you don’t need both.
LD_DEBUG!
Now for examples I’ll need any program that happens to use the dynamic loader, /bin/cp will do.
Start with the readelf utility to see what a program’s dynamic loader is.
Example:
$readelf -l /bin/cp | grep interpreter
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
Okay, in this case the dynamic loader is /lib64/ld-linux-x86-64.so.2. (The same name appears in the earlier ldd example above but I think that’s undependable.) It differs depending on the platform and the program, so always check.
First make sure that all LD_ environment variables are unset. Then:
LD_DEBUG=libs /lib64/ld-linux-x86-64.so.2 –inhibit-cache /bin/cp 2>/dev/stdout | grep search
You’ll see something like
28805: find library=libselinux.so.1 [0]; searching
28805: search path=/lib/x86_64-linux-gnu/tls/x86_64/x86_64:
/lib/x86_64-linux-gnu/tls/x86_64:/lib/x86_64-linux-gnu/tls/x86_64:
/lib/x86_64-linux-gnu/tls:/lib/x86_64-linux-gnu/x86_64/x86_64:/lib/x86_64-linux-gnu/x86_64:
/lib/x86_64-linux-gnu/x86_64:/lib/x86_64-linux-gnu:
/usr/lib/x86_64-linux-gnu/tls/x86_64/x86_64:/usr/lib/x86_64-linux-gnu/tls/x86_64:
/usr/lib/x86_64-linux-gnu/tls/x86_64:/usr/lib/x86_64-linux-gnu/tls:
/usr/lib/x86_64-linux-gnu/x86_64/x86_64:/usr/lib/x86_64-linux-gnu/x86_64:
/usr/lib/x86_64-linux-gnu/x86_64:/usr/lib/x86_64-linux-gnu:/lib/tls/x86_64/x86_64:
/lib/tls/x86_64:/lib/tls/x86_64:/lib/tls:/lib/x86_64/x86_64:/lib/x86_64:/lib/x86_64:
/lib:/usr/lib/tls/x86_64/x86_64:/usr/lib/tls/x86_64:/usr/lib/tls/x86_64:
/usr/lib/tls:/usr/lib/x86_64/x86_64:/usr/lib/x86_64:/usr/lib/x86_64:/usr/lib
(system search path)
… and so on for all the .so files of cp.
LDCONFIG!
For example,
$ /sbin/ldconfig -p | grep -e 'libmysql' -e 'libmaria'
libmysqlclient.so.21 (libc6,x86-64) => /lib/x86_64-linux-gnu/libmysqlclient.so.21
libmarias3.so (libc6,x86-64) => /lib/x86_64-linux-gnu/libmarias3.so
libmariadbd.so.19 (libc6,x86-64) => /lib/x86_64-linux-gnu/libmariadbd.so.19
libmariadbd.so (libc6,x86-64) => /lib/x86_64-linux-gnu/libmariadbd.so
libmariadb.so.3 (libc6,x86-64) => /lib/x86_64-linux-gnu/libmariadb.so.3
libmariadb.so (libc6,x86-64) => /lib/x86_64-linux-gnu/libmariadb.so
liblibmysql_client.so (libc6,x86-64) => /lib/x86_64-linux-gnu/liblibmysql_client.so
Vaguely speaking, sudo make install can change /etc/ld.so.conf and ldconfig can take from /etc/ld.so.conf to the cache and ldconfig -p can show what’s in the cache. This is good for administrator-approved libraries, as opposed to ones that have been installed in a non-system local directory.
DPKG OR WHATPROVIDES!
For example,
$ dpkg -S libmysqlclient.so
libmysqlclient21:amd64: /usr/lib/x86_64-linux-gnu/libmysqlclient.so.21
libmysqlclient18: /usr/lib/x86_64-linux-gnu/libmysqlclient.so.18
libmysqlclient21:amd64: /usr/lib/x86_64-linux-gnu/libmysqlclient.so.21.2.41
libmariadb-dev-compat:amd64: /usr/lib/x86_64-linux-gnu/libmysqlclient.so
The dpkg package manager can be on Debian-based distros. On rpm-based distros the equivalent is whatprovides. This is telling you what is supposed to be there, as opposed to what is actually there.
All of the above utilities are fine for their purposes but I’m after something different — a function I can call to find libraries at runtime, loaded or unloaded. I’ll describe the solution at the end of this blog post.
There are ways to force the path
The usual dynamic loader (often on /lib64/ld-linux-x86-64.so.2 or /lib/ld-linux.so.2 but read the previous section to check) is going to search in this order:
LD_AUDIT — environment variable
LD_PRELOAD — environment variable
DT_RPATH — set by -Wl non-default option
LD_LIBRARY_PATH — environment variable
DT_RUNPATH — set by -Wl default option or LD_RUN_PATH environment variable during build
ld.so.cache and defaults.
LD_AUDIT: specialized and difficult. I mention it but don’t expect it.
LD_PRELOAD: I’ve seen this recommended for the MySQL or MariaDB server but for clients it’s probably only a good choice if you need to force a specific .so file, as opposed to a specific path containing .so files. Oracle used to suggest this for their drop-in replacement.
DT_RPATH: set before runtime. With gcc the way to force DT_RPATH is
gcc … -Wl,-rpath,,-rpath,<library_path>,-disable-new-dtag
The -disable-new-dtag is necessary nowadays because DT_RPATH is set with the old tag. With the default new tag, -Wl,-rpath sets DT_RUNPATH instead. In other words, you’ll probably never see this.
LD_LIBRARY_PATH: or actually “ld_library_paths” plural, because you can put multiple paths delimited by colons or semicolons.
DT_RUNPATH: set before runtime. With gcc the way to force DT_RUNPATH is
gcc … -Wl,-rpath,<library_path>,-rpath,<library_path>
or
LD_RUN_PATH=<library_path> gcc … but setting the LD_RUN_PATH environment variable has no effect at runtime.
ld.so.cache: This is a list of the .so files that the dynamic loader will look for by default. It’s visible with
ldconfig -r
Typically the list is changed when you sudo make install something, so although ldconfig’s not the top choice it’s the most reliable one. You know that some package installer thought that the .so in this list is an appropriate one.
You’ll notice that DT_RPATH and DT_RUNPATH don’t get in unless they’re specified before runtime. And if you specify them yourself and then try to make a .deb package, lintian will tell you: they’re deprecated. For another package type, SUSE will tell you they’re forbidden. So they don’t matter so much.
Since environment variables do matter so much, it can be a good idea to check whether they’re already set, for example you put something in .bashrc and forgot. The best way to check environment variables is printenv (not echo). To check all the environment variables that start with LD_, say
printenv | grep LD_
Since environment variables matter so much, it can be a good idea to set them in a canonical way. For example, to say you want the dynamic loader to look in /tmp/A and /tmp/B, say
LD_LIBRARY_PATH=/tmp/A:/tmp/B program-name
and to temporarily turn it off, say
env -u LD_LIBRARY_PATH program-name
This is slightly better than
export LD_LIBRARY_PATH=program-name
because export has a permanent effect rather than an effect specific for program-name, and because export can only set the environment variable to blank rather than getting rid of it. Another thing is that the delimiter between path names is a colon — yes a semicolon would work here but it wouldn’t work with -Wl,-rpath and you might as well have the same delimiter in all possible lists. I didn’t surround the path names with ”s or “”s in the example, but if there’s a $ then their absence could cause confusion. For example:
export LD_LIBRARY_PATH=/$LIB
printenv LD_LIBRARY_PATH
… You’ll see only the / character, because $ is a signal that an environment variable name follows, unless it’s quoted or escaped.
$LIB and $PLATFORM and $ORIGIN
The dynamic loader will replace occurrences of $LIB or $PLATFORM or $ORIGIN within path names.
$LIB: According to a “Linux manual page” and according to
man ld.so
on my computer, “$LIB (or equivalently ${LIB}) This expands to lib or lib64 depending on the architecture (e.g., on x86-64, it expands to lib64 and on x86-32, it expands to lib).”
Hah! Just kidding. Pilot Logic has a page indicating that’s true for what they call “Red Hat Base” and “Mandriva Base” but not for “Debian Base” or “Arch Base” or “Gentoo Base”. (It’s actually the distro’s glibc that’s responsible.) And there might be more differences in the future.
On top of that, if you go back and look at the example of LD_DEBUG use, you’ll see a bunch of /tls (thread local storage) subdirectories. Luckily, although $LIB can expand to include them, they won’t exist.
$PLATFORM: expect something like “x86_64” on Debian-like 64-bit platforms. Hah! Just kidding again. Debian’s “ArchitectureSpecificsMemo” indicates other possibilities.
$ORIGIN: This is supposed to be the path of the program that’s running. I’ve seen complaints that it’s actually the path of the library in the program that’s running, but I haven’t understood the difference. So if you say
/usr/bin/wombat
then the $ORIGIN is /usr/bin. And if you build with
gcc … -Wl,-z,origin,-rpath,./lib,-rpath,\$ORIGIN
that’s what you’ll see — though notice the escaping of the $ here.
How ocelotgui handles it
There’s no reliable way to decide at install time what the client library will be, because the name varies, the location varies, and the appropriate library might depend on the server that ocelotgui is connecting to.
The
CMakeLists.txt for ocelotgui
has, for 64-bit builds,
set(TMP_INSTALL_RPATH "${TMP_INSTALL_RPATH}/usr/mysql/lib:
/usr/lib:/usr/lib/mysql:/usr/local:/usr/local/lib:
/usr/local/lib/mysql:/usr/local/mysql:/usr/local/mysql/lib:
/usr:/usr/lib/x86_64-linux-gnu:/usr/lib64:/usr/lib64/mysql:
/usr/mariadb/lib:/usr/lib/mariadb:/usr/local/lib/mariadb:
/usr/local/mariadb:/usr/local/mariadb/lib:/usr/lib64/mariadb")
which is reasonable.
However, it’s disabled for the .deb or .rpm packages.
By default it looks first for libmysqlclient then libmariadbclient then libmariadb,
but that’s easy to change with command-line options or in the .cfg file.
And if there’s no non-default specification then the standard-loader paths matter.
This means runtime flexibility is required, and that means we have to use dlopen(). Therefore ldd ocelotgui will tell you nothing, but in this case it’s because we’re looking everwhere, which is quite different from the mysql/mariadb client case because they’re bringing in a .a library.
Finally, Help|About and Help|libmysqlclient will say more about what’s actually connected or could be.
The ocelotgui GUI for MySQL and MariaDB is still version 2.5, which means it hasn’t kept up with recent changes of the servers.
There has to be a new version that takes into account the points that I’ve described here. It will incorporate the code of a new github project: pgfindlib.
pgfindlib
I’ve created a small new GitHub project, pgfindlib. It has major advantages over all the things I’ve described in this post, if the objective is to find relevant .so files at runtime, without cruft, from within a program.
I’ll just quote the first bit of its README here:
…
Version 0.9.7
The pgfindlib function finds dynamic libraries (.so files) in the order the loader would find them.
Copyright (c) 2025 by Peter Gulutzan. All rights reserved.
What pgfindlib is good for
Knowing what .so files the loader would load, but loading them yourself with dlopen(), means you can customize at runtime.
Or, as part of –help you can tell users what the loader picked up, and from where, and what choices it ignored.
An example: Using files supplied with the package:
mkdir /tmp/pgfindlib_example
echo "Dummy .so" >> /tmp/pgfindlib_example/libutil.so
gcc -o main main.c pgfindlib.c -Wl,-rpath,/tmp/pgfindlib_example
LD_LIBRARY_PATH='/$LIB' ./main 'where libutil.so, libcurl.so, libgcc_s.so'
The result might look like this:
1,,,002 pgfindlib,001 version 0.9.7,003 https://github.com/pgulutzan/pgfindlib,,
2,,,005 $LIB=lib/x86_64-linux-gnu,006 $PLATFORM=x86_64,007 $ORIGIN=/home/pgulutzan/pgfindlib,,
3,,,012 in source LD_LIBRARY_PATH replaced /$LIB with /lib/x86_64-linux-gnu,,,,
4,/lib/x86_64-linux-gnu/libcurl.so,LD_LIBRARY_PATH,013 symlink,,,,
5,/lib/x86_64-linux-gnu/libcurl.so.4,LD_LIBRARY_PATH,013 symlink,,,,
6,/lib/x86_64-linux-gnu/libcurl.so.4.6.0,LD_LIBRARY_PATH,,,,,
7,/lib/x86_64-linux-gnu/libgcc_s.so.1,LD_LIBRARY_PATH,,,,,
8,/lib/x86_64-linux-gnu/libutil.so,LD_LIBRARY_PATH,013 symlink,,,,
9,/lib/x86_64-linux-gnu/libutil.so.1,LD_LIBRARY_PATH,013 symlink,,,,
10,/tmp/pgfindlib_example/libutil.so,DT_RUNPATH,071 elf read failed,,,,
11,/lib/libgcc_s.so.1,ld.so.cache,,,,,
12,/lib/x86_64-linux-gnu/libcurl.so,ld.so.cache,013 symlink,014 duplicate of 4,,,
13,/lib/x86_64-linux-gnu/libcurl.so.4,ld.so.cache,013 symlink,014 duplicate of 5,,,
14,/lib/x86_64-linux-gnu/libgcc_s.so.1,ld.so.cache,014 duplicate of 7,,,,
15,/lib/x86_64-linux-gnu/libutil.so,ld.so.cache,013 symlink,014 duplicate of 8,,,
16,/lib/x86_64-linux-gnu/libutil.so.1,ld.so.cache,013 symlink,014 duplicate of 9,,,
17,/lib32/libgcc_s.so.1,ld.so.cache,075 elf machine does not match,,,,
18,/lib32/libutil.so.1,ld.so.cache,013 symlink,075 elf machine does not match,,,
19,/lib/libgcc_s.so.1,default_paths,014 duplicate of 11,,,,
20,/usr/lib/libgcc_s.so.1,default_paths,014 duplicate of 11,,,,
rval=0
This means: the loader would look first in /lib/x86_64-linux-gnu because of LD_LIBRARY_PATH. This takes precedence over DT_RUNPATH, which is where the first occurrence of libutil.so appears (this appears because of the -rpath option in the gcc command). Finally there are some .so libraries in ld.so.cache and the system libraries, which is where the loader would go if there was no prior. But some of the lines contain warnings, for example “071 elf read failed” because /tmp/pgfindlib_example/libutil.so is not a loadable file, or for example “075 elf machine does not match” because main is 64-bit and /lib32/libgcc_s.so.1 is 32-bit.
That’s all you need to know in order to decide if you’re interested. If you are, read on, there are many options and a few warnings.
…
Yes, the input is [FROM clause] WHERE clause, the output is table.
Now go over to the pgfindlib repository https://github.com/pgulutzan/pgfindlib and clone it. Since you’ve read all this, you’ll want that.
CREATE PROCEDURE p()
BEGIN
DECLARE v CHAR CHARACTER SET utf8 DEFAULT '';
SELECT * FROM information_schema.routines
WHERE routine_name > v;
END;
CALL p();
Result: with current MariaDB 11.4 or MySQL 8.3: a result set.
Result: with new or future MariaDB: an error message mentioning collations.
The error appears with MariaDB 11.5.1 and later, except for Debian-based distros such as Ubuntu where it appears with MariaDB 11.5.2 and later. It is not a bug, it is a behaviour change.
I’ll describe the error’s cause, the rare situations where the change breaks existing applications, the ways to check, and a workaround.
Assume routine’s character set is Unicode
Let’s say I installed a DBMS and created a UTF8 database. Then I can look at the database’s defaults with
SELECT * FROM information_schema.schemata;
If the server is MySQL 8.3:
The database that I created has default_character_set_name=utf8mb4, default_collation_name = utf8mb4_0900_ai_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
If the server is MariaDB 11.4:
The database that I created has default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
If the server is MariaDB 11.6:
The database that I created has default_character_set_name=utf8mb3, default_collation_name = utf8mb3_uca1400_ai_ci. System databases have default_character_set_name=utf8mb3, default_collation_name = utf8mb3_general_ci.
(A system database is sys, performance_schema, information_schema, or mysql.)
The difference between utf8mb3 and utf8mb4 is usually not important. Maybe bigger is better, but I looked at an admittedly-old stack overflow question which established that the extra characters are mostly Gothic, emoji, new Chinese personal names, and some mathematical symbols. At the moment you can’t create routines which require 4-byte UTF8 anyway which means the effect for system tables is nothing.
The difference between uca_0900 and uca_1400 collations is usually not important. The former refers to Unicode Collation Algorithm Version 9 (2016) the latter refers to Collation Algorithm Version 14 (2021). UCA’s version number is “synchronized with the version of the Unicode Standard which specifies the repertoire covered”, which means the order of new emojis or rarely-used scripts will differ. For example the Unicode-14 release notes mention the bronze-age Cypro-Minoan script, so if you use that, you should care.
However, the difference between latin1 and utf8 is usually so important that — I hope — many people will explicitly declare CHARACTER SET UTF8 or some variant, when creating the database or creating the routine. As the manual says: “If CHARACTER SET and COLLATE are not present, the database character set and collation in effect at routine creation time are used.”
Therefore, “DECLARE v CHAR;” will often mean “DECLARE v CHAR DEFAULT CHARACTER SET utf8;”. I’ll assume that’s the case. That’s what causes the error, since with a latin1 default it won’t happen.
The cause
The error message is due to the enhancement request Change default Unicode collation to uca1400_ai_ci which has explanations from the requester and the MariaDB collation expert about some of the things to watch out for, other than this error message. As well, you can find a condemnation of the non-UCA collations such as utf8mb3_general_ci.
The general collation is not awful, for example it knows that “B with dot above” is equal to B.
However, it sees differences where a Unicode _ai_ci collation does not. For example,
SELECT 'お' COLLATE utf8mb4_general_ci =
'オ' COLLATE utf8mb4_general_ci;
is false.
SELECT 'お' COLLATE uca1400_ai_ci =
'オ' COLLATE utf8mb4_uca1400_ai_ci;
is true.
But this makes it dangerous to change a system table. If the server manufacturer simply declared that the default collation of information_schema is henceforth UCA, then suddenly the indexes are no good and primary keys contain duplicates for people who happen to have created routines or tables with similar names.
Everybody learned their lesson about that from a long-ago fiasco. As I commented about it in a heated bug report in 2011: “Why don’t we just change the rules for utf8_general_ci, instead of introducing new collations with new rules? Well, as a matter of fact, that happened for another rule affecting German Sharp S in our version 5.1. The results were catastrophic, because collation affects order of keys in an index, and when index keys are out of the expected order then searches fail (Bug#37046 etc.). The only solution is to rebuild the index and when we have customers with multiple billion rows that’s hugely inconvenient. This change was a stupid error, we have sworn not to repeat it.”
Check routine for upgrade
This isn’t the same as CHECK TABLE … FOR UPGRADE and I don’t think it can be automated, it depends on humans and their particular situations.
Probably most straightforward upgrades will not cause a change of the default so there will be no immediate effect — until you create a routine which has the same expression as what worked before, which won’t work now.
Watch out for comparisons of variables with any columns in system tables.
Watch out for DECLARE HANDLER statements which could hide the error.
Watch out for CREATE TABLE statements which use the variable as a source because you don’t want to change their collation inadvertently.
Watch out for parameters too, as the passer’s character set might differ from the catcher’s.
Workaround: explicit collation
Add a COLLATE clause.
This will indicate the approved collation, so now the comparison will not cause an error.
That is, change
DECLARE v CHAR; /* assuming UTF8 database or explicit UTF8 at some higher level */
to
DECLARE v CHAR CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci;
But not change
WHERE routine_name > v;
to
WHERE routine_name > v COLLATE utf8mb3_general_ci;
This is a minimal change. It insists on the general collation, rather than a Unicode collation, so it’s compatible with the comparand and is less likely to cause an error and is more likely to cause an indexed search.
The COLLATE in the DECLARE clause usually will not interfere with later statements that contain COLLATE. For example, here is a procedure where there might seem to be a conflict:
CREATE PROCEDURE ae()
BEGIN
DECLARE v CHAR CHARACTER SET utf8mb3
COLLATE utf8mb3_general_ci;
SET v = 'ä';
SELECT coercibility(v);
SELECT coercibility((SELECT max(routine_name
COLLATE utf8mb3_german2_ci)
FROM information_schema.routines));
SELECT * FROM information_schema.routines
WHERE routine_name COLLATE utf8mb3_german2_ci = v;
END;
CALL ae();
The nifty coercibility function will say that v is 2 (implicit) while the routine_name is 0 (explicit),
therefore the WHERE’s COLLATE clause trumps the variable’s COLLATE clause,
therefore there is no error,
therefore ‘ä’ = ‘ae’ is true,
therefore there will be one row in the result set.
The workaround has two flaws.
1. For MariaDB 11.6 there’s a feature request Change default charset from latin1 to utf8mb4 So far I haven’t seen that this has happened. But when it does, CHARACTER SET utf8 COLLATE utf8mb3_general_ci could cause trouble because utf8 won’t mean utf8mb3.
Thus COLLATE utf8mb3_general_ci may not be good for the long term, I actually prefer CAST(operand AS CHAR(n) CHARACTER SET utf8mb4) COLLATE utf8mb4_general_ci as something that can work today and can probably work tomorrow.
2. For MySQL 8.3 (which is obsolete) and a similar procedure that looked at tables, I saw the bizarre error message “Error 1267 (HY000) Illegal mix of collations (utf8mb3_tolower_ci,EXPLICIT) and (utf8mb4_0900_ai_ci,EXPLICIT) for operation ‘='” which must have been a bug since there’s no such thing as utf8mb3_tolower_ci, and it doesn’t happen for MySQL 8.4.
3. It’s extra trouble for something that you don’t need in legacy MariaDB versions. To which you might be saying, “Duh, Peter, just use MariaDB’s Executable Comment Syntax to suppress the unneeded stuff when the server isn’t the latest. Well, yes, but I don’t use non-standard syntax if I don’t have to.
Thanks to Alexander Barkov for a suggestion.
How this affected me
The ocelotgui (GUI for MySQL and MariaDB) contains a debugger for stored procedures and functions. It contains DECLARE … CHAR CHARACTER SET utf8; many times. This behaviour change broke it. This commit on GitHub shows my own workaround for it. It did not go through testing with the 11.6 preview. Yesterday I included it in the latest release.
But should the GUI warn about this when parsing CREATE PROCEDURE statements? If anyone thinks so, they can submit a bug report / feature request.
Read The language rules we know – but don’t know we know which says “Adjectives in English absolutely have to be in this order: opinion-size-age-shape-colour-origin-material-purpose Noun.” Then you’ll know this is correct:
CREATE TABLE little_girls (
grade FLOAT, height SMALLINT, birth DATE, fatness BLOB,
hair SET('blond','black'), previous_school VARCHAR(64),
is_made_of_sugar_and_spice_and_everything_nice BOOL,
reason_for_existence TEXT DEFAULT 'thank heaven');
because columns are attributes and so are adjectives.
Now I’ll tell you the other factors that affect whether chicken columns precede egg columns.
Primary key columns first
As the Oracle “Ask Tom” guy said unenthusiastically in 2012: “For example – most people – pretty much all people – would put the primary key FIRST in the table. It is a universally accepted approach – convention.” Sometimes this is part of a “rule of thumb”. Sometimes it’s part of “logical data modeling standards”. Sometimes it’s part of “business rules”.
I’ve even seen an “automated analysis of database design” tool that marks you down if you put the primary key somewhere else.
General before specific
The United States Postal Service says “Automated mail processing machines read addresses on mailpieces from the bottom up and will first look for a city, state, and ZIP Code.” because those folks know that what matters first is the larger area and what matters last is the street spot.
That’s also what people care about so often they’ll say
genus before species,
or schema name before object name,
or test type before test result.
Specificity is not the same as uniqueness — there might be more addresses “100 Main Street” then there are states in the USA. But it is about moving from the target to the bullseye. Unique-first might be an advantage for CREATE INDEX, but not for CREATE TABLE. And that might mean you might want to say CREATE TABLE t (column1, column2 PRIMARY KEY (column2, column1)) but it does not mean you want to reverse the order of display.
Surname first
Looking at the States stats again, there are about 5 million occurrences of the most common given name (James) and about 2.5 million occurrences of the most common last name (Smith). That’s anecdotal but corresponds to the general belief that last names are uniquer than first names. What matters more is that the name James is less useful for identification, and therefore less important.
Alphabetical
If you’ve ever heard “Choose one from column A and one from Column B” you’ll feel this isn’t quite absurd, and if you’ve got 26 columns named column_a through column_z then you’ll appreciate it if there’s an arbitrary-but-familiar way to glance through them.
And in fact it’s not arbitrary if your column names have prefixes that indicate what group they belong to. Surely user_name and user_address belong together, or if it’s the address suffix that matters more then alphabetical DESC would work though I’ve never seen it proposed.
Important before trivial
There’s advice that columns should appear in order of importance, and if users don’t know what’s important then there are clues.
Is the value usually the same or usually NULL? Then it carries little information.
Is the column name absent from most SELECT statements? Then most people don’t care.
Is it indexed, or unique, or in a foreign key? Then somebody has already decided it matters. Accept that and bump them closer to the start.
What matters for SELECT * is:
the columns that you like most should be on the left of the screen (even if you’re Arab) so you don’t need to use horizontal scrolling.
What matters for SELECT column_x is:
if the row is so big that it might stretch over two blocks, the DBMS might be happier if the column is in the first block.
The ancient wisdom
There’s a rule that I’ve seen often, with occasional variations:
“Primary key columns first.
Foreign key columns next.
Frequently searched columns next.
Frequently updated columns later.
Nullable columns last.
Least used nullable columns after more frequently used nullable columns.
Blobs in own table with few other columns.”
What I’ve seen much less often is a link to what appears to be the first occurrence: https://community.hpe.com/t5/operating-system-hp-ux/oracle-columns/td-p/2840825. It’s from 2002 and it’s in response to a question about Oracle.
So, for example, if your DBMS happens to be one that doesn’t store NULLs if they’re the last things in the row, then that’s good advice. If on the other hand your DBMS happens to be one that has a preface of bits indicating whether the column is NULL, then it’s pointless. Documentation about this might for one InnoDB case be slightly misleading; however, my point is that most of those items will depend on your DBMS and the clauses that you use for a storage engine.
Nevertheless I’ll endorse the “NULLs last” tip because I’ve seen an old claim that it affects SQL Server too. That is, if it’s been a rule for more than one DBMS, even if it’s pointless, maybe it affects compatibility because others still think it’s real.
Old SQL Server rules, for what they’re worth, also include “fixed fields first” and “short before long” but they’re obsolete. Also if you’ve got InnoDB’s compact format then lengths of variable columns are in the header. So when you see claims that you have to journey through the varchar columns till you reach the char columns, be skeptical.
Autocompletion
Suppose in the past you said
CREATE TABLE n (s1 INT, s2 INT);
and now (after rehash) you start an INSERT statement:
INSERT INTO n (
at this point the ocelotgui autocompleter will present you with a hint and you can save a fraction of a second by selecting the first item so you don’t have to navigate.
Unfortunately you won’t save anything when the statement is SELECT, though, because the SELECT list comes before the FROM clause. That is, the GUI won’t know what table you’re using until you’ve already specified the columns.
Speaking of irritating design, I take this opportunity to mention the syntax:
INSTALL PLUGIN plugin_name SONAME 'plugin_library';
Notice again how the GUI can’t hint about a name at the appropriate point, because it won’t know the library yet. I class this as a violation by the vendor of the advice “general before specific”.
Compression
If there is a “run” of bytes with the same value, then a “run-length encoding” (RLE) algorithm might save space. Thus if if it is likely that 20 columns will all contain 0, then keeping them together is a good idea.
But it’s only an idea. The practical considerations are that (a) there’s no compression (b) the typical compression is some variant of Lempel-Ziv which wouldn’t require the columns to be exactly contiguous, (c) it’s hard to predict what algorithms and byte placements will actually save the most space without trying them all (d) they’re not all available unless you build from source.
Consistency
Consistency between tables: if table #1 has columns in a particular order, then table #2 should too. Imitate the INFORMATION_SCHEMA tables because they are likely to be static, although the collations of string columns are likely to change. I’d add “imitate examples in the manual”, but only if the examples in the manual are themselves consistent. For example the MySQL manual example
CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
has no explicit primary key, but the columns might be in order of importance and the final column is the one most likely to contain NULL. For example the MariaDB manual example
CREATE TABLE test.accounts (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(25),
last_name VARCHAR(25),
email VARCHAR(100),
amount DECIMAL(15,2) CHECK (amount >= 0.0),
UNIQUE (email)
) ENGINE=InnoDB;
has the PRIMARY KEY clause mixed in the column definition but the UNIQUE clause outside the column definition, and has first name before surname.
Consistency between statements: if WHERE clauses often have WHERE a = 5 AND b = 6, or if ORDER BY clauses often have A, B ASC, or if INSERT statements often have (a, b), then the CREATE TABLE definition can serve as a guide by letting users know that a comes before b by design.
Consistency between definitions: if table #1 has one foreign key referencing table #X and then another foreign key referencing table #Y, and table #2 has one foreign key referencing table #y and then another foreign key referencing table #X, then ask yourself why the order of foreign keys in table #2 is not the same as the order of foreign keys in table #1. Ideally the order will be reflected in entity-relationship diagrams.
ocelotgui changes
The ocelotgui 2.4 release is available for download from github.
The debugger feature won’t work with MariaDB 11.5ff for reasons I’ll explain elsewhere. However, if you download the source and build, it will work. Or wait for ocelotgui 2.5 which (I hope) will be released soon.
Progress Software on 2024-04-19 said more about “considering” an offer for MariaDB plc (the company not the foundation).
They own NuSphere which had a dispute with MySQL AB which was settled in 2002. My happy history as a MySQL employee biases me but I thought that NuSphere was not acting angelically.
I think it won’t happen.
Update: Apparently it didn’t. The 2024-04-26 K1 recommended offer differed.
Here’s a snippet of what I’d like SHOW ENGINE INNODB STATUS to look like:
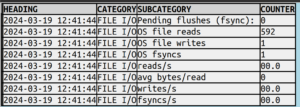
as opposed to what the server sends:
...
--------
FILE I/O
--------
Pending flushes (fsync): 0
295 OS file reads, 1 OS file writes, 1 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
...
In my last post I described a way to
Make SHOW as good as SELECT”
which was possible because most result sets from SHOW etc. are at least table-like, but
STATUS’s wall of text isn’t table-like. So I forced it into a table with these basic rules:
- A line inside ——s, like FILE I/O, is the category of what follows.
- Otherwise a line is a row but if it contains commas it is multiple rows.
- Numbers can usually be extracted from text as different columns..
After that there’s still a bunch of fiddling, I put the details in source-code comments.
Version 2.3
The new features related to SHOW etc. are now in a released version as well as in source code,
downloadable from github.
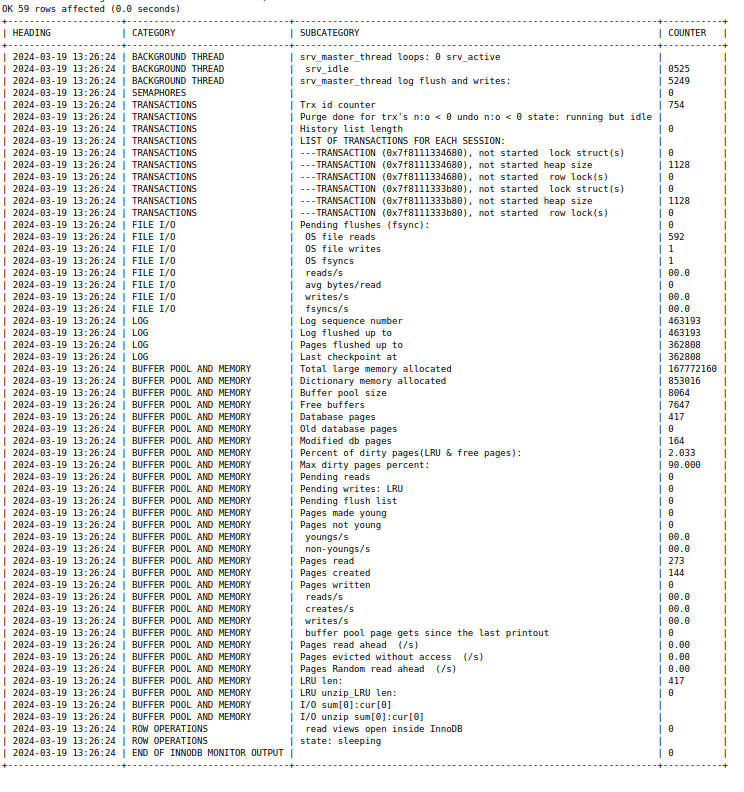
In the rest of this post I’ll show a complete result from SHOW ENGINE INNODB STATUS; (“before”),
and the same data from SHOW ENGINE INNODB STATUS WHERE 1 > 0; after ocelot_statement_syntax_checker
has been set to ‘7’ (“after”). (Instead of copying the Grid Widget I copied from the History Widget
after setting Max Row Count to 100.)
“before”
| InnoDB | |
=====================================
2024-03-19 12:39:45 0x7f80f01f3700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 43 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 0 srv_active, 2455 srv_idle
srv_master_thread log flush and writes: 2454
----------
SEMAPHORES
----------
------------
TRANSACTIONS
------------
Trx id counter 754
Purge done for trx's n:o < 0 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION (0x7f8111334680), not started
0 lock struct(s), heap size 1128, 0 row lock(s)
---TRANSACTION (0x7f8111333b80), not started
0 lock struct(s), heap size 1128, 0 row lock(s)
--------
FILE I/O
--------
Pending flushes (fsync): 0
295 OS file reads, 1 OS file writes, 1 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
---
LOG
---
Log sequence number 463193
Log flushed up to 463193
Pages flushed up to 362808
Last checkpoint at 362808
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 167772160
Dictionary memory allocated 853016
Buffer pool size 8064
Free buffers 7647
Database pages 417
Old database pages 0
Modified db pages 164
Percent of dirty pages(LRU & free pages): 2.033
Max dirty pages percent: 90.000
Pending reads 0
Pending writes: LRU 0, flush list 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 273, created 144, written 0
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 417, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 read views open inside InnoDB
state: sleeping
----------------------------
END OF INNODB MONITOR OUTPUT
============================
|
“after”
/
For example, this works:
SHOW AUTHORS GROUP BY `Location` INTO OUTFILE 'tmp.txt';
You’re thinking “Hold it, MySQL and MariaDB won’t allow SHOW (and similar statements like ANALYZE or CHECK or CHECKSUM or DESCRIBE or EXPLAIN or HELP) to work with the same clauses as SELECT, or in the same places.” You’re right — but they work anyway. “Eppur si muove”, as Galileo maybe didn’t say.
I’ll explain that the Ocelot GUI client transforms the queries so that this is transparent, that is, the user types such things where SELECTs would work, and gets result sets the same way that SELECT would do them.
Flaws and workarounds
I’ll call these statements “semiselects” because they do what a SELECT does — they produce result sets — but they can’t be used where SELECT can be used — no subqueries, no GROUP BY or ORDER BY or INTO clauses, no way to way to choose particular columns and use them in expressions.
There are three workarounds …
You can select from a system table, such as sys or information_schema or performance_schema if available and if you have the privileges and if their information corresponds to what the semiselect produces.
For the semiselects that allow WHERE clauses, you can use the bizarre “:=” assignment operator, such as
SHOW COLUMNS IN table_name WHERE (@field:=`Field`) > '';
and now @field will have one of the field values.
You can get the result set into a log file or copy-paste it, then write or acquire a program that parses, for example by extracting what’s between |s in a typical ASCII-decorated display.
Those three workarounds can be good solutions, I’m not going to quibble about their merits. I’m just going to present a method that’s not a workaround at all. You just put the semiselect where you’d ordinarily put a SELECT. It involves no extra privileges or globals or file IO.
Example statements
CHECK TABLE c1, m WHERE `Msg_text` <> 'OK';
SELECT * FROM (DESCRIBE information_schema.tables) AS x ORDER BY 1;
SHOW COLLATION ORDER BY `Id` INTO OUTFILE 'tmp.txt';
SELECT `Type` FROM (SHOW COLUMNS IN Employees) AS x GROUP BY `Type`;
SELECT UPPER(`Name`) from (SHOW Contributors) as x;
SHOW ENGINES ORDER BY `Engine`;
(SELECT `Name` FROM (SHOW CONTRIBUTORS) AS x
UNION ALL SELECT `Name` FROM (SHOW AUTHORS) AS y)
ORDER BY 1;
CREATE TABLE engines AS SHOW ENGINES;
How does this work?
The client has to see where the semiselects are within the statement. That is easy, any client that can parse SQL can do it.
The client passes each semiselect to the server, and gets back a result, which ordinarily contains field names and values.
The client changes the field names and values to SELECTs, e.g. for SHOW CONTRIBUTORS the first row is
(SELECT 'Alibaba Cloud' AS `Name`, 'https://www.alibabacloud.com' AS `Location`, 'Platinum Sponsor of the MariaDB Foundation' AS `Comment")
and that gets UNION ALLed with the second row, and so on.
The client passes this SELECT to the server, and gets back a result as a select result set.
Or, in summary, what the client must do is: Pass the SHOW to the server, intercept the result, convert to a tabular form, send or SELECT … UNION ALL SELECT …; to the server, display.
However, these steps are all hidden. the user doesn’t have to care how it works.
Limitations
It requires two trips to the server instead of one. The client log will only show the semiselect, but the server sees the SELECT UNION too.
It will not work inside routines. You will have to CREATE TEMPORARY TABLE AS semiselect; before invoking a routine, in order to use the semiselect’s result set inside CREATE FUNCTION | PROCEDURE | TRIGGER.
Speaking of CREATE TEMPORARY TABLE AS semiselect, if there are VARCHAR columns, they will only be as big as the largest item in the result set.
It will not work inside CREATE VIEW.
Sometimes it will not work with nesting, that is semiselects within semiselects might not be allowed.
Some rare situations will expose the SELECT result in very long column names.
Try it today if you can build from source
On Linux this is easy — download libraries that ocelotgui needs, download ocelotgui, cmake, make. (On Windows it’s not as easy, sorry.) The source, and the README instructions for building, are on github.
After you’ve started up ocelotgui and connected to a MySQL or MariaDB server, there is one preparatory step: you have to enable the feature. (It’s not default because these aren’t standard SQL statements.) You can do this by going to the Settings|Statement menu and changing the Syntax Checker value to 7 and clicking OK. Or you can enter the statement
SET OCELOT_STATEMENT_SYNTAX_CHECKER = '7';
Now the feature is enabled and you can try all the examples I’ve given. You’ll see that they all work.
Of course it’s made available this way because the status is beta.
Try it a bit later if you can’t build from source
This will be available in executable form in the next release of ocelotgui, real soon now. If you have a github account, you can go to the github page and click Watch to keep track of updates.
Update: the release happened on 2024-03-18, source and executables are at https://github.com/ocelot-inc/ocelotgui.
MariaDB 11.4 has a new feature: CREATE PACKAGE with routine syntax for the default mode as opposed to sql_mode=’Oracle’. It’s a well-written and long-desired feature but, since it’s alpha, a few things might still need change. I’ll say how it works, with details that aren’t in the manual and probably never will be.
The point
A package is a group of routines (procedures or functions) for which I can CREATE and GRANT and DROP as a unit, all at once.
Roland Bouman wrote a feature request for it in 2005 for MySQL, but MySQL hasn’t got it yet, the workaround is to create whole databases. MariaDB has had CREATE PACKAGE since version 10.3 but only when sql_mode=’oracle’, and only with Oracle syntax (“PL/SQL”) for defining the routines.
Now MariaDB has CREATE PACKAGE with the default sql_mode, i.e. anything except sql_mode=’oracle’, and with ordinary standard-like syntax (“SQL/PSM”) for defining the routines. But it’s a bit of a hybrid because, although the routine definitions within the package are SQL/PSM, the CREATE PACKAGE statements themselves are not.
Package versus Module
CREATE PACKAGE is a PL/SQL statement. CREATE MODULE is the SQL/PSM statement for something functionally very similar.
Here I compare the way MariaDB creates packages versus the way the standard prescribes for modules. I ignore trivial clauses that appear in most CREATE statements.
The MariaDB way
+------------------------------------------------------------+
| CREATE PACKAGE package_name |
| [ COMMENT or SQL SECURITY clause ... ] |
| [ FUNCTION | PROCEDURE name + COMMENT or SQL clauses ... ] |
| END |
+------------------------------------------------------------+
+-------------------------------+
| CREATE PACKAGE BODY |
| [ variable declaration ... ] |
| | routine definition ... ] |
| END |
+-------------------------------+
The standard way
+-------------------------------------+
| CREATE MODULE module_name |
| [ NAMES ARE character_set_name ] |
[ [ SCHEMA default_schema_name ] |
[ [ path specification ] |
| [ temporary table declaration ... ] |
| [DECLARE] routine-definition; ... ]
| END MODULE |
+-------------------------------------+
The most prominent vendor with CREATE PACKAGE is of course Oracle, but others, for example PostgreSQL and IBM, have it too.
The most prominent vendor with CREATE MODULE is IBM but Mimer has it too.
The basic example
So the absolute smallest example of statements that have all the relevant features is:
CREATE PACKAGE pkg1
PROCEDURE p1();
FUNCTION f1() RETURNS INT;
END;
CREATE PACKAGE BODY pkg1
DECLARE var1 INT;
FUNCTION f1() RETURNS INT RETURN var1;
PROCEDURE p1() SELECT f1();
SET var1=1;
END;
SELECT pkg1.f1();
CALL pkg1.p1();
SHOW CREATE PACKAGE pkg1;
SHOW CREATE PACKAGE BODY pkg1;
GRANT EXECUTE ON PACKAGE db.pkg TO PUBLIC;
DROP PACKAGE pkg1;
Documentation and Terminology
In the Canadian Football League there used to be an official term “non-import” for a player who, essentially, wasn’t from the States or Europe or Samoa etc. This caused some complaint because there were simpler terms, like, um, “Canadian” or “national” i.e. native.
Eventually the League realized that adding “non-” was being negative about the default player situation.
I was reminded of that when reading the MariaDB manual, which now has split up the sections for CREATE PACKAGE and CREATE PACKAGE BODY to put “Oracle mode” and “non-Oracle mode”. I am hopeful that someday MariaDB, like the Canadian Football League, will come up with a less negative term such as “default”, or “when sql_mode is the default”. Also I am hopeful — here I speak as the former head of documentation for MySQL — that there will be rearrangement so that the default is shown first, as it will be more important than sql_mode=’oracle’, won’t it?
Another change will happen soon — perhaps by the time you read this — to the BNF. Currently it is
CREATE
[ OR REPLACE]
[DEFINER = { user | CURRENT_USER | role | CURRENT_ROLE }]
PACKAGE [ IF NOT EXISTS ]
[ db_name . ] package_name
[ package_characteristic ... ]
[ package_specification_element ... ]
END [ package_name ]
… which is wrong, adding [ package_name ] after END will just cause an error.
And later
package_specification_function:
func_name [ ( func_param [, func_param]... ) ]
RETURN func_return_type
[ package_routine_characteristic... ]
… which is wrong, it should be RETURNS not RETURN.
Also, since CREATE FUNCTION documentation says “RETURNS type” not “RETURNS func_return_type”, there’s no need to introduce a new term here.
As for CREATE PACKAGE BODY the default mode BNF is undocumented, only Oracle mode BNF is documented. So my description above might be missing some detail, for example maybe it’s possible somehow to declare package-wide cursors and handlers as well as variables.
Error messages
I see two package-related error messages in sql/share/errmsg-utf8.txt
"Subroutine '%-.192s' is declared in the package specification but is not defined in the package body"
and
"Subroutine '%-.192s' has a forward declaration but is not defined"
… which is wrong, there is no such thing as a subroutine, the term is “routine”. (Oracle has a thing called “subprogram” but it too would be a wrong term.)
After I create a package named pkg6 with a procedure p1, if I say
DROP PROCEDURE pkg6.p1;
I get told “PROCEDURE pkg6.p1 does not exist”.
… which is wrong, pkg6.p1 does exist, I can CALL it. It would be better to re-use the message “The used command is not allowed with this MariaDB version”. (Yes, it’s a statement not a command, but I can’t ask for the moon.)
If I say
GRANT EXECUTE ON PACKAGE no_such_package TO PUBLIC;
I get told “FUNCTION or PROCEDURE no_such_package does not exist”
which is wrong, I’m trying to grant on a nonexistent package not a nonexistent routine.
Qualifiers
Suppose we have a package named pkg containing a procedure p1. “CALL p1();” is legal inside another routine in the same package, but outside the package we have to add a qualifier: “CALL pkg.p1();”.
Here is an example that shows why this is dangerous. (Delimiters added so mysql client understands.)
DROP DATABASE pkg;
DROP PACKAGE pkg;
CREATE DATABASE pkg;
CREATE PROCEDURE pkg.p1()
SELECT 'database';
CALL pkg.p1();
DELIMITER $
CREATE PACKAGE pkg PROCEDURE p1(); END;
$
DELIMITER ;
DELIMITER $
CREATE PACKAGE BODY PKG PROCEDURE p1()
SELECT 'package'; END;
$
DELIMITER ;
CALL pkg.p1();
…
The first “CALL pkg.p1();” will display “database”, the second “CALL pkg.p1();” will display “package”. The package has shadowed the database!
People can avoid the danger by adopting a naming convention that database names and package names will always have different prefixes, but they won’t.
Or people can “fully” qualify the package’s P1 by saying “CALL [database_name.].[package_name.].p1();”. But they cannot “fully” qualify the database’s P1 by saying “CALL [catalog_name.][database_name.]p1();” — you’ll see a CATALOG_NAME column in INFORMATION_SCHEMA tables, but it is useless.
Therefore MariaDB should emit a warning message when there’s ambiguity, or support a different qualifier syntax. I’m hopeful that will happen in some future version.
By the way, Mimer “solves” this by disallowing: “The module name is never used to qualify the name of a routine.” It’s unstated, but I suppose this would mean that no two procedures can have the same name in the same schema, even if they are in different packages of the schema.
Also the standard allows SCHEMA and PATH which might be another way to evade the ambiguity, but it’s not necessary.
Metadata
The obvious question after creation is: how can I see what’s in a package?
SHOW CREATE PACKAGE works. SHOW CREATE PACKAGE BODY works.
SHOW PACKAGE STATUS works. SHOW PACKAGE BODY STATUS works.
But they’re SHOW statements and therefore they’re no good.
In INFORMATION_SCHEMA.ROUTINES the package will appear with routine_type = ‘PACKAGE’ and routine_definition = ‘procedure pkg(); end’.
This is odd because
(a) a package is not a routine
(b) there is no procedure named pkg
(c) the actual routine is not a row in information_schema!
I can dig the routine out of another row that has routine_type = ‘PACKAGE BODY’ but I can do it because I have an SQL parser available, other people would be stalled because the body is a mishmash of routines and contents.
Similar cluttering occurs for mysql.proc, although at least there I see PROCEDURE and FUNCTION entries. Remember that the the ‘body’ field might be blank unless you have appropriate privileges.
The obvious answer, similar to what the standard has, is: put routines in INFORMATION_SCHEMA.ROUTINES, and add a PACKAGE_NAME column. Probably something needs to be added to mysql.proc too. Until that happens, since SHOW is not useful, getting metadata for package routines is awkward.
The answer hasn’t appeared in code yet but I’ll assume that what’s obvious will happen.
Variables
I can declare variables that are accessible from all routines in the package. This is possible in CREATE PACKAGE BODY and alas might soon be in CREATE PACKAGE too, if this is done.
Here is an illustration.
DELIMITER $
CREATE OR REPLACE PACKAGE BODY pkg
-- variable declarations
DECLARE a INT DEFAULT 11;
DECLARE b INT DEFAULT 10;
FUNCTION f1() RETURNS INT
BEGIN
SET a=a-1;
RETURN a;
END;
-- routine declarations
PROCEDURE p1()
BEGIN
SELECT a,f1(),a;
END;
-- package initialization section
SET a=a-b;
END;
$
DELIMITER ;
And the question is: what should “CALL pkg.p1();” display?
If you guessed 1, 0, 0 then good for you, but notice what’s unpleasant here. First: we have a procedure’s variable’s value being changed in a way that the procedure doesn’t see. Second: the value changes between the first time it’s selected and the second time it’s selected, in the same statement.
Now, This won’t startle any experienced person, since MariaDB user variables (the ones whose names start with ‘@’) have always worked that way. But I can’t think of any case where that can happen with a DECLAREd variable, so it might startle people who have only worked with standard-like syntax.
I like globals, but I am just expecting that some people will consider it should be noted in a style guide. One of the suggestions I’ve seen (for Oracle) is that package variables are a way to do “constants”. I must emphasize, though, that I’m only talking about what some people might like in style guides, and I’m recognizing that many more people will see an advantage to sharing dynamic variables.
Private routines
Suppose I say
CREATE PACKAGE pkg12 PROCEDURE p1(); END;
CREATE PACKAGE BODY pkg12
PROCEDURE p0() SELECT 5;
PROCEDURE p1() CALL p0();
END;
CALL pkg12.p1() /* This succeeds */;
CALL pkg12.p0() /* This fails */;
Thus p0 is not in CREATE PACKAGE but p0 is in CREATE PACKAGE BODY. That is legal provided p0 comes before p1 (no forward references please). In this case p1 is a “public” routine — I can CALL pkg12.p1() from outside the package. However, p0 is a “private” routine — I cannot CALL pkg12.p0() from outside the package. I will see “Error 1305 (42000) PROCEDURE pkg12.p0 does not exist”.
Nothing against private, but since pkg12.p0 does exist, I think a message that’s more explicit would help somebody in ages to come. Otherwise, it should be made obvious. Probably a naming convention would be a good way to do that. A comment would not be a good way because many clients, including mysql and ocelotgui, have –skip-comments as a default.
Privileges
To allow CREATE PACKAGE (example);
GRANT CREATE ROUTINE ON w2.* TO k@localhost;
To allow EXECUTE of a package (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost;
This is a good thing, the usual privileges affecting routines will affect packages, as a whole. It’s a bit odd that a qualifier is necessary for GRANT but not for CALL; however.
To allow SHOW CREATE PACKAGE (example):
GRANT EXECUTE ON PACKAGE w2.pkg TO k@localhost;
GRANT ALTER ROUTINE ON PACKAGE w2.pkg TO k@localhost;
This is a strange thing, currently one way to make SHOW CREATE possible is to grant ALTER ROUTINE.
ALTER
MariaDB has eleven ALTER statements, but ALTER PACKAGE is not one of them. Given that Oracle has one, and DB2 has ALTER MODULE, and it’s mentioned in a MariaDB document, I expect this will eventually be added with an excuse of “orthogonality”.
Debugger
The debugger in the Ocelot GUI does not yet work with routines inside packages. However, in a version which will be released soon, the “recognizer” will see MariaDB 11.4 syntax and be able to alert typists about what syntax is expected as they type, the same experience that they get for other statements.
This enhancement is already in the source code, in this patch.
Update
2024-02-15: MariaDB has done some fixes for the documentation matters that I mentioned, and there are plans for others in their bugs database, including: MDEV-33382 Documentation fixes for CREATE PACKAGE and CREATE PACKAGE BODY, MDEV-33384 ALTER PACKAGE [ BODY ] statement, MDEV-33385 Support package routines in metadata view, MDEV-33386 Wrong error message on `GRANT .. ON PACKAGE no_such_package ..`, MDEV-33395 I_S views to list stored packages, MDEV-33399 Package variables return a wrong result when changed inside a function, MDEV-33403 Document stored packages overview, MDEV-33428 Error messages ER_PACKAGE_ROUTINE_* are not good enough. For further developments follow MariaDB’s announcements. Meanwhile ocelotgui 2.2 has appeared which recognizes the new syntax.
Ocelotgui, the Ocelot Graphical User Interface, version 2.1, is now available for download. The principal new feature is the chart modifications described in the last post, Charts. Packages are for Linux or Windows, compatible DBMSs are MySQL or MariaDB or Tarantool. Get description and instructions and clone source from GitHub Code area, or get the release from GitHub Releases area.
SELECT 0,1,2,3,4,5,6,7,8; result can look like this
but should it?
I’ll try to cover here what would be an obvious way to show number columns in charts, or if not obvious then at least simple, or if not obvious or simple then at least understandable, or if none of the above, well, good looking.
The initial part of this description will look a bit like what you see with DB2 magic commands for bar or line or pie charts, but I like to think the later part of this description shows something more sophisticated.
Bars
Start with the most obvious: any group of numbers can be shown as a group of bars.
Should they be horizontal by default? That appears to be the less common choice, A Complete Guide to Bar Charts says “While the vertical bar chart is usually the default …”, ChartJs says “The default for this property is ‘x’ and thus will show vertical bars.”
But a SAS blog 3 reasons to prefer a horizontal bar chart persuaded me because, when we’re a GUI displaying an SQL result set, we usually have more room on the x (width) axis than on the y (height) axis.
Now, as for simpleness: that should mean there’s no extra work or time for exporting, manipulating in a non-SQL environment, learning Python, or even having to think — if the total time including user time is more than a second, that’s a fail. Therefore it has to be possible to get
SELECT 1,2,3;
which ordinarily displays as

to display as
with a shortcut that includes a mnemonic. Therefore hitting Alt+Shift+B should switch immediately to the bar-chart display.
But it can get more complex, and that means users must enter instructions, and the only way to make that simpler is to provide instruction syntax that looks like SQL, thus:
SET ocelot_grid_chart = 'bar vertical';
… since users will know that SET value = literal is the SQL way to assign, and will know that ''s enclose literals, and will know what vertical means. So this is the result and it won’t be surprising:
Another bar-chart variant is stacking, that is, putting 3 values in one bar instead of 3 side-by-side bars. For example
SET ocelot_grid_chart = 'bar stacked';
or
SET ocelot_grid_chart = 'bar vertical stacked';
Lines
Lines are a bit less obvious than bars, because if there’s only one number in the series, they’re meaningless. Nevertheless, there should be a simple way to show a chart. Therefore Alt+Shift+L will cause
x
Maybe, although I suppose everyone has seen this sort of thing before, I should make some terminology notes around now …
X-axis: usually this is the horizontal, with the word “samples”
Y-axis: usually this is the vertical, with the word “values”
Legend: in the upper right corner, with a colour icon and a short indicator
Ticks: the tiny marks along the values, so users can see what the scale is.
For the French terms, see Statistique Canada.
But if users don’t know the terms, that’s fine, they understand the picture anyway.
Pies
Pies are obvious and simple too, all they require is
Alt+Shift+P or
SET ocelot_grid_chart='pie';
and SELECT 1,2,3; will look like this:
Fine. But putting numbers along the x-axis and y-axis wouldn’t be informative, and nobody has figured out what should happen with negative numbers. I think Microsoft Excel would take the absolute value, I think it makes more sense to ignore, but the point is: no solution is intuitive for all, therefore there’s a gotcha, therefore it’s not obvious and simple after all.
Groups
Every illustration so far has been simple, a 3-number series. There’s no complicated decision-making, the algorithm is just “if it’s a number, i.e. any of the data types that the DBMS fits in a general numeric category, it’s in, otherwise it’s out”.
It would follow, then, that
>SELECT 1,2,3,'',4,5,6,'',7,8,9;
would result in this if the setting was for bar charts:
There are three “groups” here, and “groups” is a better word than “series” because GROUP is an SQL-standard term.
Subgroups
Now things get a bit more complex. What makes us decide that every individual numeric-column occurrence should be part of a separate bar or line or pie segment? Answer: nothing does, that’s simple but not really the best for representing some of the typical chart situations.
Take the possibility that all the columns which have something in common are combined. The commonness could be the value. For example
SET ocelot_grid_chart='bar vertical subgroup by value % 3';
SELECT 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15;
That is, the values which are divisible by 3 are together, but distributed across the landscape. Each of the things that are together are usually called “samples” if one uses chart terminology, and that’s why in this illustration the word “samples” appears at the bottom, and each subgroup has a separate colour, which is echoed by the legend.
More usefully, I think, the commonness could be the column_name prefix. The usefulness lies in the fact that users know how to put AS clauses after column names in the select list, so they can determine what the subgroups are. For example
SET ocelot_grid_chart='bar vertical subgroup by left(column_name, 1)';
SELECT 1 AS x_1, 2 AS y_1, 3 AS z_1, 4 AS x_2, 6 AS y_2, 7 AS z_2;
There might be other criteria for deciding how to subgroup, but they’re probably less important. What’s important is that once again the syntax is something any SQL user will understand.
Actually the word that chart-lovers prefer here is “categories”, and “subgroups” isn’t really a word you’ll find in typical SQL, but at the moment I’m thinking it’s “SQL-ish”.
Nulls
Since this is SQL, NULLs exist.
There’s no such thing as obvious when NULL might mean unknown or inapplicable, but this isn’t Oracle so it would be too trite to say NULLs are zeros, at least when it’s possible to hint otherwise. Thus
SET ocelot_grid_chart='bar vertical subgroup by left(column_name, 1)';
SELECT 1 AS m, 2 AS m, 3 AS m, 4 AS o, 5 AS o, NULL AS o;
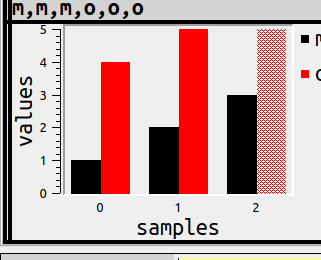
doesn’t use a solid colour, but has the same size as whatever the largest bar is.
I worry that by now we’ve evolved from “obvious” to merely “understandable”, so I’ll explain this example more deeply. In this example there are three samples of ‘m’ and ‘o’. The first sample, label 0, has the first ‘m’ and it has value = 1, the black bar, and it has the first ‘o’ and it has value = 4, the red bar. Sample 1 has the second ‘m’ and the second ‘o’. Sample 2 has the third ‘m’ and ‘o’, and, since the third ‘o’ is NULL, it is not solid. The legend in the right corner is helpful for showing that
black is ‘m’ and red is ‘o’.
WHERE clauses
But surely not every numeric column should always be in a chart? I think of column names that end with ‘_id’, or the possibility that one will want to display both the chart and the numbers as text.
The SQL syntax for deciding what’s in a group could be CASE … WHEN, or IF … THEN, but what even the novice SQL user has seen is WHERE. The condition could be COLUMN_NAME relative-operator value, COLUMN_NUMBER relative-operator value, COLUMN_TYPE relative-operator value. By the way, since this is a GUI, users will see hints for autocompletion when they type WHERE, for example
and after
SET ocelot_grid_chart='bar vertical stacked' WHERE column_type = 'integer';
SELECT 1,1.1,2,7,-44;
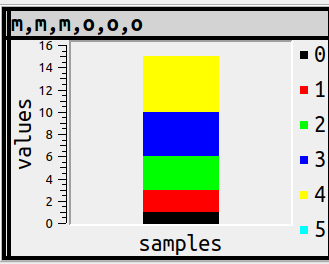
the result will not include 1.1 in a chart because it is not an integer.
And this is where it becomes possible at last to show the statements that caused the example at the start of this post, where some of the columns were in a bar chart, some in a line chart, and some in a pie.
SET ocelot_grid_chart = 'line' WHERE column_number <= 3;
SET ocelot_grid_chart = 'bar' WHERE column_number >= 4 AND column_number <= 6;
SET ocelot_grid_chart = 'pie' WHERE column_number > 6;
SET ocelot_grid_chart = '' WHERE column_number > 100;
SELECT 0,1,2,3,4,5,6,7,8;
and we’ve arrived at the example we started with.
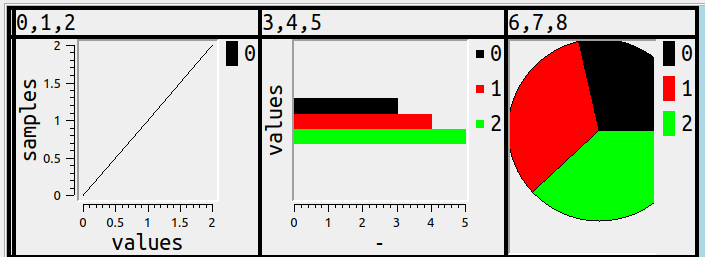
Turning it off
Alt+Shift+N or
SET ocelot_grid_chart='';
will erase all earlier chart statements. So there’s a simple way to go back to the regular way to display results.
Source Code
My main purpose describing all this is to show what the design of a GUI should look like, if my observations about goals make sense.
The illustrations show what the implementation looks like as of today, they’re screenshots of ocelotgui, and they work as I’ve described. But currently they’re only distributed in source code. Anyone who wants to reproduce them today can download the source from github, follow the special build instructions in file chart_options.txt, connect to MySQL or MariaDB or Tarantool, and see the same things. You will notice that you need to use the Qwt library, which should be no problem (ocelotgui is GPLv2, Qwt is LGPL, Qwt is on many distros). Pay no attention to the bug in the room.
But I’m not sure whether to call this the final look for the next executable release. Let me know in the comments if I’m missing tricks.