Client-Side Predictive Parsing of MySQL/MariaDB Grammar
The Ocelot GUI client for MySQL/MariaDB is now beta. The final feature is client-side predictive parsing of every SQL clause and statement. Readers who only care how we did it can skip to the section Recursive Descent Parsers”. I’ll start by illustrating why this is a good feature.
Error Checks
Compare this snapshot from mysql client:

with this from ocelotgui:
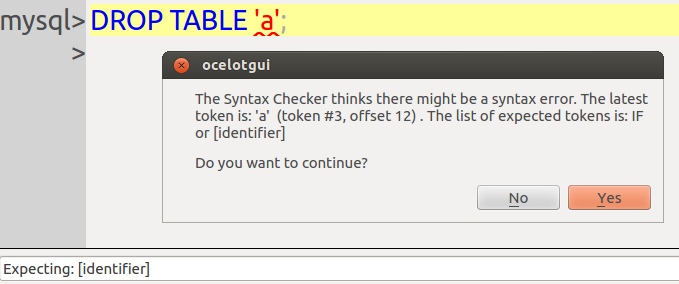
The GUI advantage is that the error message is more clear and the error location is more definite. This is not always true. However, anybody who dislikes the famous message “You have an error …” should like that there is another way to hear the bad news. It’s like getting an extra opinion.
In theory the further advantage is: this saves time on the server, because the client catches the syntax errors. In practice that should not be important, because: (a) ocelotgui is lax and can be erroneous; (b) there are better ways to catch some syntax errors before sending them to the server, for example setting up a test machine.
Finding the end
All respectable clients can scan an SQL statement to find its tokens. For example the mysql client knows that anything enclosed in quote marks, except a pair of quote marks, is a single token. This is pretty well essential, because it has to know whether a semicolon is just part of a string, or is the end of a statement.
Unfortunately a semicolon might not be the end of a compound statement, and that’s where simple “tokenizers” like mysql’s can’t cope. So in my MySQL days we had to come up with the concept of delimiters (I say “we” because I think the hassle of delimiters might have been my idea, but others are welcome to take the credit). It should be clear that a statement like
CREATE PROCEDURE p() BEGIN WHILE 0 = 0 DO ... END WHILE;
is not complete and should not go to the server, so it’s nice that we can say we don’t need delimiters.
But they still can have their uses. The scenario I dread is that a user has a spelling error, causing the client to think that input is complete, and shipping it off to the server prematurely. If there was some symbol that always meant “ship it!” and no other symbol ever meant “ship it!”, that would become unlikely. That’s what delimiters are. But we should have decided on a fixed unchangeable symbol instead of a user-defined one.
Highlighting
All respectable GUIs have highlighting, that is, they can display different colours for literals, operators, or keywords. But most GUIs cannot figure out what is a keyword, unless they ask the MySQL-server’s parser. The SQL problem is that there are two kinds of keywords: reserved words (which are guaranteed to have syntactic meaning if they’re not errors), and ordinary keywords (which might have syntactic meaning but might be identifiers, depending where they appear). An example statement is
CREATE PROCEDURE begin () end: BEGIN END;
where “end” and “begin” are identifiers, but BEGIN and END are not.
(A much easier problem is that you’d need two keyword lists, because in MySQL 5.7 GENERATED and GET and IO_AFTER_GTIDS and IO_BEFORE_GTIDS and MASTER_BIND and STORED and VIRTUAL are reserved words, but in MariaDB they’re not. But, since we don’t think the MariaDB manual’s reserved-word list is correct, we think those are the only reserved-word differences.)
So we have to beware of anything that depends on a list of keywords. For example my favoured editor is a variant of Kate, which recognizes a hodgepodge of symbols in its “SQL Keyword” list, and displays utterly useless highlighting when my file’s extension is .sql. Apparently Vim would be similar. Most clients that claim to work with MySQL or MariaDB are better than editors — they at least use a DBMS-specific keyword list rather than a generic one — and they’re generally good because in a sense they train users not to use keywords as identifiers. For example, if users see that “begin” has a non-identifier colour while they’re typing, they’ll avoid creating objects named “begin” even though it’s not a reserved word.
I’m not sure whether, in the wider SQL world, well known GUI clients have advanced past the keyword-list stage. I see hints here and there that SQL Server Management Studio has not and Toad has not, and Oracle SQL Developer has, but nothing explicit, and I repeat I’m not sure.
(UPDATE 2016-03-28: Mike Lischke’s description of Oracle’s new approach is here.)
In the end, then, a GUI with keyword-list highlighting will be right 90% of the time (I’m just guessing here, but I think it will sound right to experienced readers). On the other hand, a GUI that recognizes grammar should be right 97% of the time, and — just guessing again — I expect that’s preferable.
Predicting
The next step upwards in intelligence is knowing what the next token might be before the user starts typing it, or knowing how the current token ends before the user finishes typing it. And here, if you contemplate the Error Message example that we started with, you might realize: the MySQL/MariaDB server parser can’t do this. Which is why I emphasized right in the title: this is “predictive” parsing.
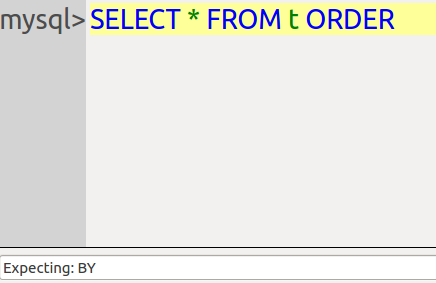
Example 1: suppose you’ve typed SELECT * FROM T ORDER. The GUI will show what the next word must be …
Example 2: suppose you’ve typed CREATE T. The GUI will show what possible words start with T …
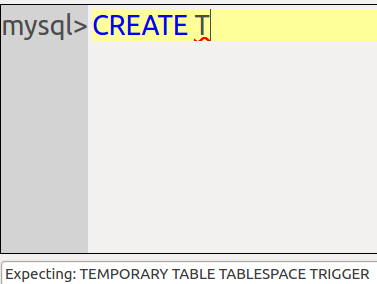
And in either case, hitting the Tab key will save a bit of typing time. I should note that “hitting the Tab key to complete” is something many can do, even the mysql client — but for identifiers not keywords. Technically we can do both, though we prefer to avoid discussing identifiers.
Initial Summary
For error checking, finding the end, highlighting, and predicting: whoopie for predictive parsing of the whole MySQL / MariaDB grammar.
As an additional point, I suppose it’s obvious that we wouldn’t have been able to incorporate a stored-procedure debugger in ocelotgui without parsing. Admittedly it is not using the new parsing code, but it is necessary for it to do a lot more than looking at keywords. So I class debugger capability as the fifth advantage of having client-side parsing.
Recursive Descent Parsers
The algorithms for recursive descent parsers are in most textbooks for compilers, and even in Wikipedia. The “recursive” means that the process can call itself; the rest of the algorithm looks like this:
If (next thing is X) accept it and get the next thing
if (next thing is Y) accept it and get the next thing
if (next thing is Z) accept it and get the next thing
…
else give up and say there’s an error.
Simple, eh?
Now for some quotes from those textbooks for compilers:
“The advantages of recursive descent parsers are that it’s easy to write, and once written, it’s easy to read and understand. The main disadvantage is that it tends to be large and slow.” — Ronald Mak, Writing Compilers And Interpreters, page 810
“The parser text shows an astonishingly direct relationship to the grammar for which it was written. This similarity is one of the great attractions of recursive descent parsing. … In spite of their initial good looks, recursive descent parsers have a number of drawbacks … repeated backtracking … often fails to produce a correct parser [text] … error handling leaves much to be desired.” — Dick Grune, Henri Bal, Ceriel Jacobs, Koen Langendoen, pages 117-119
And they’re right. Have a look at the parsing code of ocelotgui, which can be done by opening a source file here and searching for the first line that begins with “void MainWindow::hparse_f_” (line 9565 in today’s beta). Then scroll downwards till there are no more routines that begin with hparse_f_ — 5000 lines later. Readable, sure, because it’s the simplest of C code. But also tedious, repetitive, and yes, “large and slow”. And this is without knowing anything about object names, since it’s a purely syntactic syntax checker and won’t look at metadata.
On a server the disadvantages could be crippling, but on a client they don’t matter — the meanest laptop has megabytes to spare and the response time is still way faster than a user can blink. And SQL doesn’t require repeated backtracking because it’s rarely necessary to look ahead to the next tokens in order to figure out what the current token means. Here is the worst example that we ran into (I’m quoting the MariaDB 10.1 manual
GRANT role [, role2 ... ] TO grantee [, grantee2 ... ]
which can be instantiated as
GRANT EXECUTE, ROLE55 TO JOE;
See the problem? It’s perfectly okay for EXECUTE to be a role name — it’s not reserved — but typically it’s in statements like GRANT EXECUTE … ON PROCEDURE. So we have to look ahead to find whether ON follows, or whether TO follows. Which we did … and then found out that MariaDB couldn’t. I’d mentioned that this looked tough when I wrote about MariaDB roles two years ago. But for some reason it was attempted anyway and the inevitable bug report has been labelled “stalled” for a long time.
Oh, and one more detail that you’ll find in those compiler textbooks: correctly speaking, ocelotgui has a “recognizer” not a “parser” because it doesn’t generate a tree. That’s why I’ve carefully said it “does parsing” but not said it contains a parser.
Beta Status
The above represents the last feature that we intend to add. It’s at last “ocelotgui beta” rather than “ocelotgui alpha”. The C source and Linux executables, as usual, are at
https://github.com/ocelot-inc/ocelotgui.