What sequences are, who supports them, and why they’re better than GUIDs or auto-increment columns except when they aren’t.
What sequences are
When I say “sequence” I actually mean “sequence generator” because that’s what SQL’s CREATE SEQUENCE statement actually creates. So a sequence is a black box that produces an integer with a guarantee that this integer is greater than the previous integer that it produced, and less than the next integer that it will produce. Thus if I invoke it five times I might get 2, 4, 5, 6, 7. In poker that wouldn’t be considered a sequence because there’s a gap between 2 and 4. We can make sequences with few gaps or no gaps, but they’re expensive.
Sequences are good for generating unique keys, although they’re not the only tool for that.
How they work
This is the minimal scenario with a good DBMS.
An administrator says “create sequence x”, with most things default: start with 1, go up by 1, cache 20.
A user says “get the next value from x”.
The server grabs the numbers between 1 and 20. It writes to a log: “last grab value = 20”. It saves in memory: 1 number is used, 19 remain in the cache. The user gets a number: 1.
A user says “get the next value from x”. The server does not need to grab more numbers or write to a log. It saves in memory: 2 numbers are used, 18 remain in the cache. The user gets a number: 2.
This continues until there are no more numbers left in the cache — at that point the server does another “grab” and another “log write”, then proceeds with a new cache.
Ordinarily the process needs some mutexes but not DBMS locks, although some DBMS vendors like to maintain an in-memory system table that contains the highest value for user convenience. So sequence overhead might be cheap compared to the overhead of maintaining a persistent table with an auto-increment column.
There are two reasons that there will be gaps:
(1) because once a value is retrieved it’s gone, so ROLLBACK won’t cause the sequence generator to put a number back
(2) because a crash can happen any time after the grab, and when the server restarts it will use the last value written to the log, so up to 20 numbers can be left unused. Of course a different cache size would mean a different number of possible unused, or “burnt”, numbers.
Who supports them
In the table below, the left column has pieces of a CREATE SEQUENCE statement, the other columns show which DBMSs support it.
CREATE ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL
[OR REPLACE] DB2 Syb
[ TEMPORARY | TEMP ] Pos
SEQUENCE ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL
[IF NOT EXISTS] Inf Pos
sequence-name ANS DB2 Fir HSQ Inf Ing Ora Pos Syb SQL
[AS data type] ANS DB2 HSQ Ing SQL
[START WITH n] ANS DB2 HSQ Inf Ing Ora Pos Syb SQL
[ INCREMENT BY n ] ANS DB2 HSQ Inf?Ing Ora Pos Syb SQL
[ NO MINVALUE | MINVALUE n ] ANS DB2 Inf Ora Pos Syb SQL
[ NO MAXVALUE | MAXVALUE n ] ANS DB2 Inf Ing Ora Pos Syb SQL
[ NO CYCLE | CYCLE ] ANS DB2 Inf Ing Ora Pos Syb SQL
[ NO CACHE | CACHE n ] DB2 Inf Ing Ora Pos Syb SQL
[ OWNED BY column-name } ] Pos
[ ORDER | NOORDER ] Ora
[ KEEP | NOKEEP ] Ora
[ SESSION | GLOBAL ] Ora
[ SEQUENTIAL | UNORDERED] Ing
ANS = ANSI/ISO 9075-2 (the SQL:2011 standard) with optional feature T176 “external sequence generator”
DB2 = IBM DB2 for LUW
Fir = Firebird
HSQ = HSQLDB
Inf = Informix
Ing = Ingres
Ora = Oracle
Pos = PostgreSQL
Syb = Sybase IQ (not Sybase ASE)
SQL = Microsoft SQL Server
Example statement:
CREATE SEQUENCE x_seq AS DECIMAL(20) START WITH -1000000 CACHE 1000;
The chart doesn’t show some trivial variations, for example some DBMSs allow NOMAXVALUE along with or instead of NO MAXVALUE, and in some DBMSs WITH or n can be optional.
I believe that clauses like START WITH, INCREMENT BY, MIN[IMUM]VALUE have obvious meanings. The truly significant ones are [AS data-type] and CACHE.
[ AS data-type ]: this is the only clause that’s not supported by all three of the Big Three: DB2 and SQL Server have it but Oracle doesn’t. Oracle just says there are up to 28 digits. INTEGER (+ or minus 2 billion) might be enough, but if you do a billion “next value” calculations in a day, you’d run out of numbers in (4294967295 / 1000000000) = 4 days.
[CACHE n]: this is not an ANSI clause because it’s strictly for performance, and for an idea of how important it is I’ll quote IBM developerWorks:
“The main performance issue to be aware of for identity and sequence is that, for recoverability reasons, generated values must be logged. To reduce the log overhead, the values can be pre-reserved (cached), and one log record is written each time the cache is exhausted. … As the results of tests 41-51 in Appendix A show, not having a cache is extremely costly (almost nine times slower than the default).”
NEXT VALUE
The operation for “get next value” is NEXT VALUE FOR sequence-name. Some DBMSs shorten it to NEXTVAL and some DBMSs allow for “getting current value” or “getting previous value” i.e. repeating the NEXT VALUE result. But the main things to know are:
The DBMS increments once per row, not once per time that the DBMS sees “next value”. This is remarkable, because it’s not how a function invocation would work. In this respect PostgreSQL is non-standard, because it will increment every time it sees “next value”.
There is no race-condition danger for “getting current value”. User #1 does not see the number that User #2 gets, because it’s stored within the session memory not global memory.
Getting from a sequence is certainly not deterministic, and is usually disallowed for some operations that would require “next value” to come up often. Oracle disallows it with DISTINCT, ORDER BY, GROUP BY, UNION, WHERE, CHECK, DEFAULT, subqueries, and views; other DBMSs are more easygoing.
You’ll want to find out what you’re inserting. The simple way is to get the next value first into a variable, then insert it:
SET x = NEXT VALUE FOR x_seq;
INSERT INTO t VALUES (x, …)
but that involves two trips to the server. If possible, one wants to do the database operation and return the next value to the user, all via one statement, as in the SQL:2011 non-core (optional) feature T495 “Combined data change and retrieval”. Unfortunately (I’ve decried this heresy before), you’ll often see this done with UPDATE … RETURNING.
The GUID alternative
If I just want a unique number, why don’t I get the client or the middleware to generate a GUID for me? First let me state what’s good.
* Zero locks and zero log writes.
* A GUID has a 122-bit number. No, not a 128-bit number because there are a few bytes for version number and for future purposes. No, we can’t hope that there will be even distribution across the range so 2**122 is a dream. But (2**122) = 5.316912e+36, so the chances of generating duplicate numbers is still estimated as: not in this lifetime.
* So what if there’s a duplicate? If you’re generating a GUID for the sake of a surrogate key, then it will get inserted in a unique index, and so there will be a nice clean error message if the same value reappears.
Now this is what’s bad.
* GUIDs are long. It’s not just a difference between 128 bits and 64 bits, because serial numbers start at small numbers like ‘1’, while GUIDs are always long strings when you print them out. Not only does this mean that end-users wouldn’t want to be subjected to them, it means that they’d take more space to store. And, if they’re used for primary keys of an index-organized table, they might form part of secondary keys, so the extra space is being consumed more than once.
Therefore it’s not a settled matter. But people do prefer sequences for the other main reason: despite their problems, they’re generally sequential.
The IDENTITY alternative
The other way to get a sequence is to define a column as IDENTITY, or some close equivalent such as PRIMARY KEY AUTO_INCREMENT.
Clearly, SEQUENCE is better when the same generated value is useful for multiple tables, or for no tables. But what about the common situation where the generated value has something to do with a single column in a single table — then maybe IDENTITY is better for performance reasons.
I recently encountered a good insult: “You’re not stupid, you just have bad luck when you think.” Here is an example of thinking. See if you can spot the bad luck.
“The DBMS is going to generate a number as a primary key. Primary keys have B-tree indexes. The NEXT VALUE will be the current largest value, plus one. That value is in the last page of the index. I have to read that page anyway, because that’s where I’m going to add the key for the NEXT VALUE that I’m INSERTing. Therefore the overhead of using IDENTITY is negligible.”
Did you have any trouble spotting that that is not true, because the largest value might have been DELETEd? An identity value must not be re-used! Therefore there is a bit of overhead, to store what was the maximum value for all time, separately.
(Incidental note: MySQL and MariaDB and Oracle Rdb and SQL Server 2012 unfortunately do destroy the maximum auto_increment value when I say TRUNCATE TABLE. But DBMSs like DB2 for i will by default preserve the maximum IDENTITY-column value, as the SQL standard requires.)
People have compared IDENTITY versus SEQUENCE performance. On SQL Server 2012 one tester found that identity is always better but another tester found that sequence catches up when cache size = 100,000. On Oracle 12c a tester found that sequences took 26 seconds while identities took 28 seconds. On DB2 a tester found that “Identity performs up to a few percent better.” Averaging the results: it depends.
And it’s not necessarily a GUID versus SEQUENCE versus AUTO_INCREMENT contest. There are lots of ways that users can make their own unique values, with timestamps and branch-identifiers and moon phases. They’re not standardized, though, so I leave such ideas as exercises for readers who think they can do better.
Bottlenecks
The two things you want to avoid are hot spots and cache misses. Choose any one.
A hot spot is caused when multiple users are all trying to modify the same index pages. That’s inevitable if User #1 gets value 123456, User #2 gets value 123457, and User #3 gets value 123458. Naturally those will probably fall on the same page, and so cause contention. The solution is to hash or reverse the number before writing.
A cache miss is caused when multiple users are not all reading the same index pages. If they were, then the chances would be high that the page you want would be in the cache, and you’d save a disk read. The situation can arise when everybody needs to access a group of rows that were put in around the same time, for example “rows inserted today”. The solution is to not hash or reverse the number before writing.
Gaps
The easiest way to reduce gaps is to say CACHE 0 or NO CACHE when you create the sequence. As we’ve seen, this has bad effects on performance, so do it only when you have some rule saying “no gaps” (read “Gapless sequences” for an example due to German tax laws). It’s likely that you’ll still have something that’s faster than a separate auto-incrementing table.
Or you can try to plug the gaps after they’re made. Itzak ben-Gan wrote a few tips about that, and so did Baron Schwartz.
Hey, What about MySQL and MariaDB?
In 2003 in MySQL Worklog Task #827 I explained: “In the Bordeaux group leaders’ meeting (November 2003), “Oracle-type sequences” was specified as an item for version 5.1.” You can judge how well that came out.
MariaDB’s worklog task 10139 is somewhat more current — there’s an assignee and there’s recent activity. I’m dubious about the proposed plan, it specifies very little and it’s something involving a read-uncommitted table that contains the latest high number, and then the dread words appear “see [URL of postgresql.org documentation] for details”. However, plans often change.
Unless I’m behind the times, I predict that MySQL or MariaDB would have a problem imitating Oracle’s GRANT SEQUENCE (a separate privilege that only affects sequences). Making a new privilege is still hard, I believe.
When or if the syntax changes, our GUI client for MySQL and MariaDB will of course be updated to recognize it.
See also
My old DBAzine article “Sequences and identity columns” is still mostly valid.
The Oracle 12c manual says “Oracle PL/SQL provides functionality equivalent to SQL/PSM:2011, with minor syntactic differences, such as the spelling or arrangement of keywords.” Yes, and English provides functionality equivalent to Russian, except all the words are spelled differently and in different order. Seriously, since Oracle has PL/SQL and MariaDB has SQL/PSM, their stored procedures and functions and triggers and anonymous blocks — hereinafter “code blocks” — look different.
But that’s changing.
There’s a boatload of Oracle compatibility sauce in MariaDB 10.3, and part of it is PL/SQL code blocks, which is what I’ll look at here. MariaDB 10.3 is not released and might not be released for a long time, but the source code is public. I downloaded it with
git clone -b bb-10.2-compatibility https://github.com/MariaDB/server.git
and followed the usual instructions for building from source. I had a bit of trouble building, and I’ll make a few quibbles when I describe details. But to get to the bottom line here at the top: the feature is complete and works about as well as some betas that I’ve seen.
Here’s a short example.
CREATE PROCEDURE p AS
var1 NUMBER(6) := 1;
BEGIN
WHILE var1 < 5 LOOP
DELETE FROM t WHERE s1 = var1;
var1 := var1 + 1;
END LOOP;
END;
Notice some obvious differences from SQL/PSM:
there are no parentheses after p, they're optional
var1 is defined outside the BEGIN END block
WHILE ... LOOP ... END LOOP not WHILE ... DO ... END WHILE
assignment is done without SET, this too is sometimes optional.
In terms of "Oracle 12c compatibility", MariaDB is now pulling ahead of MySQL, which is bemusing when one considers that Oracle owns MySQL. MariaDB will still not be as compatible as PostgreSQL with EnterpriseDB, I suppose, but this is a boost for migrants.
First complaint: Ocelot's stored-procedure debugger, which is part of our open-source GUI (ocelotgui) for MySQL and MariaDB, can't handle the new PL/SQL. It doesn't even detect where statements end, so I've got work to do.
Second complaint: obviously Monty Widenius makes the MariaDB programmers work too hard. What happened to the halcyon days of yore when making DBMSs was one long party?
For the rest of this blog post, I will describe what the differences are between MariaDB's current PSM and MariaDB 10.3's PL/SQL.
sql_mode='oracle'
In order to enable creation of PL/SQL code blocks, say
SET sql_mode='oracle';
Before saying "this is a bad idea", I will admit that:
I don't have a better idea at the moment.
Now, with that out of the way, I can say that:
this is a bad idea.
(1) There's already a "SET sql_mode='oracle';" statement, so this is a significant behaviour change.
(2) The setting changes what statements are legal. That means that, faced with a code-block statement, it's impossible to know whether it's syntactically correct unless you know what the earlier statements were.
(3) Inevitably some things will be SQL/PSM and some things will be PL/SQL, at least in some installations. Therefore there will be lots of jumping back and forth with sql_mode settings, with special extra fun if someone makes the change to @@sql_mode globally.
In other words, this is such a bad idea that it cannot possibly survive. Therefore don't worry about it. (UPDATE: 2017-02-12: since I have no better idea, and since few current users would be affected, I backtrack -- MariaDB may as well stay on course.)
CREATE PROCEDURE
SQL/PSM PL/SQL
------- ------
CREATE CREATE
[OR REPLACE] [OR REPLACE]
[DEFINER = {user|CURRENT_USER }] [DEFINER = {user|CURRENT_USER}]
PROCEDURE sp_name PROCEDURE sp_name
([proc_parameter[,...]]) [([proc_parameter[,...]])]
[characteristic ...] [characteristic ...]
{IS|AS}
body body
proc_parameter:
[IN|OUT|INOUT] name type name [IN|OUT|INOUT] type
type:
Any MariaDB data type any MariaDB or Oracle data type
characteristic:
LANGUAGE SQL LANGUAGE SQL
| [NOT] DETERMINISTIC | [NOT] DETERMINISTIC
| contains|reads|modifies SQL clause | contains|reads|modifies SQL clause
| SQL SECURITY {DEFINER|INVOKER} | SQL SECURITY {DEFINER|INVOKER}
| COMMENT 'string' | COMMENT 'string'
The only differences between the left column and the right column are:
* {IS|AS} clause -- if you see IS OR AS here, then you know it's PL/SQL.
* parentheses around the parameter list are optional.
* types can be Oracle data types, which I'll discuss later.
If Mr Spock saw this he would say "It's PL/SQL captain, but not as we know it." The DEFINER clause and the INOUT option and all the characteristics are not in Oracle 12c. But they are good additions -- if they weren't allowed, some functionality would be lost. So my only quibble would be: the Oracle characteristics clause AUTHID {DEFINER|CURRENT_USER} should have been allowed as well.
After I created with
CREATE PROCEDURE p IS BEGIN DELETE FROM t; END;
I looked at information_schema with
SELECT routine_definition, routine_body, sql_data_access, sql_mode
FROM information_schema.routines
WHERE routine_name='p';
and saw
ROUTINE_DEFINITION: 'IS BEGIN DELETE FROM t; END'
ROUTINE_BODY = 'SQL'
SQL_DATA_ACCESS = 'CONTAINS SQL'
SQL_MODE: 'PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ORACLE, ...' (etc.)
So how do I know this is a PL/SQL routine?
I can't depend on SQL_MODE, for the reasons I stated before. I don't like to depend on ROUTINE_DEFINITION, because really the definition doesn't start with IS, it starts with BEGIN.
So my second quibble is: I wish the value in ROUTINE_BODY was 'PLSQL' rather than 'SQL'.
Approximately the same syntax enhancements exist for functions and triggers.
Body
When a body of a routine is a compound statement ...
SQL/PSM PL/SQL
------- ------
[DECLARE section]
BEGIN [[NOT] ATOMIC] BEGIN
[variable declarations]
[exception-handler declarations]
[Executable statements] Executable statements
[EXCEPTION section]
END END
In SQL/PSM the variables are declared within BEGIN/END, in PL/SQL they're declared before BEGIN/END. In SQL/PSM the exceptions are declared within BEGIN/END, in PL/SQL they're declared after BEGIN/END.
Therefore the SQL/PSM body...
CREATE OR REPLACE PROCEDURE a()
BEGIN
DECLARE v VARCHAR(100) DEFAULT 'Default';
SET v = NULL;
END;
... does look different in PL/SQL ...
CREATE PROCEDURE a IS
v VARCHAR2(100) := 'Default';
BEGIN
v := NULL;
END;
but the differences are in the syntax and order of non-executable statements. That is, the existing MariaDB-10.2 SQL executable statements (DELETE, DROP, etc.) will work in a PL/SQL body.
Control statements
SQL/PSM PL/SQL
------- ------
label: <<label>>
IF ... THEN ... [ELSE ...] END IF IF ... THEN ... [ELSE ...] END IF
LOOP ... END LOOP LOOP ... END LOOP
WHILE ... DO ...; END WHILE WHILE LOOP ...; END LOOP
CASE ... WHEN ... THEN ... END CASE CASE ... WHEN ... THEN ... END CASE
REPEAT ... UNTIL ...
ELSIF
FOR
GOTO
NULL
LEAVE EXIT [WHEN ...]
ITERATE CONTINUE [WHEN ...]
For controlling the flow of execution, there's a lot of similarity.
The only major "enhancement" in PL/SQL is GOTO, which is considered beneficial when one wishes to get out of a loop that's within a loop that's within a loop. Seeing how that works out in practice will be interesting (a euphemism for: there will be bugs).
The only minor "enhancement" in PL/SQL is NULL, which does nothing. That is, where in SQL/PSM you'd say "BEGIN END", in SQL/PSM you'd say "BEGIN NULL; END".
Third quibble: For some reason, BEGIN <<label>> NULL; END is illegal.
Fourth quibble: The NULL statement is not visible in INFORMATION_SCHEMA.
(Update 2017-01-17: The third quibble has been taken care of, and the fourth quibble was my mistake, the NULL statement is visible.)
Variables
This is a PL/SQL procedure with a mishmash of declarations and assignments.
CREATE PROCEDURE p() IS
a VARCHAR2(500);
b CHAR(7) CHARACTER SET sjis;
c NUMBER(6) := 1;
d TINYINT DEFAULT 1;
BEGIN SET @c = c; d := @d; END;
Variables a and c are declared with Oracle syntax, but variables b and d are declared with MySQL syntax. The first assignment is MariaDB syntax, but the second assignment is Oracle syntax.
Fifth quibble: "SET d := @d" wouldn't work, which shows that Oracle and MariaDB variable and assignment statements aren't always interchangeable, but they usually are.
Mishmash is good -- once again, the MariaDB folks didn't see a need to limit functionality just because Oracle doesn't do something, and didn't see a need to be strict about Oracle syntax because of course MariaDB syntax works. However, routines like this can't be migrated to Oracle 12c. Compatibility only works one way.
The worklog
MariaDB is open -- the early source code is available, and so are the worklog tasks on JIRA. The information in the worklog tasks is sparse, far inferior to what we used to do for MySQL. But these items are worth following to see when they change.
[MDEV-10137] Providing compatibility to other databases
[MDEV-10142] PL/SQL parser
[MDEV-10343] Providing compatibility for basic SQL data types
[MDEV-10411] Providing compatibility for basic PL/SQL constructs
[MDEV-10580] sql_mode=ORACLE: FOR loop statement
[MDEV-10697] GOTO statement
[MDEV-10764] PL/SQL parser - Phase 2
There are many other tasks associated with "Oracle compatibility", if I had tried to describe them all this post would be too long.
It is the business of educated people to speak so that no-one may be able to tell in what county their childhood was passed. — A. Burrell, A Handbook for Teachers in Public Elementary School, 1891
The terms that reveal where a person (mis)spent a DBMS-related childhood are “char”, “data”, “GIF”, “gigabyte”, “GUI”, “JSON”, “query”, “schema”, “tuple”, “_”, “`”, and “«”.
CHAR
(1) Like “Care” because it’s short for “Character” (so hard C and most folks say “Character” that way)?
(2) Like “Car” because it’s short for “Character” (so hard C and a few folks in the British Isles say it that way and perhaps all other English words ending in consonant + “ar” are pronounced that way)?
(3) Like “Char” (the English word for a type of trout)?
C/C++ programmers say (3), for example Bjarne Stroustrup of C++ fame says that’s illogical but usual. However, people who have not come to SQL from another programming language may be more likely to go with (2), leading one online voter to exclaim “I’ve known a lot of people who say “car” though. (Generally SQL-y people; is this what they teach in DBA classes?)” and Tom Kyte of Oracle fame reportedly says “var-car” .
DATA
The Oxford English Dictionary (OED) shows 4 (four!) variations:
“Brit. /ˈdeɪtə/, /ˈdɑːtə/, U.S. /ˈdædə/, /ˈdeɪdə/”.
It’s only the first syllable that matters — DAY or DA?
I haven’t seen the Longman Pronunciation Dictionary, but a blog post says the results of Longman’s preference poll were:
“BrE: deɪtə 92% ˈdɑːtə 6% ˈdætə 2% AmE: ˈdeɪțə 64%ˈdæțə 35% ˈdɑːțə 1%” (notice it’s ț not t for our American friends). By the way OED says in a computing context it’s “as a mass noun” so I guess “data is” is okay.
GIF
It’s “jif”, says its creator.
GIGABYTE
That letter at the start is a hard G; The “Jigabyte” pronunciation is unknown to Merriam-Webster, Cambridge, and Oxford dictionaries.
GUI
No question it’s “gooey”, for all the dictionaries I checked. So pronounce our product as “osselot-goey”“osselot-gooey”.
GUID
The author of “Essential COM” says
The exact pronunciation of GUID is a subject of heated debate among COM developers. Although the COM specification says that GUID rhymes with fluid, the author [Don Box] believes that the COM specification is simply incorrect, citing the word languid as setting the precedent.
The COM specification is a standard and therefore cannot be incorrect, but I can’t find it, and I like setting-a-precedent games, so let’s use the exact word Guid, eh? It appears in Hugh MacDiarmid’s masterpiece “A Drunk Man Looks At The Thistle”
But there are flegsome deeps
Where the soul o’Scotland sleeps
That I to bottom need
To wauk Guid kens what deid
.. which proves that Guid is a one-syllable word, though doubtless MacDiarmid pronounced it “Gweed”.
JSON
Doug Crockford of Yahoo fame, seen on Youtube, says:
So I discovered JAYsun. Java Script Object Notation. There’s a lot of argument about how you pronounce that. I strictly don’t care. I think probably the correct pronunciation is [switching to French] “je sens”.
The argument is mostly between people who say JAYsun and people who say JaySAWN. It’s controversial, and in our non-JSON environment it’s a foreign word, so spelling it out J S O N is safe and okay.
QUERY
In the 1600s the spelling was “quaery”, so it must have rhymed with “very”, and it still does, for some Americans. But the OED says that both American and British speakers say “QUEERie” nowadays.
SCHEMA
It’s “Skema”. The “Shema” pronunciation is unknown to Merriam-Webster, Cambridge, and Oxford dictionaries.
SQL
See the earlier post “How to pronounce SQL” which concluded:
In the end, then, it’s “when in Rome do as the Romans do”. In Microsoft or Oracle contexts one should, like Mr Ellison, respect Microsoft’s or Oracle’s way of speaking. But here in open-source-DBMS-land the preference is to follow the standard.
TUPLE
See the earlier post “Tuples”. It’s “Tuhple”.
_
According to Swan’s “Practical English Usage” the _ (Unicode code point 005F) character is more often called underline by Britons, more often called underscore by Americans. (The SQL-standard term is underscore.) (The Unicode term is LOW LINE; SPACING UNDERSCORE was the old Unicode-version-1.0 term.)
` `
This is a clue for telling if people have MySQL backgrounds — they’ll pronounce the ` (Unicode code point 0060) symbol as “backtick”. Of course it also is found in other programming contexts nowadays, but there are lots of choices in the Jargon File:
Common: backquote; left quote; left single quote; open quote; ; grave. Rare: Backprime; [backspark]; unapostrophe; birk; blugle; back tick; back glitch; push; ; quasiquote.
By the way The Jargon File is a good source for such whimsical alternatives of ASCII names.
« »
You might be fooled by an Adobe error, as I was, into thinking that these French-quote-mark thingies are pronounced GEELmoes. Wrong. They are GEELmays. (The Unicode term is left-point or right-point double angle quotation marks.) This matter matters because, as Professor Higgins said, “The French don’t care what they do actually, as long as they pronounce it properly.”
Meanwhile …
Enhancements made to the source code for the next version of ocelotgui, Ocelot’s Graphical User Interface for MySQL and MariaDB, are: error messages are optionally in French, and grid output is optionally in HTML. As always, the description of the current version is on ocelot.ca and the downloadable source and releases are on github.
MySQL 8.0.0 exists.
For general impressions we already have comments by Giuseppe Maxia and Stewart Smith and Serdar Yegulalp.
Two new features looked important to me: modern UCA collations, and roles. So I downloaded and tried them out.
Modern UCA collations
MySQL is going to switch to utf8mb4 for the default character set and add collations based on the the latest version of the Unicode Collation Algorithm (UCA 9.0.0). I still see messages indicating the default is still latin1, but they’re incorrect, I can put 4-byte UTF-8 characters in columns that I created without explicitly saying utf8mb4.
The new collations are only for utf8mb4. That’s suboptimal. People still have good reasons to use other character sets (I discussed some of them in an earlier blog post). And in any case, a collation that works for utf8mb4’s repertoire will work for every character set that has a pure subset of that repertoire, which is to say, every character set.
The new collations are only for the generic “Default Unicode Collation Element Table” (DUCET), and for Latin-based alphabets. So there are no updates for “persian” or “sinhala”.
For an example, the following table shows changes between the old Swedish collation (utf8mb4_swedish_ci) and the new one (utf8mb4_sv_0900_ai_ci). The “Rule” column has what Unicode says about certain Swedish primary (level-1) comparisons, the “Example” column has what an SQL comparison would look like, the “Old” column has the results I got with utf8mb4_swedish_ci, the “New” column has the results I got with utf8mb4_sv_0900_ai_ci.
Rule Example Old New
—————————- ——— —– —-
ETH = D ‘Ð’ = ‘D’ FALSE TRUE
D STROKE = D ‘Đ’ = ‘D’ FALSE TRUE
THORN = TH ‘Þ’ = ‘TH’ FALSE TRUE
O DOUBLE ACUTE = O DIAERESIS ‘Ő’ = ‘Ö’ FALSE TRUE
U DOUBLE ACUTE = Y ‘Ű’ = ‘Y’ FALSE TRUE
L STROKE = L ‘Ł’ = ‘L’ FALSE TRUE
A DIAERESIS = E OGONEK ‘Ä’ = ‘Ę’ FALSE TRUE
OE = O DIAERESIS ‘Œ’ = ‘Ö’ FALSE TRUE
O CIRCUMFLEX = O DIAERESIS ‘Ô’ = ‘Ö’ FALSE TRUE
Most Swedes don’t know about these rules, they apply to medieval texts or foreign names. But most Swedes do know that rules should cover the edge cases, not just the Stockholm phone book. Because it follows the Unicode rules, the new collation is better.
But the new collation’s name is worse, for two reasons.
(1) The “_ai” suffix, meaning “accent insensitive”, is Microsoftish. There is such a thing, but the definition of “accent” varies between languages and the factors that influence collations can be other things besides accents. Clearer suffixes for extra-sensitive collation names would be “w2” or “l2” (for weight=2 or level=2), and they’re for sorting rather than searching unless you’re Japanese, but a default = no-suffix-for-accents would have been okay.
(2) The “_sv” suffix, meaning “Swedish”, is an unnecessary change. Compatibility with the previous suffix — “swedish” — would not have violated UCA specifications and would have been clearer for people who have used MySQL before.
For a second example, I looked at the new “Latin” collation, utf8mb4_la_0900_ai_ci. This time I couldn’t find any rules file in the Unicode standard directory. There is a UCA chart for Latin but utf8mb4_la_0900_ai_ci obviously isn’t following it at all. Instead it’s like MySQL’s old and silly “Roman” collation, where i=j and u=v. This is not an important collation. But MySQL claims the new collations follow UCA rules, and here is one that doesn’t, so I worry about the others.
This has to be taken in context — MySQL has far better support for character sets and collations than any other open-source DBMS, except sometimes MariaDB. And now it’s a weenie bit more far better. Observations about paucity of new UCA collations, bad names, or standard non-compliance won’t change that fact.
Roles
I discussed MariaDB’s roles in 2014. MySQL’s roles are already in the 8.0 documentation. Is MySQL making an improvement?
The first thing I noticed is that the syntax rules for roles are, too often, the same as the syntax rules for users. This is especially obvious when I ask for things that make no sense for roles, for example:
mysql>CREATE ROLE 'r'@'host';
OK 0 rows affected (0.1 seconds)
mysql>CREATE ROLE '';
Error 1396 (HY000) Operation CREATE USER failed for anonymous user
mysql>GRANT 'root'@'localhost' TO role_name;
OK 0 rows affected (0.1 seconds)
mysql>DROP USER role_name;
OK 0 rows affected (0.1 seconds)
Because of this, some non-standard limitations exist: maximum name length is 32, names are case sensitive, role names cannot be the same as user names, and there is no separate information_schema table
However, the DML statements that I tested for MariaDB do work with MySQL as well, and are often exactly the same:
MariaDB: CREATE [OR REPLACE] ROLE [IF NOT EXISTS] role_name [WITH ADMIN ...];
MySQL: CREATE ROLE [IF NOT EXISTS] role_name [,role_name...];
MariaDB: DROP ROLE [IF EXISTS] role_name [,role_name...];
MySQL: DROP ROLE [IF EXISTS] role_name [,role_name...];
MariaDB: SET DEFAULT ROLE {role_name|NONE} [FOR user_name];
MySQL: SET DEFAULT ROLE ALL TO user_name [,user_name...];
MariaDB: SET ROLE {role_name|NONE};
MySQL: SET ROLE {role_name|NONE};
MariaDB: SELECT CURRENT_ROLE() | CURRENT_ROLE;
MySQL: SELECT CURRENT_ROLE();
MariaDB: [no exact equivalent]
MySQL: GRANT CREATE ROLE ON *.* TO grantee;
MariaDB: SHOW GRANTS [FOR role_name];
MySQL: SHOW GRANTS [FOR role_name];
MySQL: SHOW GRANTS [FOR user_name USING role_name[,role_name...]];
MariaDB: GRANT role_name TO grantee [,grantee...] [WITH ADMIN OPTION];
MySQL: GRANT role_name[,role_name...] TO grantee [,grantee...];
(The last GRANT example surprised me. MariaDB has trouble granting multiple roles in one statement, it’s Bug#5772. MySQL appears to be “solving” it by making certain role names illegal unless they’re delimited; I’m not sure that’s the right way to solve it.)
Circular roles (GRANT r1 TO r2; GRANT r2 TO r1;) are allowed but I expect they’ll be disallowed in a later version.
Example:
/* as a user with lots of privileges */
CREATE USER 'u'@'localhost';
CREATE ROLE r;
CREATE TABLE t1 (s1 INT);
CREATE TABLE t2 (s1 INT);
GRANT SELECT ON t1 TO r;
GRANT r TO 'u'@'localhost';
/* as user 'u'@'localhost' */
SET ROLE r;
SELECT * FROM t1;
SELECT * FROM t2;
/* The first SELECT succeeds, the second SELECT fails. */
To generalize: so far MySQL 8.0.0 allows creation of roles but they have to look like users. So the syntax is undesirable, but they work properly.
Again, remember the context. There’s nothing wrong with a feature that’s not ready, until MySQL declares that it’s ready.
Typos
MySQL’s announcement, buried in a section about minor fixes, says “Foreign key names as stored in the foreign_keys and foreign_key_column_usage tables are a maximum of 64 characters, per the SQL standard”. Er, up to a point. The SQL standard says “In a regular identifier, the number of identifier parts shall be less than 128.”
Us Too
We have a new-version announcement too. Version 1.0.3 of the Ocelot Graphical User Interface (ocelotgui) for MySQL and MariaDB came out on Tuesday September 27 2016. Some new items are …
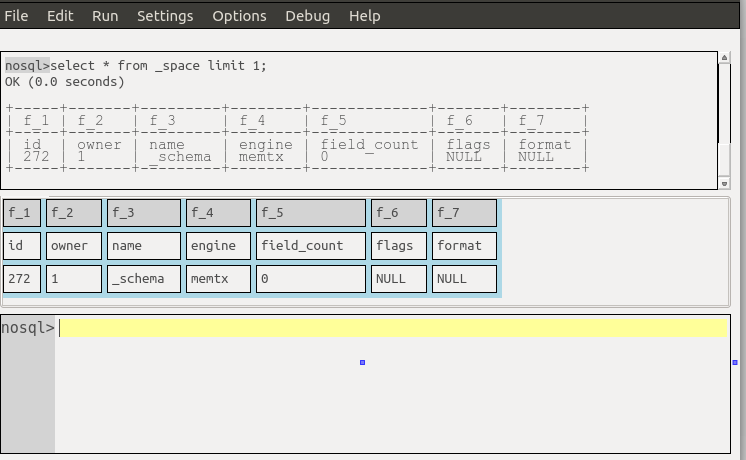
As well as getting result sets in the result-set widget, one can get them added to the history widget, with the same format as what the mysql client outputs.
As well as predicting what the next word should be, Ocelot’s syntax recognizer makes it possible to show hints if the user hovers over a word.

Finally, there is a rudimentary formatter. Clicking the edit menu item Edit|Format will change indentation, make keywords upper case, etc. I say “rudimentary” because, without a standard to follow, one must depend on taste, and nobody shares the taste that’s on display here.


Documentation is now on ocelot.ca/index.htm. C++ source and Linux-ready packages are on github.com/ocelot-inc/ocelotgui.
DBMS client applications need to store SQL query results in local memory or local files. The format is flat and the fields are ordered — that’s “serialization”. The most important serializer format uses human-readable markup, like
[start of field] [value] [end of field]
and the important ones in the MySQL/MariaDB world are CSV (what you get with SELECT … INTO OUTFILE or LOAD INFILE), XML (what you get with –xml or LOAD XML), and JSON (for which there are various solutions if you don’t use MySQL 5.7).
The less important serializer format uses length, like
[length of value] [value]
and this, although it has the silly name “binary serialization”, is what I want to talk about.
The length alone isn’t enough, we also need to know the type, so we can decode it correctly. With CSV there are hints such as “is the value enclosed in quotes”, but with binary serializers the value contains no hints. There has to be an indicator that says what the type is. There might be a single list of types for all of the records, in which case the format is said to “have a schema”. Or there might be a type attached to each record, like
[type] [length of value] [value]
in which case the format is often called “TLV” (type-length-value).
Binary serializers are better than markup serializers if you need “traversability” — the ability to skip to field number 2 without having to read every byte in field number 1. Binary TLV serializers are better than binary with-schema serializers if you ned “flexibility” — when not every record has the same number of fields and not every field has the same type. But of course TLV serializers might require slightly more space.
A “good” binary serializer will have two Characteristics:
#1 It is well known, preferably a standard with a clear specification, but otherwise a commonly-used format with a big sponsor. Otherwise you have to write your own library and you will find out all the gotchas by re-inventing a wheel. Also, if you want to ship your file for import by another application, it would be nice if the other application knew how to import it.
#2 It can store anything that comes out of MySQL or MariaDB.
Unfortunately, as we’ll see, Characteristic #1 and Characteristic #2 are contradictory. The well-known serializers usually were made with the objective of storing anything that comes out of XML or JSON, or that handled quirky situations when shipping over a wire. So they’re ready for things that MySQL and MariaDB don’t generate (such as structured arrays) but not ready for things that MySQL and MariaDB might generate (such as … well, we’ll see as I look at each serializer).
To decide “what is well known” I used the Wikipedia article Comparison of data serialization formats. It’s missing some formats (for example sereal) but it’s the biggest list I know of, from a source that’s sometimes neutral. I selected the binary serializers that fit Characteristic #1. I evaluated them according to Characteristic #2.
I’ll look at each serializer. Then I’ll show a chart. Then you’ll draw a conclusion.
Avro
Has schemas. Not standard but sponsored by Apache.
I have a gripe. Look at these two logos. The first one is for the defunct British/Canadian airplane maker A.V.Roe (from Wikipedia). The second one is for the binary serializer format Apache Avro (from their site).


Although I guess that the Apache folks somehow have avoided breaking laws, I think that taking A.V.Roe’s trademark is like wearing medals that somebody else won. But putting my gripe aside, let’s look at a technical matter.
The set of primitive type names is:
null: no value
Well, of course, in SQL a NULL is not a type and it is a value. This is not a showstopper, because I can declare a union of a null type and a string type if I want to allow nulls and strings in the same field. Um, okay. But then comes the encoding rule:
null is written as zero bytes.
I can’t read that except as “we’re like Oracle 12c, we think empty strings are NULLs”.
ASN.1
TLV. Standard.
ASN means “abstract syntax notation” but there are rules for encoding too, and ASN.1 has a huge advantage: it’s been around for over twenty years. So whenever any “why re-invent the wheel?” argument starts up on any forum, somebody is bound to ask why all these whippersnapper TLVs are proposed considering ASN.1 was good enough for grand-pappy, eh?
Kidding aside, it’s a spec that’s been updated as recently as 2015. As usual with official standards, it’s hard to find a free-and-legitimate copy, but here it is: the link to a download of “X.690 (08/2015) ITU-T X.690 | ISO/IEC 8825-1 ISO/IEC 8825-1:2015 Information technology — ASN.1 encoding rules: Specification of Basic Encoding Rules (BER), Canonical Encoding Rules (CER) and Distinguished Encoding Rules (DER)” from the International Telecommunication Union site: http://www.itu.int/rec/T-REC-X.690-201508-I/en.
It actually specifies how to handle exotic situations, such as
** If it is a “raw” string of bits, are there unused bits in the final byte?
** If the string length is greater than 2**32, is there a way to store it?
** Can I have a choice between BMP (like MySQL UCS2) and UTF-8 and other character sets?
** Can an integer value be greater than 2**63?
… You don’t always see all these things specified except in ASN.1.
Unfortunately, if you try to think of everything, your spec will be large and your overhead will be large, so competitors will appear saying they have something “simpler” and “more compact”. Have a look at trends.google.com to see how ASN.1 once did bestride the narrow world like a colossus, but nowadays is not more popular than all the others.
BSON
TLV. Sponsored by MongoDB.
Although BSON is “used mainly as a data storage and network transfer format in the MongoDB [DBMS]”, anybody can use it. There’s a non-Mongo site which refers to independent libraries and discussion groups.
BSON is supposed to make you think “binary JSON” but in fact all the binary serializers that I’m discussing (and I few that I’m not discussing such as UBJSON) can do a fair job of representing JSON-marked-up-text in binary format. Some people even claim that MessagePack does a better job of that than BSON does.
There is a “date” but it is milliseconds since the epoch, so it might be an okay analogue for MySQL/MariaDB TIMESTAMP but not for DATETIME.
CBOR
TLV. Proposed standard.
CBOR is not well known but there’s an IETF Internet Standards Document for it (RFC 7049 Concise Binary Object Representation), so I reckoned it’s worth looking at. I don’t give that document much weight, though — it has been in the proposal phase since 2013.
The project site page mentions JSON data model, schemalessness, raw binary strings, and concise encoding — but I wanted to see distinguishing features. There are a few.
I was kind of surprised that there are two “integer” types: one type is positive integers, the other type is negative integers.
In other words -5 is
[type = negative number] [length] [value = 5]
rather than the Two’s Complement style
[type = signed number] [length] [value = -5]
but that’s just an oddness rather than a problem.
There was an acknowledgment in the IETF document that “CBOR is inspired by MessagePack”. But one of MessagePack’s defects (the lack of a raw string type) has been fixed now. That takes away one of the reasons that I’d have for regarding CBOR as a successor to MessagePack.
Fast Infoset
TLV. Uses a standard.
After seeing so much JSON, it’s nice to run into an international standard that specifies a binary encoding format for the XML Information Set (XML Infoset) as an alternative to the XML document format”. Okay, they get points for variety.
However, it’s using ASN.1’s underlying encoding methods, so I won’t count it as a separate product.
MessagePack
TLV. Not standard but widely used.
MessagePack, also called MsgPack, is popular and is actually used as a data storage format for Pinterest and Tarantool.
It’s got a following among people who care a lot about saving bytes; for example see this Uber survey where MessagePack beat out some of the other formats that I’m looking at here.
One of the flaws of MessagePack, from my point of view, is its poor handling for character sets other than UTF-8. But I’ll admit: when MessagePack’s original author is named Sadayuki Furuhashi, I’m wary about arguing that back in Japan UTF-8 is not enough. For some of the arguing that happened about supporting other character sets with MessagePack, see this thread. Still, I think my “The UTF-8 world is not enough” post is valid for the purposes I’m discussing.
And the maximum length of a string is 2**32-1 bytes, so you can forget about dumping a LONGBLOB. I’d have the same trouble with BSON but BSON allows null-terminated strings.
OPC-UA
TLV. Sort of a standard for a particular industry group.
Open Platform Communications – Unified Architecture has a Binary Encoding format.
Most of the expected types are there: boolean, integer, float, double, string, raw string, and datetime. The datetime description is a bit weird though: number of 100 nanosecond intervals since January 1, 1601 (UTC). I’ve seen strange cutover dates in my time, but this is a new one for me.
For strings, there’s a way to indicate NULLs (hurrah).
I have the impression that OPC is an organization for special purposes (field devices, control systems, etc.) and I’m interested in general-purpose formats, so didn’t look hard at this.
Protocol Buffers
Has schemas. Not standard but sponsored by Google.
Like Avro, Google’s Protocol Buffers have a schema for the type and so they are schema + LV rather than TLV. But MariaDB uses them for its Dynamic Columns feature, so everybody should know about them.
Numbers and strings can be long, but there’s very little differentiation — essentially you have integers, double-precision floating point numbers, and strings. So, since I was objecting earlier when I saw that other serialization formats didn’t distinguish (say) character sets, I have to be fair and say: this is worse. When the same “type” tag can be used for multiple different types, it’s not specific enough.
Supposedly the makers of Protocol Buffers were asked why they didn’t use ASN.1 and they answered “We never heard of it before”. That’s from a totally unreliable biased source but I did stop and ask myself: is that really so unbelievable? In this benighted age?
Thrift
Can be TLV but depends on protocol. Not standard but sponsored by Apache, used a lot by Facebook.
I looked in vain for what one might call a “specification” of Thrift’s binary serialization, and finally found an old stackoverflow discussion that said: er, there isn’t any. There’s a “Thrift Missing Guide” that tells me the base types, and a Java class describer for one of the protocols to help me guess the size limits.
Thrift’s big advantage is that it’s language neutral, which is why it’s popular and there are many libraries and high-level tutorials. That makes it great as a communication format, which is what it’s supposed to be. However, the number of options is small and the specification is so vague that I can’t call it “good” according to the criteria I stated earlier.
The Chart
I depend on each serializer’s specification, I didn’t try anything out, I could easily have made some mistakes.
For the “NULL is a value” row, I say No (and could have added “Alackaday!”) for all the formats that say NULL is a data type. Really the only way to handle NULL is with a flag so this would be best:
[type] [length] [flag] [value]
and in fact, if I was worried about dynamic schemas, I’d be partial to Codd’s “two kinds of NULLs” arguments, in case some application wanted to make a distinction between not-applicable-value and missing-value.
For most of the data-type rows, I say Yes for all the formats that have explicit defined support. This does not mean that it’s impossible to store the value — for example it’s easy to store a BOOLEAN with an integer or with a user-defined extension — but then you’re not using the format specification so some of its advantages are lost.
For dates (including DATETIME TIMESTAMP DATE etc.), I did not worry if the precision and range were less than what MySQL or MariaDB can handle. But for DECIMAL, i say No if the maximum number of digits is 18 or if there are no post-decimal digits.
For LONGBLOB, I say No if the maximum number of bytes is 2**32.
For VARCHAR, I say Yes if there’s any way to store any encoded characters (rather than just bytes, which is what BINARY and BLOB are). In the “VARCHAR+” row I say Yes if there is more than one character set, although this doesn’t mean much — the extra character sets don’t match with MySQL/MariaDB’s variety.
I’ll say again that specifications allow for “extensions”, for example with ASN.1 you can define your own tags, but I’m only looking at what’s specific in the specification.
|
Avro |
ASN.1 |
BSON |
CBOR |
Message Pack |
OPC UA |
Protocol Buffers |
Thrift |
| NULL is a value |
no |
no |
no |
no |
no |
YES |
no |
no |
| BOOLEAN |
YES |
YES |
YES |
YES |
YES |
YES |
no |
YES
|
| INTEGER |
YES |
YES |
YES |
YES |
YES |
YES |
YES |
YES
|
| BIGINT |
YES |
YES |
YES |
YES |
YES |
YES |
YES |
YES
|
| FLOAT |
YES |
YES |
YES |
YES |
YES |
YES |
no |
no
|
| DOUBLE |
YES |
YES |
YES |
YES |
YES |
YES |
YES |
YES
|
| BINARY / BLOB |
YES |
YES |
YES |
YES |
YES |
YES |
YES |
YES
|
| VARCHAR |
YES |
YES |
YES |
YES |
YES |
YES |
no |
YES
|
| Dates |
no |
YES |
YES |
YES |
no |
YES |
no |
no
|
| LONGBLOB |
YES |
YES |
no |
YES |
no |
no |
YES |
no
|
| DECIMAL |
no |
YES |
no |
YES |
no |
no |
no |
no
|
| VARCHAR+ |
no |
YES |
no |
no |
no |
YES |
no |
no
|
| BIT |
no |
YES |
no |
no |
no |
no |
no |
no
|
Your Conclusion
You have multiple choice:
(1) Peter Gulutzan is obsessed with standards and exactness,
(2) Well, might as well use one of these despite its defects
(3) We really need yet another binary serializer format.
ocelotgui news
Recently there were some changes to the ocelot.ca site to give more prominence to the ocelotgui manual, and a minor release — ocelotgui version 1.02 — happened on August 15.
In a previous post I said it’s bogus that NoSQL stands for Not Only SQL, but NoSQL products can have “some” SQL. How much?
To get past the SQL-for-Hadoop stuff I’ll just mine a few quotes: “Hive was the first SQL on Hadoop engine and is still the most mature engine.” “Apache Phoenix is a project which aims to provide OLTP style SQL on top of Apache HBase.” “Cloudera Impala and Apache Drill are the two most prominent Dremel clones.” “Oracle, IBM, and Greenplum have all retrofit their database engines to integrate with Hadoop in various ways.” There, that’s the history out of the way. With thanks to a comprehensive article series: The Truth about SQL on Hadoop”.
Of course I could add that it’s possible to take an SQL front and add a NoSQL back as an “engine”, as MariaDB did with Cassandra plus LevelDB, as PostgreSQL did with MongoDB.
Here’s what I see as the documented capabilities provided by NoSQL vendors themselves, or via the Dremel clones.
| thing |
CQL |
Drill |
Impala |
OrientDB |
| DELETE,INSERT,UPDATE |
1/2 |
no |
yes |
yes |
| SELECT + WHERE |
1/2 |
yes |
yes |
yes |
| SELECT + GROUP BY |
no |
yes |
yes |
yes |
| SELECT + functions |
1/2 |
yes |
1/2 |
yes |
| SELECT + IS NULL |
no |
yes |
yes |
yes |
| Subqueries or Joins |
no |
1/2 |
yes |
no |
| GRANT + REVOKE |
yes |
no |
yes |
yes |
| Stored SQL Routines |
no |
no |
no |
no |
| Collations |
no |
|
no |
1/10 |
CQL (Cassandra Query Language) does what I expect: I can do the regular DML statements, but UPDATE can only handle one row at a time. There are no subqueries or joins or views or SQL functions, and the WHERE is restricted because I have to use a query that includes information that tells Cassandra what cluster to go to. All strings are ASCII or UTF-8.
Apache Drill has all the options I respect for SELECT, even windowing. But ithe updating is done outside SQL. There are lots of built-in functions that CQL lacks.
Impala, from Cloudera, is regarded as a good option for analytic queries.
OrientDB handles graph databases, which the OrientDB founder says is defined as “index-free adjacency” (that’s my first joke, I’m making sure you don’t miss them).
For my chart, I deliberately added criteria that I thought might make the DBMSs choke. Specifically I thought IS [NOT] NULL would cause trouble because in a flexible schema the data might be either “missing” = not stored at all or “unknown” = stored explicitly as null value … but usually this caused no problem. Specifically I thought collations would cause trouble because they must affect either storage or performance … and they certainly did, CQL and Impala are byte-value-comparison-only and OrientDB has a grand total of two collations (case sensitive or insensitive). Most of the limitations are understandable for a DBMS that does clustering and searching quickly, but that’s not mom-and-pop stuff. I will end this paragraph with my second joke. NoSQL doesn’t scale … down.
Sometimes the vendors get it that when you use SQL you should use ANSI SQL, for example it’s typical that identifiers can be enclosed within double quotes — far better than MySQL/MariaDB’s ANSI_QUOTES requirement. On the other hand I see that Impala has SHOW statements — just as bad as MySQL/MariaD. And I’ve no idea where OrientDB came up with the syntax “ORDER BY … SKIP”.
On the other hand, NoSQL can be expected to be better at flexible schemas. And it is, because some of the SQL vendors (I’m especially thinking of the work-in-progress “dynamic column” stuff in MariaDB and the JSON functions in MySQL) are still catching up. But they will catch up eventually. That’s why I like the Gartner Report on DBMSs predicting
By 2017, the “NoSQL” label will cease to distinguish DBMSs, which will result in it falling out of use.
Only 5 months left to go, eh?
Another NoSQL DBMS, Tarantool, is also going to have SQL real soon now. Anti-disclosure: I do some work for the vendor but I had nothing to do with the SQL planning.
The idea behind Tarantool/SQL is: instead of struggling to add a piece at a time to a home-grown parser, just fork the one in SQLite. Poof, there’s SQL syntax which, as I discussed in an earlier post, is more than an insignificant subset of the standard core features. The actual data maintenance job is done by Tarantool’s multi-user server.
Here is an ocelotgui screenshot of a Tarantool/SQL query showing the usual advantages that one gets when the language is SQL: syntax highlighting, predicting, and columnar output.
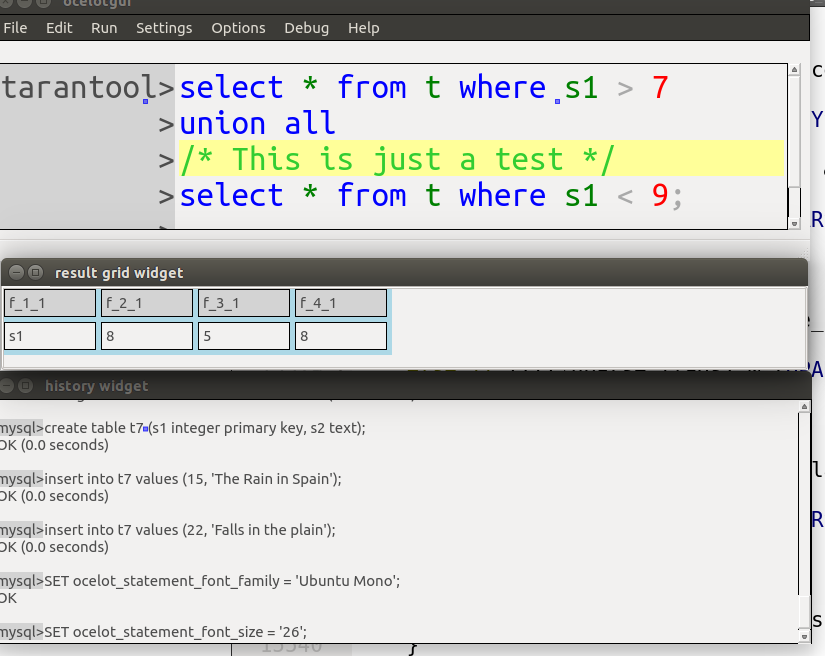
I’m going to need to use SQLite syntax for a project that I’m involved with, and predictably I wonder: how standard is it? The SQLite folks themselves make modest claims to support most of the features with a special focus on SQL-92, but (a) I like to do my own counting (b) there’s no official standard named SQL-92 because it was superseded 17 years ago.
By ignoring SQL-92 claims I eschew use of the NIST test suite. I’ll be far less strict and more arbitrary: I’ll go through SQL:2011’s “Feature taxonomy and definition for mandatory features”. For each feature in that list, I’ll come up with a simple example SQL statement. If SQLite appears to handle the example, I’ll mark it “Okay”, else I’ll mark it “Fail”. I’m hoping that arbitrariness equals objectivity, because the unfair pluses should balance the unfair minuses.
Skip to the end of this blog post if you just want to see the final score.
Standard SQL Core Features, Examples, and Okay/Fail Results
E-011 Numeric data types
E-011-01 INTEGER and SMALLINT
Example: create table t (s1 int);
Fail. A numeric column can contain non-numeric strings. There is a similar flaw for all data types, but let’s count them all as only one fail.
E-011-02 REAL, DOUBLE PRECISION,and FLOAT data types
Example: create table tr (s1 float);
Okay.
E-011-03 DECIMAL and NUMERIC data types
Example: create table td (s1 numeric);
Okay, although: when there are many post-decimal digits there is a switch to exponential notation, for example after “insert into t3 values (0.0000000000000001);” and “select *from t3” I get “1.0e-16”. I regard this as a display flaw rather than a fail.
E-011-04 Arithmetic operators
Example: select 10+1,9-2,8*3,7/2 from t;
Okay. SQLite is wrong to calculate that 7/0 is NULL, though.
E-011-05 Numeric comparison
Example: select * from t where 1 < 2;
Okay.
E-011-06 Implicit casting among the numeric data types
Example: select * from t where s1 = 1.00;
Okay, but only because SQLite doesn’t distinguish etween numeric data types.
E021 Character string types
E-021-01 Character data type (including all its spellings)
Example: create table t44 (s1 char);
Okay, but only because SQLite accepts any definition that includes the word ‘CHAR’, for example CREATE TABLE t (s1 BIGCHAR) is okay although there’s no such data type. There are no checks on maximum length, and no padding for insertions with less than the maximum length.
E021-02 CHARACTER VARYING data type (including all its spellings)
Example: create table t45 (s1 varchar);
Okay, but the behaviour is exactly the same as for CHARACTER.
E021-03 Character literals
Example: insert into t45 values (”);
Okay, and the bad practice of accepting “”s for character literals is avoided.Even hex notation, for example X’41’, is okay.
E021-04 CHARACTER_LENGTH function
Example: select character_length(s1) from t;
Fail. There is no such function. There is a function LENGTH(), which is okay.
E021-05 OCTET_LENGTH
Example: select octet_length(s1) from t;
Fail. There is no such function.
E021-06 SUBSTRING function.
Example: select substring(s1 from 1 for 1) from t;
Fail. There is no such function. There is a function SUBSTR(x,n,n) which is okay.
E021-07 Character concatenation
Example: select ‘a’ || ‘b’ from t;
Okay.
E021-08 UPPER and LOWER functions
Example: select upper(‘a’),lower(‘B’) from t;
Okay. It does not work well out of the box, but I loaded the ICU extension.
E021-09 TRIM function
Example: select trim(‘a ‘) from t;
Okay.
E021-10 Implicit casting among the fixed-length and variable-length character string types
Example: select * from tm where char_column > varchar_column;
Okay, but only because SQLite doesn’t distinguish between character data types.
E021-11 POSITION function
Example; select position(x in y) from z;
Fail. There is no such function.
E021-02 Character comparison
Example: select * from t where s1 > ‘a’;
Okay. I should note here that comparisons are case sensitive, and it is devilishly hard to change this except with ASCII,but case insensitivity is not a requirement for this feature.
E031 Identifiers
E031-01 Delimited
Example: create table “t47” (s1 int);
Fail. Although I can enclose identifiers inside double quotes, that doesn’t make them case sensitive.
E031-02 Lower case identifiers
Example: create table t48 (s1 int);
Okay.
E031-03 Trailing underscore
Example: create table t49_ (s1 int);
Okay.
E051 Basic query specification
E051-01 SELECT DISTINCT
Example: select distinct s1 from t;
Okay.
E051-02 GROUP BY clause
Example: select distinct s1 from t group by s1;
Okay.
E051-04 GROUP BY can contain columns not in select list
Example: select s1 from t group by lower(s1);
Okay.
E051-05 select list items can be renamed
Example: select s1 as K from t order by K;
Okay.
E051-06 HAVING clause
Example: select s1,count(*) from t having s1 < 'b';
Fail. GROUP BY is mandatory before HAVING.
If I hadn’t happened to omit GROUP BY, it would have been okay.
E051-07 Qualifie d * in select list
Example: select t.* from t;
Okay.
E051-08 Correlation names in the FROM clause
Example: select * from t as K;
Okay.
E051-09 Rename columns in the FROM clause
Example: select * from t as x(q,c);
Fail.
E061 Basic predicates and search conditions
E061-01 Comparison predicate
Example: select * from t where 0 = 0;
Okay. But less correct syntax would work too, for example “where 0 is 0”.
E061-02 BETWEEN predicate
Example: select * from t where ‘ ‘ between ” and ‘ ‘;
Okay.
E061-03 IN predicate with list of values
Example: select * from t where s1 in (‘a’,upper(‘a’));
Okay.
E061-04 LIKE predicate
Example: select * from t where s1 like ‘_’;
Okay.
E061-05 LIKE predicate: ESCAPE clause
Example: select * from t where s1 like ‘_’ escape ‘_’;
Okay.
E061-06 NULL predicate
Example: select * from t where s1 is not null;
Okay.
E061-07 Quantified comparison predicate
Example: select * from t where s1 = any (select s1 from t);
Fail. Syntax error.
E061-08 EXISTS predicate
Example: select * from t where not exists (select * from t);
Okay.
E061-09 Subqueries in comparison predicate
Example: select * from t where s1 > (select s1 from t);
Fail. There was more than one row in the subquery result set, but SQLite didn’t return an error.
E061-11 Subqueries in IN predicate
Example: select * from t where s1 in (select s1 from t);
Okay.
E061-12 Subqueries in quantified comparison predicate
Example: select * from t where s1 >= all (select s1 from t);
Fail. Syntax error.
E061-13 Correlated subqueries
Example: select * from t where s1 = (select s1 from t2 where t2.s2 = t.s1);
Okay.
E061-14 Search condition
Example: select * from t where 0 <> 0 or ‘a’ < 'b' and s1 is null;
Okay.
E071 Basic query expressions
E071-01 UNION DISTINCT table operator
Example: select * from t union distinct select * from t;
Fail. However, “select * from t union select * from t;” is okay.
E071-01 UNION ALL table operator
Example: select * from t union all select * from t;
Okay.
E071-03 EXCEPT DISTINCT table operator
Example: select * from t except distinct select * from t;
Fail. However, “select * from t except select * from t;” is okay.
E071-05 Columns combined via table operators need not have exactly the same data type.
Example: select s1 from t union select 5 from t;
Okay, but only because SQLite doesn’t distinguish data types very well.
E071-06 Table operators in subqueries
Example: select * from t where ‘a’ in (select * from t union select * from t);
Okay.
E081 Basic privileges
E081-01 Select privilege at the table level
Fail. Syntax error. (SQLite doesn’t support privileges.)
E081-02 DELETE privilege
Fail. (SQLite doesn’t support privileges.)
E081-03 INSERT privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-04 UPDATE privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-05 UPDATE privilege at column level
Fail. (SQLite doesn’t support privileges.)
E081-06 REFERENCES privilege at the table level
Fail. (SQLite doesn’t support privileges.)
E081-07 REFERENCES privilege at column level
Fail. (SQLite doesn’t support privileges.)
E081-08 WITH GRANT OPTION
Fail. (SQLite doesn’t support privileges.)
E081-09 USAGE privilege
Fail. (SQLite doesn’t support privileges.)
E081-10 EXECUTE privilege
Fail. (SQLite doesn’t support privileges.)
E091 Set functions
E091-01 AVG
Example: select avg(s1) from t7;
Fail. No warning that nulls were eliminated.
E091-02 COUNT
Example: select count(*) from t7 where s1 > 0;
Okay.
E091-03 MAX
Example: select max(s1) from t7 where s1 > 0;
Okay.
E091-04 MIN
Example: select min(s1) from t7 where s1 > 0;
Okay.
E091-05 SUM
Example: select sum(1) from t7 where s1 > 0;
Okay.
E091-06 ALL quantifier
Example: select sum(all s1) from t7 where s1 > 0;
Okay.
E091-07 DISTINCT quantifier
Example: select sum(distinct s1) from t7 where s1 > 0;
Okay.
E101 Basic data manipulation
E101-01 INSERT statement
Example: insert into t (s1) values (”),(null),(55);
Okay.
E101-03 Searched UPDATE statement
Example: update t set s1 = null where s1 in (select s1 from t2);
Okay.
E01-04 Searched DELETE statement
Example: delete from t where s1 in (select s1 from t);
Okay.
E111 Single row SELECT statement
Example: select count(*) from t;
Okay.
E121 Basic cursor support
E121-01 DECLARE CURSOR
Fail. SQLite doesn’t support cursors.
E121-02 ORDER BY columns need not be in select list
Example: select s1 from t order by s2;
Okay. Update on 2016-06-27: Originally I wrongly said “Fail”, see the comments.
E121-03 Value expressions in select list
Example: select s1 from t7 order by -s1;
Okay.
E121-04 OPEN statement
Fail. SQLite doesn’t support cursors.
E121-06 Positioned UPDATE statement
Fail. SQLite doesn’t support cursors.
E121-07 Positioned DELETE statement
Fail. SQLite doesn’t support cursors.
E121-08 CLOSE statement
Fail. SQLite doesn’t support cursors.
E121-10 FETCH statement implicit next
Fail. SQLite doesn’t support cursors.
E121-17 WITH HOLD cursors
Fail. SQLite doesn’t support cursors.
E131 Null value support (nulls in lieu of values)
Example: select s1 from t7 where s1 is null;
Okay.
E141 Basic integrity constraints
E141-01 NOT NULL constraints
Example: create table t8 (s1 int not null);
Okay.
E141-02 UNIQUE constraints of NOT NULL columns
Example: create table t9 (s1 int not null unique);
Okay.
E141-03 PRIMARY KEY constraints
Example: create table t10 (s1 int primary key);
Okay, although SQLite wrongly assumes s1 is auto-increment.
E141-04 Basic FOREIGN KEY constraint with the NO ACTION default for both referential delete action and referential update action.
Example: create table t11 (s1 int references t10);
Fail. The foreign-key check will only be checked when I have said “pragma foreign_keys = on;”.
E141-06 CHECK constraints
Example: create table t12 (s1 int, s2 int, check (s1 = s2));
Okay.
E141-07 Column defaults
Example: create table t13 (s1 int, s2 int default -1);
Okay.
E141-08 NOT NULL inferred on primary key
Example: create table t14 (s1 int primary key);
Fail. I am able to insert NULL if I don’t explicitly say the column is NOT NULL.
E141-10 Names in a foreign key can be specified in any order
Example: create table t15 (s1 int, s2 int, primary key (s1,s2));
create table t16 (s1 int, s2 int, foreign key (s2,s1) references t15 (s1,s2));
Okay.
E151 Transaction support
E151-01 COMMIT statement
Example: commit;
Fail. I have to say BEGIN TRANSACTION first.
E151-02 ROLLBACK statement
Example: rollback;
Okay.
E152 Basic SET TRANSACTION statement
E152-01 SET TRANSACTION statement ISOLATION SERIALIZABLE clause
Example: set transaction isolation level serializable;
Fail. Syntax error.
E152-02 SET TRANSACTION statement READ ONLY and READ WRITE clauses
Example: set transaction read only;
Fail. Syntax error.
E153 Updatable queries with subqueries
E161 SQL comments using leading double minus
Example: –comment;
Okay.
E171 SQLSTATE suport
Example: drop table no_such_table;
Fail. At least, the error message doesn’t hint that SQLSTATE exists.
E182 Host language binding
Okay. The existence of shell executable proves there is a C binding.
F031 Basic schema manipulation
F031-01 CREATE TABLE statement to create persistent base tables
Example: create table t20 (t20_1 int not null);
Okay.
F031-02 CREATE VIEW statement
Example: create view t21 as select * from t20;
Okay.
F031-03 GRANT statement
Fail. SQLite doesn’t support privileges.
F031-04 ALTER TABLE statement: add column
Example: alter table t7 add column t7_2 varchar default ‘q’;
Okay.
F031-14 DROP TABLE statement: RESTRICT clause
Example: drop table t20 restrict;
Fail. Syntax error, and RESTRICT is not assumed.
F031-14 DROP VIEW statement: RESTRICT clause
Example: drop view v2 restrict;
Fail. Syntax error, and RESTRICT is not assumed.
F031-10 REVOKE statement: RESTRICT clause
Fail. SQLite does not support privileges.
F041 Basic joined table
F041-01 Inner join but not necessarily the INNER keyword
Example: select a.s1 from t7 a join t7 b;
Okay.
F041-02 INNER keyword
Example: select a.s1 from t7 a inner join t7 b;
Okay.
F041-03 LEFT OUTER JOIN
Example: select t7.*,t22.* from t22 left outer join t7 on (t22_1=s1);
Okay.
F041-04 RIGHT OUTER JOIN
Example: select t7.*,t22.* from t22 right outer join t7 on (t22_1=s1);
Fail. Syntax error.
F041-05 Outer joins can be nested
Example: select t7.*,t22.* from t22 left outer join t7 on (t22_1=s1) left outer join t23;
Okay.
F041-07 The inner table in a left or right outer join can also be used in an inner join
Example: select t7.* from t22 left outer join t7 on (t22_1=s1) inner join t22 on (t22_4=t22_5);
Okay. The query fails due to a syntax error but that’s expectable.
F041-08 All comparison operators are supported (rather than just =)
Example: select * from t where 0=1 or 0>1 or 0<1 or 0<>1;
Okay.
F051 Basic date and time
F051-01 DATE data type (including support of DATE literal)
Example: create table dates (s1 date);
Okay. (SQLite doesn’t enforce valid dates or times, but we’ve already noted that.)
F051-02 TIME data type (including support of TIME literal)
Example: create table times (s1 time default time ‘1:2:3’);
Fail. Syntax error.
F051-03 TIMESTAMP data type (including support of TIMESTAMP literal)
Example: create table timestamps (s1 timestamp);
Okay.
F051-04 Comparison predicate on DATE, TIME and TIMESTAMP data types
Example: select * from dates where s1 = s1;
Okay.
F051-05 Explicit CAST between date-time types and character string types
Example: select cast(s1 as varchar) from dates;
Okay.
F051-06 CURRENT_DATE
Example: select current_date from t;
Okay.
F051-07 CURRENT_TIME
Example: select * from t where current_time < '23:23:23';
Okay.
F051-08 LOCALTIME
Example: select localtime from t;
Fail. Syntax error.
F051-09 LOCALTIMESTAMP
Example: select localtimestamp from t;
Fail. Syntax error.
F081 UNION and EXCEPT in views
Example: create view vv as select * from t7 except select * from t15;
Okay.
F131 Grouped operations
F131-01 WHERE, GROUP BY, and HAVING clauses supported in queries with grouped views
Example: create view vv2 as select * from vv group by s1;
Okay.
F131-02 Multiple tables supported in queries with grouped views
Example: create view vv3 as select * from vv2,t30;
Okay.
F131-03 Set functions supported in queries with grouped views
Example: create view vv4 as select count(*) from vv2;
Okay.
F131-04 Subqueries with GROUP BY and HAVING clauses and grouped views
Example: create view vv5 as select count(*) from vv2 group by s1 having count(*) > 0;
Okay.
F181 Multiple module support
Fail. SQLite doesn’t have modules.
F201 CAST function
Example: select cast(s1 as int) from t;
Okay.
F221 Explicit defaults
Example: update t set s1 = default;
Fail. Syntax error.
F261 CASE expression
F261-01 Simple CASE
Example: select case when 1 = 0 then 5 else 7 end from t;
Okay.
F261-02 Searched CASE
Example: select case 1 when 0 then 5 else 7 end from t;
Okay.
F261-03 NULLIF
Example: select nullif(s1,7) from t;
Okay.
F261-04 COALESCE
Example: select coalesce(s1,7) from t;
Okay.
F311 Schema definition statement
F311-01 CREATE SCHEMA
Fail. SQLite doesn’t have schemas or databases.
F311-02 CREATE TABLE for persistent base tables
Fail. SQLite doesn’t have CREATE TABLE inside CREATE SCHEMA.
F311-03 CREATE VIEW
Fail. SQLite doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-04 CREATE VIEW: WITH CHECK OPTION
Fail. SQLite doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-05 GRANT statement
Fail. SQLite doesn’t have GRANT inside CREATE SCHEMA.
F471 Scalar subquery values
Example: select s1 from t where s1 = (select count(*) from t);
Okay.
F481 Expanded NULL Predicate
Example: select * from t where row(s1,s1) is not null;
Fail. Syntax error.
F812 Basic flagging
Fail. SQLite doesn’t support any flagging
S011 Distinct types
Example: create type x as float;
Fail. SQLite doesn’t support distinct types.
T321 Basic SQL-invoked routines
T321-01 User-defined functions with no overloading
Example: create function f () returns int return 5;
Fail. SQLite doesn’t support user-defined functions.
T321-02 User-defined procedures with no overloading
Example: create procedure p () begin end;
Fail. SQLite doesn’t support user-defined procedures.
T321-03 Function invocation
Example: select f(1) from t;
Fail. SQLite doesn’t support user-defined functions.
T321-04 CALL statement.
Example: call p();
Fail. SQLite doesn’t support user-defined procedures.
T321-05 RETURN statement.
Example: create function f() returns int return 5;
Fail. SQLite doesn’t support user-defined functions.
T631 IN predicate with one list element
Example: select * from t where 1 in (1);
Okay.
F031 Basic information schema.
Example: select * from information_schema.tables;
Fail. There is no schema with that name (not counted in the final score).
The Final Score
Fail: 59
Okay: 75
Update 2016-06-26: Originally I counted 60 to 74, that was an error.
So SQLite could claim to support most of the core features of the current standard, according to this counting method, after taking into account all the caveats and disclaimers embedded in the description above.
I anticipate the question, “Will ocelotgui (the Ocelot Graphical User Interface for MySQL and MariaDB) support SQLite too?” and the answer is “I don’t know.” The project would only take two weeks, but I have no idea whether it’s worth that much effort.
In the last while, I’ve concentrated on some ocelotgui bug fixes and on checking whether it runs on Windows as well as on Linux. It does, but only from source — see the instructions at https://github.com/ocelot-inc/ocelotgui/blob/master/windows.txt.
Today ocelotgui, the Ocelot Graphical User Interface for MySQL and MariaDB, version 1.0.0, is generally available for Linux. Read the manual, see the screenshots, and download binary (.deb or .rpm) packages and GPL-licensed C++ source here.
Today the first MariaDB 10.2 alpha popped up and for the first time there is support for window functions.
I’ll describe what’s been announced, what’s been expected, comparisons to other DBMSs, problems (including crashes and wrong answers), how to prepare, what you can use as a substitute while you wait.
I assume some knowledge of what window functions are. If you’d prefer an introductory tutorial, I’d suggest reading articles like this one by Joe Celko before you continue reading this post.
What’s been announced
The MariaDB sources are:
The release notes
The source code trees — the feature tree up till now has been github.com/MariaDB/server/commits/bb-10.2-mdev9543 but the version-10.2 download page has more choices and is probably more stable.
Sergei Petrunia and Vicentiu Ciorbaru, two developers who I think deserve the credit, made a set of slides for a conference in Berlin earlier this month. It seems to have some typos but is the best description I’ve seen so far.
On Wednesday April 20 Mr Petrunia will give a talk at the Percona conference. Alas, it coincides with Konstantin Osipov’s talk about Tarantool — which I’ve done some work for — which, if you somehow haven’t heard, is a NoSQL DBMS that’s stable and faster than others according to independent benchmarks like the one from Coimbra. What a shame that two such important talks are scheduled for the same time.
Anyway, it’s clear that I’ll have to update this post as more things happen.
What’s been expected
There have been several wishes / feature requests for window functions over the years.
Typical feature requests or forum queries are “Oracle-like Analytic Function RANK() / DENSE_RANK() [in 2004]”, “analytical function like RANK etc to be implemented [in 2008]”, “Is MySQL planning to implement CTE and Window functions? [in 2010]”.
Typical blog posts are Shlomi Noach’s “Three wishes for a new year [in 2012]” and Baron Schwartz’s “Features I’d like in MySQL: windowing functions [in 2013]”..
Typical articles mentioning the MySQL/MariaDB lack of window functions are “What PostgreSQL has over other open source SQL databases” and “Window Functions Comparison …”.
So it’s clear that there has been steady demand, or reason for demand, over the years.
My first applause moment is: Mr Petrunia and Mr Ciorbaru have addressed something that’s been asked for, rather than what they wished had been asked for.
Comparisons to other DBMSs
I know twelve DBMSs that support window functions. No screen is wide enough for a chart showing them all, so I’ll just list their windows-function documents here so that you can click on the names to get the details:
APACHE DRILL,
CUBRID,
DB2 LUW,
DB2 z/OS 10,
DERBY,
FIREBIRD,
INFORMIX,
ORACLE,
POSTGRESQL,
SQL SERVER,
SYBASE,
TERADATA. I’ll show MariaDB against The Big Three.
These functions are mentioned in the standard document as required by optional feature T611 ELementary OLAP operations:
| Function |
MariaDB |
Oracle |
DB2 |
SQL Server |
| DENSE_RANK |
yes |
yes |
yes |
yes |
| RANK |
yes |
yes |
yes |
yes |
| ROW_NUMBER |
yes |
yes |
yes |
yes |
These functions are mentioned in the standard document as required by optional feature T612 Advanced OLAP operations:
| Function |
MariaDB |
Oracle |
DB2 |
SQL Server |
| CUME_DIST |
yes |
yes |
no |
yes |
| PERCENT_RANK |
yes |
yes |
no |
yes |
These functions are mentioned in the standard document as required by optional features T614 through T617:
| Function |
MariaDB |
Oracle |
DB2 |
SQL Server |
| FIRST_VALUE |
no |
yes |
yes |
yes |
| LAG |
no |
yes |
yes |
yes |
| LAST_VALUE |
no |
yes |
yes |
yes |
| LEAD |
no |
yes |
yes |
yes |
| NTH_VALUE |
no |
yes |
no |
no |
| NTILE |
yes |
yes |
no |
yes |
These are common functions which are in the standard and which can be window functions:
| Function |
MariaDB |
Oracle |
DB2 |
SQL Server |
| AVG |
yes |
yes |
yes |
yes |
| COUNT |
yes |
yes |
yes |
yes |
| COVAR_POP/SAMP |
no |
yes |
yes |
yes |
| MAX |
no |
yes |
yes |
yes |
| MIN |
no |
yes |
yes |
no |
| SUM |
yes |
yes |
yes |
yes |
| VAR_POP/SAMP |
no |
yes |
yes |
yes |
Yes MariaDB also supports non-standard functions like BIT_XOR, but they’re worthless for comparison purposes. What’s more important is that the MariaDB functions cannot be DISTINCT.
As for the options in OVER clause … just the important ones …
| Function |
MariaDB |
Oracle |
DB2 |
SQL Server |
| ORDER BY |
yes |
yes |
yes |
yes |
| NULLS FIRST|LAST |
no |
“yes” |
yes |
no |
| PARTITION BY |
yes |
yes |
yes |
yes |
| PRECEDING|FOLLOWING |
sometimes |
yes |
yes |
yes |
Those are the options that matter. The NULLS clause is important only because it shows how far an implementor will go to support the standard, rather than because most people care. MariaDB in effect supports NULLS HIGH|LOW, which is as good as Oracle — The Oracle manual puts it this way: “NULLS LAST is the default for ascending order, and NULLS FIRST is the default for descending order.” People who think that’s not cheating can add a comment at the end of this post.
From the above I suppose this second applause moment is justifiable: MariaDB has all the basics, and half of the advanced features that other DBMSs have.
Problems (including crashes and wrong answers)
The MariaDB announcement says:
“Do not use alpha releases on production systems! … Thanks, and enjoy MariaDB!”
Indeed anyone who used 10.2.0 in production would discover that enjoyable things can be bad for you.
I started with this database: …
create table t1 (s1 int, s2 char(5));
insert into t1 values (1,'a');
insert into t1 values (null,null);
insert into t1 values (1,null);
insert into t1 values (null,'a');
insert into t1 values (2,'b');
insert into t1 values (-1,'');
The following statements all cause the server to crash:
select row_number() over ();
select 1 as a, row_number() over (order by a) from dual;
select *, abs(row_number() over (order by s1))
- row_number() over (order by s1) as X from t1;
select rank() over (order by avg(s1)) from t1;
The following statements all give the wrong answers:
select count(*) over (order by s2) from t1 where s2 is null;
select *,dense_rank() over (order by s2 desc),
dense_rank() over (order by s2) from t1;
select *, sum(s1) over (order by s1) from t1 order by s1;
select avg(s1), rank() over (order by s1) from t1;
The following statement causes the client to hang (it loops in mysql_store_result, I think this is the first time I’ve seen this type of error)
select *, avg(s1) over () from t1;
And now for the third applause line … to which you might be saying: huh? Aren’t those, er, less-than-desirable results? To which I would reply: yes, but two weeks ago there were far more and far bigger problems. We should be clapping for how quickly progress has been made, and guessing that this section of my post will be obsolete soon.
How to prepare
You have lots of time to get ready for 10.2, but may as well start now by getting rid of words that have special meaning for window functions.
The word OVER is reserved.
The newly supported function names — DENSE_RANK RANK ROW_NUMBER CUME_DIST PERCENT_RANK NTILE — are not reserved, and the names of functions which will probably be supported soon — FIRST_VALUE LAG LEAD LAST_VALUE NTH_VALUE — will probably not be reserved. But they might as well be, because you won’t be able to use those names for your own functions. Besides, they’re reserved in standard SQL.
What you can use as a substitute
Suppose you don’t want to wait till MariaDB is perfect, or you’d like to stay with MySQL (which as far as I know has made less progress than MariaDB toward this feature). Well, in short: gee that’s too bad. But I have seen three claims about getting a slight subset.
One: Shlomi Noach claimss you can use a trick with GROUP_CONCAT:
Two: Adrian Corston claims you can make delta functions with assignments.
Three: I claim that in ocelotgui you can put ‘row_number() over ()’ in a SELECT and get a row-number column even with older versions of MySQL or MariaDB (this is a recent change, it’s in the source not the binary).
In fact all the “window_function_name() OVER ()” functions could be done easily in the client, if they’re in the select list and not part of an expression,
and the result set is ordered. But I’m not sure whether that’s something to excite the populace.
There might be a “Four:”. I have not surveyed the various applications that can do cumulations. I suspect that mondrian is one, and open OLAP might be another, but haven’t looked at them.
Our own progress
For ocelotgui (Ocelot’s GUI client for MySQL and MariaDB) we had to adjust the syntax checker to highlight the new syntax in 10.2, as this screenshot shows 
So we now can claim to have “the only native-Linux GUI that correctly recognizes MariaDB 10.2 window functions”. Catchy slogan, eh? The beta download is at https://github.com/ocelot-inc/ocelotgui. I still expect that it will be out of beta in a few weeks.
The Ocelot GUI client for MySQL/MariaDB is now beta. The final feature is client-side predictive parsing of every SQL clause and statement. Readers who only care how we did it can skip to the section Recursive Descent Parsers”. I’ll start by illustrating why this is a good feature.
Error Checks
Compare this snapshot from mysql client:

with this from ocelotgui:
The GUI advantage is that the error message is more clear and the error location is more definite. This is not always true. However, anybody who dislikes the famous message “You have an error …” should like that there is another way to hear the bad news. It’s like getting an extra opinion.
In theory the further advantage is: this saves time on the server, because the client catches the syntax errors. In practice that should not be important, because: (a) ocelotgui is lax and can be erroneous; (b) there are better ways to catch some syntax errors before sending them to the server, for example setting up a test machine.
Finding the end
All respectable clients can scan an SQL statement to find its tokens. For example the mysql client knows that anything enclosed in quote marks, except a pair of quote marks, is a single token. This is pretty well essential, because it has to know whether a semicolon is just part of a string, or is the end of a statement.
Unfortunately a semicolon might not be the end of a compound statement, and that’s where simple “tokenizers” like mysql’s can’t cope. So in my MySQL days we had to come up with the concept of delimiters (I say “we” because I think the hassle of delimiters might have been my idea, but others are welcome to take the credit). It should be clear that a statement like
CREATE PROCEDURE p() BEGIN WHILE 0 = 0 DO ... END WHILE;
is not complete and should not go to the server, so it’s nice that we can say we don’t need delimiters.
But they still can have their uses. The scenario I dread is that a user has a spelling error, causing the client to think that input is complete, and shipping it off to the server prematurely. If there was some symbol that always meant “ship it!” and no other symbol ever meant “ship it!”, that would become unlikely. That’s what delimiters are. But we should have decided on a fixed unchangeable symbol instead of a user-defined one.
Highlighting
All respectable GUIs have highlighting, that is, they can display different colours for literals, operators, or keywords. But most GUIs cannot figure out what is a keyword, unless they ask the MySQL-server’s parser. The SQL problem is that there are two kinds of keywords: reserved words (which are guaranteed to have syntactic meaning if they’re not errors), and ordinary keywords (which might have syntactic meaning but might be identifiers, depending where they appear). An example statement is
CREATE PROCEDURE begin () end: BEGIN END;
where “end” and “begin” are identifiers, but BEGIN and END are not.
(A much easier problem is that you’d need two keyword lists, because in MySQL 5.7 GENERATED and GET and IO_AFTER_GTIDS and IO_BEFORE_GTIDS and MASTER_BIND and STORED and VIRTUAL are reserved words, but in MariaDB they’re not. But, since we don’t think the MariaDB manual’s reserved-word list is correct, we think those are the only reserved-word differences.)
So we have to beware of anything that depends on a list of keywords. For example my favoured editor is a variant of Kate, which recognizes a hodgepodge of symbols in its “SQL Keyword” list, and displays utterly useless highlighting when my file’s extension is .sql. Apparently Vim would be similar. Most clients that claim to work with MySQL or MariaDB are better than editors — they at least use a DBMS-specific keyword list rather than a generic one — and they’re generally good because in a sense they train users not to use keywords as identifiers. For example, if users see that “begin” has a non-identifier colour while they’re typing, they’ll avoid creating objects named “begin” even though it’s not a reserved word.
I’m not sure whether, in the wider SQL world, well known GUI clients have advanced past the keyword-list stage. I see hints here and there that SQL Server Management Studio has not and Toad has not, and Oracle SQL Developer has, but nothing explicit, and I repeat I’m not sure.
(UPDATE 2016-03-28: Mike Lischke’s description of Oracle’s new approach is here.)
In the end, then, a GUI with keyword-list highlighting will be right 90% of the time (I’m just guessing here, but I think it will sound right to experienced readers). On the other hand, a GUI that recognizes grammar should be right 97% of the time, and — just guessing again — I expect that’s preferable.
Predicting
The next step upwards in intelligence is knowing what the next token might be before the user starts typing it, or knowing how the current token ends before the user finishes typing it. And here, if you contemplate the Error Message example that we started with, you might realize: the MySQL/MariaDB server parser can’t do this. Which is why I emphasized right in the title: this is “predictive” parsing.
Example 1: suppose you’ve typed SELECT * FROM T ORDER. The GUI will show what the next word must be …
Example 2: suppose you’ve typed CREATE T. The GUI will show what possible words start with T …
And in either case, hitting the Tab key will save a bit of typing time. I should note that “hitting the Tab key to complete” is something many can do, even the mysql client — but for identifiers not keywords. Technically we can do both, though we prefer to avoid discussing identifiers.
Initial Summary
For error checking, finding the end, highlighting, and predicting: whoopie for predictive parsing of the whole MySQL / MariaDB grammar.
As an additional point, I suppose it’s obvious that we wouldn’t have been able to incorporate a stored-procedure debugger in ocelotgui without parsing. Admittedly it is not using the new parsing code, but it is necessary for it to do a lot more than looking at keywords. So I class debugger capability as the fifth advantage of having client-side parsing.
Recursive Descent Parsers
The algorithms for recursive descent parsers are in most textbooks for compilers, and even in Wikipedia. The “recursive” means that the process can call itself; the rest of the algorithm looks like this:
If (next thing is X) accept it and get the next thing
if (next thing is Y) accept it and get the next thing
if (next thing is Z) accept it and get the next thing
…
else give up and say there’s an error.
Simple, eh?
Now for some quotes from those textbooks for compilers:
“The advantages of recursive descent parsers are that it’s easy to write, and once written, it’s easy to read and understand. The main disadvantage is that it tends to be large and slow.” — Ronald Mak, Writing Compilers And Interpreters, page 810
“The parser text shows an astonishingly direct relationship to the grammar for which it was written. This similarity is one of the great attractions of recursive descent parsing. … In spite of their initial good looks, recursive descent parsers have a number of drawbacks … repeated backtracking … often fails to produce a correct parser [text] … error handling leaves much to be desired.” — Dick Grune, Henri Bal, Ceriel Jacobs, Koen Langendoen, pages 117-119
And they’re right. Have a look at the parsing code of ocelotgui, which can be done by opening a source file here and searching for the first line that begins with “void MainWindow::hparse_f_” (line 9565 in today’s beta). Then scroll downwards till there are no more routines that begin with hparse_f_ — 5000 lines later. Readable, sure, because it’s the simplest of C code. But also tedious, repetitive, and yes, “large and slow”. And this is without knowing anything about object names, since it’s a purely syntactic syntax checker and won’t look at metadata.
On a server the disadvantages could be crippling, but on a client they don’t matter — the meanest laptop has megabytes to spare and the response time is still way faster than a user can blink. And SQL doesn’t require repeated backtracking because it’s rarely necessary to look ahead to the next tokens in order to figure out what the current token means. Here is the worst example that we ran into (I’m quoting the MariaDB 10.1 manual
GRANT role [, role2 ... ] TO grantee [, grantee2 ... ]
which can be instantiated as
GRANT EXECUTE, ROLE55 TO JOE;
See the problem? It’s perfectly okay for EXECUTE to be a role name — it’s not reserved — but typically it’s in statements like GRANT EXECUTE … ON PROCEDURE. So we have to look ahead to find whether ON follows, or whether TO follows. Which we did … and then found out that MariaDB couldn’t. I’d mentioned that this looked tough when I wrote about MariaDB roles two years ago. But for some reason it was attempted anyway and the inevitable bug report has been labelled “stalled” for a long time.
Oh, and one more detail that you’ll find in those compiler textbooks: correctly speaking, ocelotgui has a “recognizer” not a “parser” because it doesn’t generate a tree. That’s why I’ve carefully said it “does parsing” but not said it contains a parser.
Beta Status
The above represents the last feature that we intend to add. It’s at last “ocelotgui beta” rather than “ocelotgui alpha”. The C source and Linux executables, as usual, are at
https://github.com/ocelot-inc/ocelotgui.
